本文為您介紹使用網絡插件Terway或Flannel遇到的常見問題,以及如何解決。例如,如何選擇網絡插件、集群是否支持安裝第三方網絡插件、如何規劃集群網絡等。
索引
Terway相關
Flannel相關
kube-proxy相關
IPv6相關
ACK容器網絡數據鏈路
其他
已經創建的ACK集群是否支持切換網絡插件?
網絡插件類型(Terway和Flannel)僅支持在集群創建階段選擇,集群創建后不支持修改。如需切換,請重新創建集群,具體操作,請參見創建ACK托管集群。
Terway網絡模式下增加了虛擬交換機后,集群無法訪問公網怎么辦?
問題現象
在Terway網絡下,因Pod沒有IP資源而手動增加虛擬交換機,在增加虛擬交換機后,發現集群不能正常訪問公網。
問題原因
Pod IP所屬的虛擬交換機不具備公網訪問的能力。
解決方法
您可以通過NAT網關的SNAT功能,為Pod IP所屬的虛擬交換機配置公網SNAT規則。更多信息,請參見為已有集群開啟公網訪問能力。
手動升級了Flannel鏡像版本后,如何解決無法兼容1.16以上版本集群的問題?
問題現象
集群版本升級到1.16之后,集群節點變成NotReady。
問題原因
手動升級了Flannel版本,而并沒有升級Flannel的配置,導致Kubelet無法識別。
解決方法
執行以下命令,編輯Flannel,增加
cniVersion字段。kubectl edit cm kube-flannel-cfg -n kube-system返回結果中增加
cniVersion字段。"name": "cb0", "cniVersion":"0.3.0", "type": "flannel",執行以下命令,重啟Flannel。
kubectl delete pod -n kube-system -l app=flannel
如何解決Pod啟動后存在時延的問題?
問題現象
Pod啟動后網絡需要延遲一會才能通信。
問題原因
配置Network Policy會有一定的時延,關閉Network Policy后,就能解決該問題。
解決方法
執行以下命令,修改Terway的ConfigMap,增加禁用NetworkPolicy的配置。
kubectl edit cm -n kube-system eni-config在返回結果中增加以下字段。
disable_network_policy: "true"可選:如果Terway版本不是最新的,請在控制臺升級Terway版本。
登錄容器服務管理控制臺,在左側導航欄選擇集群。
在集群列表頁面,單擊目標集群名稱,然后在左側導航欄,選擇。
在組件管理頁面,單擊網絡頁簽,單擊目標Terway組件區域的升級。
在提示對話框,單擊確定。
執行以下命令,重啟所有Terway的Pod。
kubectl delete pod -n kube-system -l app=terway-eniip
如何讓Pod訪問自己暴露的服務?
問題現象
Pod無法訪問自己暴露的服務,存在時好時壞或者調度到自己就出問題的現象。
問題原因
Flannel集群可能未開啟回環訪問。
低于v0.15.1.4-e02c8f12-aliyun版本的Flannel不允許回環訪問。升級版本后,仍默認不允許回環訪問,但可以手動開啟。
只有全新部署的v0.15.1.4-e02c8f12-aliyun及以上版本的Flannel,才默認開啟回環訪問。
解決方法
使用Headless Service暴露服務和訪問,具體操作,請參見Headless Services。
說明推薦使用此方法。
重建集群使用Terway的網絡插件,具體操作,請參見使用Terway網絡插件。
修改Flannel的配置,然后重建Flannel和Pod。
說明不推薦此方法,可能會被后續升級覆蓋。
執行以下命令編輯cni-config.json。
kubectl edit cm kube-flannel-cfg -n kube-system在返回結果的
delegate中增加hairpinMode: true。示例如下:
cni-conf.json: | { "name": "cb0", "cniVersion":"0.3.1", "type": "flannel", "delegate": { "isDefaultGateway": true, "hairpinMode": true } }執行以下命令,重啟Flannel。
kubectl delete pod -n kube-system -l app=flannel刪除并重新創建Pod。
如何選擇Kubernetes集群Terway和Flannel網絡插件?
下面為您詳細介紹在ACK創建集群時使用的兩種網絡插件:Terway和Flannel。
在創建Kubernetes集群時,阿里云容器服務提供以下兩種網絡插件:
Flannel:使用的是簡單穩定的社區的Flannel CNI插件,配合阿里云的VPC的高速網絡,能給集群高性能和穩定的容器網絡體驗,但功能偏簡單,支持的特性少,例如:不支持基于Kubernetes標準的Network Policy。
Terway:是阿里云容器服務自研的網絡插件,功能上完全兼容Flannel,支持將阿里云的彈性網卡分配給容器,支持基于Kubernetes標準的NetworkPolicy來定義容器間的訪問策略,支持對單個容器做帶寬的限流。對于不需要使用Network Policy的用戶,可以選擇Flannel,其他情況建議選擇Terway。了解更多Terway網絡插件的相關內容,請參見使用Terway網絡插件。
如何規劃集群網絡?
在創建ACK集群時,需要指定專有網絡VPC、虛擬交換機、Pod網絡CIDR(地址段)和Service CIDR(地址段)。建議您提前規劃ECS地址、Kubernetes Pod地址和Service地址。詳情請參見Kubernetes集群網絡規劃。
ACK是否支持hostPort的端口映射?
只有Flannel插件支持hostPort,其他插件暫不支持hostPort。
容器服務ACK的Pod地址是可以直接被VPC中其他資源訪問的,不需要額外的端口映射。
如果需要把服務暴露到外部,可以使用NodePort或者LoadBalancer類型的Service。
如何查看集群的網絡類型及對應的虛擬交換機?
ACK支持兩種容器網絡類型,分別是Flannel網絡類型和Terway網絡類型。
通過以下步驟查看您創建集群時所選擇的網絡類型
登錄容器服務管理控制臺,在左側導航欄單擊集群。
在集群列表頁面中,單擊目標集群名稱或者目標集群右側操作列下的詳情。
單擊基本信息頁簽,在集群信息區域查看集群的容器網絡類型,即網絡插件右側的值。
如果網絡插件右側顯示terway-eniip ,則容器的網絡類型為Terway網絡。
如果網絡插件右側顯示Flannel,則容器的網絡類型為Flannel網絡。
通過以下步驟查看對應網絡類型使用的節點虛擬交換機
登錄容器服務管理控制臺,在左側導航欄單擊集群。
在集群列表頁面,單擊目標集群名稱,然后在左側導航欄,選擇。
在節點池頁面,單擊目標節點池右側操作列下的詳情。
在節點配置區域查看節點虛擬交換機ID。
通過以下步驟查詢Terway網絡類型使用的Pod虛擬交換機ID
只有Terway網絡類型使用Pod虛擬交換機,Flannel網絡類型無需使用Pod虛擬交換機。
登錄容器服務管理控制臺,在左側導航欄單擊集群。
在集群列表中單擊目標集群名稱或目標集群右側操作列下的詳情。
在集群信息頁面,單擊基本信息頁簽,然后查看Pod虛擬交換機ID。
如何查看集群中使用的云資源?
通過以下步驟查看集群中使用的云資源信息,包括虛擬機、虛擬專有網絡VPC、Worker RAM角色等。
登錄容器服務管理控制臺,在左側導航欄單擊集群。
在集群列表頁面中,單擊目標集群名稱或者目標集群右側操作列下的詳情。
單擊基本信息頁簽,查看集群中使用的云資源信息。
如何修改kube-proxy配置?
ACK托管版默認部署kube-proxy-worker DaemonSet作為負載均衡,可通過其同名配置項kube-proxy-worker ConfigMap控制其參數。如果您使用的是ACK專有版,您在集群中會額外部署kube-proxy-master DaemonSet和同名配置項,其會運行于Master節點上。
kube-proxy配置項均兼容社區KubeProxyConfiguration標準,您可以參考社區KubeProxyConfiguration標準進行自定義配置,更多信息,請參見kube-proxy Configuration。kube-proxy配置文件對格式要求嚴格,請勿漏填冒號和空格。修改kube-proxy配置操作如下:
如果您使用的是托管版集群,您需要修改kube-proxy-worker的配置。
登錄容器服務管理控制臺,在左側導航欄單擊集群。
在集群列表頁面,單擊目標集群名稱,然后在左側導航欄,選擇。
在頂部選擇kube-system命名空間,然后單擊配置項kube-proxy-worker右側的YAML編輯。
在查看YAML面板上修改參數,然后單擊確定。
重建所有名為kube-proxy-worker的容器,使配置生效。
重要kube-proxy的重啟不會導致已有運行業務中斷,如果有并發業務發布,新啟動的業務在kube-proxy的生效時間會略有延遲,請盡量于業務低峰期操作。
在集群管理頁左側導航欄中,選擇。
在守護進程集列表中,找到并單擊kube-proxy-worker。
在kube-proxy-worker頁面的容器組頁簽下,選擇,然后單擊確定。
重復操作刪除所有容器組。刪除容器組后,系統會自動重建所有容器。
如果您使用的是專有版集群,您需要修改kube-proxy-worker和kube-proxy-master的配置,然后刪除kube-proxy-worker和kube-proxy-master Pod,該Pod自動重新創建后會使配置生效。具體操作,請參見上文。
如何提升Linux連接跟蹤Conntrack數量限制?
內核日志(dmesg)中出現conntrack full的報錯日志,說明Conntrack數量已經達到conntrack_max數量限制。您需要提升Linux連接跟蹤Conntrack數量限制。
執行
conntrack -L命令,確認目前Conntrack中的各協議占用情況。如果出現大量TCP協議的占用,您需要確認具體業務,如果是短連接型應用可以考慮整改成長連接型。
如果出現大量DNS的占用,您需要在ACK集群中使用NodeLocal DNSCache,提高DNS的性能,具體操作,請參見使用NodeLocal DNSCache。
如果Conntrack實際占用情況合理,或者您不希望對業務進行整改,您可以通過配置kube-proxy增加maxPerCore參數,調整連接跟蹤數量限制。
如果您使用的是托管版集群,您需要在kube-proxy-worker中增加maxPerCore參數,并設置其值為65536或更高的數值,然后刪除kube-proxy-worker Pod,該Pod自動重新創建后會使配置生效。關于如何修改并刪除kube-proxy-worker,請參見如何修改kube-proxy配置?。
apiVersion: v1 kind: ConfigMap metadata: name: kube-proxy-worker namespace: kube-system data: config.conf: | apiVersion: kubeproxy.config.k8s.io/v1alpha1 kind: KubeProxyConfiguration featureGates: IPv6DualStack: true clusterCIDR: 172.20.0.0/16 clientConnection: kubeconfig: /var/lib/kube-proxy/kubeconfig.conf conntrack: maxPerCore: 65536 # 需設置maxPerCore至合理值,此處65536為默認設置。 mode: ipvs # 其它略如果您使用的是專有版集群,您需要在kube-proxy-worker和kube-proxy-master中增加maxPerCore參數,并設置其值為65536或更高的數值,然后刪除kube-proxy-worker和kube-proxy-master Pod,該Pod自動重新創建后會使配置生效。關于如何修改并刪除kube-proxy-worker和kube-proxy-master,請參見如何修改kube-proxy配置?。
如何修改kube-proxy中IPVS負載均衡模式?
您可以通過修改kube-proxy中IPVS負載均衡模式來解決大量長連接的負載不均問題,具體操作如下:
選擇合適的調度算法。關于如何選擇合適的調度算法,請參見K8s官方文檔parameter-changes。
早于2022年10月創建的集群節點可能未默認啟用所有IPVS調度算法,您需要手動在所有集群節點上啟用IPVS調度算法內核模塊(以最小連接數調度算法lc為例,如果選用其他算法,請替換lc關鍵字),逐臺登錄每個節點,并運行lsmod | grep ip_vs_lc查看是否有輸出。
如果命令輸出ip_vs_lc,則說明調度算法內核模塊已經加載,可以跳過本步驟。
如果沒有加載,運行modprobe ip_vs_lc使節點立即生效,并運行echo "ip_vs_lc" >> /etc/modules-load.d/ack-ipvs-modules.conf使機器重啟后生效。
設置kube-proxy中的ipvs scheduler參數值為合理的調度算法。
如果您使用的是托管版集群,您需要修改kube-proxy-worker的ipvs scheduler參數值為合理的調度算法,然后刪除kube-proxy-worker Pod,該Pod自動重新創建后會使配置生效。關于如何修改并刪除kube-proxy-worker,請參見如何修改kube-proxy配置?。
apiVersion: v1 kind: ConfigMap metadata: name: kube-proxy-worker namespace: kube-system data: config.conf: | apiVersion: kubeproxy.config.k8s.io/v1alpha1 kind: KubeProxyConfiguration featureGates: IPv6DualStack: true clusterCIDR: 172.20.0.0/16 clientConnection: kubeconfig: /var/lib/kube-proxy/kubeconfig.conf conntrack: maxPerCore: 65536 mode: ipvs ipvs: scheduler: lc # 需設置scheduler成合理的調度算法。 # 其它略如果您使用的是專有版集群,您需要修改kube-proxy-worker和kube-proxy-master中的ipvs scheduler參數值為合理的調度算法,然后刪除kube-proxy-worker和kube-proxy-master Pod,該Pod自動重新創建后會使配置生效。關于如何修改并刪除kube-proxy-worker和kube-proxy-master,請參見如何修改kube-proxy配置?。
查看kube-proxy運行日志。
通過kubectl get pods命令查看kube-system命名空間下新建的kube-proxy-worker容器(如果您使用專有版集群,還需查看kube-proxy-master)是否為Running狀態。
通過kubectl logs命令查看新建容器的日志。
如果出現Can't use the IPVS proxier: IPVS proxier will not be used because the following required kernel modules are not loaded: [ip_vs_lc]則說明IPVS調度算法內核模塊未成功加載,您需要檢查上述步驟是否已經正確執行,并嘗試重試。
如果出現Using iptables Proxier.說明kube-proxy無法啟用IPVS模塊,開始自動回退使用iptables模式,此時建議先回滾kube-proxy配置,再對機器進行重啟操作。
如果未出現上述日志,并顯示Using ipvs Proxier.說明IPVS模塊成功啟用。
如果上述檢查均返回正常,說明變更成功。
如何修改kube-proxy中IPVS UDP會話保持的超時時間?
如果您的ACK集群使用了kube-proxy IPVS模式,IPVS的默認會話保持策略會使UDP協議后端在摘除后五分鐘內出現概率性丟包的問題。如果您業務依賴于CoreDNS,當CoreDNS組件升級或所在節點重啟時,您可能會在五分鐘內遇到業務接口延遲、請求超時等現象。
若您在ACK集群中的業務沒有使用UDP協議,您可以通過降低IPVS UDP協議的會話保持的超時時間來減少解析延遲或失敗的影響時間。具體操作如下:
若您的自有業務使用了UDP協議,請提交工單咨詢。
K8s 1.18及以上版本集群
如果您使用的是托管版集群,您需要在kube-proxy-worker中修改udpTimeout參數值。然后刪除kube-proxy-worker Pod,該Pod自動重新創建后會使配置生效。關于如何修改并刪除kube-proxy-worker,請參見如何修改kube-proxy配置?。
apiVersion: v1 kind: ConfigMap metadata: name: kube-proxy-worker namespace: kube-system data: config.conf: | apiVersion: kubeproxy.config.k8s.io/v1alpha1 kind: KubeProxyConfiguration # 其它不相關字段已省略。 mode: ipvs # 如果ipvs鍵不存在,需要添加此鍵。 ipvs: udpTimeout: 10s # 此處默認為300秒,調整成10秒可以將IPVS UDP類型后端摘除后丟包問題的影響時間縮短到10秒。如果您使用的是專有版集群,您需要在kube-proxy-worker和kube-proxy-master中修改udpTimeout參數值。然后刪除kube-proxy-worker和kube-proxy-master Pod,該Pod自動重新創建后會使配置生效。關于如何修改并刪除kube-proxy-worker,請參見如何修改kube-proxy配置?。
K8s 1.16及以下版本集群
此類版本集群的kube-proxy不支持udpTimeout參數,推薦使用系統運維管理 OOS(CloudOps Orchestration Service)批量在所有集群機器上執行
ipvsadm命令以調整UDP超時時間配置。命令如下:yum install -y ipvsadm ipvsadm -L --timeout > /tmp/ipvsadm_timeout_old ipvsadm --set 900 120 10 ipvsadm -L --timeout > /tmp/ipvsadm_timeout_new diff /tmp/ipvsadm_timeout_old /tmp/ipvsadm_timeout_new關于OOS的批量操作實例介紹,請參見批量操作實例。
如何解決IPv6雙棧的部分常見問題?
問題現象:在kubectl中顯示的Pod IP仍然是IPv4地址。
解決方法:執行以下命令,展示Pod IPs字段,預期輸出IPv6地址。
kubectl get pods -A -o jsonpath='{range .items[*]}{@.metadata.namespace} {@.metadata.name} {@.status.podIPs[*].ip} {"\n"}{end}'問題現象:在kubectl中顯示的Cluster IP仍然是IPv4地址。
解決方法:
請確認spec.ipFamilyPolicy配置的不是SingleStack。
執行以下命令,展示Cluster IPs字段,預期輸出IPv6地址。
kubectl get svc -A -o jsonpath='{range .items[*]}{@.metadata.namespace} {@.metadata.name} {@.spec.ipFamilyPolicy} {@.spec.clusterIPs[*]} {"\n"}{end}'
問題現象:無法通過IPv6地址訪問Pod。
問題原因:部分應用默認不監聽IPv6地址,例如Nginx容器。
解決方法:執行
netstat -anp命令,確認Pod已監聽IPv6地址。預期輸出:
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name tcp 0 0 127.0.XX.XX:10248 0.0.0.0:* LISTEN 8196/kubelet tcp 0 0 127.0.XX.XX:41935 0.0.0.0:* LISTEN 8196/kubelet tcp 0 0 0.0.XX.XX:111 0.0.0.0:* LISTEN 598/rpcbind tcp 0 0 0.0.XX.XX:22 0.0.0.0:* LISTEN 3577/sshd tcp6 0 0 :::30500 :::* LISTEN 1916680/kube-proxy tcp6 0 0 :::10250 :::* LISTEN 8196/kubelet tcp6 0 0 :::31183 :::* LISTEN 1916680/kube-proxy tcp6 0 0 :::10255 :::* LISTEN 8196/kubelet tcp6 0 0 :::111 :::* LISTEN 598/rpcbind tcp6 0 0 :::10256 :::* LISTEN 1916680/kube-proxy tcp6 0 0 :::31641 :::* LISTEN 1916680/kube-proxy udp 0 0 0.0.0.0:68 0.0.0.0:* 4892/dhclient udp 0 0 0.0.0.0:111 0.0.0.0:* 598/rpcbind udp 0 0 47.100.XX.XX:323 0.0.0.0:* 6750/chronyd udp 0 0 0.0.0.0:720 0.0.0.0:* 598/rpcbind udp6 0 0 :::111 :::* 598/rpcbind udp6 0 0 ::1:323 :::* 6750/chronyd udp6 0 0 fe80::216:XXXX:fe03:546 :::* 6673/dhclient udp6 0 0 :::720 :::* 598/rpcbindProto顯示為tcp即監聽IPv4地址,顯示為tcp6即監聽IPv6地址。問題現象:通過IPv6地址可以在集群內訪問Pod,但無法從公網訪問。
問題原因:該IPv6地址可能未配置公網帶寬。
解決方法:配置該IPv6地址的公網帶寬。具體操作,請參見開通和管理IPv6公網帶寬。
問題現象:無法通過IPv6 Cluster IP訪問Pod。
解決方法:
請確認spec.ipFamilyPolicy配置的不是SingleStack。
執行
netstat -anp命令,確認Pod已監聽IPv6地址。預期輸出:
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name tcp 0 0 127.0.XX.XX:10248 0.0.0.0:* LISTEN 8196/kubelet tcp 0 0 127.0.XX.XX:41935 0.0.0.0:* LISTEN 8196/kubelet tcp 0 0 0.0.XX.XX:111 0.0.0.0:* LISTEN 598/rpcbind tcp 0 0 0.0.XX.XX:22 0.0.0.0:* LISTEN 3577/sshd tcp6 0 0 :::30500 :::* LISTEN 1916680/kube-proxy tcp6 0 0 :::10250 :::* LISTEN 8196/kubelet tcp6 0 0 :::31183 :::* LISTEN 1916680/kube-proxy tcp6 0 0 :::10255 :::* LISTEN 8196/kubelet tcp6 0 0 :::111 :::* LISTEN 598/rpcbind tcp6 0 0 :::10256 :::* LISTEN 1916680/kube-proxy tcp6 0 0 :::31641 :::* LISTEN 1916680/kube-proxy udp 0 0 0.0.0.0:68 0.0.0.0:* 4892/dhclient udp 0 0 0.0.0.0:111 0.0.0.0:* 598/rpcbind udp 0 0 47.100.XX.XX:323 0.0.0.0:* 6750/chronyd udp 0 0 0.0.0.0:720 0.0.0.0:* 598/rpcbind udp6 0 0 :::111 :::* 598/rpcbind udp6 0 0 ::1:323 :::* 6750/chronyd udp6 0 0 fe80::216:XXXX:fe03:546 :::* 6673/dhclient udp6 0 0 :::720 :::* 598/rpcbindProto顯示為tcp即監聽IPv4地址,顯示為tcp6即監聽IPv6地址。問題現象:Pod無法通過IPv6訪問公網。
解決方法:對IPv6使用公網,需要開通IPv6網關,并對IPv6地址配置公網帶寬。詳細信息,請參見創建和管理IPv6網關和開通和管理IPv6公網帶寬。
Terway網絡插件下交換機的IP資源不足怎么辦?
問題描述
在創建Pod時發現無法創建,登錄VPC控制臺,選擇目標地域,在左側導航欄單擊交換機,查看集群使用的交換機(vSwitch)信息,發現該vSwitch可用IP數為0。如何進一步確認問題請參見更多信息。
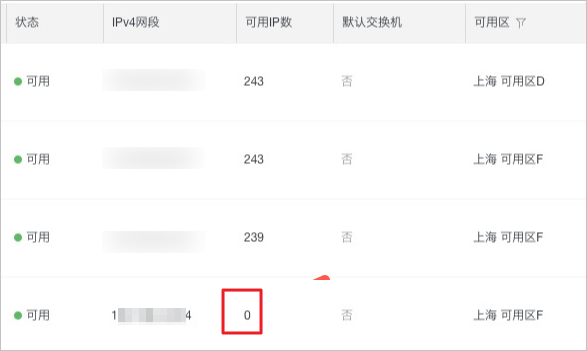
問題原因
該節點的Terway所使用的vSwitch沒有空余IP地址,導致Pod會因為沒有IP資源而一直處于ContainerCreating狀態。
解決方案
您可以參考以下內容,擴容vSwitch,即添加新的vSwitch,擴容集群的IP資源:
登錄VPC控制臺,選擇目標地域,創建新的vSwitch。
說明該vSwitch必須與IP資源不足的vSwitch在同一個地域和可用區。如果Pod密度越來越大,建議給Pod使用的vSwitch網段的網絡位小于等于19,也就是網段至少包含8192個IP地址。
參考以下命令,刪除全部Terway Pod,刪除后Terway Pod會重新創建。
說明如果您在創建集群時,使用Terway并勾選了Pod獨占彈性網卡以獲得最佳性能,說明您是ENI單IP;沒有勾選則是ENI多IP,詳細信息請參見Terway網絡插件。
針對ENI多IP場景:
kubectl delete -n kube-system pod -l app=terway-eniip針對ENI單IP場景:
kubectl delete -n kube-system pod -l app=terway-eni
然后執行
kubectl get pod命令,確認全部Terway Pod重建成功。創建新的Pod,確認Pod創建成功且可以重新vSwitch成功分配獲得IP。
更多信息
連接Kubernetes集群,如何連接請參見通過kubectl連接Kubernetes集群,執行kubectl get pod命令,發現Pod狀態為ContainerCreating。執行以下命令,查看Pod所在節點上的Terway容器的日志。
kubectl get pod -l app=terway-eniip -n kube-system | grep [$Node_Name] # [$Node_Name] 為Pod所在節點的節點名,用來找出該節點上的Terway Pod的名稱
kubectl logs --tail=100 -f [$Pod_Name] -n kube-system -c terway # [$Pod_Name]為Pod所在節點上的Terway Pod的名稱。系統顯示類似如下,出現類似InvalidVSwitchId.IpNotEnough錯誤信息,表明存在交換機IP不足的情況。
time="2020-03-17T07:03:40Z" level=warning msg="Assign private ip address failed: Aliyun API Error: RequestId: 2095E971-E473-4BA0-853F-0C41CF52651D Status Code: 403 Code: InvalidVSwitchId.IpNotEnough Message: The specified VSwitch \"vsw-AAA\" has not enough IpAddress., retrying"Terway網絡模式下,Pod分配的IP不在虛擬交換機網段中怎么辦?
問題現象
在Terway網絡下,創建的Pod IP不在配置的虛擬交換機網段內。
問題原因
Pod IP來源于VPC地址,并且通過ENI分配給容器使用。只有在新建ENI時,才可以配置虛擬交換機。如果ENI已經創建,則Pod IP將繼續從該ENI對應的虛擬交換機中分配。
通常以下兩個使用場景會遇到該問題:
納管一個節點到集群內,但這個節點之前在其他集群使用,且刪除節點時沒有排空節點Pod。這種情況下節點上可能殘留之前集群使用的ENI資源。
手動增加、修改Terway使用的虛擬交換機配置,由于節點上可能還存在原有配置的ENI,則新建的Pod將可能繼續使用原有ENI上的IP。
解決方法
您可以通過新建節點、輪轉老節點的方式來確保配置文件在新節點上生效。
輪轉老節點操作步驟如下:
Terway網絡模式擴容vSwitch后,依然無法分配Pod IP怎么辦?
問題現象
在Terway網絡下,Terway網絡模式擴容vSwitch后依然無法分配Pod IP。
問題原因
Pod IP來源于VPC地址,并且通過ENI分配給容器使用。只有在新建ENI時,才可以配置虛擬交換機。如果ENI已經創建,則Pod IP將繼續從該ENI對應的虛擬交換機中分配。由于節點上ENI配額已經用完,無法新建ENI,也就無法讓新配置生效。關于ENI配額的具體信息,請參見彈性網卡概述。
解決方法
您可以通過新建節點、輪轉老節點的方式來確保配置文件在新節點上生效。
輪轉老節點操作步驟如下:
如何為Terway IPvlan集群開啟集群內負載均衡?
問題現象
在IPvlan模式下,v1.2.0及以上版本的Terway,新建的集群默認開啟集群內負載均衡功能。在集群內訪問ExternalIP,LoadBalancer流量將被負載到Service網絡。如何為已創建的Terway IPvlan集群開啟集群內負載均衡?
問題原因
Kube-Proxy會短路集群內訪問ExternalIP、LoadBalancer的流量,即集群內訪問這些外部地址,實際流量不會到外部,而會被轉為對應后端的Endpoint直接訪問。在Terway IPvlan模式下,Pod訪問這些地址流量由Cilium而不是kube-proxy進行處理, 在Terway v1.2.0之前版本并不支持這種鏈路的短路。在Terway v1.2.0版本發布后,新建集群將默認開啟該功能,已創建的集群不會開啟。
解決方法
Terway需要v1.2.0及以上版本,且使用IPvlan模式。
如果集群未啟用IPvlan模式,則該配置無效,無需配置。
新建集群此功能默認開啟,無需配置。
執行以下命令,修改Terway的配置ConfigMap。
kubectl edit cm eni-config -n kube-system在eni_conf中增加以下內容。
in_cluster_loadbalance: "true"說明請保持
in_cluster_loadbalance和eni_conf在同級別。執行以下命令,重建Terway Pod,使集群內負載均衡配置生效。
kubectl delete pod -n kube-system -l app=terway-eniip驗證配置
執行以下命令,檢查terway-ennip中policy日志,如果顯示
enable-in-cluster-loadbalance=true則配置生效。kubectl logs -n kube-system <terway pod name> policy | grep enable-in-cluster-loadbalance
如何在ACK中對Terway網絡下的Pod指定網段加白?
問題現象
您通常需要在一些類似數據庫之類的服務設置白名單,以此來給服務提供更安全的訪問控制能力。在容器網絡下同樣有此需求,需要在容器中給動態變化的Pod IP設置白名單。
問題原因
ACK的容器網絡主要有Flannel和Terway兩種:
在Flannel網絡下,因為Pod是通過節點訪問其他服務,所以在Flannel網絡下的數據庫設置白名單時,首先可以將客戶端Pod通過節點綁定的方式調度到固定的少數節點上去,然后在數據庫側直接對節點的IP地址做加白操作即可。
在Terway網絡下,Pod IP是通過ENI提供。Pod通過ENI訪問外部服務,外部服務得到的客戶端IP是ENI提供的IP地址,即使把Pod和節點設置了親和性綁定,Pod訪問外部服務的客戶端IP仍然是ENI提供的IP而不是節點的IP。Pod IP還是會從Terway指定的vSwitch中隨機分配IP地址,而且客戶端Pod通常都會有自動伸縮之類的配置,那即使能固定Pod IP也很難滿足彈性伸縮的場景,建議直接給客戶端指定一個網段來分配IP,然后在數據庫側對這個網段來做加白操作。
解決方法
通過給指定節點添加標簽來指定Pod使用的vSwitch,從而當Pod調度到有固定標簽的節點上時,該Pod就可以通過自定義的vSwitch去創建Pod IP。
在kube-system命名空間下單獨創建一個名稱為eni-config-fixed的ConfigMap ,其中需要指定專門的vSwitch。
本示例以vsw-2zem796p76viir02c****,10.2.1.0/24為例。
apiVersion: v1 data: eni_conf: | { "vswitches": {"cn-beijing-h":["vsw-2zem796p76viir02c****"]}, "security_group": "sg-bp19k3sj8dk3dcd7****", "security_groups": ["sg-bp1b39sjf3v49c33****","sg-bp1bpdfg35tg****"] } kind: ConfigMap metadata: name: eni-config-fixed namespace: kube-system創建節點池,為節點打上標簽
terway-config:eni-config-fixed。關于創建節點池的具體操作,請參見操作步驟。為了保證該節點池內的節點上不會出現其他Pod,可以給該節點池同時配置上污點,例如
fixed=true:NoSchedule。
擴容該節點池。具體操作,請參見擴縮容ACK集群的節點。
通過該節點池擴容出來的節點默認會帶有上一步設置的節點標簽和污點。
創建Pod,調度到已有
terway-config:eni-config-fixed標簽的節點上,需要添加容忍。apiVersion: apps/v1 # 1.8.0以前的版本請使用apps/v1beta1。 kind: Deployment metadata: name: nginx-fixed labels: app: nginx-fixed spec: replicas: 2 selector: matchLabels: app: nginx-fixed template: metadata: labels: app: nginx-fixed spec: tolerations: # 添加容忍。 - key: "fixed" operator: "Equal" value: "true" effect: "NoSchedule" nodeSelector: terway-config: eni-config-fixed containers: - name: nginx image: nginx:1.9.0 #替換成您實際的鏡像<image_name:tags>。 ports: - containerPort: 80結果驗證
執行以下命令,查看Pod IP。
kubectl get po -o wide | grep fixed預期輸出:
nginx-fixed-57d4c9bd97-l**** 1/1 Running 0 39s 10.2.1.124 bj-tw.062149.aliyun.com <none> <none> nginx-fixed-57d4c9bd97-t**** 1/1 Running 0 39s 10.2.1.125 bj-tw.062148.aliyun.com <none> <none>可以看到Pod IP已經從指定的vSwitch分配。
執行以下命令,將Pod擴容到30個。
kubectl scale deployment nginx-fixed --replicas=30預期輸出:
nginx-fixed-57d4c9bd97-2**** 1/1 Running 0 60s 10.2.1.132 bj-tw.062148.aliyun.com <none> <none> nginx-fixed-57d4c9bd97-4**** 1/1 Running 0 60s 10.2.1.144 bj-tw.062149.aliyun.com <none> <none> nginx-fixed-57d4c9bd97-5**** 1/1 Running 0 60s 10.2.1.143 bj-tw.062148.aliyun.com <none> <none> ...可以看到生成的Pod IP全部在指定的vSwitch下,然后在數據庫側直接對此vSwitch做加白操作,從而實現對動態Pod IP的訪問控制。
建議您使用新創建的節點,如果使用已有節點,需要在節點添加進集群之前先將ENI和ECS實例解綁,再添加進集群。添加方式要選用自動添加已有節點(替換系統盤)。具體操作,請參見解綁輔助彈性網卡和自動添加節點。
注意給特定的節點池打上標簽和污點,盡可能保證不需要加白的業務不會調度到這部分節點上。
這個設置白名單的方法其實是配置覆蓋,ACK會用現在指定的ConfigMap里的配置來覆蓋之前的eni-config的配置,關于配置參數的具體信息,請參見Terway節點動態配置。
指定vSwitch的IP個數建議為預計Pod個數的2倍(或更多),一方面可以給將來的擴容多一些余量,另一方面也可以避免當發生故障導致Pod IP無法及時回收時,出現沒有IP可分配的情況。
為什么Pod無法ping通部分ECS節點?
問題現象
Flannel網絡模式下,檢查VPN路由正常,進入Pod,發現部分ECS節點無法ping通。
問題原因
Pod無法ping通部分ECS節點的原因分為兩種。
原因一:Pod訪問的ECS和集群在同一個VPC下,但不在同一個安全組。
原因二:Pod訪問的ECS和集群不在同一個VPC下。
解決方法
根據不同的原因,提供不同的解決方法。
針對原因一,需要將ECS加入到集群的安全組中。具體操作,請參見配置安全組。
針對原因二,需要通過ECS的公網入口訪問,需要在ECS的安全組中加入集群的公網出口IP地址。具體操作,請參見ECS通過EIP對公網提供服務。
為什么集群節點有NodeNetworkUnavailable污點?
問題現象
Flannel網絡模式下,新增的集群節點上有NodeNetworkUnavailable污點,導致Pod無法調度。
問題原因
Cloud Controller Manager沒有及時刪除該節點污點,可能原因是路由表滿、VPC存在多路由表等情況。
解決方法
使用kubectl describe node命令查看節點的Event事件信息,根據實際輸出的報錯進行處理。關于多路由表的問題,需要手動配置CCM的支持,更多詳情請參見使用VPC的多路由表功能。
為什么Pod無法正常啟動,且報錯no IP addresses available in range?
問題現象
Flannel網絡模式下,Pod無法正常啟動,查看Pod事件時顯示類似于failed to allocate for range 0: no IP addresses available in range set: 172.30.34.129-172.30.34.190的錯誤信息。
問題原因
解決方案
針對低版本ACK導致的IP地址泄露,您可以升級集群至1.20及以上版本。具體操作,請參見手動升級集群。
針對低版本Fannel導致的IP地址泄露,您可以升級Flannel至v0.15.1.11-7e95fe23-aliyun及以上版本。操作如下:
Flannel只要在v0.15.1.11-7e95fe23-aliyun及以上版本,ACK會在Flannel中將默認IP段分配數據庫遷移至臨時目錄 /var/run中,重啟時系統會自動清空,避免IP地址泄露。
升級Flannel組件至v0.15.1.11-7e95fe23-aliyun及以上版本。具體操作,請參見管理組件。
執行以下命令,編輯kube-flannel-cfg文件,然后在kube-flannel-cfg文件中新增dataDir和ipam參數。
kubectl -n kube-system edit cm kube-flannel-cfgkube-flannel-cfg文件示例如下。
# 修改前 { "name": "cb0", "cniVersion":"0.3.1", "plugins": [ { "type": "flannel", "delegate": { "isDefaultGateway": true, "hairpinMode": true }, }, # portmap # 低版本可能沒有,如不使用請忽略。 { "type": "portmap", "capabilities": { "portMappings": true }, "externalSetMarkChain": "KUBE-MARK-MASQ" } ] } # 修改后 { "name": "cb0", "cniVersion":"0.3.1", "plugins": [ { "type": "flannel", "delegate": { "isDefaultGateway": true, "hairpinMode": true }, # 注意逗號。 "dataDir": "/var/run/cni/flannel", "ipam": { "type": "host-local", "dataDir": "/var/run/cni/networks" } }, { "type": "portmap", "capabilities": { "portMappings": true }, "externalSetMarkChain": "KUBE-MARK-MASQ" } ] }執行以下命令,重啟Flannel Pod。
重啟Flannel Pod不會影響運行中的業務。
kubectl -n kube-system delete pod -l app=flannel刪除節點上的IP目錄,重啟節點。
在節點上執行以下命令,驗證節點是否啟用臨時目錄。
if [ -d /var/lib/cni/networks/cb0 ]; then echo "not using tmpfs"; fi if [ -d /var/run/cni/networks/cb0 ]; then echo "using tmpfs"; fi cat /etc/cni/net.d/10-flannel.conf*返回
using tmpfs,說明當前節點已經啟用臨時目錄/var/run作為IP段分配數據庫,變更成功。
如果短時間內無法升級ACK或Flannel,您可以按照以下方法臨時緊急處理。臨時緊急處理適用于以上兩種原因導致的泄漏。
臨時緊急處理操作只是幫助您清理泄露的IP地址,IP地址泄露的情況仍然有可能發生,因此您還是需要升級Flannel或集群的版本。
說明以下命令不適用于v0.15.1.11-7e95fe23-aliyun及以上版本的Flannel,并且已經切換使用/var/run存儲IP地址分配信息的節點。
以下腳本僅供參考,如果節點曾有過自定義修改,腳本可能無法正常工作。
將問題節點設置為不可調度狀態。具體操作,請參見設置節點調度狀態。
使用以下腳本,按照運行時引擎清理節點。
如果您使用的是Docker運行時,請使用以下腳本清理節點。
#!/bin/bash cd /var/lib/cni/networks/cb0; docker ps -q > /tmp/running_container_ids find /var/lib/cni/networks/cb0 -regex ".*/[0-9]+\.[0-9]+\.[0-9]+\.[0-9]+" -printf '%f\n' > /tmp/allocated_ips for ip in $(cat /tmp/allocated_ips); do cid=$(head -1 $ip | sed 's/\r#g' | cut -c-12) grep $cid /tmp/running_container_ids > /dev/null || (echo removing leaked ip $ip && rm $ip) done如果您使用的是Containerd運行時,請使用以下腳本清理節點。
#!/bin/bash # install jq yum install -y jq # export all running pod's configs crictl -r /run/containerd/containerd.sock pods -s ready -q | xargs -n1 crictl -r /run/containerd/containerd.sock inspectp > /tmp/flannel_ip_gc_all_pods # export and sort pod ip cat /tmp/flannel_ip_gc_all_pods | jq -r '.info.cniResult.Interfaces.eth0.IPConfigs[0].IP' | sort > /tmp/flannel_ip_gc_all_pods_ips # export flannel's all allocated pod ip ls -alh /var/lib/cni/networks/cb0/1* | cut -f7 -d"/" | sort > /tmp/flannel_ip_gc_all_allocated_pod_ips # print leaked pod ip comm -13 /tmp/flannel_ip_gc_all_pods_ips /tmp/flannel_ip_gc_all_allocated_pod_ips > /tmp/flannel_ip_gc_leaked_pod_ip # clean leaked pod ip echo "Found $(cat /tmp/flannel_ip_gc_leaked_pod_ip | wc -l) leaked Pod IP, press <Enter> to clean." read sure # delete leaked pod ip for pod_ip in $(cat /tmp/flannel_ip_gc_leaked_pod_ip); do rm /var/lib/cni/networks/cb0/${pod_ip} done echo "Leaked Pod IP cleaned, removing temp file." rm /tmp/flannel_ip_gc_all_pods_ips /tmp/flannel_ip_gc_all_pods /tmp/flannel_ip_gc_leaked_pod_ip /tmp/flannel_ip_gc_all_allocated_pod_ips
將問題節點設置為可調度狀態。具體操作,請參見設置節點調度狀態。
如何修改節點IP數量、Pod IP網段、Service IP網段?
節點IP數量、Pod IP網段、Service IP網段在集群創建后一律不支持修改,請在創建集群時合理規劃您的網段。
什么場景下需要為集群配置多個路由表?
在Flannel網絡模式下,以下是需要為cloud-controller-manager配置多路由表的常見場景。關于如何為集群配置多路由表,請參見使用VPC的多路由表功能。
問題場景
場景一:
系統診斷中提示“節點Pod網段不在VPC路由表條目中,請參考添加自定義路由條目到自定義路由表添加Pod網段的下一跳路由到當前節點”。
原因:集群中創建自定義路由表時,需要給CCM配置支持多路由表功能。
場景二:
cloud-controller-manager組件報錯,提示網絡異常
multiple route tables found。原因:集群中存在多個路由表時,需要給CCM配置支持多路由表功能。
場景三:
Flannel網絡模式下,新增的集群節點上有NodeNetworkUnavailable污點,而cloud-controller-manager組件沒有及時刪除該節點污點,導致Pod無法調度。詳情請參見為什么集群節點有NodeNetworkUnavailable污點?。
是否支持安裝和配置第三方網絡插件?
ACK集群不支持安裝和配置第三方網絡插件,如果安裝了可能會導致集群網絡不可用。
為什么Pod CIDR地址不足,報錯no IP addresses available in range set?
這是因為您的ACK集群使用了Flannel網絡插件。Flannel定義了Pod網絡CIDR,即為每個節點提供一組有限的IP地址用于分配給Pod,且不支持更改。一旦范圍內的IP地址用盡,新的Pod便無法在此節點上創建。請釋放一些IP地址或重構集群。關于如何規劃集群網絡,請參見Kubernetes集群網絡規劃。
Terway網絡模式支持的Pod數量是多少?
Terway網絡模式的集群支持的Pod數量是ECS支持的IP數量。詳細信息,請參見使用Terway網絡插件。
Terway DataPath V2數據面模式
從Terway v1.8.0版本起,新建集群時選擇IPvlan選項將默認啟用DataPath V2模式。對于已經啟用 IPvlan功能的現有集群,數據面維持原有的IPvlan方式。
DataPath V2是新一代的數據面路徑,與原有的IPvlan模式相比,DataPath V2模式具有更好的兼容性。詳細信息,請參見使用Terway網絡插件。
如何查看Terway網絡Pod生命周期?
登錄容器服務管理控制臺,在左側導航欄選擇集群。
在集群列表頁面,單擊目標集群名稱,然后在左側導航欄,選擇。
在守護進程集頁面頂部,單擊
 選擇kube-system命名空間。
選擇kube-system命名空間。在守護進程集頁面搜索terway-eniip,單擊名稱列表下的terway-eniip。
Terway組件升級失敗常見問題
問題現象 | 處理辦法 |
升級時提示錯誤碼 | EIP功能在Terway組件中已不再支持,如需繼續使用此功能,請參見將EIP從Terway遷移至ack-extend-network-controller。 |
Terway網絡模式下,創建Pod提示找不到mac地址
問題現象
創建Pod失敗,提示MAC地址找不到。
failed to do add; error parse config, can't found dev by mac 00:16:3e:xx:xx:xx: not found解決辦法
網卡在系統中加載是異步的,在CNI配置時,可能網卡還沒有加載成功。這種情況下CNI會自動重試,并不會有影響。請通過Pod最終狀態判斷是否成功。
如果Pod長時間沒有創建成功,并提示上述錯誤,通常是由于在彈性網卡掛載時,由于高階內存不足導致驅動加載失敗。您可以通過重啟實例解決。