本文基于Alpaca提供了一套LLaMA-7B模型在阿里云ECS上進行指令微調的訓練方案,最終可以獲得性能更貼近具體使用場景的語言模型。
背景信息
LLaMA(Large Language Model Meta AI )是Meta AI在2023年2月發布的開放使用預訓練語言模型(Large Language Model, LLM),其參數量包含7B到65B的集合,并僅使用完全公開的數據集進行訓練。LLaMA的訓練原理是將一系列單詞作為“輸入”并預測下一個單詞以遞歸生成文本。
LLM具有建模大量詞語之間聯系的能力,但是為了讓其強大的建模能力向下游具體任務輸出,需要進行指令微調,根據大量不同指令對模型部分權重進行更新,使模型更善于遵循指令。指令微調中的指令簡單直觀地描述了任務,具體的指令格式如下:
{
"instruction": "Given the following input, find the missing number",
"input": "10, 12, 14, __, 18",
"output": "16"
}Alpaca是一個由LLaMA-7B模型進行指令微調得到的模型,其訓練過程中采用的通過指令對LLaMA-7B模型進行小規模權重更新的方式,實現了模型性能和訓練時間的平衡。
本文基于Alpaca提供了一套LLaMA-7B模型,基于DeepSpeed進行指令微調訓練,并使用AIACC加速訓練。AIACC包括ACSpeed和AGSpeed兩個加速器。
加速器 | 說明 | 相關文檔 |
ACSpeed | AIACC-ACSpeed(簡稱ACSpeed)是阿里云自研的AI訓練加速器,在AI框架層、集合算法層和網絡層上分別實現了與開源主流分布式框架的充分兼容,并實現了軟硬件結合的全面優化。ACSpeed具有其顯著的性能優勢,在提高訓練效率的同時能夠降低使用成本,可以實現無感的分布式通信性能優化。 | |
AGSpeed | AIACC-AGSpeed(簡稱AGSpeed)是阿里云推出的一個基于PyTorch深度學習框架研發的計算優化編譯器,用于優化PyTorch深度學習模型在阿里云GPU異構計算實例上的計算性能,可以實現計算優化。 |
阿里云不對第三方模型“llama-7b-hf”的合法性、安全性、準確性進行任何保證,阿里云不對由此引發的任何損害承擔責任。
您應自覺遵守第三方模型的用戶協議、使用規范和相關法律法規,并就使用第三方模型的合法性、合規性自行承擔相關責任。
操作步驟
準備工作
操作前,請先在合適的地域和可用區下創建VPC和交換機。
本文使用ecs.gn7i-c32g1.32xlarge規格的ECS實例進行訓練,僅部分地域可用區支持該實例規格,具體請參見ECS實例規格可購買地域。
創建ECS實例
控制臺方式
前往實例創建頁。
按照向導完成參數配置,創建一臺ECS實例。
需要注意的參數如下。更多信息,請參見自定義購買實例。
實例:規格選擇ecs.gn7i-c32g1.32xlarge(包含4卡NVIDIA A10 GPU)。
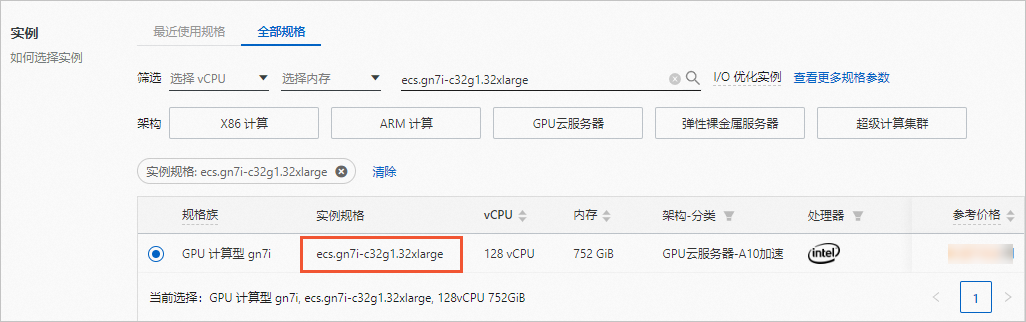
鏡像:使用云市場鏡像,名稱為aiacc-train-solution,該鏡像已部署好訓練所需環境。您可以直接通過名稱搜索該鏡像,版本可選擇最新版本。
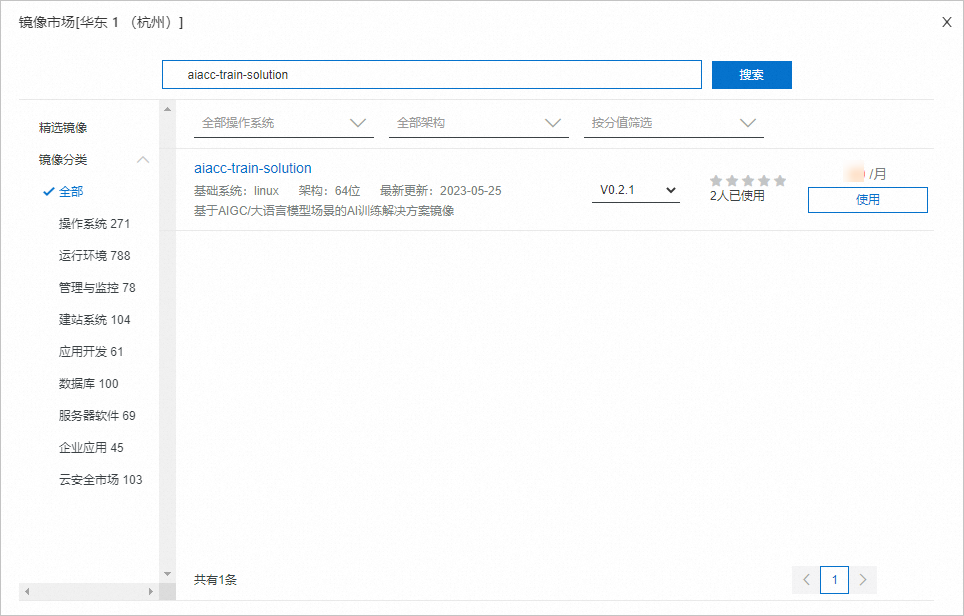 說明
說明您也可以選擇公共鏡像(如CentOS 7.9 64位),后續手動部署環境。
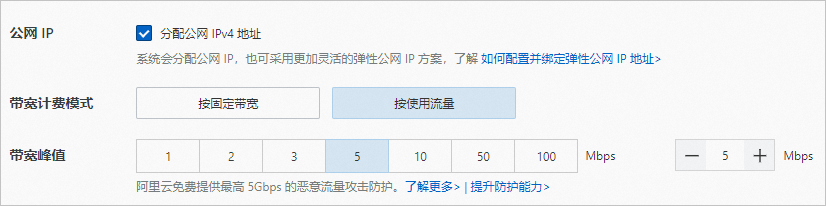
公網IP:選中分配公網IPv4地址,按需選擇計費模式和帶寬。本文使用按流量計費,帶寬峰值為5 Mbps。
添加安全組規則。
在ECS實例所需安全組的入方向添加一條規則,開放7860端口,用于訪問WebUI。具體操作,請參見添加安全組規則。
以下示例表示向所有網段開放7860端口,開放后所有公網IP均可訪問您的WebUI。您可以根據需要將授權對象設置為特定網段,僅允許部分IP地址訪問WebUI。

使用Workbench連接實例。
如果使用示例的云市場鏡像進行測試,由于環境安裝在
/root目錄下,連接實例時需使用root用戶。關于如何連接ECS實例,請參見通過密碼或密鑰認證登錄Linux實例。
FastGPU方式
FastGPU方式僅支持在Linux系統或macOS系統中使用。如果您使用Windows系統,請采用控制臺方式。
安裝FastGPU軟件包并配置環境變量。
安裝FastGPU軟件包。
pip3 install --force-reinstall https://ali-perseus-release.oss-cn-huhehaote.aliyuncs.com/fastgpu/fastgpu-1.1.6-py3-none-any.whl配置環境變量。
配置環境變量前,請獲取阿里云賬號AccessKey(AccessKey ID和AccessKey Secret),以及您希望創建ECS實例的地域等信息。關于如何獲取AccessKey,請參見創建AccessKey。
export ALIYUN_ACCESS_KEY_ID=**** #填入您的AccessKey ID export ALIYUN_ACCESS_KEY_SECRET=**** #填入您的AccessKey Secret export ALIYUN_DEFAULT_REGION=cn-beijing #填入您希望使用的地域(Region)
創建一臺ECS實例。
命令示例如下,表示創建一臺名為aiacc_solution的ECS實例,實例規格為ecs.gn7i-c32g1.32xlarge,鏡像類型為aiacc_train_solution。
說明本文使用云市場的aiacc-train-solution鏡像作為示例,該鏡像已部署好訓練所需環境。您也可以選擇公共鏡像(如CentOS 7.9 64位),后續手動部署環境。
fastgpu create --name aiacc_solution -i ecs.gn7i-c32g1.32xlarge --machines 1 --image_type aiacc_train_solution添加安全組規則。
添加本機公網IP的22端口到默認安全組中。
fastgpu addip -a開放7860端口,用于訪問WebUI。
以下命令示例表示向所有網段開放7860端口,開放后所有公網IP均可訪問您的WebUI。您可以根據需要將
0.0.0.0/0改為特定網段,僅允許部分IP地址訪問WebUI。fastgpu addip {aiacc_solution} 0.0.0.0/0 7860
通過SSH連接ECS實例。
您可以通過
fastgpu ssh {instance_name}命令連接ECS實例。示例如下:fastgpu ssh aiacc_solution
更多關于FastGPU的命令,請參見命令行使用說明。
(可選)手動部署環境
創建ECS實例時,如果您使用的是已部署好訓練所需環境的云市場鏡像,則可以跳過此步驟。如果您使用的是公共鏡像,需要手動部署環境。
部署訓練所需環境。
安裝devtoolset。
mkdir /root/LLaMA && cd /root/LLaMA yum install -y ninja-build centos-release-scl devtoolset-7 git-lfs source /opt/rh/devtoolset-7/enable echo "source /opt/rh/devtoolset-7/enable" >> /etc/bashrc;拉取代碼。
配置git。
git config --unset --global https.proxy git config --unset --global http.proxy拉取stanford_alpaca。
git clone https://github.com/tatsu-lab/stanford_alpaca.git
安裝Conda。
wget https://repo.anaconda.com/miniconda/Miniconda3-py39_23.1.0-1-Linux-x86_64.sh sh Miniconda3-py39_23.1.0-1-Linux-x86_64.sh安裝后執行
source ~/.bashrc生效環境變量,如果命令行前綴出現(base)表示已啟動Conda。創建Conda虛擬環境。
conda create -n llama_train python=3.9 conda activate llama_train pip install torch==1.13.1+cu117 torchvision==0.14.1+cu117 torchaudio==0.13.1 --extra-index-url https://download.pytorch.org/whl/cu117 pip install deepspeed==0.8.3 pip install protobuf==3.19.0 pip install accelerate cd stanford_alpaca pip install -r requirements.txt安裝pdsh。
wget https://storage.googleapis.com/google-code-archive-downloads/v2/code.google.com/pdsh/pdsh-2.29.tar.bz2 tar -jxvf pdsh-2.29.tar.bz2 cd pdsh-2.29 ./configure --with-ssh --with-rsh --with-mrsh--with-mqshell --with-qshell --with-dshgroups--with-machines=/etc/pdsh/machines --without-pam make make install cd ..
使用AIACC加速訓練。
安裝AIACC。
wget https://ali-perseus-release.oss-cn-huhehaote.aliyuncs.com/aiacc/aiacc-1.1.0.tar.gz pip install aiacc-1.1.0.tar.gz使用AIACC。
以本方案為例,需要在訓練文件train.py(默認在
/root/LLaMA/stanford_alpaca目錄下)中加入以下代碼:import torch import aiacc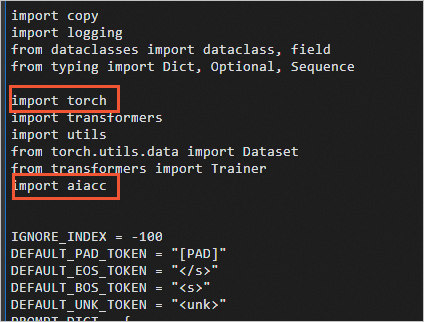 說明
說明AIACC默認開啟,如果想要關閉AIACC,可以執行
export AIACC_DISABLE=1設置環境變量。關閉后如果想要重新開啟AIACC,可以執行unset AIACC_DISABLE重新開啟。
安裝WebUI。
cd /root/LLaMA git clone https://github.com/oobabooga/text-generation-webui cd text-generation-webui git reset --hard 7ff645899e4610b16574bdd22a4d154c93d5b830 pip install -r requirements.txt
啟動訓練
下載tmux并創建一個tmux session。
yum install tmux tmux說明訓練耗時較長,建議在tmux session中啟動訓練,以免ECS斷開連接導致訓練中斷。
進入Conda環境。
conda activate llama_train獲取llama-7b-hf預訓練權重。
下載llama-7b權重。
cd /root/LLaMA git lfs install git clone https://huggingface.co/decapoda-research/llama-7b-hf修復官方代碼Bug。
sed -i "s/LLaMATokenizer/LlamaTokenizer/1" ./llama-7b-hf/tokenizer_config.json
創建并設置DeepSpeed配置文件。
cd LLaMA/stanford_alpacacat << EOF | sudo tee ds_config.json { "zero_optimization": { "stage": 3, "contiguous_gradients": true, "stage3_max_live_parameters": 0, "stage3_max_reuse_distance": 0, "stage3_prefetch_bucket_size": 0, "stage3_param_persistence_threshold": 1e2, "reduce_bucket_size": 1e2, "sub_group_size": 1e8, "offload_optimizer": { "device": "cpu", "pin_memory": true }, "offload_param": { "device": "cpu", "pin_memory": true }, "stage3_gather_16bit_weights_on_model_save": true }, "communication":{ "prescale_gradients": true }, "fp16": { "enabled": true, "auto_cast": false, "loss_scale": 0, "initial_scale_power": 32, "loss_scale_window": 1000, "hysteresis": 2, "min_loss_scale": 1 }, "train_batch_size": "auto", "train_micro_batch_size_per_gpu": "auto", "wall_clock_breakdown": false, "zero_force_ds_cpu_optimizer": false } EOF(可選)如果使用多臺ECS實例進行訓練,需配置hostfile。
本文使用一臺ECS實例進行訓練,可跳過此步驟。
如下示例表示配置兩臺ECS實例(GPU總數為8)時,需要填入每臺ECS實例的內網IP和slots,其中slots表示進程數(即GPU數量)。
cat > hostfile <<EOF {private_ip1} slots=4 {private_ip2} slots=4 EOF啟動訓練。
啟動訓練的命令腳本如下,alpaca_data.json為指令數據集文件,
$MASTER_PORT請替換為2000-65535之間的隨機端口號。deepspeed --master_port=$MASTER_PORT --hostfile hostfile \ train.py \ --model_name_or_path ../llama-7b-hf \ --data_path ./alpaca_data.json \ --output_dir ./output \ --report_to none \ --num_train_epochs 1 \ --per_device_train_batch_size 2 \ --per_device_eval_batch_size 2 \ --gradient_accumulation_steps 8 \ --evaluation_strategy "no" \ --save_strategy "steps" \ --save_steps 400 \ --save_total_limit 2 \ --learning_rate 2e-5 \ --weight_decay 0. \ --warmup_ratio 0.03 \ --lr_scheduler_type "cosine" \ --logging_steps 1 \ --deepspeed ./ds_config.json \ --tf32 False \ --bf16 False \ --fp16啟動訓練后預期返回如下:
 說明
說明訓練完成大概需要7小時左右,在tmux session中進行訓練的過程中,如果斷開了ECS連接,重新登錄ECS實例后執行
tmux attach命令即可恢復tmux session,查看訓練進度。
效果展示
查看WebUI推理效果
查看原生預訓練模型的推理效果。
進入Conda環境。
conda activate llama_train使用原生checkpoint文件進行推理。
cd /root/LLaMA/text-generation-webui ln -s /root/LLaMA/llama-7b-hf ./models/llama-7b-hf啟動WebUI服務。
python /root/LLaMA/text-generation-webui/server.py --model llama-7b-hf --listen預期返回:

打開本地瀏覽器,訪問ECS實例的公網IP地址加7860端口,如
101.200.XX.XX:7860。在Input框中輸入問題(建議輸入英語),單擊Generate,在Output框獲取結果。
原生的預訓練模型不能很好理解指令。示例如下:
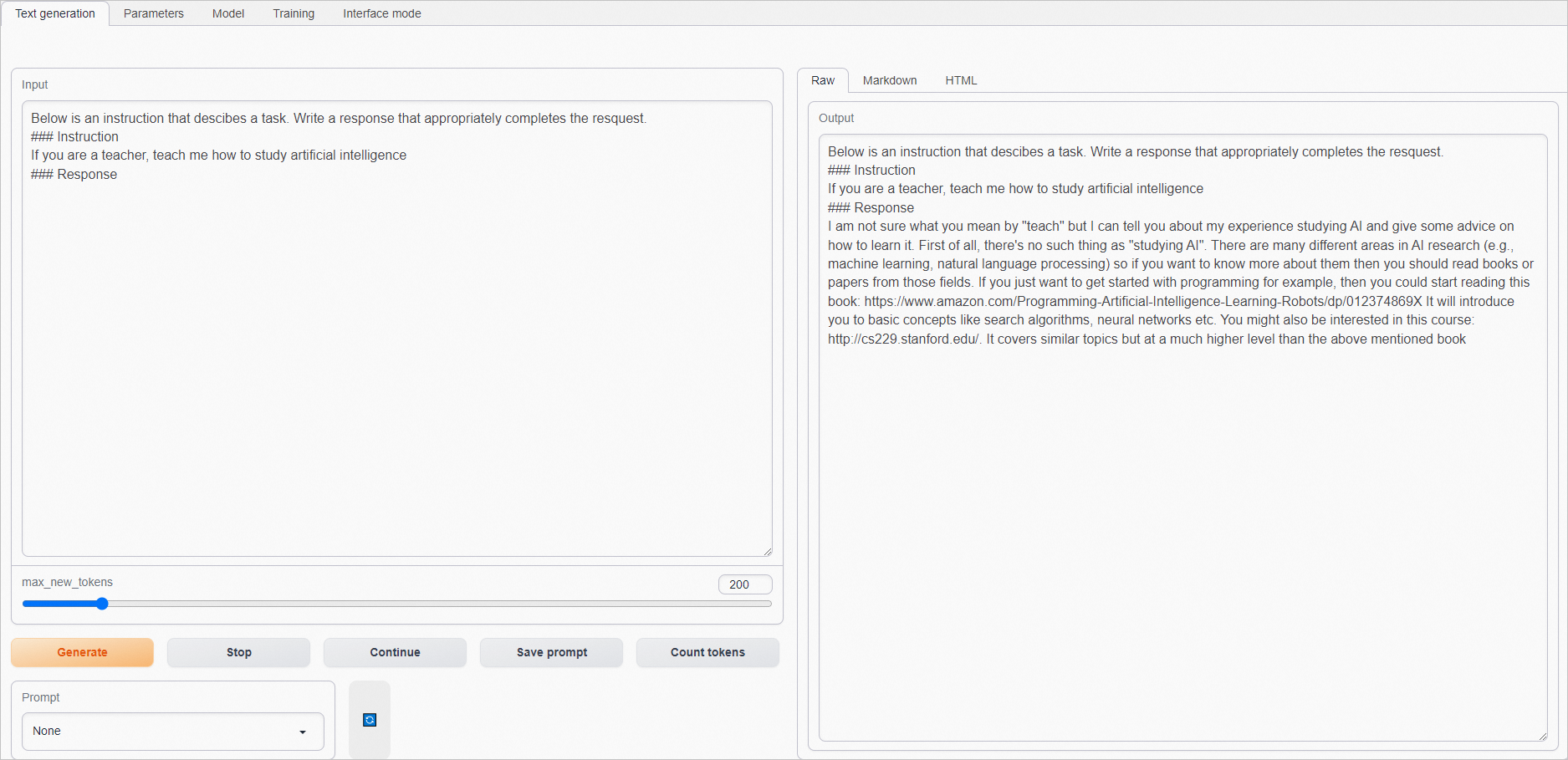
等待訓練完成后,查看指令微調后模型的推理效果。
重新連接ECS實例。
進入Conda環境。
conda activate llama_train使用訓練完成的checkpoint文件進行推理。
cd /root/LLaMA/text-generation-webui ln -s /root/LLaMA/stanford_alpaca/output/checkpoint-800 ./models/llama-7b-hf-800啟動WebUI服務。
python /root/LLaMA/text-generation-webui/server.py --model llama-7b-hf-800 --listen預期返回:

打開本地瀏覽器,訪問ECS實例的公網IP地址加7860端口,如
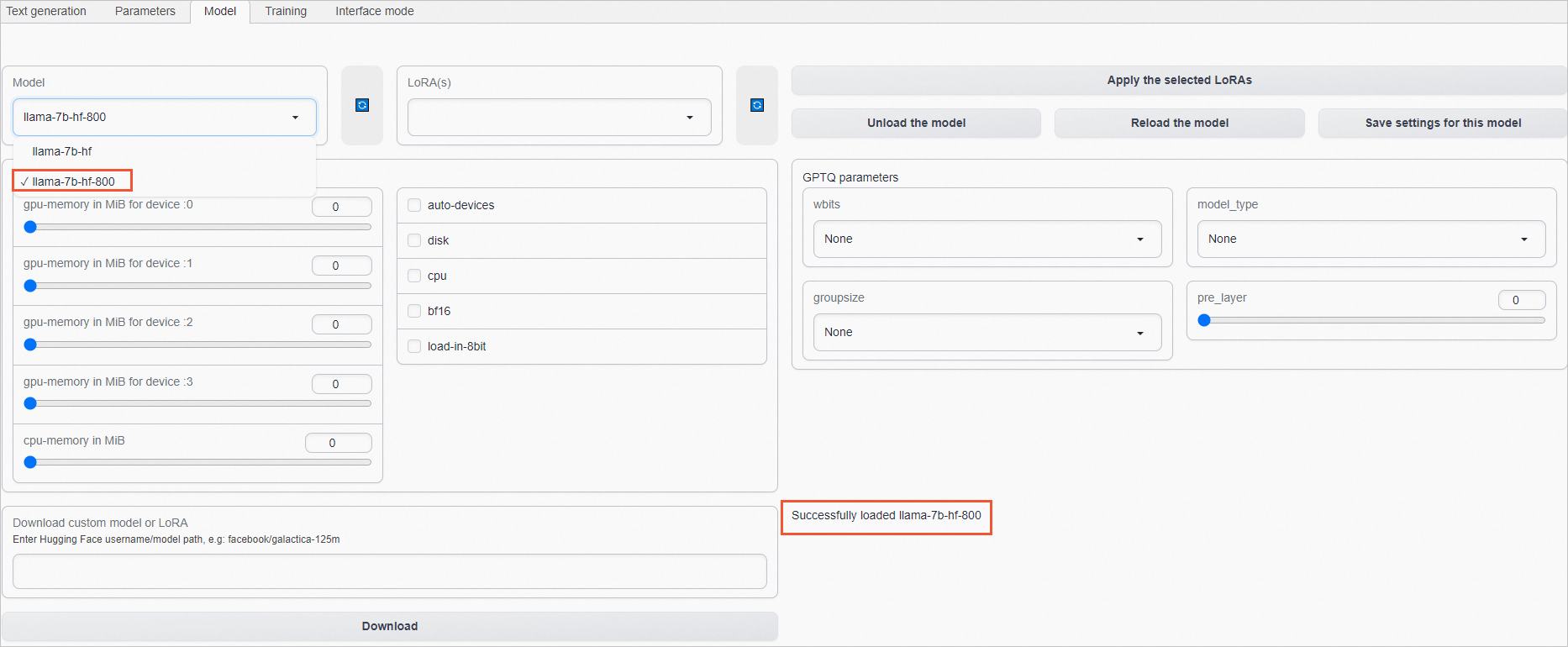
101.200.XX.XX:7860。單擊Model頁簽,在Model模型列表中,選擇指令微調后模型(如本文的llama-7b-hf-800)。
當頁面右下角顯示Successfully loaded llama-7b-hf-800時,說明該模型已加載完成。
說明llama-7b-hf-***后面的數字代表微調的step數,一般情況下,選擇微調step數越大的模型,效果越好。
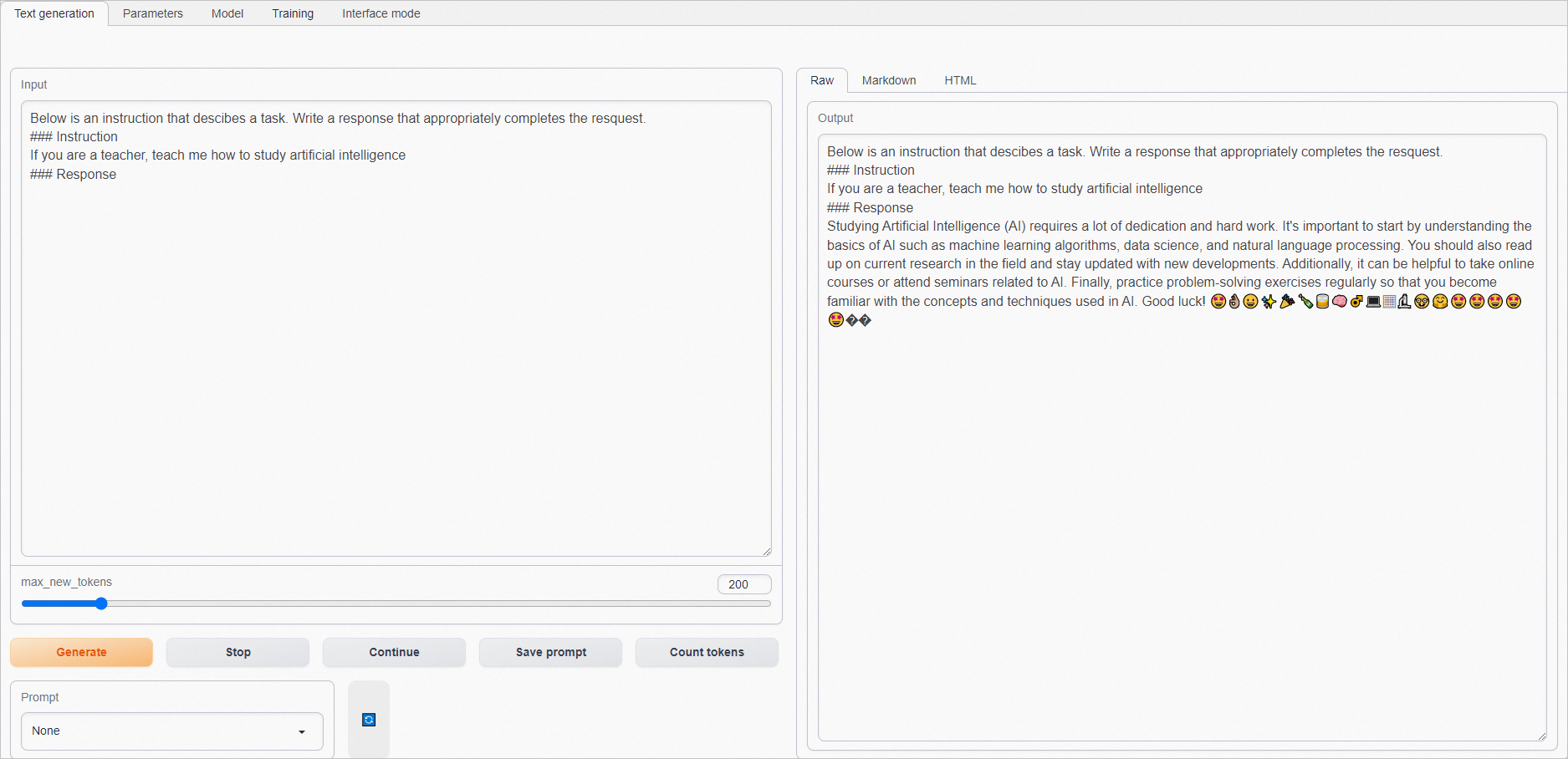
在Input框中輸入問題(建議輸入英語),單擊Generate,在Output框獲取結果。
指令微調后的模型能更好地理解指令,并生成更合理的答案。示例如下:
查看AIACC加速效果
以下是使用2臺ecs.gn7i-c32g1.32xlarge規格的ECS實例(2*4 NVIDIA A10 GPU),基于DeepSpeed進行訓練時,是否啟動AIACC的性能對比。s/it代表訓練每個iteration的時間,時間越短代表訓練速度越快。由下圖可以看出啟動AIACC后相比原生DeepSpeed提速35%左右。
訓練完成后,您可以在/root/LLaMA/stanford_alpaca/wandb/latest-run/files/output.log文件中了解性能。
使用DeepSpeed進行訓練

使用DeepSpeed+AIACC進行訓練

了解更多AIGC實踐和GPU優惠
活動入口:立即開啟AIGC之旅

反饋與建議
如果您在使用教程或實踐過程中有任何問題或建議,可以使用釘釘掃描以下二維碼加入客戶支持群(也可以搜索釘釘群號23210030587加入)與我們的工程師在線交流,將有專人跟進您的問題和建議。
