AIACC-AGSpeed(AIACC 2.0-AIACC Graph Speeding)是阿里云推出的一個基于PyTorch深度學習框架研發的計算優化編譯器,用于優化PyTorch深度學習模型在阿里云GPU異構計算實例上的計算性能,相比原始的神龍AI加速引擎AIACC,AIACC-AGSpeed是AIACC 2.0產品的實現,是完全獨立的產品形態,可以實現無感的計算優化功能。
AIACC-AGSpeed介紹
AIACC-AGSpeed簡稱為AGSpeed,AGSpeed作為阿里云自研的AI訓練計算優化編譯器,對PyTorch深度學習框架訓練過程中的計算性能進行深度優化,具有其顯著的計算性能優勢。
AGSpeed的組件架構圖如下所示: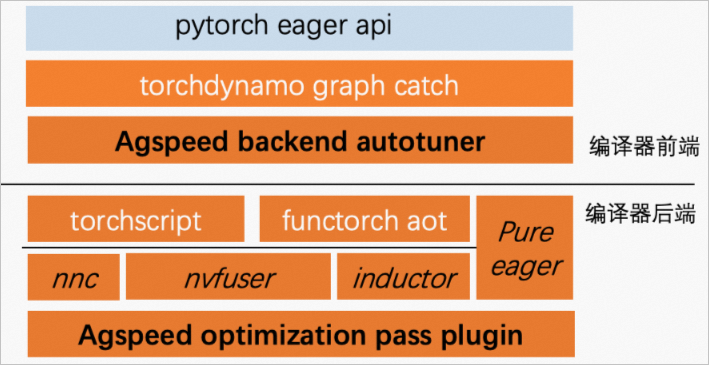
| 組件架構 | 說明 |
|---|---|
| 編譯器前端 | AGSpeed編譯器前端集成了由神龍AI訓練性能和加速團隊進行深度優化后的TorchDynamo,您無需修改任何模型代碼,AGSpeed前端直接從PyTorch Eager API中抓取計算圖,并將計算圖交給AGSpeed Backend Autotuner處理,Autotuner會自動選擇性能優化效果最佳的后端實現,為您提供了最佳的性能體驗。 |
| 編譯器后端 | AGSpeed編譯器后端集成了由神龍AI訓練性能和加速團隊為TorchScript IR研發的IR優化Pass,用于啟用更多融合操作來提升性能。另外,AGSpeed后端還集成了由神龍AI訓練性能和加速團隊進行深度優化后的NvFuser,相比原生NvFuser具有更強的魯棒性和優化性能。 |
受限場景說明
在AGSpeed編譯器前端,如果使用Dynamic Tensor Shape會觸發Re-capture、Re-optimize、Re-compile動作,可能會導致AGSpeed的計算優化性能回退,建議您盡可能使用
agspeed.optimize()接口優化模型的靜態部分。具體原因和建議如下所示:
說明 靜態指的是輸入Tensor的shape不變,模型在向前傳播過程中計算得到的中間變量的shape也保持不變。
原因
- 在AGSpeed編譯器前端,如果存在Dynamic Tensor Shape,可能會導致TorchDynamo重新抓取計算圖并且重新執行convert frame,對優化性能產生較大影響。
- 在AGSpeed編譯器后端,如果存在Dynamic Tensor Shape,會導致TorchScript重新specialize graph,并重新執行所有的優化Pass。另外,NvFuser后端也有可能會為新的Tensor Shape重新編譯新的kernel,這些都會對性能產生較大影響。
建議
使用agspeed.optimize()接口優化模型的靜態部分可以有效避免上述限制。例如,針對目標檢測模型,僅使用agspeed.optimize()優化深度學習的backbone,避免封裝檢測頭,因為檢測頭部分計算的中間變量存在shape多變的現象。
聯系我們
如果您有AI加速AIACC相關的問題或需求,歡迎使用釘釘搜索群號33617640加入阿里云神龍AI加速AIACC外部支持群。(釘釘通訊客戶端下載地址)