節(jié)點(diǎn)異常問題排查
本文介紹關(guān)于節(jié)點(diǎn)異常問題的診斷流程、排查思路、常見問題及解決方案。
本文目錄
類別 | 內(nèi)容 |
診斷流程 | |
常見排查方法 | |
常見問題及解決方案 |
|
診斷流程

查看節(jié)點(diǎn)是否處于異常狀態(tài)。具體操作,請參見檢查節(jié)點(diǎn)的狀態(tài)。
若節(jié)點(diǎn)處于NotReady狀態(tài),可參考如下步驟進(jìn)行排查:
檢查節(jié)點(diǎn)狀態(tài)信息,查看PIDPressure、DiskPressure、MemoryPressure等節(jié)點(diǎn)類型的狀態(tài)是否為True。若某一節(jié)點(diǎn)類型的狀態(tài)為True,則根據(jù)相應(yīng)異常狀態(tài)關(guān)鍵字進(jìn)行排查。具體操作,請參見Dockerd異常處理-RuntimeOffline、節(jié)點(diǎn)內(nèi)存不足-MemoryPressure和節(jié)點(diǎn)索引節(jié)點(diǎn)不足-InodesPressure等進(jìn)行解決。
檢查節(jié)點(diǎn)的關(guān)鍵組件和日志。
Kubelet
檢查Kubelet的狀態(tài)、日志、配置等是否存在異常。具體操作,請參見檢查節(jié)點(diǎn)的關(guān)鍵組件。
若Kubelet存在異常,請參見Kubelet異常處理操作。
Dockerd
檢查Dockerd的狀態(tài)、日志、配置等是否存在異常。具體操作,請參見檢查節(jié)點(diǎn)的關(guān)鍵組件。
若Dockerd存在異常,請參見Dockerd異常處理-RuntimeOffline操作。
Containerd
檢查Containerd的狀態(tài)、日志、配置等是否存在異常。具體操作,請參見檢查節(jié)點(diǎn)的關(guān)鍵組件。
若Containerd存在異常,請參見Containerd異常處理-RuntimeOffline操作。
NTP
檢查NTP服務(wù)的狀態(tài)、日志、配置等是否存在異常。具體操作,請參見檢查節(jié)點(diǎn)的關(guān)鍵組件。
若NTP服務(wù)存在異常,請參見NTP異常處理-NTPProblem操作。
檢查節(jié)點(diǎn)的診斷日志。具體操作,請參見檢查節(jié)點(diǎn)的診斷日志。
檢查節(jié)點(diǎn)的監(jiān)控,查看節(jié)點(diǎn)CPU、內(nèi)存、網(wǎng)絡(luò)等資源負(fù)載情況是否存在異常。具體操作,請參見檢查節(jié)點(diǎn)的監(jiān)控。若節(jié)點(diǎn)負(fù)載異常,請參見節(jié)點(diǎn)CPU不足和節(jié)點(diǎn)內(nèi)存不足-MemoryPressure等解決。
若節(jié)點(diǎn)處于Unknown狀態(tài),可參考如下步驟進(jìn)行排查。
檢查節(jié)點(diǎn)ECS實(shí)例狀態(tài)是否為運(yùn)行中。
檢查節(jié)點(diǎn)的關(guān)鍵組件。
Kubelet
檢查Kubelet的狀態(tài)、日志、配置等是否存在異常。具體操作,請參見檢查節(jié)點(diǎn)的關(guān)鍵組件。
若Kubelet存在異常,請參見Kubelet異常處理操作。
Dockerd
檢查Dockerd的狀態(tài)、日志、配置等是否存在異常。具體操作,請參見檢查節(jié)點(diǎn)的關(guān)鍵組件。
若Dockerd存在異常,請參見Dockerd異常處理-RuntimeOffline操作。
Containerd
檢查Containerd的狀態(tài)、日志、配置等是否存在異常。具體操作,請參見檢查節(jié)點(diǎn)的關(guān)鍵組件。
若Containerd存在異常,請參見Containerd異常處理-RuntimeOffline操作。
NTP
檢查NTP服務(wù)的狀態(tài)、日志、配置等是否存在異常。具體操作,請參見檢查節(jié)點(diǎn)的關(guān)鍵組件。
若NTP服務(wù)存在異常,請參見NTP異常處理-NTPProblem操作。
檢查節(jié)點(diǎn)的網(wǎng)絡(luò)連通性。具體操作,請參見檢查節(jié)點(diǎn)的安全組。若節(jié)點(diǎn)網(wǎng)絡(luò)存在異常,請參見節(jié)點(diǎn)網(wǎng)絡(luò)異常解決。
檢查節(jié)點(diǎn)的診斷日志。具體操作,請參見檢查節(jié)點(diǎn)的診斷日志。
檢查節(jié)點(diǎn)的監(jiān)控,查看節(jié)點(diǎn)CPU、內(nèi)存、網(wǎng)絡(luò)等資源負(fù)載情況是否存在異常。具體操作,請參見檢查節(jié)點(diǎn)的監(jiān)控。若節(jié)點(diǎn)負(fù)載異常,請參見節(jié)點(diǎn)CPU不足和節(jié)點(diǎn)內(nèi)存不足-MemoryPressure解決。
若根據(jù)診斷流程未能排查問題,請使用容器服務(wù)ACK提供的故障診斷功能進(jìn)行排查。具體操作,請參見節(jié)點(diǎn)故障診斷。
若問題仍未解決,請提交工單排查。
常見排查方法
節(jié)點(diǎn)故障診斷
當(dāng)節(jié)點(diǎn)出現(xiàn)故障時,您可以使用容器服務(wù)ACK提供的故障診斷功能,一鍵診斷節(jié)點(diǎn)異常。
在控制臺左側(cè)導(dǎo)航欄,單擊集群。
在集群列表頁面,單擊目標(biāo)集群名稱或者目標(biāo)集群右側(cè)操作列下的詳情。
在集群管理頁左側(cè)導(dǎo)航欄,選擇。
在節(jié)點(diǎn)管理頁面,單擊目標(biāo)診斷節(jié)點(diǎn)右側(cè)操作列下的。
在診斷詳情頁面,根據(jù)診斷后的異常信息進(jìn)行排查。
檢查節(jié)點(diǎn)的詳情
在控制臺左側(cè)導(dǎo)航欄,單擊集群。
在集群列表頁面,單擊目標(biāo)集群名稱或者目標(biāo)集群右側(cè)操作列下的詳情。
在集群管理頁左側(cè)導(dǎo)航欄,選擇。
在節(jié)點(diǎn)頁面,單擊目標(biāo)節(jié)點(diǎn)名稱或者目標(biāo)節(jié)點(diǎn)右側(cè)操作列下的,查看節(jié)點(diǎn)的詳情。
檢查節(jié)點(diǎn)的狀態(tài)
在控制臺左側(cè)導(dǎo)航欄,單擊集群。
在集群列表頁面,單擊目標(biāo)集群名稱或者目標(biāo)集群右側(cè)操作列下的詳情。
在集群管理頁左側(cè)導(dǎo)航欄,選擇。
在節(jié)點(diǎn)頁面,可查看對應(yīng)節(jié)點(diǎn)的狀態(tài)。
若節(jié)點(diǎn)狀態(tài)為運(yùn)行中,說明節(jié)點(diǎn)運(yùn)行正常。
若節(jié)點(diǎn)狀態(tài)不是運(yùn)行中,可單擊目標(biāo)節(jié)點(diǎn)名稱或者目標(biāo)節(jié)點(diǎn)右側(cè)操作列下的,查看異常狀態(tài)節(jié)點(diǎn)的詳情。
說明若您要收集InodesPressure、DockerOffline、RuntimeOffline等類型的狀態(tài)信息,需要在集群中安裝node-problem-detector并創(chuàng)建事件中心,該功能在創(chuàng)建集群時默認(rèn)選中。更多信息,請參見創(chuàng)建并使用K8s事件中心。
檢查節(jié)點(diǎn)的事件
在控制臺左側(cè)導(dǎo)航欄,單擊集群。
在集群列表頁面,單擊目標(biāo)集群名稱或者目標(biāo)集群右側(cè)操作列下的詳情。
在集群管理頁左側(cè)導(dǎo)航欄,選擇。
在節(jié)點(diǎn)頁面,單擊目標(biāo)節(jié)點(diǎn)名稱或者目標(biāo)節(jié)點(diǎn)右側(cè)操作列下的,查看節(jié)點(diǎn)的詳情。
在節(jié)點(diǎn)詳情頁面的最下方,可查看節(jié)點(diǎn)事件信息。
檢查節(jié)點(diǎn)的診斷日志
使用腳本收集診斷日志:具體操作,請參見如何收集Kubernetes集群診斷信息?。
使用控制臺收集診斷日志:具體操作,請參見一鍵采集節(jié)點(diǎn)的診斷日志。
檢查節(jié)點(diǎn)的關(guān)鍵組件
Kubelet:
查看Kubelet狀態(tài)
登錄對應(yīng)節(jié)點(diǎn),在節(jié)點(diǎn)上執(zhí)行如下命令,查看Kubelet進(jìn)程狀態(tài)。
systemctl status kubelet預(yù)期輸出:
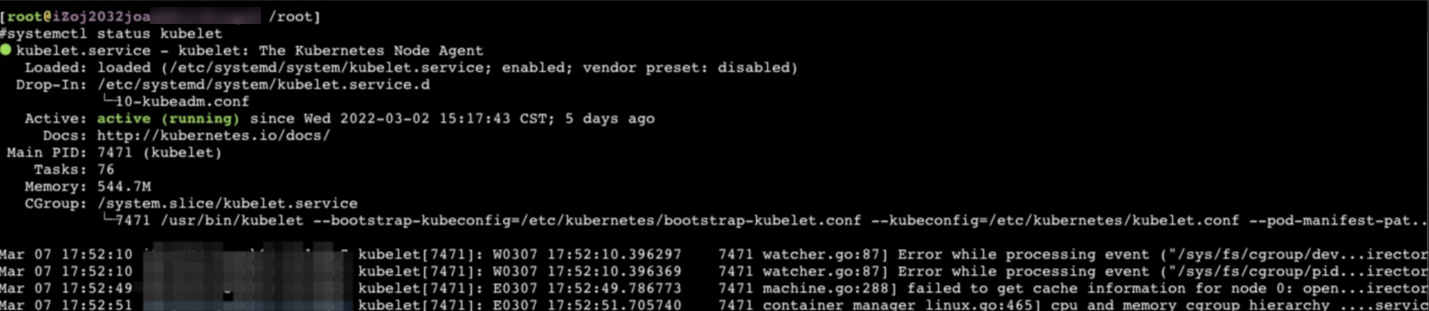
查看Kubelet日志
登錄對應(yīng)節(jié)點(diǎn),在節(jié)點(diǎn)上執(zhí)行如下命令,可查看Kubelet日志信息。關(guān)于更多查看Kubelet日志的方式,請參見檢查節(jié)點(diǎn)的診斷日志。
journalctl -u kubelet查看Kubelet配置
登錄對應(yīng)節(jié)點(diǎn),在節(jié)點(diǎn)上執(zhí)行如下命令,可查看Kubelet配置信息。
cat /etc/systemd/system/kubelet.service.d/10-kubeadm.conf
運(yùn)行時:
檢查Dockerd
查看Dockerd狀態(tài)
登錄對應(yīng)節(jié)點(diǎn),在節(jié)點(diǎn)上執(zhí)行如下命令,查看Dockerd進(jìn)程狀態(tài)。
systemctl status docker預(yù)期輸出:

查看Dockerd日志
登錄對應(yīng)節(jié)點(diǎn),在節(jié)點(diǎn)上執(zhí)行如下命令,可查看Dockerd的日志信息。關(guān)于更多查看Dockerd日志的方式,請參見檢查節(jié)點(diǎn)的診斷日志。
journalctl -u docker查看Dockerd配置
登錄對應(yīng)節(jié)點(diǎn),在節(jié)點(diǎn)上執(zhí)行如下命令,可查看Dockerd配置信息。
cat /etc/docker/daemon.json
檢查Containerd
查看Containerd狀態(tài)
登錄對應(yīng)節(jié)點(diǎn),在節(jié)點(diǎn)上執(zhí)行如下命令,查看Containerd進(jìn)程狀態(tài)。
systemctl status containerd預(yù)期輸出:

查看Containerd日志
登錄對應(yīng)節(jié)點(diǎn),在節(jié)點(diǎn)上執(zhí)行如下命令,可查看Containerd日志信息。關(guān)于更多查看Containerd日志的方式,請參見檢查節(jié)點(diǎn)的診斷日志 。
journalctl -u containerd
檢查NTP:
查看NTP服務(wù)狀態(tài)
登錄對應(yīng)節(jié)點(diǎn),在節(jié)點(diǎn)上執(zhí)行如下命令,查看Chronyd進(jìn)程的狀態(tài)。
systemctl status chronyd預(yù)期輸出:
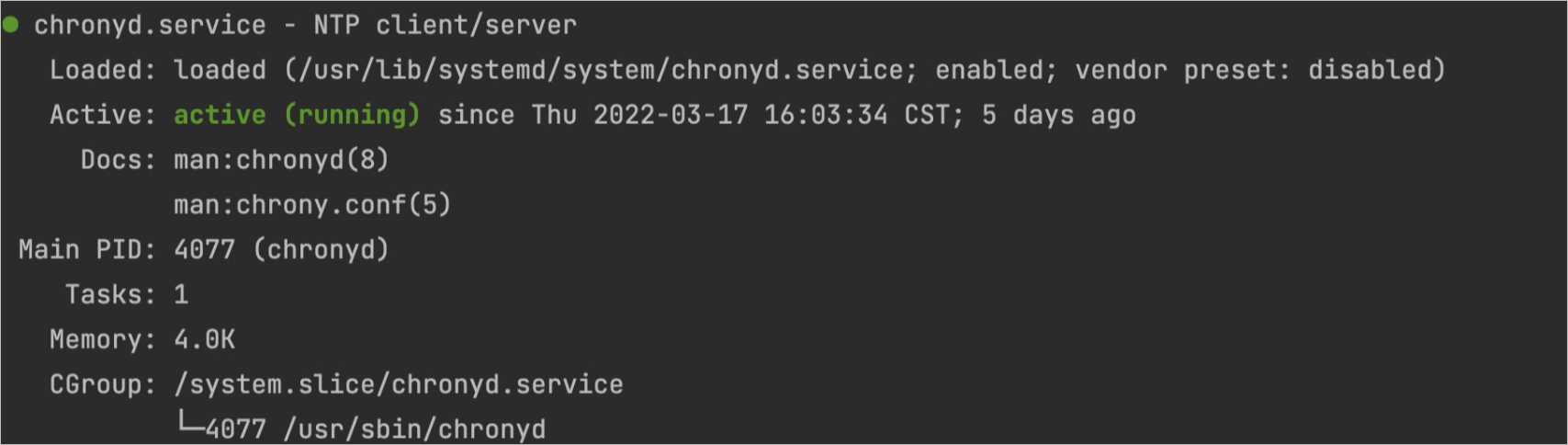
查看NTP服務(wù)日志
登錄對應(yīng)節(jié)點(diǎn),在節(jié)點(diǎn)上執(zhí)行如下命令,可查看NTP日志信息。
journalctl -u chronyd
檢查節(jié)點(diǎn)的監(jiān)控
云監(jiān)控
阿里云容器服務(wù)ACK集群集成了監(jiān)控服務(wù),可登錄云監(jiān)控制臺查看對應(yīng)ECS實(shí)例的基本監(jiān)控信息,關(guān)于云監(jiān)控節(jié)點(diǎn)的使用方式,請參見監(jiān)控節(jié)點(diǎn)。
Prometheus監(jiān)控
在控制臺左側(cè)導(dǎo)航欄中,單擊集群。
在集群列表頁面中,單擊目標(biāo)集群名稱或者目標(biāo)集群右側(cè)操作列下的詳情。
在集群管理頁左側(cè)導(dǎo)航欄中,選擇。
在Prometheus監(jiān)控頁面,單擊節(jié)點(diǎn)監(jiān)控頁簽,在集群節(jié)點(diǎn)監(jiān)控詳情頁面選擇待查看的節(jié)點(diǎn),可查看對應(yīng)節(jié)點(diǎn)的CPU、內(nèi)存、磁盤等監(jiān)控信息。
檢查節(jié)點(diǎn)的安全組
Kubelet異常處理
問題原因
通常是Kubelet進(jìn)程異常、運(yùn)行時異常、Kubelet配置有誤等原因?qū)е隆?/p>
問題現(xiàn)象
Kubelet狀態(tài)為inactive。
解決方案
執(zhí)行如下命令重啟Kubelet。重啟Kubelet不會影響運(yùn)行中的容器。
systemctl restart kubeletKubelet重啟后,登錄節(jié)點(diǎn)執(zhí)行以下命令,再次查看kubelet狀態(tài)是否恢復(fù)正常。
systemctl status kubelet若Kubelet重啟后狀態(tài)仍異常,請登錄節(jié)點(diǎn)執(zhí)行以下命令查看Kubelet日志。
journalctl -u kubelet若日志中有明確的異常信息,請根據(jù)異常關(guān)鍵字進(jìn)行排查。
若確認(rèn)是Kubelet配置異常,請執(zhí)行如下命令修改Kubelet配置。
vi /etc/systemd/system/kubelet.service.d/10-kubeadm.conf #修改Kubelet配置。 systemctl daemon-reload;systemctl restart kubelet #重新加載配置并重啟Kubelet。
Dockerd異常處理-RuntimeOffline
問題原因
通常是Dockerd配置異常、進(jìn)程負(fù)載異常、節(jié)點(diǎn)負(fù)載異常等原因?qū)е隆?/p>
問題現(xiàn)象
Dockerd狀態(tài)為inactive。
Dockerd狀態(tài)為active (running),但未正常工作,導(dǎo)致節(jié)點(diǎn)異常。通常有
docker ps、docker exec等命令執(zhí)行失敗的現(xiàn)象。節(jié)點(diǎn)狀態(tài)中RuntimeOffline為True。
若集群配置了集群節(jié)點(diǎn)異常報警,則節(jié)點(diǎn)Dockerd異常時可收到相關(guān)報警。關(guān)于配置報警,請參見容器服務(wù)報警管理。
解決方案
執(zhí)行如下命令重啟Dockerd。
systemctl restart dockerDockerd重啟后,登錄節(jié)點(diǎn)執(zhí)行以下命令,再次查看Dockerd狀態(tài)是否恢復(fù)正常。
systemctl status docker若Dockerd重啟后狀態(tài)仍異常,請登錄節(jié)點(diǎn)執(zhí)行以下命令查看Dockerd日志。
journalctl -u docker
Containerd異常處理-RuntimeOffline
問題原因
通常是Containerd配置異常、進(jìn)程負(fù)載異常、節(jié)點(diǎn)負(fù)載異常等原因?qū)е隆?/p>
Containerd狀態(tài)為inactive。
節(jié)點(diǎn)狀態(tài)中RuntimeOffline為True。
若集群配置了集群節(jié)點(diǎn)異常報警,則節(jié)點(diǎn)Containerd異常時可收到相關(guān)報警。關(guān)于配置報警,請參見容器服務(wù)報警管理。
解決方案
執(zhí)行如下命令重啟Containerd。
systemctl restart containerdContainerd重啟后,登錄節(jié)點(diǎn)執(zhí)行以下命令,再次查看Containerd狀態(tài)是否恢復(fù)正常。
systemctl status containerd若Containerd重啟后狀態(tài)仍異常,請登錄節(jié)點(diǎn)執(zhí)行以下命令查看Containerd日志。
journalctl -u containerd
NTP異常處理-NTPProblem
問題原因
通常是NTP進(jìn)程狀態(tài)異常導(dǎo)致。
問題現(xiàn)象
Chronyd狀態(tài)為inactive。
節(jié)點(diǎn)狀態(tài)中NTPProblem為True。
若集群配置了集群節(jié)點(diǎn)異常報警,則節(jié)點(diǎn)時間服務(wù)異常時可收到相關(guān)報警。關(guān)于配置報警,請參見容器服務(wù)報警管理。
解決方案
執(zhí)行如下命令重啟Chronyd。
systemctl restart chronydChronyd重啟后,登錄節(jié)點(diǎn)執(zhí)行以下命令,再次查看Chronyd狀態(tài)是否恢復(fù)正常。
systemctl status chronyd若Chronyd重啟后狀態(tài)仍異常,請登錄節(jié)點(diǎn)執(zhí)行以下命令查看Chronyd日志。
journalctl -u chronyd
節(jié)點(diǎn)PLEG異常-PLEG is not healthy
問題原因
Pod生命周期事件生成器PLEG(Pod Lifecycle Event Generator)會記錄Pod生命周期中的各種事件,如容器的啟動、終止等。PLEG is not healthy異常通常是由于節(jié)點(diǎn)上的運(yùn)行時進(jìn)程異常或者節(jié)點(diǎn)Systemd版本缺陷導(dǎo)致。
問題現(xiàn)象
節(jié)點(diǎn)狀態(tài)NotReady。
在Kubelet日志中,可看到如下日志。
I0729 11:20:59.245243 9575 kubelet.go:1823] skipping pod synchronization - PLEG is not healthy: pleg was last seen active 3m57.138893648s ago; threshold is 3m0s.若集群配置了集群節(jié)點(diǎn)異常報警,則節(jié)點(diǎn)PLEG異常時可收到相關(guān)報警。關(guān)于配置報警,請參見容器服務(wù)報警管理。
解決方案
依次重啟節(jié)點(diǎn)關(guān)鍵組件Dockerd、Contatinerd、Kubelet,重啟后查看節(jié)點(diǎn)是否恢復(fù)正常。
若節(jié)點(diǎn)關(guān)鍵組件重啟后節(jié)點(diǎn)仍未恢復(fù)正常,可嘗試重啟異常節(jié)點(diǎn)。具體操作,請參見重啟實(shí)例。
警告重啟節(jié)點(diǎn)可能會導(dǎo)致您的業(yè)務(wù)中斷,請謹(jǐn)慎操作。
若異常節(jié)點(diǎn)系統(tǒng)為CentOS 7.6,參見 使用CentOS 7.6系統(tǒng)時kubelet日志含有“PLEG is not healthy”進(jìn)行排查 。
節(jié)點(diǎn)調(diào)度資源不足
問題原因
通常是集群中的節(jié)點(diǎn)資源不足導(dǎo)致。
問題現(xiàn)象
當(dāng)集群中的節(jié)點(diǎn)調(diào)度資源不足時,會導(dǎo)致Pod調(diào)度失敗,出現(xiàn)以下常見錯誤信息:
集群CPU資源不足:0/2 nodes are available: 2 Insufficient cpu
集群內(nèi)存資源不足:0/2 nodes are available: 2 Insufficient memory
集群臨時存儲不足:0/2 nodes are available: 2 Insufficient ephemeral-storage
其中調(diào)度器判定節(jié)點(diǎn)資源不足的計算方式為:
集群節(jié)點(diǎn)CPU資源不足的判定方式:當(dāng)前Pod請求的CPU資源總量>(節(jié)點(diǎn)可分配的CPU資源總量-節(jié)點(diǎn)已分配的CPU資源總量)
集群節(jié)點(diǎn)內(nèi)存資源不足的判定方式:當(dāng)前Pod請求的內(nèi)存資源總量>(節(jié)點(diǎn)可分配的內(nèi)存資源總量-節(jié)點(diǎn)已分配的內(nèi)存資源總量)
集群節(jié)點(diǎn)臨時存儲不足的判定方式:當(dāng)前Pod請求的臨時存儲總量>(節(jié)點(diǎn)可分配的臨時存儲總量-節(jié)點(diǎn)已分配的臨時存儲總量)
如果當(dāng)前Pod請求的資源總量大于節(jié)點(diǎn)可分配的資源總量減去節(jié)點(diǎn)已分配的資源總量,Pod就不會調(diào)度到當(dāng)前節(jié)點(diǎn)。
執(zhí)行以下命令,查看節(jié)點(diǎn)的資源分配信息:
kubectl describe node [$nodeName]關(guān)注輸出中的如下部分::
Allocatable:
cpu: 3900m
ephemeral-storage: 114022843818
hugepages-1Gi: 0
hugepages-2Mi: 0
memory: 12601Mi
pods: 60
Allocated resources:
(Total limits may be over 100 percent, i.e., overcommitted.)
Resource Requests Limits
-------- -------- ------
cpu 725m (18%) 6600m (169%)
memory 977Mi (7%) 16640Mi (132%)
ephemeral-storage 0 (0%) 0 (0%)
hugepages-1Gi 0 (0%) 0 (0%)
hugepages-2Mi 0 (0%) 0 (0%)其中:
Allocatable:表示本節(jié)點(diǎn)可分配的(CPU/內(nèi)存/臨時存儲)資源總量。
Allocated resources:表示本節(jié)點(diǎn)已經(jīng)分配的(CPU/內(nèi)存/臨時存儲)資源總量。
解決方案
當(dāng)節(jié)點(diǎn)調(diào)度資源不足時,需降低節(jié)點(diǎn)負(fù)載,方法如下:
刪除或減少不必要的Pod,降低節(jié)點(diǎn)的負(fù)載。具體操作,請參見管理容器組(Pod)。
根據(jù)自身業(yè)務(wù)情況,限制Pod的資源配置。具體操作,請參見設(shè)置容器的CPU和內(nèi)存資源上下限。
您可以使用ACK提供的資源畫像功能,基于資源使用量的歷史數(shù)據(jù)獲得容器粒度的資源規(guī)格推薦,簡化為容器配置Request和Limit的復(fù)雜度。更多信息,請參見資源畫像。
在集群中添加新的節(jié)點(diǎn)。具體操作,請參見創(chuàng)建節(jié)點(diǎn)池。
為節(jié)點(diǎn)進(jìn)行升配。具體操作,請參見升配Worker節(jié)點(diǎn)的資源。
更多信息,請參見節(jié)點(diǎn)CPU不足、節(jié)點(diǎn)內(nèi)存不足-MemoryPressure和節(jié)點(diǎn)磁盤空間不足-DiskPressure。
節(jié)點(diǎn)CPU不足
問題原因
通常是節(jié)點(diǎn)上的容器占用CPU過多導(dǎo)致節(jié)點(diǎn)的CPU不足。
問題現(xiàn)象
當(dāng)節(jié)點(diǎn)CPU不足時,可能會導(dǎo)致節(jié)點(diǎn)狀態(tài)異常。
若集群配置了集群節(jié)點(diǎn)異常報警,則節(jié)點(diǎn)CPU使用率>=85%時可收到相關(guān)報警。關(guān)于配置報警,請參見容器服務(wù)報警管理。
解決方案
通過節(jié)點(diǎn)的監(jiān)控查看CPU增長曲線,確認(rèn)異常出現(xiàn)時間點(diǎn),檢查節(jié)點(diǎn)上的進(jìn)程是否存在CPU占用過高的現(xiàn)象。具體操作,請參見檢查節(jié)點(diǎn)的監(jiān)控。
降低節(jié)點(diǎn)的負(fù)載,具體操作,請參見節(jié)點(diǎn)調(diào)度資源不足。
如需重啟節(jié)點(diǎn),可嘗試重啟異常節(jié)點(diǎn)。具體操作,請參見重啟實(shí)例。
警告重啟節(jié)點(diǎn)可能會導(dǎo)致您的業(yè)務(wù)中斷,請謹(jǐn)慎操作。
節(jié)點(diǎn)內(nèi)存不足-MemoryPressure
問題原因
通常是節(jié)點(diǎn)上的容器占用內(nèi)存過多導(dǎo)致節(jié)點(diǎn)的內(nèi)存不足。
問題現(xiàn)象
當(dāng)節(jié)點(diǎn)的可用內(nèi)存低于
memory.available配置項(xiàng)時,則節(jié)點(diǎn)狀態(tài)中MemoryPressure為True,同時該節(jié)點(diǎn)上的容器被驅(qū)逐。關(guān)于節(jié)點(diǎn)驅(qū)逐,請參見節(jié)點(diǎn)壓力驅(qū)逐。當(dāng)節(jié)點(diǎn)內(nèi)存不足時,會有以下常見錯誤信息:
節(jié)點(diǎn)狀態(tài)中MemoryPressure為True。
當(dāng)節(jié)點(diǎn)上的容器被驅(qū)逐時:
在被驅(qū)逐的容器事件中可看到關(guān)鍵字The node was low on resource: memory。
在節(jié)點(diǎn)事件中可看到關(guān)鍵字attempting to reclaim memory。
可能會導(dǎo)致系統(tǒng)OOM異常,當(dāng)出現(xiàn)系統(tǒng)OOM異常時,節(jié)點(diǎn)事件中可看到關(guān)鍵字System OOM。
若集群配置了集群節(jié)點(diǎn)異常報警,則節(jié)點(diǎn)內(nèi)存使用率>=85%時可收到相關(guān)報警。關(guān)于配置報警,請參見容器服務(wù)報警管理。
解決方案
通過節(jié)點(diǎn)的監(jiān)控查看內(nèi)存增長曲線,確認(rèn)異常出現(xiàn)時間點(diǎn),檢查節(jié)點(diǎn)上的進(jìn)程是否存在內(nèi)存泄露現(xiàn)象。具體操作,請參見檢查節(jié)點(diǎn)的監(jiān)控。
降低節(jié)點(diǎn)的負(fù)載,具體操作,請參見節(jié)點(diǎn)調(diào)度資源不足。
如需重啟節(jié)點(diǎn),可嘗試重啟異常節(jié)點(diǎn)。具體操作,請參見重啟實(shí)例。
警告重啟節(jié)點(diǎn)可能會導(dǎo)致您的業(yè)務(wù)中斷,請謹(jǐn)慎操作。
節(jié)點(diǎn)索引節(jié)點(diǎn)不足-InodesPressure
問題原因
通常是節(jié)點(diǎn)上的容器占用索引節(jié)點(diǎn)過多導(dǎo)致節(jié)點(diǎn)的索引節(jié)點(diǎn)不足。
問題現(xiàn)象
當(dāng)節(jié)點(diǎn)的可用索引節(jié)點(diǎn)低于
inodesFree配置項(xiàng)時,則節(jié)點(diǎn)狀態(tài)中InodesPressure為True,同時該節(jié)點(diǎn)上的容器被驅(qū)逐。關(guān)于節(jié)點(diǎn)驅(qū)逐,請參見節(jié)點(diǎn)壓力驅(qū)逐。當(dāng)節(jié)點(diǎn)索引點(diǎn)不足時,通常會有以下常見錯誤信息:
節(jié)點(diǎn)狀態(tài)中InodesPressure為True。
當(dāng)節(jié)點(diǎn)上的容器被驅(qū)逐時:
被驅(qū)逐的容器事件中可看到關(guān)鍵字The node was low on resource: inodes。
節(jié)點(diǎn)事件中可看到關(guān)鍵字attempting to reclaim inodes。
若集群配置了集群節(jié)點(diǎn)異常報警,則節(jié)點(diǎn)索引節(jié)點(diǎn)不足時可收到相關(guān)報警。關(guān)于配置報警,請參見容器服務(wù)報警管理。
解決方案
通過節(jié)點(diǎn)的監(jiān)控查看索引節(jié)點(diǎn)增長曲線,確認(rèn)異常出現(xiàn)時間點(diǎn),檢查節(jié)點(diǎn)上的進(jìn)程是否存在占用索引節(jié)點(diǎn)過多現(xiàn)象。具體操作,請參見檢查節(jié)點(diǎn)的監(jiān)控。
其他問題相關(guān)操作,請參見解決Linux實(shí)例磁盤空間滿問題。
節(jié)點(diǎn)PID不足-NodePIDPressure
問題原因
通常是節(jié)點(diǎn)上的容器占用PID過多導(dǎo)致節(jié)點(diǎn)的PID不足。
問題現(xiàn)象
當(dāng)節(jié)點(diǎn)的可用PID低于
pid.available配置項(xiàng)時,則節(jié)點(diǎn)狀態(tài)中NodePIDPressure為True,同時該節(jié)點(diǎn)上的容器被驅(qū)逐。關(guān)于節(jié)點(diǎn)驅(qū)逐,請參見節(jié)點(diǎn)壓力驅(qū)逐。若集群配置了集群節(jié)點(diǎn)異常報警,則節(jié)點(diǎn)PID不足時可收到相關(guān)報警。關(guān)于配置報警,請參見容器服務(wù)報警管理。
解決方案
執(zhí)行如下命令,查看節(jié)點(diǎn)的最大PID數(shù)和節(jié)點(diǎn)當(dāng)前的最大PID。
sysctl kernel.pid_max #查看最大PID數(shù)。 ps -eLf|awk '{print $2}' | sort -rn| head -n 1 #查看當(dāng)前的最大PID。執(zhí)行如下命令,查看占用PID最多的前5個進(jìn)程。
ps -elT | awk '{print $4}' | sort | uniq -c | sort -k1 -g | tail -5預(yù)期輸出:
#第一列為進(jìn)程占用的PID數(shù),第二列為當(dāng)前進(jìn)程號。 73 9743 75 9316 76 2812 77 5726 93 5691根據(jù)進(jìn)程號找到對應(yīng)進(jìn)程和所屬的Pod,分析占用PID過多的原因并優(yōu)化對應(yīng)代碼。
降低節(jié)點(diǎn)的負(fù)載。具體操作,請參見節(jié)點(diǎn)調(diào)度資源不足。
如需重啟節(jié)點(diǎn),可嘗試重啟異常節(jié)點(diǎn)。具體操作,請參見重啟實(shí)例。
警告重啟節(jié)點(diǎn)可能會導(dǎo)致您的業(yè)務(wù)中斷,請謹(jǐn)慎操作。
節(jié)點(diǎn)磁盤空間不足-DiskPressure
問題原因
通常是節(jié)點(diǎn)上的容器占用磁盤過多、鏡像文件過大導(dǎo)致節(jié)點(diǎn)的磁盤空間不足。
問題現(xiàn)象
當(dāng)節(jié)點(diǎn)的可用磁盤空間低于
imagefs.available配置項(xiàng)時,則節(jié)點(diǎn)狀態(tài)中DiskPressure為True。當(dāng)可用磁盤空間低于
nodefs.available配置項(xiàng)時,則該節(jié)點(diǎn)上的容器全部被驅(qū)逐。關(guān)于節(jié)點(diǎn)驅(qū)逐,請參見節(jié)點(diǎn)壓力驅(qū)逐。當(dāng)磁盤空間不足時,通常會有以下常見錯誤信息:
節(jié)點(diǎn)狀態(tài)中DiskPressure為True。
當(dāng)觸發(fā)鏡像回收策略后,磁盤空間仍然不足以達(dá)到健康閾值(默認(rèn)為80%),在節(jié)點(diǎn)事件中可看到關(guān)鍵字failed to garbage collect required amount of images。
當(dāng)節(jié)點(diǎn)上的容器被驅(qū)逐時:
被驅(qū)逐的容器事件中可看到關(guān)鍵字The node was low on resource: [DiskPressure]。
節(jié)點(diǎn)事件中可看到關(guān)鍵字attempting to reclaim ephemeral-storage或attempting to reclaim nodefs。
若集群配置了集群節(jié)點(diǎn)異常報警,則節(jié)點(diǎn)磁盤使用率>=85%時可收到相關(guān)報警。關(guān)于配置報警,請參見容器服務(wù)報警管理。
解決方案
通過節(jié)點(diǎn)的監(jiān)控查看磁盤增長曲線,確認(rèn)異常出現(xiàn)時間點(diǎn),檢查節(jié)點(diǎn)上的進(jìn)程是否存在占用磁盤空間過多的現(xiàn)象。具體操作,請參見檢查節(jié)點(diǎn)的監(jiān)控。
若有大量文件在磁盤上未清理,請清理文件。具體操作,請參見解決Linux實(shí)例磁盤空間滿問題。
根據(jù)自身業(yè)務(wù)情況,限制Pod的
ephemeral-storage資源配置。具體操作,請參見設(shè)置容器的CPU和內(nèi)存資源上下限。建議使用阿里云存儲產(chǎn)品,盡量避免使用HostPath數(shù)據(jù)卷。更多信息,請參見存儲CSI概述。
節(jié)點(diǎn)磁盤擴(kuò)容。
降低節(jié)點(diǎn)的負(fù)載。具體操作,請參見節(jié)點(diǎn)調(diào)度資源不足。
節(jié)點(diǎn)IP資源不足-InvalidVSwitchId.IpNotEnough
問題原因
通常是節(jié)點(diǎn)上的容器數(shù)過多導(dǎo)致IP資源不足。
問題現(xiàn)象
Pod啟動失敗,狀態(tài)為ContainerCreating。檢查Pod的日志有類似如下報錯,包含錯誤信息關(guān)鍵字InvalidVSwitchId.IpNotEnough。關(guān)于查看Pod日志的具體操作,請參見檢查Pod的日志。
time="2020-03-17T07:03:40Z" level=warning msg="Assign private ip address failed: Aliyun API Error: RequestId: 2095E971-E473-4BA0-853F-0C41CF52651D Status Code: 403 Code: InvalidVSwitchId.IpNotEnough Message: The specified VSwitch \"vsw-AAA\" has not enough IpAddress., retrying"若集群配置了集群節(jié)點(diǎn)異常報警,則節(jié)點(diǎn)IP資源不足時可收到相關(guān)報警。關(guān)于配置報警,請參見容器服務(wù)報警管理。
解決方案
降低節(jié)點(diǎn)上的容器數(shù)量。具體操作,請參見節(jié)點(diǎn)調(diào)度資源不足。其他相關(guān)操作,請參見Terway網(wǎng)絡(luò)場景中交換機(jī)的IP資源不足和Terway網(wǎng)絡(luò)模式擴(kuò)容vSwitch后,依然無法分配Pod IP怎么辦?。
節(jié)點(diǎn)網(wǎng)絡(luò)異常
問題原因
通常是節(jié)點(diǎn)運(yùn)行狀態(tài)異常、安全組配置有誤或網(wǎng)絡(luò)負(fù)載過高導(dǎo)致。
問題現(xiàn)象
節(jié)點(diǎn)無法登錄。
節(jié)點(diǎn)狀態(tài)Unknown。
若集群配置了集群節(jié)點(diǎn)異常報警,則節(jié)點(diǎn)公網(wǎng)流出帶寬使用率 >=85%時可收到相關(guān)報警。關(guān)于配置報警,請參見容器服務(wù)報警管理。
解決方案
若節(jié)點(diǎn)無法登錄,請參考以下步驟進(jìn)行排查:
檢查節(jié)點(diǎn)實(shí)例狀態(tài)是否為運(yùn)行中。
檢查節(jié)點(diǎn)的安全組配置。具體操作,請參見檢查節(jié)點(diǎn)的安全組。
若節(jié)點(diǎn)的網(wǎng)絡(luò)負(fù)載過高,請參考以下步驟進(jìn)行排查:
通過節(jié)點(diǎn)的監(jiān)控查節(jié)點(diǎn)網(wǎng)絡(luò)增長曲線,檢查節(jié)點(diǎn)上的Pod是否存在占用網(wǎng)絡(luò)帶寬過多的現(xiàn)象。具體操作,請參見檢查節(jié)點(diǎn)的監(jiān)控。
使用網(wǎng)絡(luò)策略控制Pod的網(wǎng)絡(luò)流量。具體操作,請參見在ACK集群使用網(wǎng)絡(luò)策略。
節(jié)點(diǎn)異常重啟
問題原因
通常是節(jié)點(diǎn)負(fù)載異常等原因?qū)е隆?/p>
問題現(xiàn)象
在節(jié)點(diǎn)重啟的過程中,節(jié)點(diǎn)狀態(tài)為NotReady。
若集群配置了集群節(jié)點(diǎn)異常報警,則節(jié)點(diǎn)異常重啟時可收到相關(guān)報警。關(guān)于配置報警,請參見容器服務(wù)報警管理。
解決方案
執(zhí)行以下命令,查看節(jié)點(diǎn)重啟時間。
last reboot預(yù)期輸出:

查看節(jié)點(diǎn)的監(jiān)控,根據(jù)重啟時間排查出現(xiàn)異常的資源。具體操作,請參見檢查節(jié)點(diǎn)的監(jiān)控 。
查看節(jié)點(diǎn)的內(nèi)核日志,根據(jù)重啟時間排查異常日志。具體操作,請參見檢查節(jié)點(diǎn)的診斷日志 。
如何解決auditd進(jìn)程占用大量磁盤IO或者系統(tǒng)日志中出現(xiàn)audit: backlog limit exceeded錯誤的問題
問題原因
部分集群的存量節(jié)點(diǎn)上默認(rèn)配置了Docker相關(guān)的auditd審計規(guī)則,當(dāng)節(jié)點(diǎn)使用了Docker容器運(yùn)行時,這些審計規(guī)則會觸發(fā)系統(tǒng)記錄Docker操作相關(guān)的審計日志。在某些情況下(節(jié)點(diǎn)上大量容器集中反復(fù)重啟、容器內(nèi)應(yīng)用短時間內(nèi)寫入海量文件、內(nèi)核Bug等),會低概率出現(xiàn)系統(tǒng)大量寫入審計日志影響節(jié)點(diǎn)磁盤IO,進(jìn)而出現(xiàn)auditd進(jìn)程占用大量磁盤IO的現(xiàn)象或者系統(tǒng)日志中出現(xiàn)audit: backlog limit exceeded錯誤的問題。
問題現(xiàn)象
該問題只影響使用Docker容器運(yùn)行時的節(jié)點(diǎn)。當(dāng)您在節(jié)點(diǎn)上執(zhí)行相關(guān)命令時,具體的問題現(xiàn)象如下:
執(zhí)行iotop -o -d 1命令時,結(jié)果顯示auditd進(jìn)程的
DISK WRITE指標(biāo)持續(xù)大于或等于1MB/s。執(zhí)行dmesg -d命令時,結(jié)果中存在包含關(guān)鍵字
audit_printk_skb的日志。比如audit_printk_skb: 100 callbacks suppressed。執(zhí)行dmesg -d命令時,結(jié)果中存在關(guān)鍵字
audit: backlog limit exceeded。
解決方案
您可以通過以下操作,檢查您的節(jié)點(diǎn)中出現(xiàn)的以上問題是否與節(jié)點(diǎn)的auditd配置有關(guān):
登錄集群節(jié)點(diǎn)。
執(zhí)行以下命令,檢查auditd規(guī)則。
sudo auditctl -l | grep -- ' -k docker'如果該命令的輸出中包含如下信息,說明該節(jié)點(diǎn)出現(xiàn)的問題與auditd配置有關(guān)。
-w /var/lib/docker -k docker
如果通過以上檢查確認(rèn)是該問題影響了集群節(jié)點(diǎn),您可以選擇以下三種解決方案的任一方案解決問題。
升級集群版本
您可以通過升級集群版本來修復(fù)該問題。具體操作,請參見升級ACK集群K8s版本。
使用Containerd容器運(yùn)行時
對于無法升級的集群,可以通過使用Containerd代替Docker作為節(jié)點(diǎn)容器運(yùn)行時的方法規(guī)避該問題。需要對每個使用Docker容器運(yùn)行時的節(jié)點(diǎn)池進(jìn)行如下操作:
通過克隆節(jié)點(diǎn)池的方式新建一個以Containerd為容器運(yùn)行時的節(jié)點(diǎn)池,同時確保新節(jié)點(diǎn)池除容器運(yùn)行時配置外的其他配置都與被克隆的目標(biāo)節(jié)點(diǎn)池保持一致。
在業(yè)務(wù)低峰期對目標(biāo)節(jié)點(diǎn)池內(nèi)的節(jié)點(diǎn)逐個進(jìn)行排空節(jié)點(diǎn)操作,確保已無業(yè)務(wù)服務(wù)部署在目標(biāo)節(jié)點(diǎn)池中。
更新節(jié)點(diǎn)上的auditd配置
對于無法升級集群也不能使用Containerd容器運(yùn)行時的場景,可以通過手動更新節(jié)點(diǎn)上的auditd配置的方法規(guī)避該問題。需要對每個使用Docker容器運(yùn)行時的節(jié)點(diǎn)進(jìn)行如下操作:
說明您可以對節(jié)點(diǎn)進(jìn)行批量操作,具體操作,請參見批量運(yùn)維節(jié)點(diǎn)。
登錄集群節(jié)點(diǎn)。
執(zhí)行以下命令,刪除Docker相關(guān)的auditd規(guī)則。
sudo test -f /etc/audit/rules.d/audit.rules && sudo sed -i.bak '/ -k docker/d' /etc/audit/rules.d/audit.rules sudo test -f /etc/audit/audit.rules && sudo sed -i.bak '/ -k docker/d' /etc/audit/audit.rules執(zhí)行以下命令,應(yīng)用新的auditd規(guī)則。
if service auditd status |grep running || systemctl status auditd |grep running; then sudo service auditd restart || sudo systemctl restart auditd sudo service auditd status || sudo systemctl status auditd fi