優(yōu)化寫入和更新性能
當(dāng)您Hologres的表數(shù)據(jù)寫入或更新的性能無法達(dá)到業(yè)務(wù)預(yù)期時,可根據(jù)本文提供的寫入瓶頸判斷方法分析其具體原因(上游數(shù)據(jù)讀取較慢,或達(dá)到了Hologres的資源瓶頸等),從而選擇合適的調(diào)優(yōu)手段,幫助業(yè)務(wù)實(shí)現(xiàn)更高的數(shù)據(jù)寫入和更新性能。
背景信息
Hologres是一站式實(shí)時數(shù)據(jù)倉庫引擎,支持海量數(shù)據(jù)高性能實(shí)時寫入與實(shí)時更新,滿足大數(shù)據(jù)場景上對數(shù)據(jù)高性能低延遲的需求,Hologres的寫入技術(shù)原理詳情請參見寫入技術(shù)揭秘。在寫入或更新場景上,Hologres提供多種數(shù)據(jù)寫入和更新的方式,詳情請參見數(shù)據(jù)同步概述。
基本原理
在了解寫入或更新的調(diào)優(yōu)手段前,先了解基本的原理,以幫助業(yè)務(wù)在使用過程中,對不同寫入模式的寫入性能有著更加合理的預(yù)估。
不同表存儲格式的寫入或更新性能。
全列寫入或更新時,性能排序如下。
行存 > 列存 > 行列共存。部分列寫入或更新時,性能排序如下。
行存 > 行列共存 > 列存。
不同寫入模式的性能。
寫入模式類型如下。
寫入模式
說明
Insert
以追加(Append-Only)的方式寫入,結(jié)果表無主鍵(PK)。
InsertOrIgnore
寫入時忽略更新,結(jié)果表有主鍵,實(shí)時寫入時如果主鍵重復(fù),丟棄后到的數(shù)據(jù)。
InsertOrReplace
寫入覆蓋,結(jié)果表有主鍵,實(shí)時寫入時如果主鍵重復(fù),按照主鍵更新。如果寫入的一行數(shù)據(jù)不包含所有列,缺失的列的數(shù)據(jù)補(bǔ)Null。
InsertOrUpdate
寫入更新,結(jié)果表有主鍵,實(shí)時寫入時如果主鍵重復(fù),按照主鍵更新。分為整行更新和部分列更新,部分列更新指如果寫入的一行數(shù)據(jù)不包含所有列,缺失的列不更新。
列存表不同寫入模式的性能排序如下。
結(jié)果表無主鍵性能最高。
結(jié)果表有主鍵時:
InsertOrIgnore > InsertOrReplace >= InsertOrUpdate(整行)> InsertOrUpdate(部分列)。
行存表不同寫入模式的性能排序如下。
InsertOrReplace = InsertOrUpdate(整行)>= InsertOrUpdate(部分列) >= InsertOrIgnore。
開啟Binlog的表寫入或更新性能排序如下。
行存 > 行列共存 > 列存。
寫入瓶頸判斷
在表數(shù)據(jù)寫入或更新時,如果寫入性能慢,可通過查看管理控制臺的CPU使用率監(jiān)控指標(biāo),初步判斷性能瓶頸:
CPU使用率很低。
說明Hologres資源沒有完全用上,性能瓶頸不在Hologres側(cè),可自行排查是否存在上游數(shù)據(jù)讀取較慢等問題。
CPU使用率較高(長期100%)。
說明已經(jīng)達(dá)到了Hologres的資源瓶頸,可以通過如下方法處理。
通過基本調(diào)優(yōu)手段排查是否因基礎(chǔ)設(shè)置不到位導(dǎo)致資源負(fù)載較高,影響寫入性能,詳情請參見基本調(diào)優(yōu)手段。
在基本調(diào)優(yōu)手段已經(jīng)檢查完畢后,可以通過寫入渠道(常見的如Flink、數(shù)據(jù)集成)以及Hologres的高級調(diào)優(yōu)手段,更深層次的判斷是否存在寫入瓶頸,并做相應(yīng)的處理,詳情請參見Flink寫入調(diào)優(yōu)、數(shù)據(jù)集成調(diào)優(yōu)和高級調(diào)優(yōu)手段。
查詢影響寫入,二者共同執(zhí)行會導(dǎo)致資源使用率較高,通過慢Query日志排查同一時間查詢的CPU消耗。若是查詢影響寫入,可以考慮為實(shí)例配置讀寫分離高可用部署,詳情請參見主從實(shí)例讀寫分離部署(共享存儲)。
所有調(diào)優(yōu)手段已操作完畢,但寫入性能仍然不滿足預(yù)期,可適當(dāng)擴(kuò)容Hologres實(shí)例。
基本調(diào)優(yōu)手段
一般情況下Hologres就能達(dá)到非常高的寫入性能,如果在數(shù)據(jù)寫入過程中覺得性能不符合預(yù)期,可以通過以下方法進(jìn)行常規(guī)調(diào)優(yōu)。
避免使用公網(wǎng),減少網(wǎng)絡(luò)開銷。
Hologres提供VPC、經(jīng)典、公網(wǎng)等網(wǎng)絡(luò)類型,適用場景請參見網(wǎng)絡(luò)配置。推薦在進(jìn)行數(shù)據(jù)寫入時,尤其是使用JDBC、PSQL等業(yè)務(wù)應(yīng)用連接Hologres時,盡量使用VPC網(wǎng)絡(luò)連接而不是公網(wǎng)連接。因?yàn)楣W(wǎng)有流量限制,相比VPC網(wǎng)絡(luò)會更加不穩(wěn)定。
盡量使用Fixed Plan寫入。
一個SQL在Hologres中的執(zhí)行流程如下圖所示,詳細(xì)原理請參見執(zhí)行引擎。
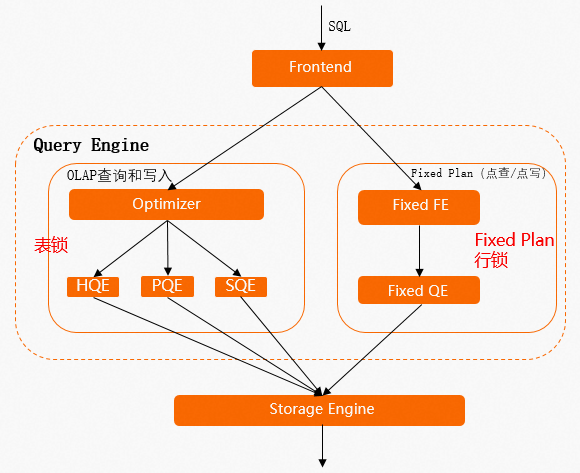
SQL為普通OLAP寫入,那么就會走左側(cè)的鏈路,會經(jīng)過優(yōu)化器(QO)、執(zhí)行引擎(QE)等一系列組件,數(shù)據(jù)寫入或更新時會整個表拿鎖即表鎖,如果是并發(fā)執(zhí)行
INSERT、UPDATE或DELETE命令,那么SQL間會相互等鎖,導(dǎo)致延遲較高。SQL為點(diǎn)查點(diǎn)寫,那么就會走右側(cè)的執(zhí)行鏈路,此鏈路統(tǒng)稱為Fixed Plan。Fixed Plan的Query特征足夠簡單,沒有QO等組件的開銷,因此在寫入或更新時是行鎖,這樣就能極大的提高Query的并發(fā)能力及性能。
因此在優(yōu)化寫入或更新性能時,優(yōu)先考慮讓Query盡量走Fixed Plan。
Query走Fixed Plan
走Fixed Plan的SQL需要符合一定的特征,常見未走Fixed Plan的情形如下。
使用
insert on conflict語法進(jìn)行多行插入更新時,示例如下。INSERT INTO test_upsert(pk1, pk2, col1, col2) VALUES (1, 2, 5, 6), (2, 3, 7, 8) ON CONFLICT (pk1, pk2) DO UPDATE SET col1 = excluded.col1, col2 = excluded.col2;使用
insert on conflict語法進(jìn)行局部更新時,結(jié)果表的列和插入數(shù)據(jù)的列沒有一一對應(yīng)。結(jié)果表中有SERIAL類型的列。
結(jié)果表設(shè)置了
Default屬性。基于主鍵的
update或delete,如:update table set col1 = ?, col2 = ? where pk1 = ? and pk2 = ?;。使用了Fixed Plan不支持的數(shù)據(jù)類型。
如果SQL沒有走Fixed Plan,那么在管理控制臺監(jiān)控指標(biāo)中
實(shí)時導(dǎo)入RPS指標(biāo)則會顯示插入類型為INSERT,示例如下。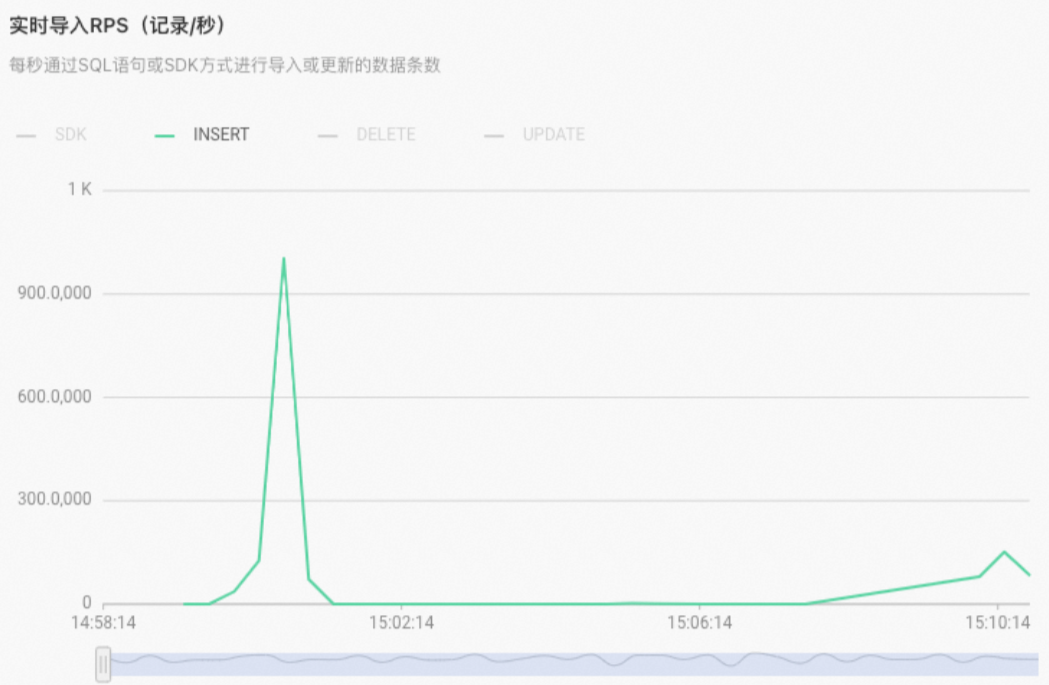 沒有走Fixed Plan的SQL,其執(zhí)行引擎類型為HQE或PQE,大多數(shù)情況的寫入為HQE。因此當(dāng)發(fā)現(xiàn)寫入或更新較慢時,可以通過如下示例語句查看慢Query日志,排查Query的執(zhí)行引擎類型(engine_type)。
沒有走Fixed Plan的SQL,其執(zhí)行引擎類型為HQE或PQE,大多數(shù)情況的寫入為HQE。因此當(dāng)發(fā)現(xiàn)寫入或更新較慢時,可以通過如下示例語句查看慢Query日志,排查Query的執(zhí)行引擎類型(engine_type)。--示例查看過去3小時未走Fixed Plan的insert/update/delete SELECT * FROM hologres.hg_query_log WHERE query_start >= now() - interval '3 h' AND command_tag IN ('INSERT', 'UPDATE', 'DELETE') AND ARRAY['HQE'] && engine_type ORDER BY query_start DESC LIMIT 500;盡量將執(zhí)行引擎類型為HQE的Query改寫為符合Fixed Plan特征的SDK SQL,從而提高性能。重點(diǎn)關(guān)注如下GUC參數(shù),建議DB級別開啟GUC參數(shù),更多關(guān)于Fixed Plan的使用請參見Fixed Plan加速SQL執(zhí)行。
場景
GUC設(shè)置
說明
支持使用
insert on conflict語法多行記錄的Fixed Plan寫入。alter database <databasename> set hg_experimental_enable_fixed_dispatcher_for_multi_values =on;建議DB級別開啟。
支持含有SERIAL類型列的Fixed Plan寫入。
alter database <databasename> set hg_experimental_enable_fixed_dispatcher_autofill_series =on;不建議為表設(shè)置SERIAL類型,對寫入性能有一定的犧牲。Hologres從 V1.3.25版本開始此GUC參數(shù)默認(rèn)為
on。支持Default屬性的列的Fixed Plan寫入。
Hologres從 V1.3版本開始,使用
insert on conflict語法寫入數(shù)據(jù)時含有設(shè)置了Default屬性的字段,則會默認(rèn)走Fixed Plan。不建議為表設(shè)置Default屬性,對寫入性能有一定的犧牲。Hologres V1.1版本不支持含有設(shè)置了Default屬性的字段走Fixed Plan,從V1.3版本開始支持。
基于主鍵的UPDATE。
alter database <databasename> set hg_experimental_enable_fixed_dispatcher_for_update =on;Hologres從 V1.3.25版本開始此GUC參數(shù)值默認(rèn)為
on。基于主鍵的DELETE。
alter database <databasename> set hg_experimental_enable_fixed_dispatcher_for_delete =on;Hologres從 V1.3.25版本開始此GUC參數(shù)值默認(rèn)為
on。如果SQL走了Fixed Plan,如下圖所示監(jiān)控指標(biāo)
實(shí)時導(dǎo)入RPS的類型為SDK。并且在慢Query日志中SQL的engine_type也為SDK。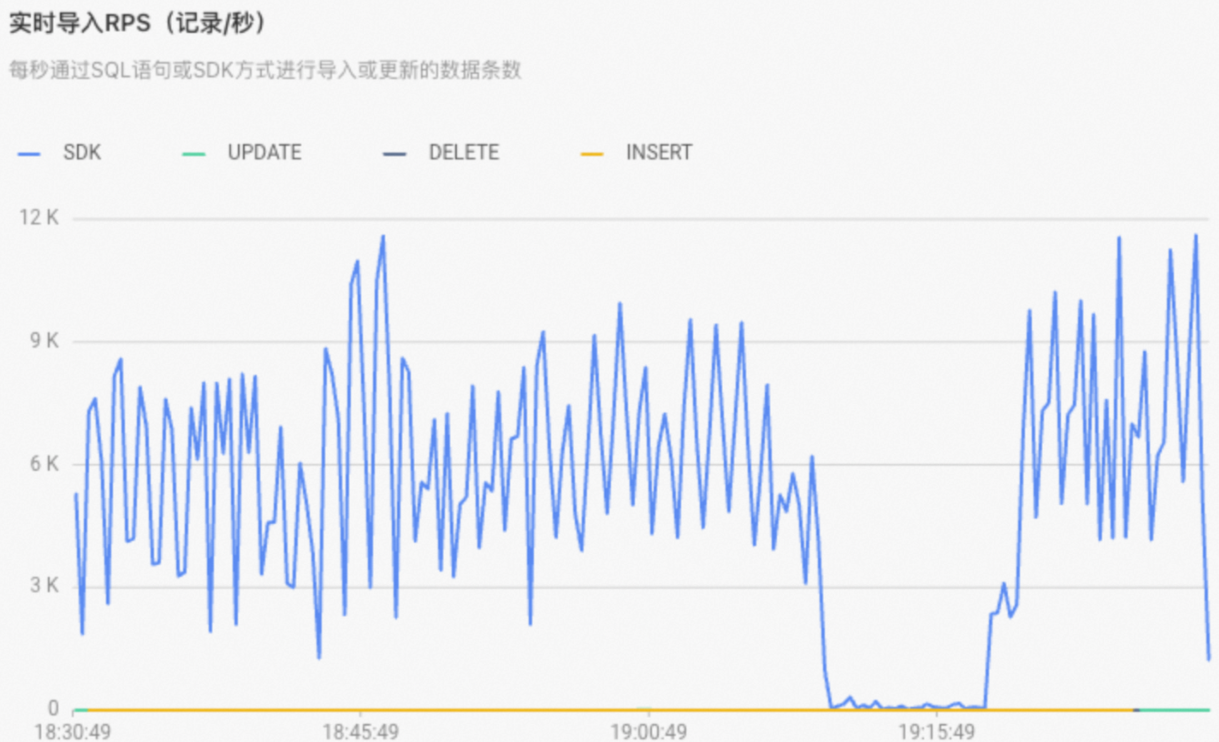
走了Fixed Plan后寫入仍然比較慢。
SQL已經(jīng)走了Fixed Plan仍然耗時較長,可能原因如下。
通常情況是該表既有Fixed Plan的SDK寫入或更新,又有HQE的寫入或更新,HQE是表鎖,會導(dǎo)致SDK的寫入因?yàn)榈孺i而耗時較長。可以通過以下SQL查詢當(dāng)前表是否有HQE的操作,并根據(jù)業(yè)務(wù)情況優(yōu)化為SDK的SQL。可以通過HoloWeb Query洞察快速識別出某個Fixed Plan的Query是否有HQE的鎖,詳情請參見Query洞察。
--查詢表在過去3小時未走Fixed Plan的insert/update/delete SELECT * FROM hologres.hg_query_log WHERE query_start >= now() - interval '3 h' AND command_tag IN ('INSERT', 'UPDATE', 'DELETE') AND ARRAY['HQE'] && engine_type AND table_write = '<table_name>' ORDER BY query_start DESC LIMIT 500;如果表都是SDK寫入,但仍然慢,觀察
CPU使用率監(jiān)控指標(biāo),若是持續(xù)較高,可能已經(jīng)達(dá)到實(shí)例資源瓶頸,可適當(dāng)進(jìn)行擴(kuò)容。
開啟Binlog會降低寫入吞吐。
Hologres Binlog記錄了數(shù)據(jù)變更記錄(INSERT、UPDATE、DELETE),會完整的記錄每行數(shù)據(jù)的變更情況。為某張表打開Binlog,以UPDATE語句為例,示例SQL如下:
update tbl set body =new_body where id='1';由于Binlog記錄的是整行所有字段的數(shù)據(jù),因此在生成Binlog的過程中,需要通過過濾字段(示例中的
id字段)去點(diǎn)查目標(biāo)表的整行數(shù)據(jù)。如果是列存表的話,這種點(diǎn)查SQL相比行存表會消耗更多的資源,因此開啟Binlog的表在寫入性能上行存表 > 列存表。同一張表避免并發(fā)實(shí)時和離線寫入。
離線寫入如MaxCompute寫入Hologres時是表鎖,實(shí)時寫入大多數(shù)是Fixed Plan寫入為行鎖(例如Flink實(shí)時寫入或者DataWorks數(shù)據(jù)集成實(shí)時寫入),如果對同一個表并發(fā)執(zhí)行離線寫入和實(shí)時寫入,那么離線寫入就會拿表鎖,實(shí)時寫入會因?yàn)榈孺i而導(dǎo)致寫入性能慢。所以建議同一張表避免并發(fā)進(jìn)行實(shí)時和離線寫入。
Holo Client或JDBC寫入調(diào)優(yōu)
Holo Client、JDBC等客戶端在寫入數(shù)據(jù)時,提高寫入性能的調(diào)優(yōu)手段如下。
攢批寫入數(shù)據(jù)。
在通過客戶端寫入時,攢批寫入相比單條寫入能夠提供更高的吞吐,從而提升寫入性能。
使用Holo Client會自動攢批,建議使用Holo Client默認(rèn)配置參數(shù),詳情請參見通過Holo Client讀寫數(shù)據(jù)。
使用JDBC時可以在JDBC連接串配置
WriteBatchedInserts=true,如下所示則可實(shí)現(xiàn)攢批的功能,更多JDBC詳情請參見JDBC。jdbc:postgresql://{ENDPOINT}:{PORT}/{DBNAME}?ApplicationName={APPLICATION_NAME}&reWriteBatchedInserts=true
未攢批的SQL改造成可攢批的SQL示例如下。
--未攢批的兩個sql insert into data_t values (1, 2, 3); insert into data_t values (2, 3, 4); --攢批后的sql insert into data_t values (1, 2, 3), (4, 5, 6); --攢批的另一種寫法 insert into data_t select unnest(ARRAY[1, 4]::int[]), unnest(ARRAY[2, 5]::int[]), unnest(ARRAY[3, 6]::int[]);使用Prepared Statement模式寫入數(shù)據(jù)。
Hologres兼容PostgreSQL生態(tài),并基于Postgres的extended協(xié)議,支持了Prepared Statement模式,會緩存服務(wù)器的SQL編譯結(jié)果,從而降低了FE、QO等組件的開銷,提高寫入的性能。相關(guān)技術(shù)原理請參見如何支持超高QPS在線服務(wù)(點(diǎn)查)場景。
JDBC、Holo Client使用Prepared Statement模式寫入數(shù)據(jù)請參見JDBC。
Flink寫入調(diào)優(yōu)
各類型表的注意事項(xiàng)如下。
Binlog源表
Flink消費(fèi)Hologres Binlog支持的數(shù)據(jù)類型有限,對不支持的數(shù)據(jù)類型(如SMALLINT)即使不消費(fèi)此字段,仍然可能導(dǎo)致作業(yè)無法上線。從Flink引擎VVR-6.0.3-Flink-1.15 版本開始,支持通過JDBC模式消費(fèi)Hologres Binlog,此模式下支持更多數(shù)據(jù)類型,詳情請參見Flink全托管。
開啟Binlog的Hologres表建議使用行存表。列存表開啟Binlog會使用較多的資源,影響寫入性能。
維表
維表必須使用行存表或行列共存表,列存表對于點(diǎn)查場景性能開銷較大。
創(chuàng)建行存表時必須設(shè)置主鍵,并且將主鍵配置為Clustering Key時性能較好。
維表的主鍵必須是Flink Join ON的字段,F(xiàn)link Join ON的字段也必須是表的完整主鍵,兩者必須完全匹配。
結(jié)果表
寬表Merge或局部更新功能對應(yīng)的Hologres表必須有主鍵,且每個結(jié)果表都必須聲明和寫入主鍵字段,必須使用
InsertOrUpdate的寫入模式。每個結(jié)果表的ignoredelete屬性都必須設(shè)置為true,防止回撤消息產(chǎn)生Delete請求。列存表的寬表Merge場景在高RPS的情況下,CPU使用率會偏高,建議關(guān)閉表中字段的
Dictionary Encoding。結(jié)果表有主鍵場景,建議設(shè)置
segment_key,可以在寫入和更新時快速定位到數(shù)據(jù)所在的底層文件。推薦使用時間戳、日期等字段作為segment_key,并且在寫入時使對應(yīng)字段的數(shù)據(jù)與寫入時間有強(qiáng)相關(guān)性。
Flink參數(shù)配置建議。
Hologres Connector各參數(shù)的默認(rèn)值是大多數(shù)情況下的最佳配置。如果出現(xiàn)以下情況,可以酌情修改參數(shù)。
Binlog消費(fèi)延遲比較高:
默認(rèn)讀取Binlog批量大小(
binlogBatchReadSize)為100,如果單行數(shù)據(jù)的byte size并不大,可以增加此參數(shù),可以優(yōu)化消費(fèi)延遲。維表點(diǎn)查性能較差:
設(shè)置
async參數(shù)為true開啟異步模式。此模式可以并發(fā)地處理多個請求和響應(yīng),從而連續(xù)的請求之間不需要阻塞等待,提高查詢的吞吐。但在異步模式下,無法保證請求的絕對順序。有關(guān)異步請求的原理請參見維表JOIN與異步優(yōu)化。維表數(shù)據(jù)量較大且更新不頻繁時,推薦使用維表緩存優(yōu)化查詢性能。相應(yīng)參數(shù)設(shè)置為
cache = 'LRU',同時默認(rèn)的cacheSize較保守,為10000行,推薦根據(jù)實(shí)際情況調(diào)大一些。
連接數(shù)不足:
connector默認(rèn)使用JDBC方式實(shí)現(xiàn),如果Flink作業(yè)較多,可能會導(dǎo)致Hologres的連接數(shù)不足,此時可以使用connectionPoolName參數(shù)實(shí)現(xiàn)同一個TaskManager中,連接池相同的表可以共享連接。
作業(yè)開發(fā)推薦。
Flink SQL相對DataStream來說,可維護(hù)性高且可移植性強(qiáng),因此推薦使用Flink SQL來實(shí)現(xiàn)作業(yè)。如果業(yè)務(wù)需要使用DataStream,更推薦使用Hologres DataStream Connector,詳情請參見Hologres DataStream Connector。如果需要開發(fā)自定義Datastream作業(yè),則推薦使用Holo Client而不是JDBC,即推薦使用的作業(yè)開發(fā)方式排序?yàn)椋?span data-tag="ph" id="codeph-dir-sng-1kg" class="ph">
Flink SQL > Flink DataStream(connector) > Flink DataStream(holo-client) > Flink DataStream(JDBC)。寫入慢的原因排查。
很多情況下,寫入慢也可能是Flink作業(yè)中其他步驟的問題。您可以拆分Flink作業(yè)的節(jié)點(diǎn),并觀察Flink作業(yè)的反壓情況,是否在讀數(shù)據(jù)源或一些復(fù)雜的計算節(jié)點(diǎn)已經(jīng)反壓,數(shù)據(jù)進(jìn)入到Hologres結(jié)果表的速率已經(jīng)很慢,此時優(yōu)先排查Flink側(cè)是否有可以優(yōu)化的地方。
如果Hologres實(shí)例的CPU使用率很高(如長時間達(dá)到100%),寫入延遲也比較高,則可以考慮是Hologres側(cè)的問題。
其他常見異常信息和排查方法請參見Blink和Flink常見問題及診斷。
數(shù)據(jù)集成調(diào)優(yōu)
并發(fā)配置與連接的關(guān)系。
數(shù)據(jù)集成中非腳本模式作業(yè)的連接數(shù)為每個并發(fā)三個連接,腳本模式作業(yè)可通過
maxConnectionCount參數(shù)配置任務(wù)的總連接數(shù),或者insertThreadCount參數(shù)配置單并發(fā)的連接數(shù)。一般情況下,無需修改并發(fā)和連接數(shù)就能達(dá)到很好的性能,可根據(jù)實(shí)際業(yè)務(wù)情況適當(dāng)修改。獨(dú)享資源組。
數(shù)據(jù)集成大部分作業(yè)都需要使用獨(dú)享資源組,因此獨(dú)享資源組的規(guī)格也決定著任務(wù)的性能上限。 為了保證性能,推薦作業(yè)一個并發(fā)對應(yīng)獨(dú)享資源組1 Core。 如果資源組規(guī)格過小,但任務(wù)并發(fā)高可能會存在JVM內(nèi)存不足等問題。同樣的如果獨(dú)享資源組的帶寬打滿也會影響寫入任務(wù)的性能上限,如果發(fā)生此現(xiàn)象,建議對任務(wù)進(jìn)行拆解,把大任務(wù)拆成小任務(wù)并分配到不同的資源組上。關(guān)于數(shù)據(jù)集成獨(dú)享資源組的規(guī)格指標(biāo)請參見性能指標(biāo)。
寫入慢時如何排查是數(shù)據(jù)集成或上游慢還是Hologres側(cè)的問題?
數(shù)據(jù)集成寫Hologres時,如果數(shù)據(jù)集成讀端的等待時間比寫端的等待時間大,通常情況是讀端慢導(dǎo)致。
如果Hologres實(shí)例的CPU使用率很高(如長時間達(dá)到100%),寫入延遲也比較高,則可以考慮是Hologres側(cè)的問題。
高級調(diào)優(yōu)手段
基本調(diào)優(yōu)手段已經(jīng)覆蓋提升寫入性能的基本方法,若是使用正確就能達(dá)到很好的寫入性能。但是在實(shí)際情況中,還有一些其他因素影響性能,比如索引的設(shè)置、數(shù)據(jù)的分布等,高級調(diào)優(yōu)將會介紹在基本調(diào)優(yōu)手段的基礎(chǔ)上,如何進(jìn)一步的排查并提升寫入性能,適用于對Hologres原理有進(jìn)一步了解的業(yè)務(wù)。
數(shù)據(jù)傾斜導(dǎo)致寫入慢。
如果數(shù)據(jù)傾斜或Distribution Key設(shè)置的不合理,就會導(dǎo)致Hologres實(shí)例的計算資源出現(xiàn)傾斜,導(dǎo)致資源無法高效使用從而影響寫入性能,排查數(shù)據(jù)傾斜和對應(yīng)問題解決方法請參見查看Worker傾斜關(guān)系。
Segment Key設(shè)置不合理導(dǎo)致寫入慢。
寫入列存表時,設(shè)置了不合理的Segment Key可能會極大的影響寫入性能,表已有數(shù)據(jù)量越多性能下降越明顯。這是因?yàn)镾egment Key用于底層文件分段,在寫入或更新時Hologres會根據(jù)主鍵反查對應(yīng)的舊數(shù)據(jù),列存表的反查操作需要通過Segment Key快速定位到數(shù)據(jù)所在的底層文件。如果這張列存表沒有配置Segment Key或者Segment Key配置了不合理的字段或者Segment Key對應(yīng)的字段在寫入時沒有與時間有強(qiáng)相關(guān)性(比如基本亂序),那反查時需要掃描的文件將會非常之多,不僅會有大量的IO操作,而且也可大量占用CPU,影響寫入性能和整個實(shí)例的負(fù)載。此時管控臺監(jiān)控頁面的
IO吞吐指標(biāo)往往表現(xiàn)為即使主要是寫入作業(yè),其Read指標(biāo)也非常高。因此推薦使用時間戳、日期等字段作為Segment Key,并且在寫入時使對應(yīng)字段的數(shù)據(jù)與寫入時間有強(qiáng)相關(guān)性。
Clustering Key設(shè)置不合理導(dǎo)致寫入慢
有主鍵(PK)的情況下,在寫入或更新時,Hologres會根據(jù)主鍵反查對應(yīng)的舊數(shù)據(jù)。
對于行存表來說,當(dāng)Clustering Key與PK不一致時,反查就會需要反查兩次,即分別按照PK索引和Clustering Key索引,這種行為會增加寫入的延時,所以對于行存表推薦Clustering Key和PK保持一致。
對于列存表,Clustering Key的設(shè)置主要會影響查詢性能,不會影響寫入性能,可以暫不考慮。