事件監控是Kubernetes中的一種監控方式,可以彌補資源監控在實時性、準確性和場景上的不足。您可以通過使用NPD(node-problem-detector)結合SLS的Kubernetes事件中心、配置NPD集群檢查項以及異常事件離線功能、使用釘釘、使用SLS離線Kubernetes事件及使用EventBridge離線Kubernetes事件,實時監控集群的異常與問題。
費用說明
ACK事件監控功能默認上報集群事件至SLS日志服務,SLS日志服務提供事件數據的存儲、分析能力,默認90天內的ACK集群事件數據免費。詳細信息,請參見創建并使用K8s事件中心。
背景信息
Kubernetes的架構設計基于狀態機,不同的狀態之間進行轉換會生成相應的事件,正常的狀態之間轉換會生成Normal等級的事件,正常狀態與異常狀態之間的轉換會生成Warning等級的事件。
ACK提供開箱即用的容器場景事件監控方案,通過ACK維護的NPD以及包含在NPD中的kube-eventer提供容器事件監控能力。

NPD(node-problem-detector)是Kubernetes節點診斷的工具,可以將節點的異常,例如Docker Engine Hang、Linux Kernel Hang、網絡出網異常、文件描述符異常轉換為Node的事件,結合kube-eventer可以實現節點事件告警的閉環。更多信息,請參見NPD。
kube-eventer是ACK維護的開源Kubernetes事件離線工具,可以將集群的事件離線到釘釘、SLS、EventBridge等系統,并提供不同等級的過濾條件,實現事件的實時采集、定向告警、異步歸檔。更多信息,請參見kube-eventer。
本文通過以下五種場景為您介紹事件監控。
場景一:使用NPD結合SLS的Kubernetes事件中心監控集群事件
NPD根據配置與第三方插件檢測節點的問題或故障、生成相應的集群事件。而Kubernetes集群自身也會因為集群狀態的切換產生各種事件,例如Pod驅逐、鏡像拉取失敗等異常情況。日志服務SLS(Log Service)的Kubernetes事件中心實時匯聚Kubernetes中的所有事件并提供存儲、查詢、分析、可視化、告警等能力。將集群事件接入日志服務的Kubernetes事件中心操作步驟如下。
步驟一:安裝ack-node-problem-detector組件
如果您在創建集群時,已選中安裝node-problem-detector并創建事件中心,可直接按照步驟二查看Kubernetes事件中心。關于如何通過創建集群時安裝NPD組件,請參見創建ACK托管集群。
若創建集群時未選中安裝node-problem-detector并創建事件中心,則需手動安裝,具體的操作步驟如下。
登錄容器服務管理控制臺。
在集群列表頁面,單擊目標集群名稱,然后在左側導航欄,選擇。
在日志與監控頁簽,查找并安裝ack-node-problem-detector。
步驟二:查看事件中心
登錄容器服務管理控制臺,在左側導航欄選擇集群。
在集群列表頁面,單擊目標集群名稱,然后在左側導航欄,選擇。
單擊右上角的事件中心管理,在K8s事件中心頁面的左側導航欄,單擊目標集群名稱左邊的展開圖標
 ,查看Kubernetes事件中心相關信息。
,查看Kubernetes事件中心相關信息。您可以查看Kubernetes事件的總覽及詳情、Pod生命周期,還可以進行自定義查詢和告警配置。更多信息,請參見采集Kubernetes事件。
場景二:配置NPD集群檢查項以及異常事件離線功能
NPD(node-problem-detector)是Kubernetes節點診斷的工具,可以將節點的異常,例如Docker Engine Hang、Linux Kernel Hang、網絡出網異常、文件描述符異常轉換為Node的事件,結合kube-eventer可以實現節點事件告警的閉環。
操作流程
安裝ack-node-problem-detector組件,安裝過程請參見安裝ack-node-problem-detector組件。
說明若之前已安裝過ack-node-problem-detector組件,請刪除重新安裝。具體操作,請參見如何重新安裝ack-node-problem-detector組件。
在集群列表頁面,單擊目標集群名稱,然后在左側導航欄,選擇。
在守護進程集頁面,選擇命名空間為kube-system,查看組件ack-node-problem-detector-daemonset運行正常。
當node-problem-detector與
eventer都正常運行后,可以通過配置的eventer的離線通道進行數據的離線處理或者報警。
NPD支持的問題檢查插件
插件名 | 功能 | 說明 |
fd_check | 檢查集群節點系統的已打開的文件描述符是否超過最大上限的80%。 | 80%為默認值,可通過參數修改。該檢查項消耗資源較多,不建議開啟。 |
ram_role_check | 檢查集群節點是否具有RAM Role以及相應的鑒權密鑰。 | 無 |
ntp_check | 檢查集群節點上的NTP時間同步服務是否正常運行。 | 默認開啟項。 |
nvidia_gpu_check | 檢查集群節點上的NVIDIA GPU計算卡是否具有有效的 | 無 |
network_problem_check | 檢查集群節點上的 | 默認開啟項。 |
inodes_usage_check | 檢查集群節點系統盤的 | 80%為默認值,可通過參數修改。默認開啟項。 |
csi_hang_check | 檢查集群節點上的CSI存儲插件狀態是否正常。 | 無 |
ps_hang_check | 檢查集群節點系統中是否有狀態為D(掛起且無法喚醒)的進程。 | 無 |
public_network_check | 檢查集群節點是否可以訪問公網。 | 無 |
irqbalance_check | 檢查集群節點系統中的 | 無 |
pid_pressure_check | 檢查集群節點系統中的進程 | 默認開啟項。 |
docker_offline_check | 檢測集群節點上的 | 默認開啟項。 |
場景三:使用釘釘實現Kubernetes監控告警
使用釘釘機器人監控并告警Kubernetes的事件是一個非常典型的ChatOps實現。具體的操作步驟如下。
單擊釘釘群右上角的
 圖標,進入群設置頁面。
圖標,進入群設置頁面。單擊機器人,然后單擊添加機器人,選擇需要添加的機器人。此處選擇自定義機器人。
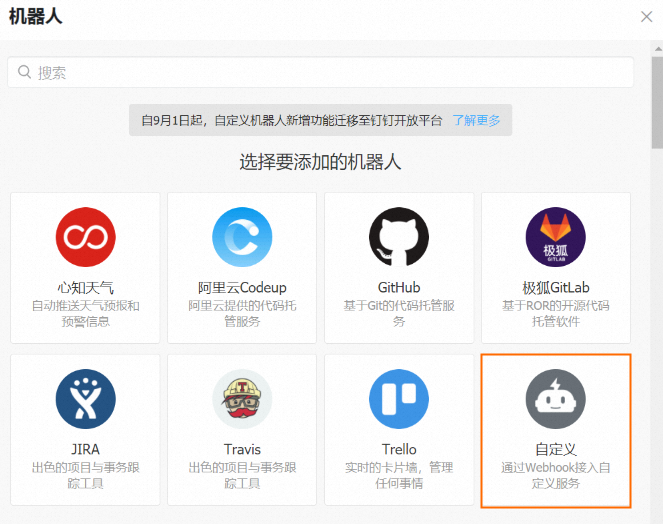
在機器人詳情頁面,單擊添加,進入添加機器人頁面。
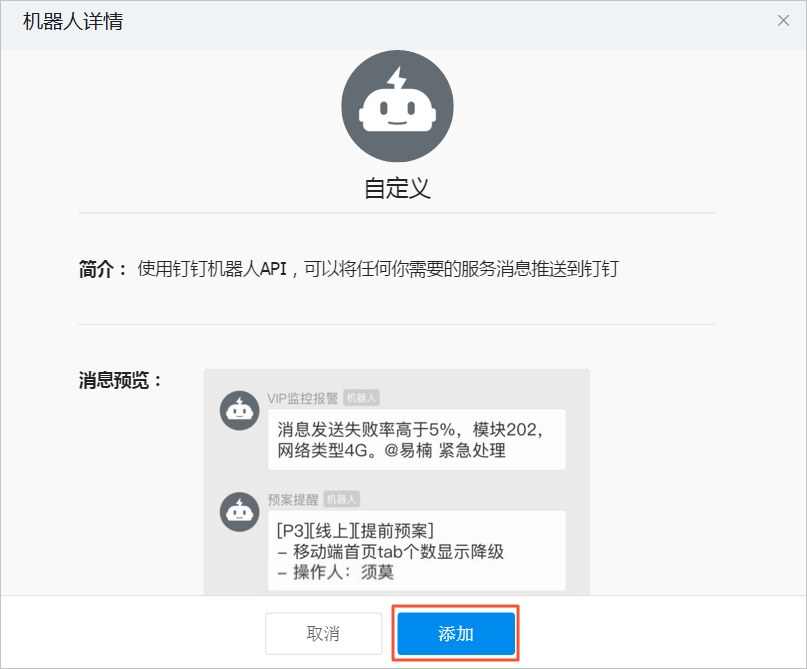
根據以下信息配置群機器人后,閱讀并同意服務及免責條款,然后單擊完成。
參數
說明
編輯頭像
(可選)為群機器人設置頭像。
機器人名字
添加的機器人名稱。
添加到群組
添加機器人的群組。
安全設置
安全設置支持3種方式:自定義關鍵詞、加簽和IP地址(段)。
目前集群的事件監控僅支持第一種方式,即自定義關鍵詞。
選中自定義關鍵詞,填入
Warning可接收所有監控報警。如果發現機器人消息發送過于頻繁,可增加關鍵詞進行過濾,最多支持設置10個關鍵詞。ACK發送消息時也會同步此關鍵詞。單擊復制,復制webhook地址以備后續使用。
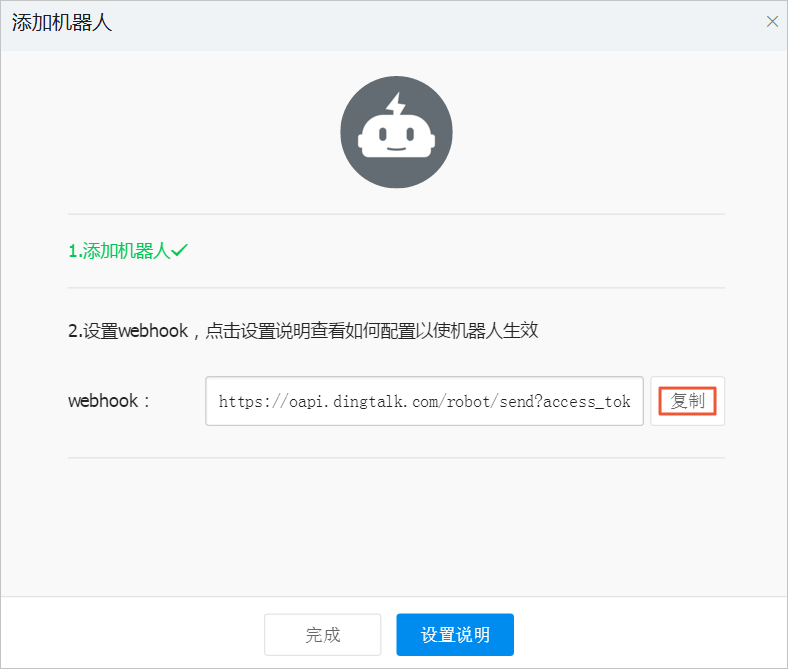 說明
說明在群機器人頁面,選擇目標群機器人,單擊右側
 圖標可以進行以下操作:
圖標可以進行以下操作:修改群機器人的頭像及機器人名字。
開啟或關閉消息推送。
重置webhook地址。
刪除群機器人。
安裝ack-node-problem-detector組件,安裝過程請參見安裝ack-node-problem-detector組件。
說明若之前已安裝過ack-node-problem-detector組件,請刪除重新安裝,具體操作請參見如何重新安裝ack-node-problem-detector組件。
在集群列表頁面,單擊目標集群名稱,然后在左側導航欄,選擇。
在Helm頁面,找到ack-node-problem-detector組件,然后在組件對應的操作列單擊更新,修改以下內容,然后單擊確定。
將
npd下方的enabled設置為false。將
eventer.sinks.dingtalk.enabled設置為true。通過步驟5創建webhook地址查看Token,填入Token字段。
預期結果:
部署成功后30秒,eventer生效,當事件等級超過閾值等級時,即可在釘釘群收到如下告警。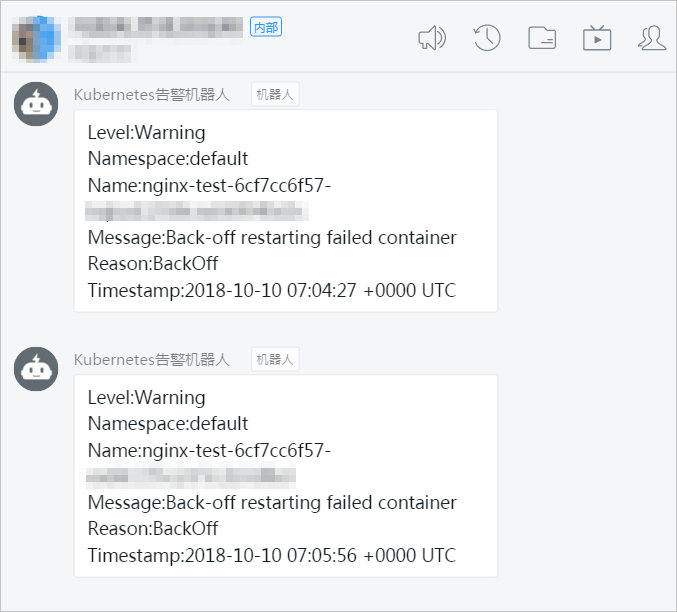
場景四:使用SLS離線Kubernetes事件
阿里云日志服務SLS(Log Service)可以將Kubernetes的事件以更持久的方式進行存儲,從而提供更多的事件歸檔、審計的能力。詳情請參見創建并使用K8s事件中心。
創建Project與Logstore。
登錄日志服務管理控制臺。
在Project列表區域,單擊創建Project,填寫Project的基本信息并單擊確認進行創建。
本示例創建一個名為k8s-log4j的Project,與Kubernetes集群位于同一地域(華東1)。
說明為降低成本并提高效率,通常建議將日志服務與Kubernetes集群配置在同一地域。這樣可以使日志數據通過內網進行傳輸,避免因地域不一致產生的外網數據傳輸費用,并減少傳輸延遲,實現日志的實時采集和快速查詢。
創建完成后,k8s-log4j出現在Project列表下,單擊該Project名稱,進入Project詳情頁面。
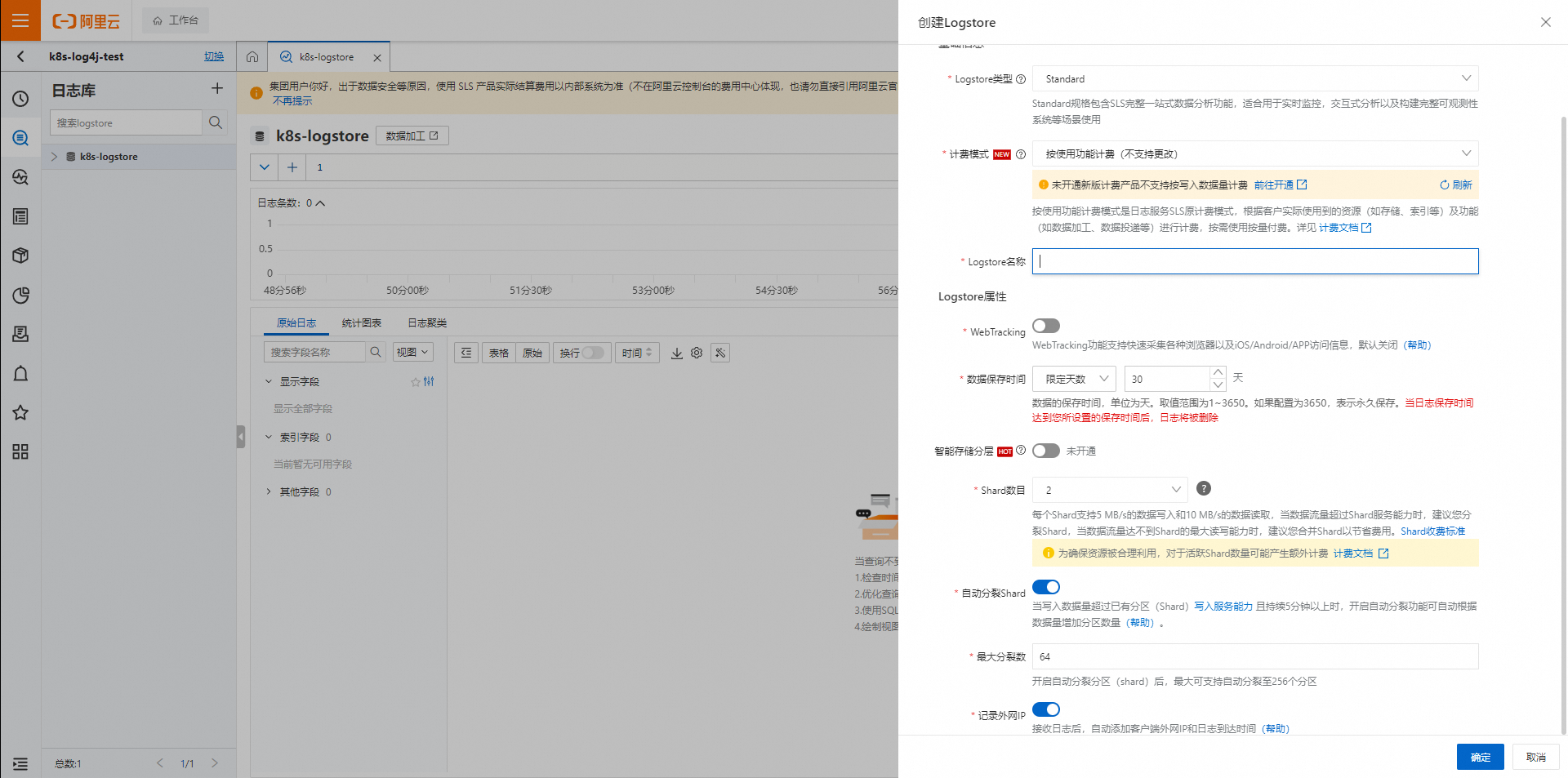
默認進入日志庫頁面,在頁面左側,單擊加號+,彈出創建Logstore對話框。
填寫日志庫配置信息并單擊確定。
本示例創建名為k8s-logstore的日志庫。
創建完畢后,頁面會提示您使用數據接入向導。單擊數據接入向導,彈出接入數據對話框。
選擇Log4j 1/2,根據頁面引導進行配置。
本示例使用了默認配置,您可根據日志數據的具體使用場景,進行相應的配置。
在Kubernetes集群中配置log4j。
安裝ack-node-problem-detector組件,安裝過程請參見安裝ack-node-problem-detector組件。
重要單擊安裝ack-node-problem-detector組件時,在配置項中將步驟1創建好的
Project和Logstore分別填入各字段。若之前已安裝過ack-node-problem-detector組件,請刪除重新安裝,具體操作請參見如何重新安裝ack-node-problem-detector組件。
在集群列表頁面,單擊目標集群名稱,然后在左側導航欄,選擇。
在Helm頁面,找到ack-node-problem-detector組件,然后在組件對應的操作列單擊更新,修改以下內容,然后單擊確定。
將
npd下方的enabled設置為false。將
eventer.sinks.sls.enabled設置為true。
操作集群(例如,刪除Pod或者創建應用等)產生事件后,登錄日志服務控制臺查看數據采集。請參見通過API消費。
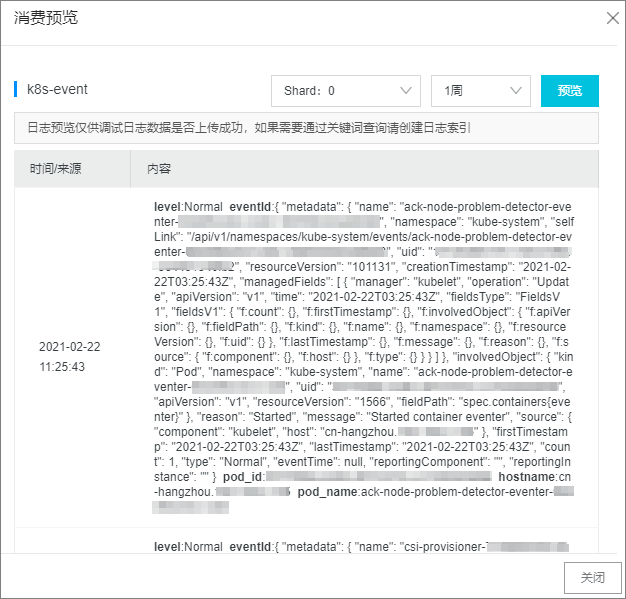
設置索引與歸檔。請參見創建索引。
在日志服務控制臺Project列表區域,單擊Project名稱。
單擊日志庫名稱后的
 圖標,選擇查詢分析。
圖標,選擇查詢分析。單擊右上角的開啟索引。
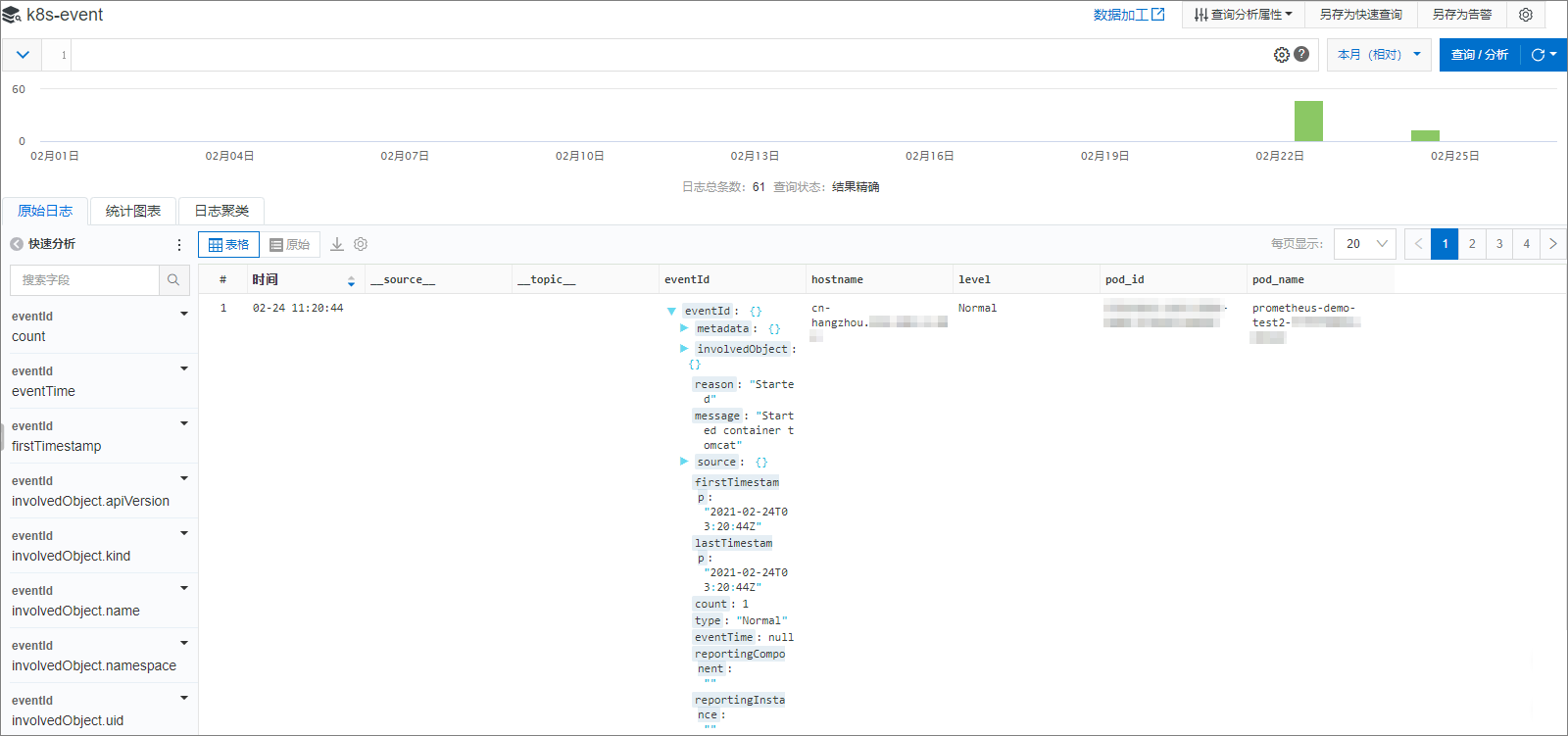
在查詢分析對話框中配置索引,然后單擊確定。
此時會出現日志查詢與分析頁面。
 說明
說明索引配置在1分鐘之內生效。
開啟或修改索引后,新的索引配置只對新寫入的數據生效。
(可選)在需要設置離線歸檔與計算的場景下,在Logstore上將數據投遞給MaxCompute或者OSS,請參見創建MaxCompute投遞任務(新版)、創建OSS投遞任務(新版)。
場景五:使用EventBridge離線Kubernetes事件
事件總線EventBridge是阿里云提供的一款無服務器事件總線服務,支持阿里云服務、自定義應用及SaaS應用以標準化、中心化的方式接入,并能夠以標準化的CloudEvents 1.0協議在這些應用之間路由事件。容器服務事件可支持通過離線到EventBridge實現構建松耦合、分布式的事件驅動架構。關于EventBridge的詳情,請參見什么是事件總線EventBridge。
開通事件總線EventBridge。具體操作,請參見開通事件總線EventBridge并授權。
安裝ack-node-problem-detector組件,安裝過程請參見安裝ack-node-problem-detector組件。
說明若之前已安裝過ack-node-problem-detector組件,請刪除重新安裝,具體操作請參見如何重新安裝ack-node-problem-detector組件。
在集群列表頁面,單擊目標集群名稱,然后在左側導航欄,選擇。
在Helm頁面,定位ack-node-problem-detector組件,然后在組件對應的操作列單擊更新,將
eventer.sinks.eventbridge.enable修改為true,以配置事件中心并開啟EventBridge事件離線數據鏈路,然后單擊確定。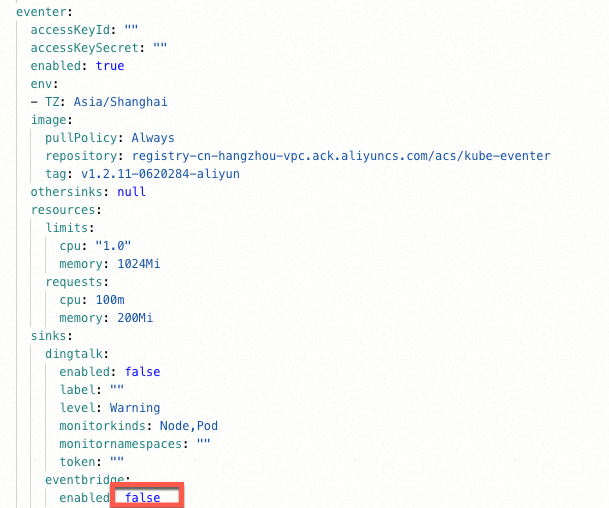
數據鏈路開啟成功后,在事件總線EventBridge控制臺查看容器事件。
- 登錄事件總線EventBridge控制臺。
- 在左側導航欄,單擊事件總線。
- 在事件總線頁面,單擊目標總線名稱。
- 在左側導航欄,單擊事件追蹤。
選擇事件查詢方式,設置查詢條件,單擊查詢。
在事件列表操作列,單擊事件詳情,查看事件詳細內容。
更多信息,請參見查詢事件。
如何重新安裝ack-node-problem-detector組件
登錄容器服務管理控制臺,在左側導航欄單擊集群。
在集群列表頁面,單擊目標集群名稱,然后在左側導航欄,選擇。
在任務頁面,單擊kube-eventer-init-v1.7-xxxx右側更多,單擊刪除。
在集群列表頁面,單擊目標集群名稱,然后在左側導航欄,選擇。
在Helm頁面,刪除原有的ack-node-problem-detector組件。
在集群列表頁面,單擊目標集群名稱,然后在左側導航欄,選擇。
在日志與監控頁簽,查找并重新安裝ack-node-problem-detector。