本教程通過分析2023年浙江省考生報考的省份,以及不同省份居民對于食物的消費觀念,預測在哪個城市擺攤能獲得更多收益。教程采用DataV-Note(智能分析)完成對原始高考數據的清洗、查看及分析操作,并將分析結果生成報告,進行查閱分享。
教程簡介
背景介紹
通常,大學生作為小吃攤的主要受眾群體,有助于帶動擺攤經濟的增長。我們將運用智能分析,借助2023年浙江省的學校報考數據,探究浙江的學生都流向了哪些地區;同時,對各地區的食品偏好程度進行分析,基于分析結果,針對性地去對應地區擺小吃攤。
分析流程
本教程的分析流程如下圖。

數據清洗:首先對獲取到的多個高考數據進行整合,生成一張包含所有高校及招生信息的匯總表。后續將基于該表進行查詢分析。
數據概覽:基于匯總表進行查詢,可查看各高校的報考信息概況、錄取情況及各城市的教育水平。
數據分析:
基于分析結果,我們可以將獲得的“考生報考熱度高,且居民食品消費指數較高的地區”視為擺攤收益更為顯著的區域。
生成分析報告:您可將分析過程發布為分析報告,導出或分享給他人使用。
分析工具
整個分析過程,將會使用DataV-Note的如下分析單元:
SQL分析:通過SQL語句整合原始數據,以及對結果數據進行查詢分析操作。
智能報告:使用自然語言一鍵分析學生報考的意向省份,以及省份與錄取分數的關系,并生成分析報告。
Python分析:通過Python語句進行線性回歸分析,探索省份與平均分數線是否存在線性趨勢。
可視化分析:通過圖表可視化展示分析結果。
文本分析:使用Markdown文本分析單元,編寫報告相關介紹,輔助理解分析過程。
效果展示
完成本教程后,您將輸出類似如下樣式的分析報告。
準備數據
請下載如下數據至本地,后續需將該數據上傳至DataV-Note,進行相關查詢分析操作。
原始數據 | 作用 |
存放浙江省2023年普通類高校招生投檔分數線數據,以及高校信息數據(例如,所在省份、城市等)。 用于分析各省份的分數線及招生計劃。 | |
用于分析各個城市的人均消費支出。 | |
用于分析各個城市的食品平均消費量。 |
該數據為樣例數據,僅用于學習和交流。
創建項目并上傳數據
數據清洗:整合高校信息
由于獲取到的三個原始文件數據(招生一段線、招生二段線、高校信息)均包含高校相關信息,且存在信息重合情況,為避免多次查詢導致分析過程繁瑣,在進行數據分析前,需先對這些數據進行整合。
創建SQL分析單元。
在報告編輯區域,單擊
 圖標,創建SQL分析單元。
圖標,創建SQL分析單元。進行數據整合。
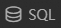
選擇文件數據集(上傳的招生表存放于此),運行如下SQL語句。合并兩個招生表數據,通過學校名稱與高校信息表進行連接,生成一張包含高校信息及招生數據的匯總表,并將匯總表重命名為school。
-- 合并一段線及二段線招生表 WITH merged_table AS ( SELECT * FROM "浙江省招生一段線.csv" UNION SELECT * FROM "浙江省招生二段線.csv" ) -- 將合并后的結果與高校信息表連接,并篩選所需字段。 SELECT mt.學校名稱, mt.計劃數, mt.分數線, mt.位次, t3.省份, t3.城市 FROM merged_table mt JOIN "高校信息.csv" t3 ON mt.學校名稱 = t3.學校名稱;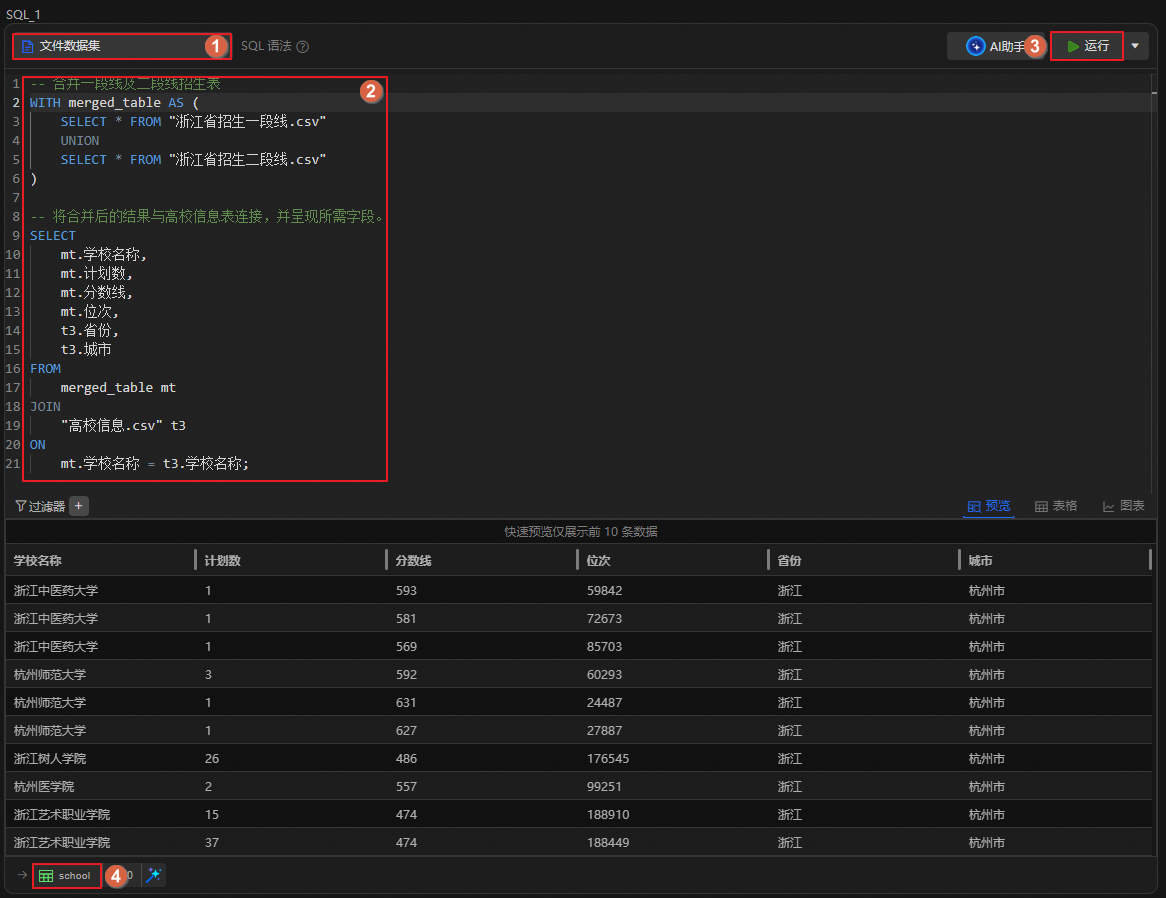
生成的匯總表將展示在左側導航欄的查詢結果集中,后續會基于該查詢結果集進行查詢分析。
數據概覽:查看高校信息概況
在該步驟,可使用SQL查看相關數據詳情,了解高校信息概況。您可參考如下語句進行查詢,也可自行編寫SQL查詢語句。
查看高校匯總表概況
單擊
圖標,創建SQL分析單元。運行如下語句,查看匯總表數據詳情。
SELECT * FROM "school" LIMIT 100;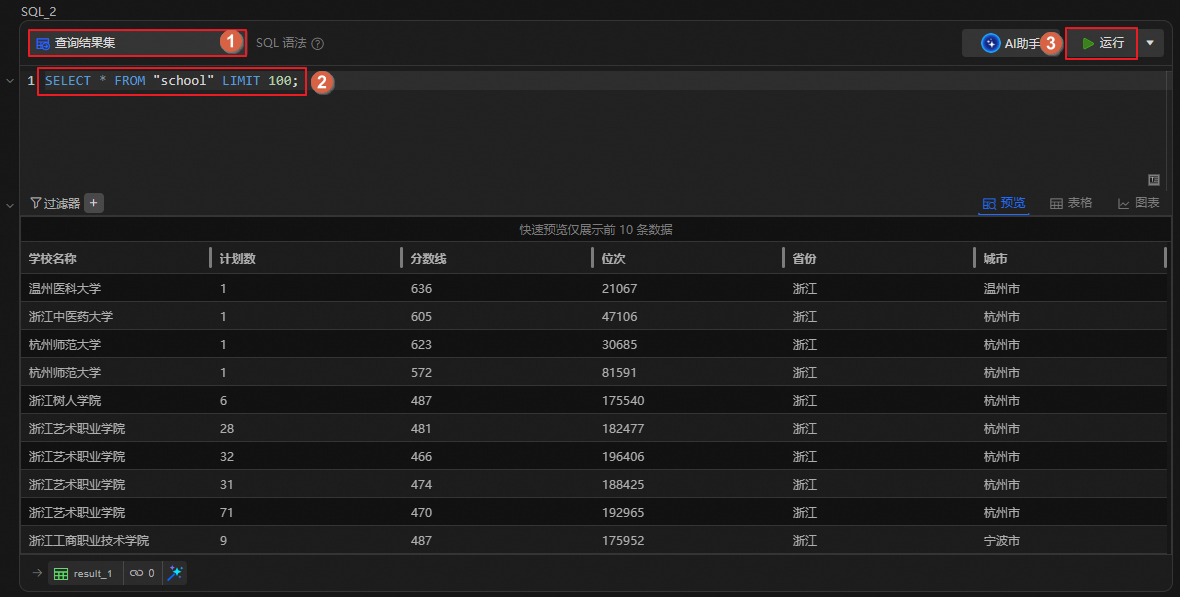
查看各高校的錄取情況
基于高校匯總表,統計每個學校的計劃數、分數線及位次,并按分數線降序排列,以便了解不同學校的錄取分數和表現。
單擊
圖標,創建SQL分析單元。運行如下語句,查看各個學校的錄取情況。
SELECT 學校名稱, SUM(計劃數) AS 計劃數, ROUND(AVG(分數線), 2) AS 分數線, ROUND(AVG(位次), 2) AS 位次, ANY_VALUE(省份) AS 省份, ANY_VALUE(城市) AS 城市 FROM school GROUP BY 學校名稱 ORDER BY 分數線 DESC;
查看各城市的教育水平
統計每個城市中學校的數量,以及分數線和位次的平均值,并按分數線降序排序,以便了解不同城市的教育水平。
單擊
圖標,創建SQL分析單元。運行如下語句,查看各個城市的教育水平。
SELECT ANY_VALUE(省份) AS 省份, 城市, COUNT(*) AS 學校數量, ROUND(AVG(分數線), 2) AS 分數線, ROUND(AVG(位次), 2) AS 位次 FROM school GROUP BY 城市 ORDER BY 分數線 DESC;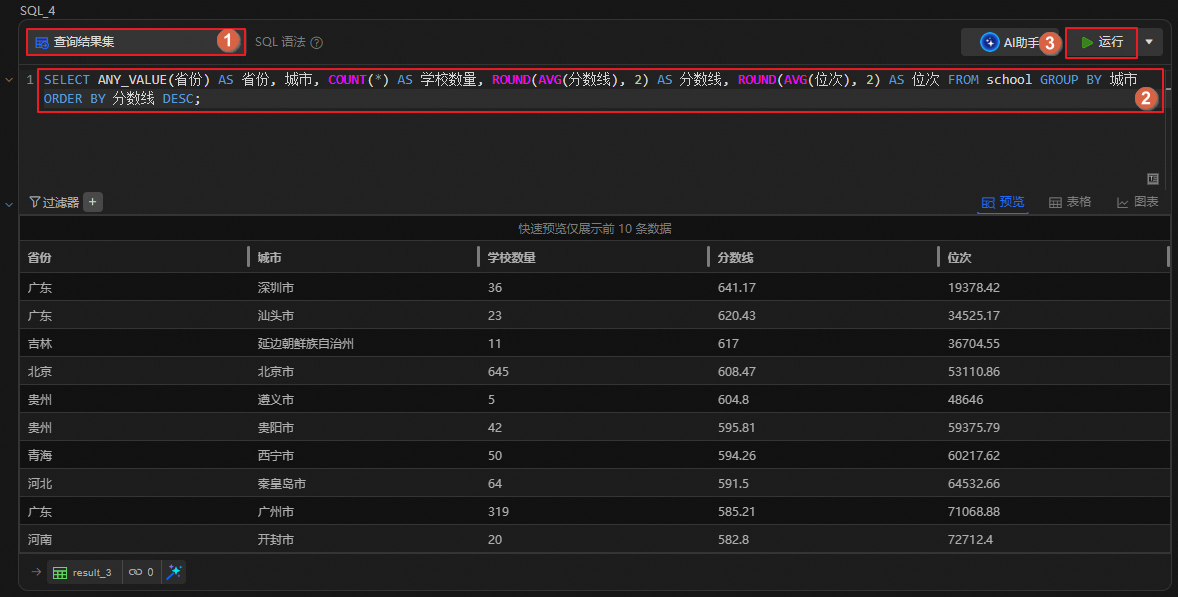
數據分析:報考熱度及差異
至此,將正式進入報告的分析及編寫階段。在該步驟,我們將借助Data-Note的AI能力,輸出分析思路及分析過程,了解各地區的學校招生情況、錄取標準及報考熱度,并評估地域是否會影響錄取分數線。
智能分析是系統根據您輸入的需求,自動分析并匹配相應算法,輸出合適結果。因此,即使每次輸入的描述相同,生成的分析過程也可能存在差異,但不會影響最終的結論導向,具體請以實際界面為準。
智能分析生成的報告您可直接使用,也可基于該報告進行二次編輯。為保障報考熱度及差異分析與后文飲食消費指數分析的關聯性,本文示例使用智能分析體驗生成分析思路,并通過手動操作體驗核心分析過程。
智能分析操作指引
分析操作
在報告編輯區域單擊智能報告,選擇數據源為查詢結果集中的school(高校信息匯總表),使用自然語言描述您的需求并運行。
示例輸入“分析下學生都被招到了哪些省份,以及地域是否影響高校的最低錄取分數線”。
分析過程預計需要3~5分鐘,請耐心等待。

分析過程
智能分析接收到需求后,將自動為您設計報告結構、生成分析思路、執行分析操作、并總結分析結果。
示例生成的報告結構如下。生成的報告您可直接使用,也可基于該報告進行二次編輯。單擊報考熱度及差異.pdf,可查看完整的示例報告內容。

各地區學生報考熱度排名
在智能分析的指引下,我們將通過如下步驟手動體驗核心分析操作。
根據每所學校的所在省份及該省所有院校的總報名人數(即“計劃數”之和),計算出各省內高校的整體受歡迎排序。
查看各省的招生計劃。
單擊
圖標,創建SQL分析單元,運行如下語句。查看各省的總計劃數,并按總計劃數降序排序,將結果表重命名為enrollment_plan。SELECT "省份", SUM("計劃數") AS "總計劃數" FROM school GROUP BY "省份" ORDER BY "總計劃數" DESC;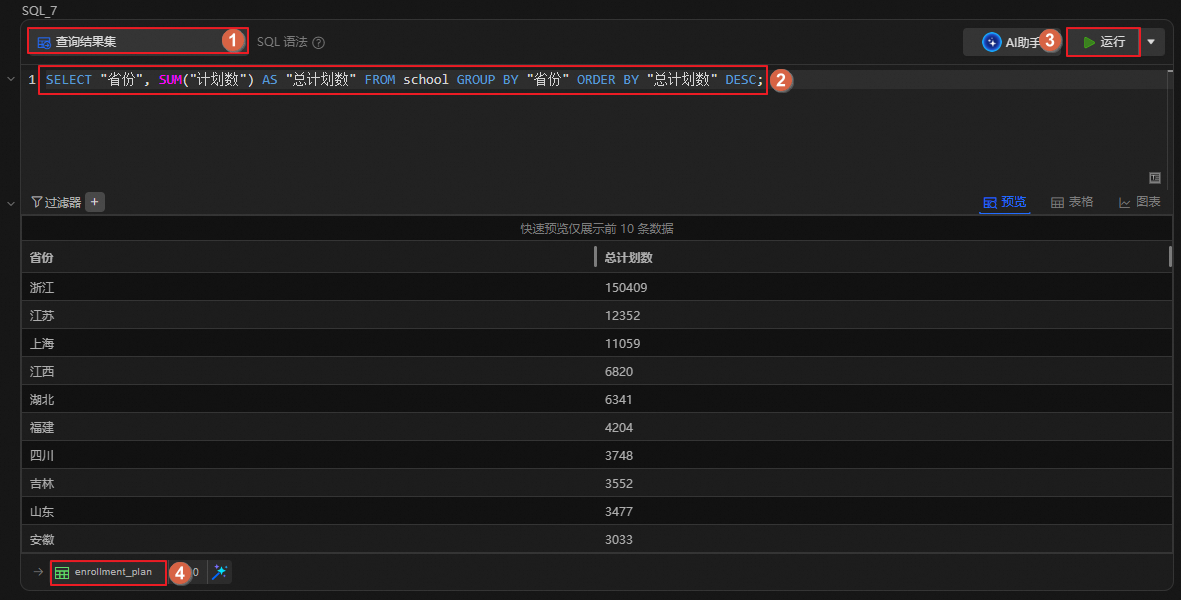
通過圖表展示省份分布,觀測主導地位占比。
單擊,創建圖表分析單元,使用餅圖展示各省份的總計劃數占比。
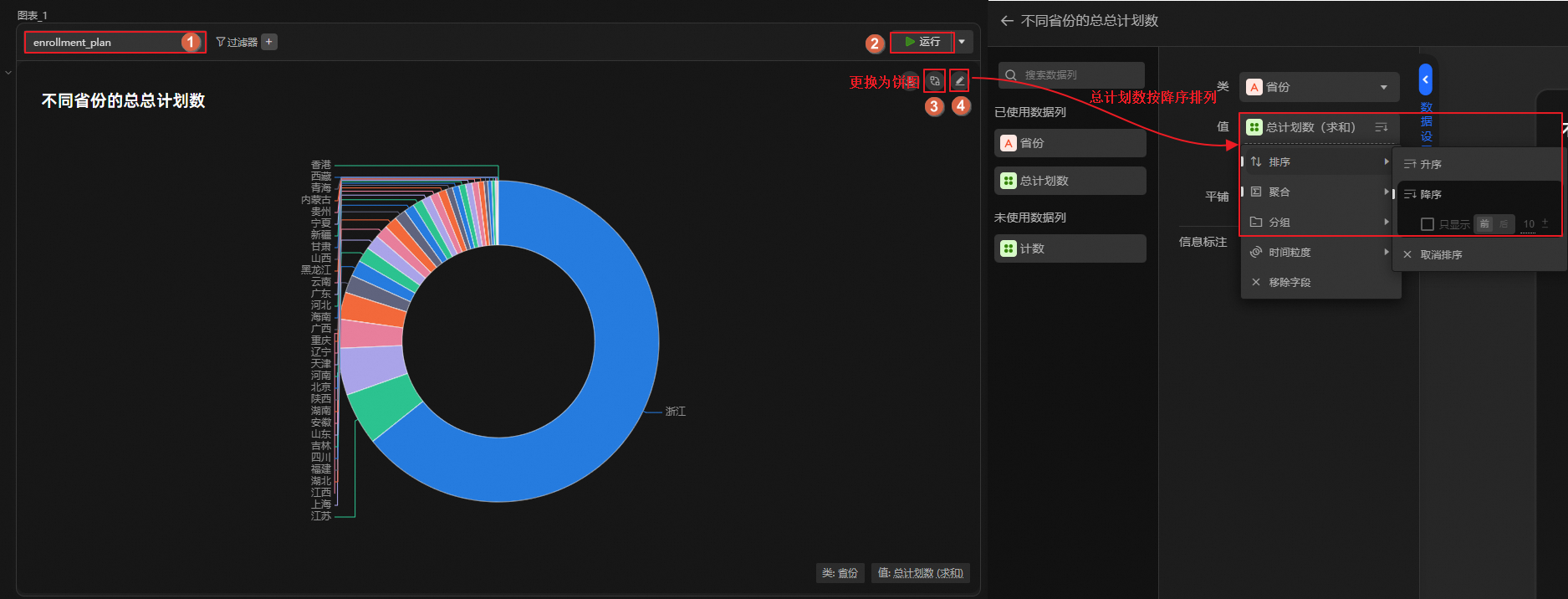
根據上述分析可看出,參與統計的省份中,浙江、江蘇、上海、江西、湖北等地對浙江考生的歡迎程度更高。
地域對錄取分數線的影響評估
在該步驟,將按照省份分組后求取平均分數線,探索省份與平均分數線是否存在線性趨勢,以此衡量地域是否會影響高校的錄取分數線。分析過程使用SQL、Python,并結合圖表進行可視化展示。
查看各省份總平均分數線。
單擊
圖標,創建SQL分析單元,運行如下語句。查看各省份的總平均分數線,并按總平均分數線降序排序,將結果表重命名為score_line。SELECT "省份", AVG("分數線") AS 平均分數線 FROM school GROUP BY "省份";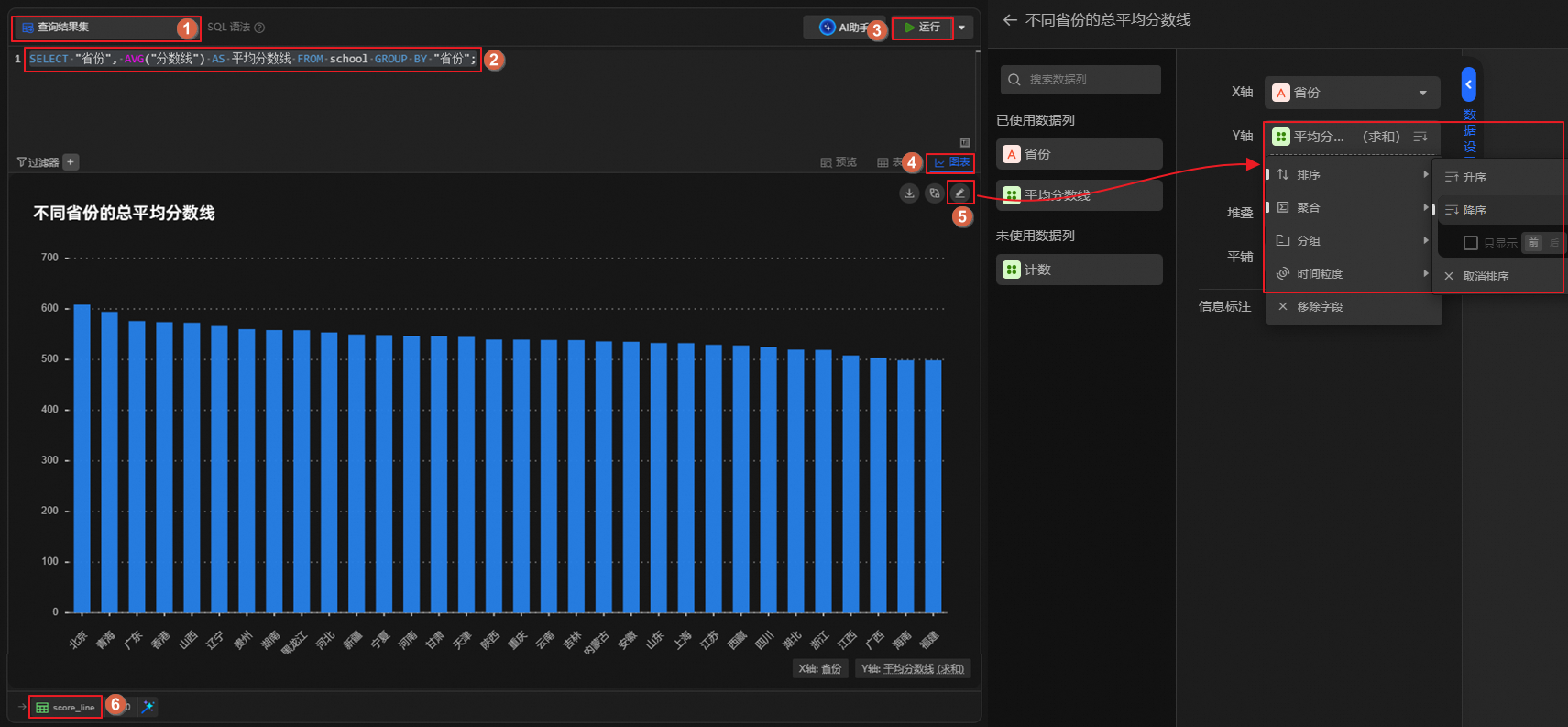
利用數學擬合趨勢線,分析省份與招生標準的關聯性。
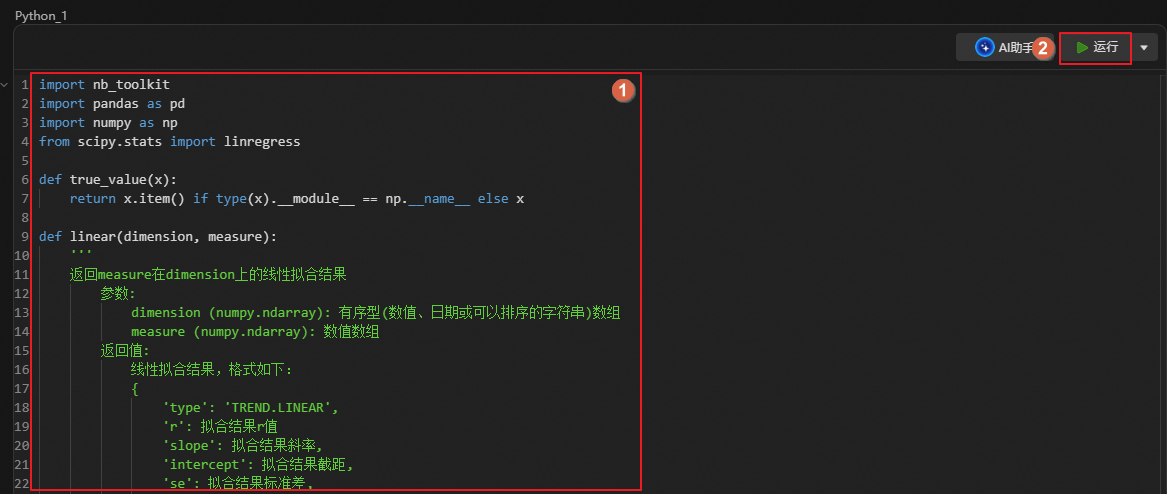
單擊,創建Python分析單元,通過如下語句進行線性回歸分析,探索省份與平均分數線是否存在線性趨勢。
import nb_toolkit import pandas as pd import numpy as np from scipy.stats import linregress def true_value(x): return x.item() if type(x).__module__ == np.__name__ else x def linear(dimension, measure): ''' 返回measure在dimension上的線性擬合結果 參數: dimension (numpy.ndarray): 有序型(數值、日期或可以排序的字符串)數組 measure (numpy.ndarray): 數值數組 返回值: 線性擬合結果,格式如下: { 'type': 'TREND.LINEAR', 'r': 擬合結果r值 'slope': 擬合結果斜率, 'intercept': 擬合結果截距, 'se': 擬合結果標準差, 'p': 擬合結果顯著性(零假設:斜率為零, 使用Wald檢驗且檢驗統計量服從t分布的)(當p值<0.05時拒絕零假設,表明斜率顯著不為0), } 注:擬合時有序型dimension僅作為順序參考,不考慮具體數值 ''' # 線性擬合 scikit——learn里面現成的, 但是數據格式要整理成(n_sample行,n_feature列, 顯然我們就一個feature) # 該方法可以直接獲得rsqured和斜率 mask = np.ma.masked_not_equal(dimension, None).mask # 排除None dimension_remain = dimension[mask] args = dimension_remain.argsort() X = measure[mask][args] # 排序 mask_valid = ~pd.isna(X) # 排除NaN X_valid = (X[mask_valid]).astype(float) dimension_valid = dimension_remain[mask_valid] length_valid = len(dimension_valid) if length_valid < 3: return None slope, intercept, r, p, se = linregress( np.array(range(0, length_valid)), X_valid) slope = true_value(slope) intercept = true_value(intercept) p = true_value(p) se = true_value(se) r = true_value(r) return { 'type': 'TREND.LINEAR', 'r': r, 'slope': slope, 'intercept': intercept, 'se': se, 'p': p, } data = score_line.toDataFrame() if isinstance(score_line, nb_toolkit.view.View) else score_line dimension = np.array(data['省份']) measure = np.array(data['平均分數線']) result = linear(dimension, measure) print(result)說明nb_toolkit:是一個Python工具庫(例如,Notebook管理、版本控制、數據可視化),可在GitHub搜索。
Pandas:是一個Python數據分析庫,主要用于數據操作和分析。
Numpy:提供了支持大型多維數組和矩陣的對象,主要用于高效的數值計算和數據分析。
scipy.stats.linregress:用于執行線性回歸分析。
{'type': 'TREND.LINEAR', 'r': 0.09203176634665855, 'slope': 0.2510677358578127, 'intercept': 539.2637194982078, 'se': 0.4959586674633785, 'p': 0.6163973632699788}通過線性回歸模型,對各省份的平均分數線進行了擬合,得到的趨勢線斜率為正但非常小。盡管斜率顯示存在輕微上升趨勢,但由于其p值遠大于0.05,表明地理因素對于解釋各省間錄取分數差異的作用并不明顯。此結論有助于我們更客觀地看待地域對學生升學難度的影響程度。
根據上述分析可看出,福建、海南、廣西、江西、浙江等省份的總平均分數線相對較低,且地域對學生升學的影響不大。
分析結論
結合AI分析及手動分析結果,我們可得出如下結論:
報考浙江、江蘇、上海、江西、湖北、福建等省份的浙江考生居多。
省份和高校的平均錄取分數線關系不是很大。
數據分析:飲食消費指數
在該步驟,我們將通過分析各地區居民對食品的偏好指數,預測在哪個地區擺攤會獲得更高的收益。分析過程使用SQL,并結合圖表進行可視化展示,結合Markdown進行輔助描述。
各地區人均消費支出
編寫分析操作介紹。
單擊,創建Markdown分析單元,輸入如下內容。
## 3. 各地區人均消費支出 根據居民人均消費支出情況,分析出哪個地區的經濟發展水平及生活質量較高。計算各地區人均消費支出。
單擊
圖標,創建SQL分析單元,運行如下語句,計算各地區的居民人均消費支出,按照人均消費支出降序排序,并將結果表重命名為cost。SELECT 地區, SUM("2022年"+"2021年"+"2020年"+"2019年"/ 4) AS 人均消費支出 FROM "居民人均消費支出.csv" GROUP BY 地區 ORDER BY 人均消費支出 DESC;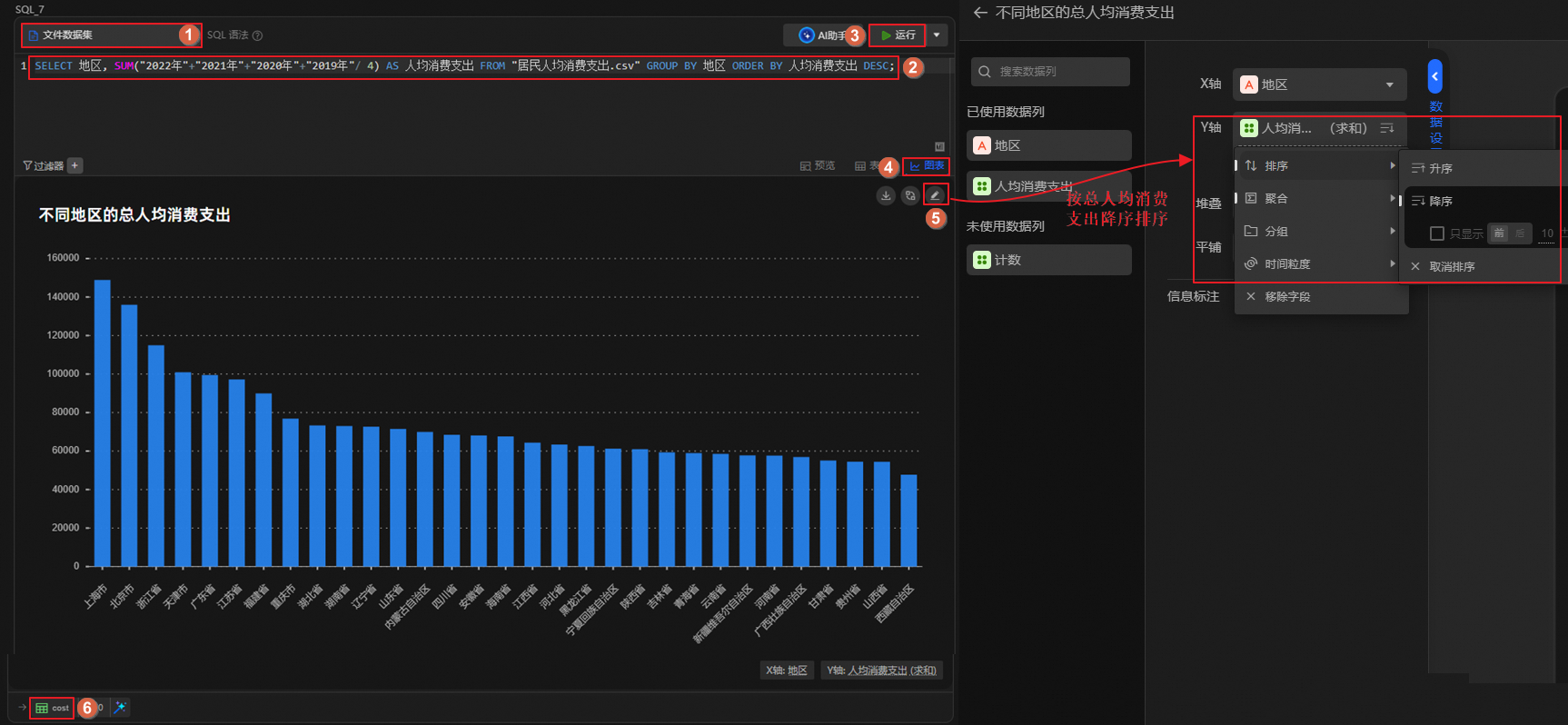
各地區總食品消費量
編寫分析操作介紹。
單擊,創建Markdown分析單元,輸入如下內容。
## 4. 各地區人均食品消費量 根據居民人均食品消費支出情況,分析出哪個地區的居民更愿意為美食買單。計算各地區總食品平均消費量。
單擊
圖標,創建SQL分析單元,運行如下語句。計算各地區居民的總食品平均消費量,按照消費量降序排序,并將結果表重命名為food_like。SELECT 地區, SUM("2022年"+"2021年"+"2020年"+"2019年"/ 4) AS 食品平均消費量 FROM "居民主要食品消費量.csv" GROUP BY 地區 ORDER BY 食品平均消費量 DESC;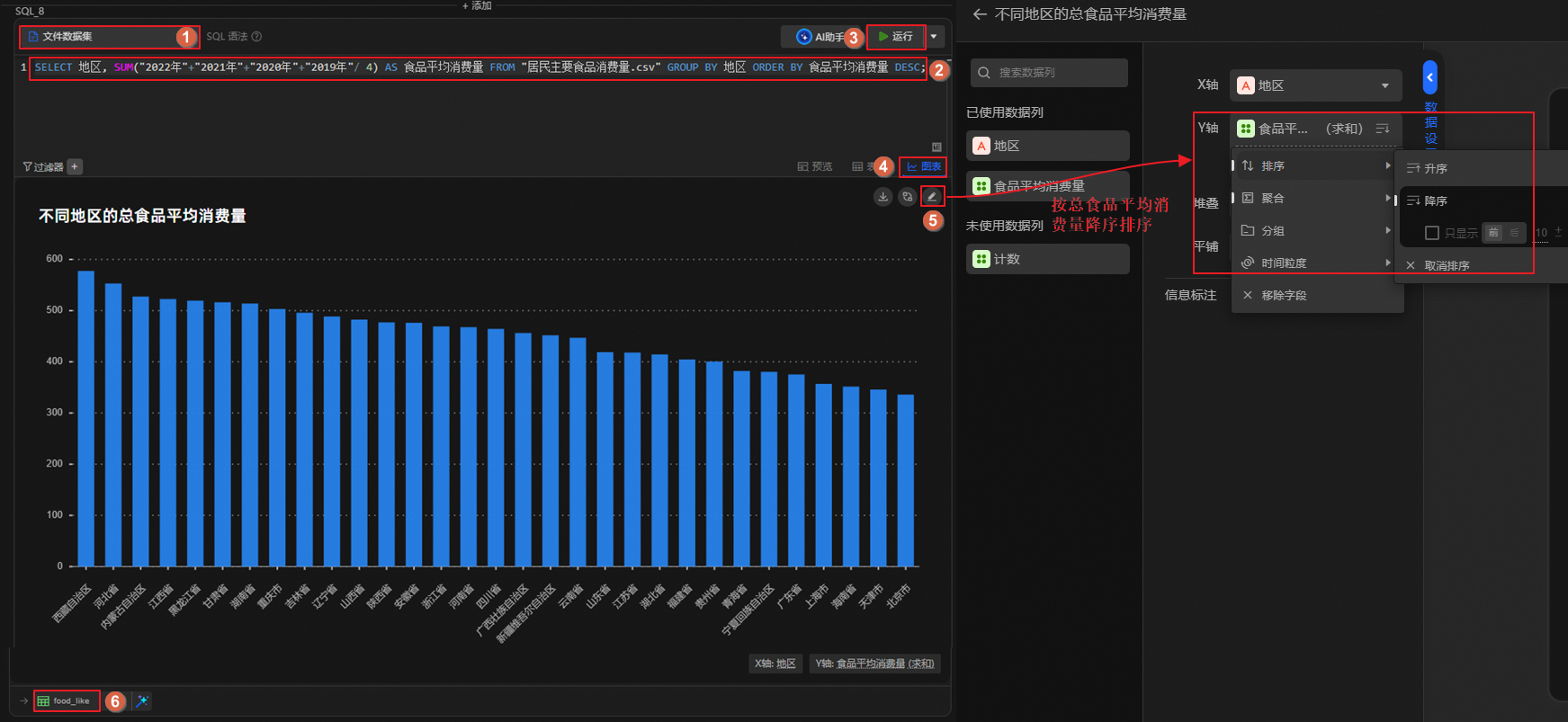
計算食品偏好指數并得出結論
至此,您將結合學生報考熱度及差異分析,和居民的食品消費情況,計算出地區的食品偏好指數,并基于分析結果預測收益更高的擺攤地區。
計算食品偏好指數。
單擊
圖標,創建SQL分析單元,運行如下語句,計算各地區居民的食品偏好指數。說明您可通過如下計算公式,預估各地區的銷售利潤,利潤較高的地區將被視為食品偏好指數較高。
利潤 = 小吃單位利潤 * 銷量 - 自身固定生活開支
= (各省消費水平 / 2000) * (各省計劃招生人數 / 10) * 食品平均消費量 / 500 - 消費水平 / 150
各省消費水平 / 2000:預估的小吃單位利潤。各省計劃招生人數 / 10:預估的購買人數。食品平均消費量 / 500:預估的人均購買量。消費水平 / 150:預估的各省固定生活開支。
計算公式中的各個數值,是基于本文分析情況預估的較為合理的數值,您也可按需調整數值大小。
-- 計算每個地區的食品偏好指數 SELECT cost.地區, ANY_VALUE( ((cost.人均消費支出 / 2000) * -- 小吃單位利潤 (enrollment_plan.總計劃數 / 10) * -- 購買小吃的人數 food_like.食品平均消費量 / 500 - -- 每個人的購買量 cost.人均消費支出 / 150) -- 固定生活開支 + 50000 -- 調整參數,用于調整最終的指數結果 ) AS 食品偏好指數 FROM enrollment_plan JOIN cost ON enrollment_plan.省份 = substr(cost.地區, 1, 2) JOIN food_like ON enrollment_plan.省份 = substr(food_like.地區, 1, 2) GROUP BY cost.地區 ORDER BY 食品偏好指數 DESC;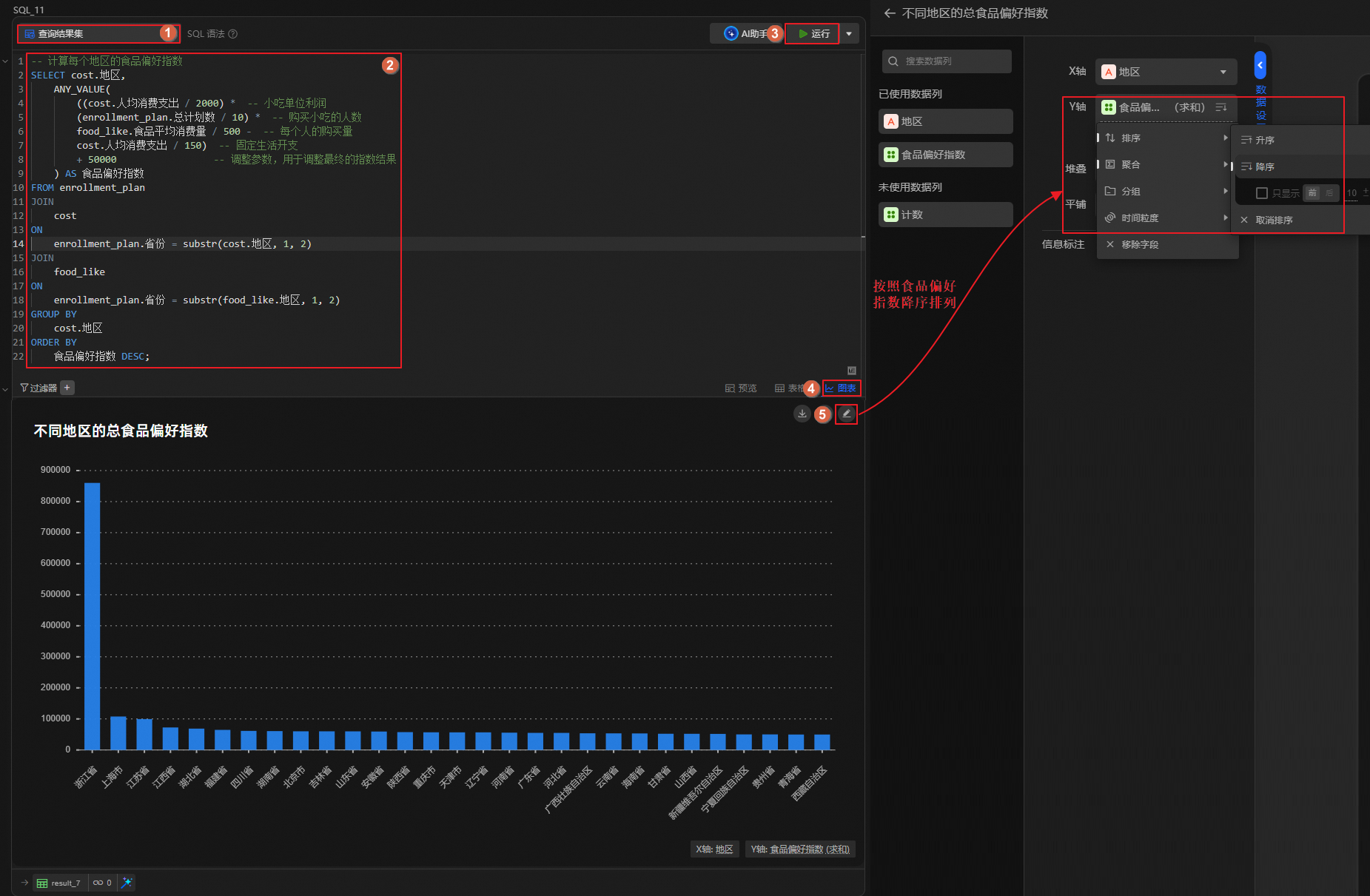
輸出結論。
單擊,創建Markdown分析單元,輸出分析結果。
# 結論與價值 基于計算出的地區食品偏好指數,我們可以看出,浙江、上海、江蘇等省份均適合擺小吃攤。 當然,本案例獲取的僅是浙江省學生去其他省份的招生數據,未包含其他省份報考相應地區的人數及消費能力,相關結論存在一定局限性。僅供體驗功能及參考。
生成分析報告
分析操作執行完成后,您可將分析過程發布為分析報告,并導出或分享給他人查閱。
單擊分析界面右上角的預覽&發布,將分析結果生成可視化報告。
在報告界面右上角,單擊
 圖標,即可將該報告導出為指定格式或分享至所需應用。說明
圖標,即可將該報告導出為指定格式或分享至所需應用。說明您也可按需進行相關發布設置,調整報告樣式。
相關文檔
更多分析單元(圖表、文本、控件等)的介紹,請參見分析單元使用。
更多核心操作介紹,請參見操作指引。
更多AI體驗案例,請參見使用AI一鍵生成分析報告、AI助力SQL分析:宜居小區案例。