數(shù)據(jù)同步概述
實時數(shù)倉Hologres是一款兼容PostgreSQL 11協(xié)議的實時數(shù)倉,與大數(shù)據(jù)生態(tài)無縫連接,支持高并發(fā)地實時寫入,數(shù)據(jù)寫入即可查,同時也支持離線數(shù)據(jù)的加速查詢、實時數(shù)據(jù)和離線數(shù)據(jù)聯(lián)邦分析,助力快速搭建企業(yè)級實時數(shù)倉。
Hologres數(shù)據(jù)同步說明
Hologres有著非常龐大的生態(tài)家族,支持多種異構(gòu)數(shù)據(jù)源的離線、實時寫入。
對于開源大數(shù)據(jù):Hologres支持當(dāng)下最流行的大數(shù)據(jù)開源組件,其中包括Flink、Blink和Spark等,通過內(nèi)置的Hologres Connector實現(xiàn)高并發(fā)實時寫入。
對于數(shù)據(jù)庫類數(shù)據(jù):Hologres與DataWorks數(shù)據(jù)集成(DataX和StreamX)深度集成,支持通過Hologres Writer和Hologres Reader,實現(xiàn)方便高效地將多種數(shù)據(jù)庫數(shù)據(jù)離線、實時、整庫同步至Hologres中,滿足各類企業(yè)數(shù)據(jù)同步遷移的需求。
無論是實時數(shù)據(jù),還是離線數(shù)據(jù),同步至Hologres之后就能使用Hologres對數(shù)據(jù)進(jìn)行多維分析,例如通過JDBC或者ODBC對數(shù)據(jù)進(jìn)行查詢、分析、監(jiān)控,然后直接承接上游的業(yè)務(wù)例如大屏、報表、應(yīng)用等可視化展現(xiàn),實現(xiàn)數(shù)據(jù)從寫入到服務(wù)分析一體化。具體使用流程如下所示: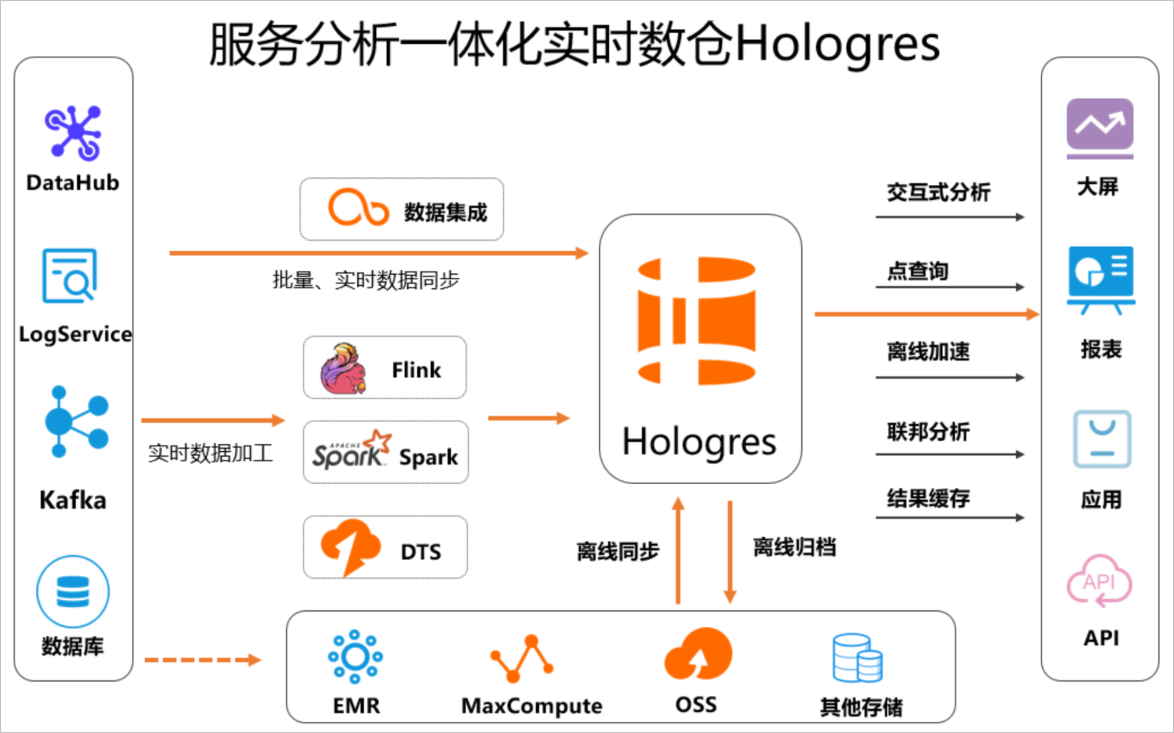
常見同步方案
常見數(shù)據(jù)源同步數(shù)據(jù)至Hologres的同步方式支持情況如下表所示,您可以根據(jù)業(yè)務(wù)情況選擇合適的同步方式。
常見數(shù)據(jù)源 | Hologres內(nèi)置同步方案 | DataWorks數(shù)據(jù)集成方式同步數(shù)據(jù) | Flink方式同步數(shù)據(jù) |
MaxCompute | 支持(推薦,SQL命令) | 支持 | 支持 |
OSS | 支持(推薦,SQL命令) | 支持 | 不支持 |
本地文件 | 支持(Copy命令) | 不支持 | 不支持 |
MySQL等數(shù)據(jù)庫 | 不支持 | 支持(推薦) | 支持 |
Kafka | 不支持 | 支持 | 支持 |
DataHub | 支持(Hologres數(shù)據(jù)源直接寫入) | 支持 | 支持 |
開源Connector支持
Hologres支持豐富的同步Connector如下表所示,并且這些Connector已經(jīng)開源,請您根據(jù)業(yè)務(wù)情況自行選用。
Connector名稱 | 適用場景 |
適用于大批量數(shù)據(jù)寫入(批量、實時同步至Hologres)和高QPS點查(維表關(guān)聯(lián))場景,基于JDBC實現(xiàn),也提供C語言和GO語言版本。 | |
將實例部分表導(dǎo)入導(dǎo)出的備份工具,適用于實例遷移或者數(shù)據(jù)庫數(shù)據(jù)遷移的場景,也可以dump至中間存儲再恢復(fù)。 | |
適配開源DataX,依賴DataX框架,適用開源DataX將多種數(shù)據(jù)源寫入Hologres,相比PostgreSQL Writer性能更好。 | |
對接開源Flink,F(xiàn)link版本包括1.11、1.12、1.13以及后續(xù)版本,實現(xiàn)高性能實時寫入。 說明 阿里云Flink支持Hologres數(shù)據(jù)源,可以直接寫入,無需引用connector。 | |
適用于Kafka直接寫入Hologres的場景。 | |
適用于Spark(社區(qū)版以及阿里云EMR Spark版)寫入Hologres的場景,支持Spark2.x、3.x及以上版本,提供高性能的寫入。 | |
適用于Hive寫入Hologres的場景,支持Hive2.x、3.x及以上版本,提供高性能的寫入。 |