OOM(Out of Memory)描述的是Query的內存消耗超出了系統當前的供給,系統做出的一種異常提示。本文將為您介紹如何在Hologres中查看內存消耗、分析內存水位高情況,識別OOM(內存溢出)現象及其產生原因,并提供相應的處理方法。
內存消耗分析
查看內存消耗
管理控制臺提供整個實例的內存消耗情況,即多個節點的內存匯總值,詳情請參見Hologres管控臺的監控指標。
慢Query日志中memory_bytes字段提供單個Query的內存消耗情況,是非精確的值,存在一定的誤差,詳情請參見慢Query日志查看與分析。
內存水位高
可以通過Hologres管控臺的
內存使用率和實例內存分布使用率指標了解實例的內存綜合使用率,詳情請參見Hologres管控臺的監控指標。當內存水位長期超過80%,可以認為屬于內存水位高的情況。Hologres的內存資源采用預留模式,即使沒有執行查詢操作,也會有部分Meta、Index元數據和Cache加載到內存中,該類元數據用于提升計算速度,無任務運行時內存使用率可能會到達30%~50%左右,屬于正常現象。內存使用率持續升高,甚至接近100%,通常會影響系統的運行,影響實例的穩定性和性能。關于該問題產生的原因、主要影響和解決方法具體如下:產生原因
元數據占用內存多
表現為Meta內存使用率高:表數據量增加,數據總量也隨之增加,元數據占用內存多,當沒有任務運行時,內存水位也會高,通常建議一個Table Group下不要超過10000張表(包括分區子表,不包含外部表),Table Group的Shard數高,也會造成更多的文件碎片和積累更多的元數據,占用元數據內存。
計算內存高
表現為Query內存使用率高:運行任務時掃描大數據量或者計算邏輯非常復雜,例如有非常多的Count Distinct函數、復雜的Join操作、多字段Group By、窗口操作等。
主要影響
影響穩定性
當存在元數據過大等問題時,會超額占據正常Query可用的內存空間,導致在查詢過程中,可能會偶發
SERVER_INTERNAL_ERROR、ERPC_ERROR_CONNECTION_CLOSED、Total memory used by all existing queries exceeded memory limitation等報錯。影響性能
當存在元數據過大等問題時,會超額占據正常Query可用的緩存空間,從而導致緩存命中減少,Query延遲增加。
解決方法
元數據過多導致內存較高時,建議通過
hg_table_info表對數據表進行治理,詳情請參見表統計信息查看與分析。建議刪除不再查詢的數據或者表和減少不必要的分區表設計,以釋放占用的內存。計算導致內存水位較高時,建議區分寫入和查詢場景,進行SQL優化,詳情請參見如何解決查詢時OOM和如何解決導入導出時OOM。
擴容,對實例的計算和存儲資源進行升配,詳情請參見實例列表。
識別OOM報錯
當計算內存超出上限時(大于等于20 GB),就會出現OOM的情況。常見的報錯如下。
Total memory used by all existing queries exceeded memory limitation.
memory usage for existing queries=(2031xxxx,184yy)(2021yyyy,85yy)(1021121xxxx,6yy)(2021xxx,18yy)(202xxxx,14yy); Used/Limit: xy1/xy2 quota/sum_quota: zz/100報錯解讀如下。
queries=(2031xxxx,184yy)指
queries=(query_id,query使用的內存),例如queries=(2031xxxx,18441803528),代表query_id=2031xxxx的Query,在運行時單個節點使用了18 GB的內存。異常信息里面會列出消耗內存的Top 5的Query,可以通過報錯找到內存消耗最大的Query,并在慢Query日志查看與分析中查看詳細的Query信息。Used/Limit: xy1/xy2指
單個節點使用的計算內存/單個節點的計算內存上限,單位為Byte。單個節點使用的計算內存是指當前時刻所有Query運行時在該節點使用的計算內存總和。例如Used/Limit: 33288093696/33114697728,代表所有Query在該節點運行時的內存使用了33.2 GB,但是單個計算節點的彈性內存只能配33.1 GB,因此出現OOM。quota/sum_quota: zz/100quota代表資源組,其中zz對應資源組分配的資源。例如quota/sum_quota: 50/100代表設置了資源組,其分配的資源是實例總資源的50%。
產生OOM的基本原因
有的系統在內存資源不足時會采用磁盤緩存的方式進行算子降級(Spill to Disk),Hologres為了保障查詢的效率,默認所有算子都采用內存資源進行計算,因此會存在內存不足導致OOM的問題。
內存的分配和上限
一個Hologres實例是由多個節點組成的分布式系統,不同的實例規格對應不同的節點數,詳情請參見實例規格概述。
在Hologres中一個節點的規格是16 Core 64 GB,即內存上限是64 GB,一個Query運行時涉及到的任意節點的內存不足,都會產生OOM異常。內存會分幾個部分,包括Query計算、后端進程、緩存、Meta等部分。在早期版本中,計算節點(Worker Node)的內存上限是20 GB,但Hologres從V1.1.24版本開始,計算節點運行時內存取消單節點20 GB的限制,采用動態調整節點內存,定期檢查內存水位,如果元數據較少時,會盡量將剩余可用內存都分配給查詢運行時使用,盡量保證運行時內存最大化分配,保障Query獲得足夠內存分配。
如何解決查詢時OOM
當出現查詢OOM時,其原因通常有如下幾類。
執行計劃錯誤:統計信息不正確、Join Order不正確等。
Query并發度高,且每個Query消耗的內存很大。
Query本身復雜或者掃描的數據量很大。
Query中包含
union all,增加執行器的并行度。設置了資源組,但是給資源組分配的資源較少。
數據傾斜或者Shard Pruning導致負載不均衡,個別節點的內存壓力較大。
以上原因的具體分析以及相應的解決方法如下。
資源組分配的資源較少
使用Serverless Computing功能執行查詢。Serverless Computing功能可以實現在實例獨享資源之外,使用Serverless資源執行相關查詢。相比實例獨享資源,Serverless Computing提供更豐富的計算資源,并且查詢之間不會相互爭搶資源,因此非常適合解決內存溢出(OOM)問題。Serverless Computing介紹,詳情請參見Serverless Computing概述,其使用方式詳情,請參見Serverless Computing使用指南。
檢查執行計劃是否合理
類型1:統計信息不準確
通過執行
explain <SQL>可以查詢執行計劃,如下圖所示rows=1000表示缺少統計信息或者統計信息不準確,會導致生成不準確的執行計劃,從而使用更多的資源進行計算造成OOM。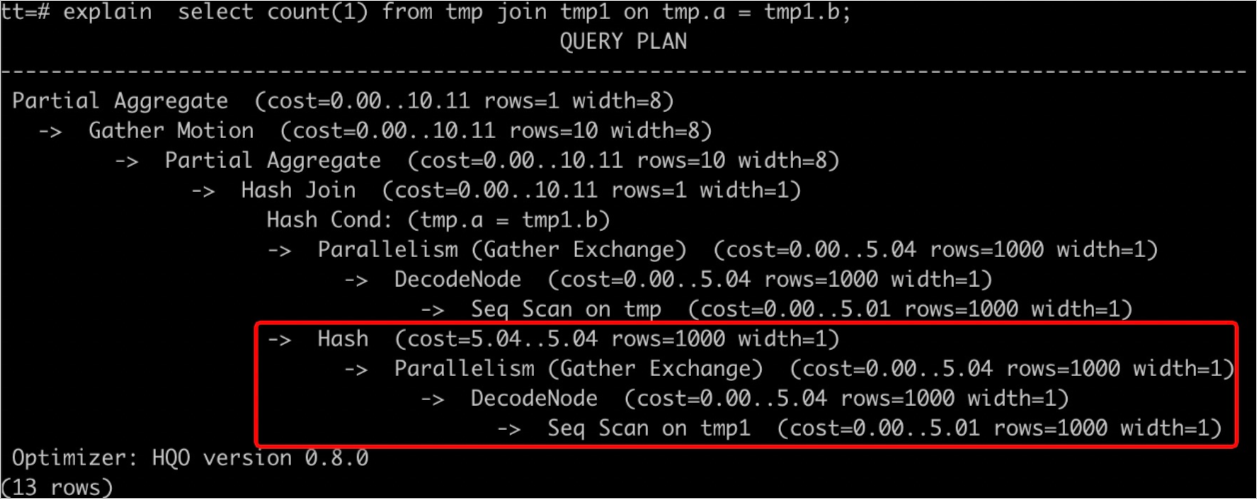
解決方法如下。
執行
analyze <tablename>命令,更新表的統計信息。設置AUTO ANALYZE自動更新統計信息,詳情請參見ANALYZE和AUTO ANALYZE。
類型2:Join Order不正確
當兩個表通過Hash算子執行連接時,合理的連接方式是數據量較小的表構建Hash表。通過執行
explain <SQL>命令查看執行計劃,如果數據量更大的表在下方,小表在上方時,表示使用更大的表構建Hash表,這種Join Order容易導致OOM。Join Order不正確的原因通常如下。表未及時更新統計信息,例如下圖中上面的表沒有更新統計信息,導致
rows=1000。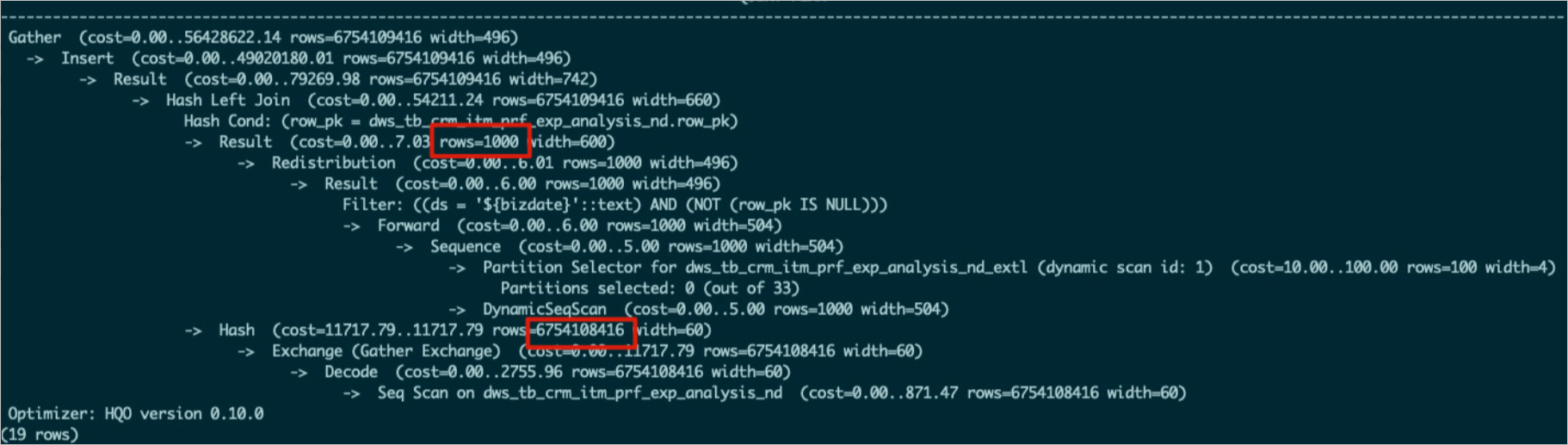
優化器未能生成更好的執行計劃。
解決方法如下。
對參與Join的表都執行
analyze <tablename>命令,及時更新統計信息,使其生成正確的Join Order。執行
analyze tablename命令之后,Join Order還是不正確,可以通過修改GUC參數進行干預。如下所示設置optimizer_join_order=query,使優化器按照SQL的書寫順序確定Join Order,適用于復雜Query。SET optimizer_join_order = query; SELECT * FROM a JOIN b ON a.id = b.id; -- 會將b作為HashTable的build side同時也可以根據業務情況,調整Join Order策略。
參數
說明
set optimizer_join_order = <value>
優化器Join Order算法,values有如下三種。
query:不進行Join Order轉換,按照SQL書寫的連接順序執行,優化器開銷最低。
greedy:通過貪心算法進行Join Order的探索,優化器開銷適中。
exhaustive(默認):通過動態規劃算法進行Join Order轉換,會生成最優的執行計劃,但優化器開銷最高。
類型3:Hash表預估錯誤
當有Join操作時,通常是會把小表或者數據量小的子查詢作為Build Side構建Hash表,這樣既能優化性能,又能節省內存。但是有時候因為查詢過于復雜,或者統計信息的問題,數據量會估錯,就導致把數據量大的表或者子查詢做了Build Side,這樣一來,構建Hash表會消耗大量的內存,導致OOM。
如下圖所示,執行計劃中
Hash (cost=727353.45..627353.35 , rows=970902134 width=94)即為Build Side,rows=970902134就是構建Hash表的數據量,若是實際表數據量比這個少,說明Hash表預估不準確。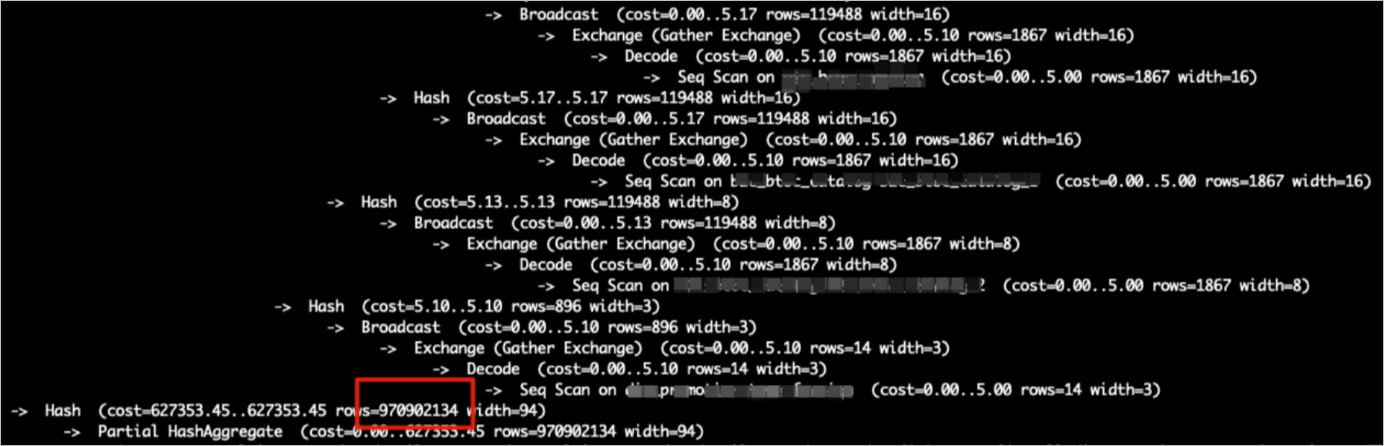
解決方法如下。
查看子查詢的表是否更新統計信息或者統計信息是否準確,若是不準確,請執行
analyze <tablename>命令。通過以下參數關閉執行引擎對Hash表的預估。
說明該參數默認關閉,但是可能在某些調優場景被打開過,若是查看時打開的,可以進行關閉。
SET hg_experimental_enable_estimate_hash_table_size =off;
類型4:大表被Broadcast
Broadcast是指將數據復制至所有Shard。僅在Shard數量與廣播表的數量均較少時,Broadcast Motion的優勢較大。在Join場景中,執行計劃先進行Broadcast,即將Build Side的數據廣播完再構建Hash表,這就意味著每個Shard內構建Hash表的數據都是Build Side的全量數據,若是Shard多或者數據量較大,則會消耗很多內存,造成OOM。
假如表數據量是8000萬行,如下圖執行計劃所示,預估表只有1行,參與Broadcast只有80行,與真實情況不符合,真實執行時需要8000萬行數據參與Broadcast,導致消耗過多內存從而出現OOM。
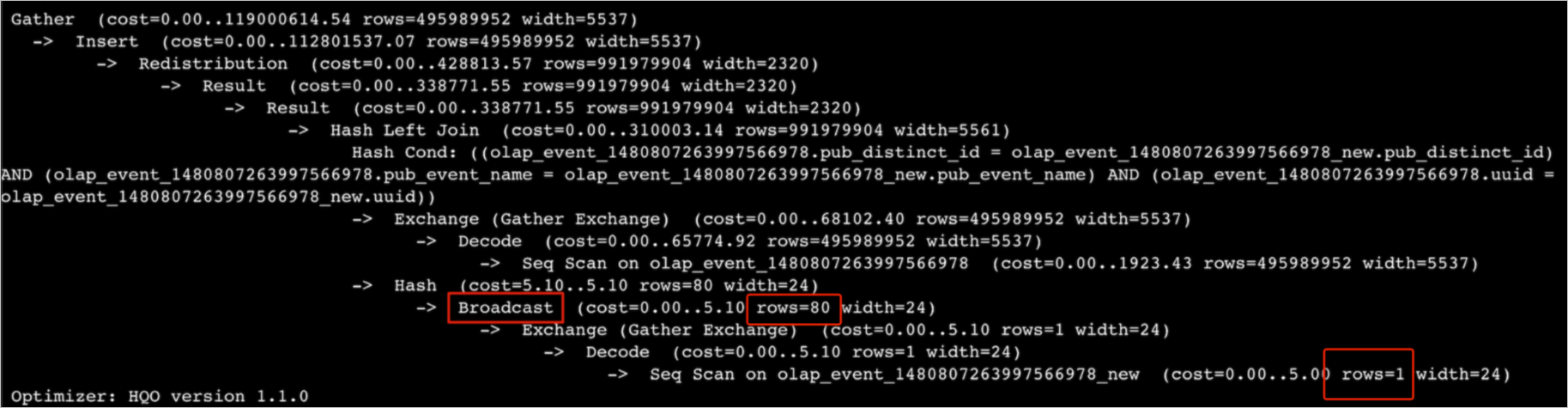
解決方法如下。
檢查執行計劃中預估行數是否正確,不正確的話,請執行
analyze tablename命令更新統計信息。通過以下GUC關閉Broadcast,直接改寫為redistribution算子。
SET optimizer_enable_motion_broadcast = off;
Query并發大
監控指標上QPS增加明顯,或者OOM中報錯:
HGERR_detl memory usage for existing queries=(2031xxxx,184yy)(2021yyyy,85yy)(1021121xxxx,6yy)(2021xxx,18yy)(202xxxx,14yy);且每個Query使用的內存較少,說明當前Query并發較大,可以通過以下方式解決。若是有寫入,可以降低寫入并發,詳情請參見如何解決導入導出時OOM。
擴容實例計算規格。
復雜Query
若是Query本身比較復雜或者掃描數據量較多,一個Query就出現OOM,可以通過以下方法解決。
計算前置,將清洗好的數據寫入Hologres,避免在Hologres進行大型ETL操作。
增加過濾條件。
SQL優化:例如使用Fixed Plan、Count Distinct優化等,詳情請參見優化查詢性能。
UNION ALL
如下所示,當SQL中含有大量
UNION ALL subquery時,執行器會并行處理每個subquery,導致內存壓力變大,從而出現OOM。subquery1 UNION ALL subquery2 UNION ALL subquery3 ...可以通過如下參數強制執行器串行,減少OOM情況,但查詢速度會變慢。
SET hg_experimental_hqe_union_all_type=1; SET hg_experimental_enable_fragment_instance_delay_open=on;資源組配置不合理
OOM時出現報錯:
memory usage for existing queries=(3019xxx,37yy)(3022xxx,37yy)(3023xxx,35yy)(4015xxx,30yy)(2004xxx,2yy); Used/Limit: xy1/xy2 quota/sum_quota: zz/100。其中zz的取值較小,如下圖所示為10,說明資源組只擁有實例10%的資源。
解決方法:重新設置資源組配額,每個資源組都不應該小于
30%。數據傾斜或Shard Pruning
當實例整體內存水位不高,但仍然出現OOM的情況,一般原因為數據傾斜或者Shard Pruning導致某個或者某幾個節點的內存水位較高,從而出現OOM。
說明Shard Pruning是指通過查詢剪枝技術,只掃描部分Shard。
通過以下SQL排查數據傾斜,
hg_shard_id是每個表的內置隱藏字段,表示數據所在的Shard。SELECT hg_shard_id, count(1) FROM t1 GROUP BY hg_shard_id;從執行計劃查看Shard Pruning,例如執行計劃中Shard Selector為
l0[1],說明只選中了一個Shard數據進行查詢。-- 這里distribution_key為x, 基于x=1過濾條件,可以快速定位所在Shard SELECT count(1) FROM bbb WHERE x=1 GROUP BY y;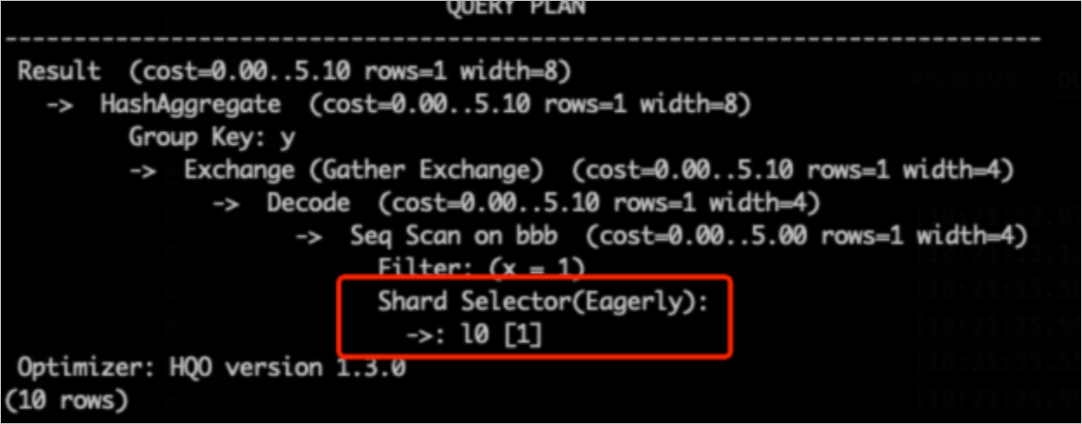
解決方法如下。
設計合理的Distribution Key避免數據傾斜。
若是業務有數據傾斜,需要對業務進行改造。
大基數多階段GROUP BY
從Hologres V3.0版本開始,對于大基數的多階段Agg,當GROUP BY的列與數據分布不匹配(Distribution Key不是GROUP BY Key的子集)時,低階段Agg的每個并發實例都會維護一張很大的Hash Table做GROUP BY Key聚合,導致內存壓力很大,容易OOM。可以通過設置如下參數分階段去進行Agg操作。
-- 通過guc設置Agg HashTable行數的上限,如下SQL表示partial_agg_hash_table最多時8192行。默認值為0,表示不限制。 SET hg_experimental_partial_agg_hash_table_size = 8192;
如何解決導入導出時OOM
導入導出OOM是指數據在Hologres表之間導入導出,也包括內部表和外部表之間導入導出,常見于MaxCompute導入到Hologres時出現OOM。
使用Serverless Computing功能執行導入導出
Serverless Computing功能可以實現在實例獨享資源之外,使用Serverless資源執行相關導入導出任務。相比實例獨享資源,Serverless Computing提供更多的計算資源,并避免了任務之間的資源爭搶,非常適合解決內存溢出(OOM)問題。Serverless Computing概述請參見Serverless Computing概述,其詳細使用方法請參見Serverless Computing使用指南。
大寬表或者寬列且有高Scan并行度
通常在MaxCompute導入場景會出現大寬表或者比較寬的列有比較大的Scan并行度,導致寫入出現OOM。可以通過以下參數控制導入并行度減少OOM。
大寬表導入(常用場景)
說明以下參數與SQL一起執行(優先選擇前兩個參數,若是仍然出現OOM,可以適當調低參數取值)。
-- 設置訪問外部表時的最大并發度,默認為實例的Core數,最大為128,不建議設置大,避免外部表Query(特別是數據導入場景)影響其它Query,導致系統繁忙導致報錯。該參數在Hologres V1.1及以上版本中生效。 SET hg_foreign_table_executor_max_dop = 32; -- 調整每次讀取MaxCompute表batch的大小,默認為8192。 SET hg_experimental_query_batch_size = 4096; -- 設置訪問外部表時執行DML語句的最大并發度,默認值為32,針對數據導入導出場景專門優化的參數,避免導入操作占用過多系統資源,該參數在Hologres V1.1及以上版本中生效。 SET hg_foreign_table_executor_dml_max_dop = 16; -- 設置MaxCompute表訪問切分split的數目,可以調節并發數目,默認64MB,當表很大時需要調大,避免過多的split影響性能。該參數在Hologres V1.1及以上版本中生效。 SET hg_foreign_table_split_size = 128;比較寬的列有比較大的Scan并行度
若是已經調整過大寬表的導入參數,但是仍然出現OOM,可以排查業務是否有比較寬的列,若有可以通過調整以下參數解決。
-- 調整寬列的shuffle并行度,減少寬列數據量的堆積 SET hg_experimental_max_num_record_batches_in_buffer = 32; -- 調整每次讀取MaxCompute表batch的大小,默認8192。 SET hg_experimental_query_batch_size=128;
外部表數據重復
若是外部表包含大量重復數據,會導致導入速度變慢或出現OOM。重復數據是相對而言,并沒有統一標準,例如有1億行數據,有8000萬行數據都是重復的,則認為重復數據較多,請根據實際業務情況進行判斷。
解決方法:導入之前先對數據進行去重再進行導入或者分批次導入,避免一次性導入大量重復數據。