Hologres是一款高性能的、計算存儲分離的分布式一站式實時數倉引擎,數據存儲在位于底層存儲系統的數據分片(又稱Shard)上。本文為您介紹Hologres中Table Group和Shard Count的概念。
Table Group和Shard
在Hologres中數據存儲在Pangu系統上,Shard表示數據分片,Table Group則是用于管理這些Shard,類似于存儲邏輯概念。一個表的數據將會存儲在固定的一組Shard上,數據寫入時會按照Distribution Key將數據分發到具體的Shard上。從創建表開始,負責存儲表數據的這一組Shard就已經分配好了,Table Group則負責管理這一組Shard。
Table Group是Hologres特有的一個存儲邏輯概念(PostgreSQL無此概念)。Table Group與PostgreSQL中的TABLESPACE是不一樣的:TABLESPACE唯一標識了數據庫對象的存儲位置,類似一個目錄的概念。而Table Group代表的是底層的邏輯Shard組。
Table Group布局圖如下: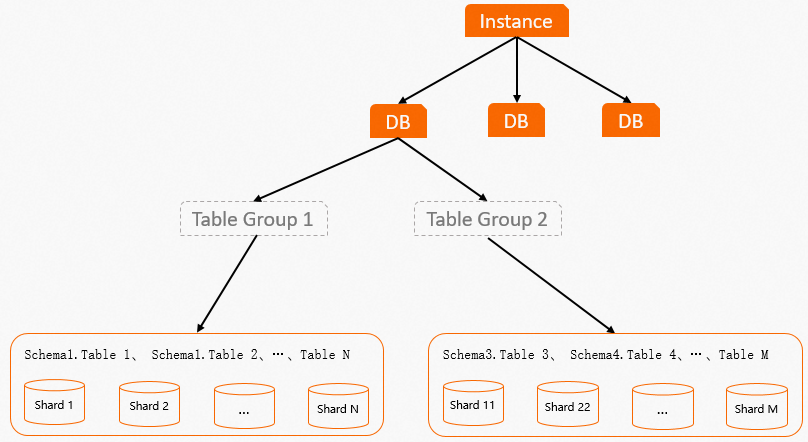 通過Table Group布局圖,可以看出:
通過Table Group布局圖,可以看出:
Table Group與Schema的區別
Schema是一個標準的數據庫概念,而Table Group是一個邏輯存儲概念,并非數據庫標準。不同Schema下的表可以位于同一個Table Group,即底層使用同一組Shard存儲。
Table Group與數據庫(DB)的關系
一個DB可以包含一個或者多個Table Group,但是一個DB只能有一個默認Table Group。在創建DB之后,系統會創建一個默認Table Group,可以根據業務情況增加Table Group或者修改默認Table Group。
不同Table Group的區別
一個DB可以存在多個Table Group,但Table Group之間的Shard互不相交,每個Shard在實例級別擁有單獨的編號。
Shard Count
一個Table Group中Shard的數量稱為Shard Count。Shard Count在創建Table Group時指定,所以Table Group一旦建立,Shard Count就不能調整,如需調整Shard Count,需要重新創建Table Group并指定Shard數。
Shard與Table的關系
Shard負責表數據的存儲和查詢,系統根據Distribution Key決定表數據分布在哪些Shard,如果沒有設置Distribution Key,那么數據就會被隨機分配到各個Shard。
一個Table Group中可以有多個Table,即多個Table可以分布在同一組Shard上。但是一個Table只能屬于一個Table Group,如果Table Group中沒有Table,那么Table Group會被系統自動刪除。
如果Table的數據要從一個Table Group遷移至另外一個Table Group,那么需要重新建表指定Table Group,或者通過遷移函數將數據進行遷移。
Shard與計算節點Worker的關系
在Hologres中存儲引擎Storage Engine(SE)主要負責管理和處理數據,在DML的功能上,SE提供了單條或者批量的創建、查詢、更新、和刪除(CRUD操作)訪問方法的接口,查詢引擎(QE)可以通過這些接口訪問Shard上的數據,從而實現數據的高性能寫入或者讀取。
計算節點Worker、SE、Shard的布局關系圖如下。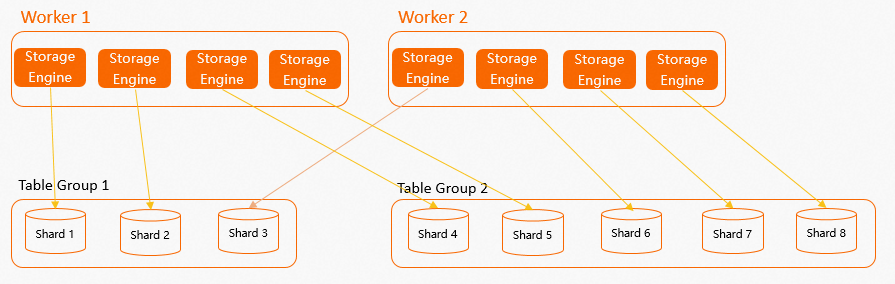 從圖中可以看出Table Group和Shard不僅與數據的存儲分布有關系,還與計算Worker有一定的關系:
從圖中可以看出Table Group和Shard不僅與數據的存儲分布有關系,還與計算Worker有一定的關系:
當創建Table Group并設置Shard數后(如果沒有顯式設置Table Group和Shard數,那么Hologres會在創建數據庫時創建一個默認Table Group并為其設置默認的Shard Count,詳情請參見實例規格概述),每個計算節點Worker會在內部創建多個SE,一個SE負責一個Shard數據的讀取和寫入。
系統機制會盡量保證每個Worker中的SE數量均勻,這樣能夠讓Worker計算資源均勻分配。
系統會保證一個Table Group內的Shard一定是分配給多個Worker,不會出現一個Table Group僅對應一個Worker,其余Worker空置的情況。但如果Table Group的Shard數較少,但是實例規格較大即Worker較多,則會導致某些Worker無法分配Shard,導致某些Worker空置,因此在設計Shard數時一定要充分考慮業務情況,確保Worker的個數與實例總的Shard數有一定的均衡關系。
從上圖中能很容易看出一個問題:假如Table Group的Shard數與Worker個數不成比例關系(如上圖
Table Group 1有3個Shard,但是只有2個Worker),那么就一定會存在某個Worker比其他Worker多分配一個SE給Table Group的情況,這樣在計算時,就非常容易造成Worker資源傾斜,容易出現計算長尾。因此我們建議若是要修改Shard Count,建議Shard Count與計算Worker成一定的比例關系。如下圖所示Table Group 1和Table Group 2的Shard數都與Worker個數存在倍數關系,計算資源能夠均勻的分配。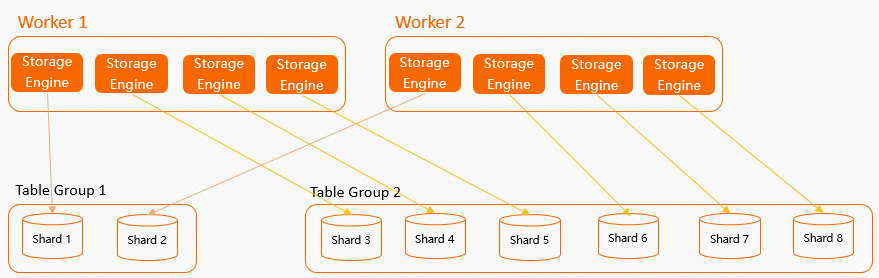
在實際業務中,可能會存在某個Worker因為OOM等原因出現Failover的情況,那么該Worker對應的Shard將會在Worker Failover之后自動掛載在其他Worker上,系統會保證每個Worker新分配的Shard均勻。如下示例,實例一共有4個Worker,2個Table Group共8個Shard,其中每個Worker有2個SE均勻對應Shard,當
Worker 4Failover后,假設Worker 4對應Shard 7和Shard 8,那么Shard 7和Shard 8就會被快速分配給其他3個Worker,因為只有2個Shard,所以系統會隨機選擇2個Worker進行分配,盡量保證Worker的SE數量均勻。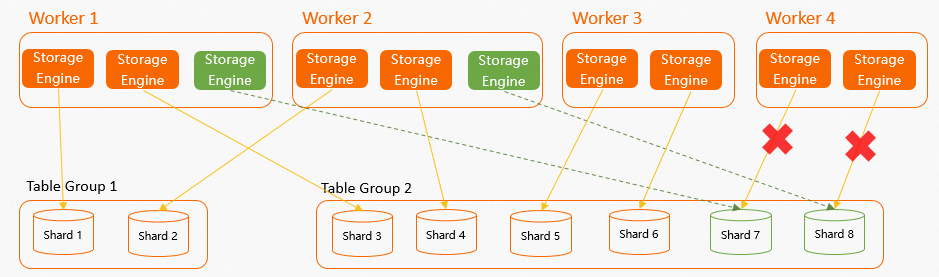
總結
Worker數量與Shard數有著非常緊密的聯系。合理的設置Table Group與Shard Count,其數據寫入和查詢分析處理可以得到更大的并行度,將計算資源充分使用,從而從根本上提高數據的存儲與計算效率。反之如果Table Group和Shard數制定不當,很容易出現性能不如預期的情況,且無法從根本上調優到最佳性能:
一定范圍內Shard數多的Table Group,其數據寫入和查詢分析處理可以得到更大的并行度。但Shard數也并非越多越好,更多的Shard數需要更多的節點間通信資源、計算資源以及內存資源,在資源不滿足的時候,或者Query很小時可能會導致適得其反的效果。
Shard數下限是1,在數據量只有幾百幾千條等很小的情況下,可以設置Shard數為1。一個Table Group上,Shard數的上限建議是實例的總計算Core數,這樣是為了保證每個Shard在計算時,至少可以占據1個Core用于計算。如果Shard數超過計算Core數,那么運行查詢時,將有部分Shard無法一直分到CPU資源,可能帶來長尾和切換開銷。
除Shard數量外,Table Group本身的數量也不是越多越好。每個Shard無論是否正在使用,都會占據一定的內存空間,用于存放表元數據、Schema等信息,在表有寫入時則會占據更多內存空間。因此如果Table Group越多,則實例內總Shard數越多,內存空間占用越大。另外多個表之間有一些特殊的關系(例如需要Local Join)時,這些表必須要處在同一Table Group下才行。
從磁盤上來看,Shard數越多,對于同樣的一張表,數據會分的越散,越容易出現小文件,從而文件個數更多。如果表多并且Shard也多,那文件數量就會非常龐大。在查詢時Failover時都需要更多的開銷,造成查詢I/O增多,恢復時間變長。