本文中含有需要您注意的重要提示信息,忽略該信息可能對您的業務造成影響,請務必仔細閱讀。
如需對采集到Logstore中的日志進行查詢和分析,您必須首先創建索引。本文為您介紹日志服務索引概念、索引類型、配置索引示例和步驟。
為什么需要創建索引
通常我們使用關鍵詞,從原始日志內容中檢索想要的內容,例如檢索出包含Chrome的如下日志內容:
Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.2 (KHTML, like Gecko) Chrome/192.0.2.0 Safari/537.2如果不進行切分,該日志文本會作為一個整體,不能和關鍵詞Chrome完全對應,因此不會被日志服務Project檢索到。為了便于檢索,需要將日志切分成獨立、可搜索的詞。日志切分由分詞符實現,這些符號決定了日志文本內容被切分的位置。以該日志為例,使用分詞符\n\t\r,;[]{}()&^*#@~=<>/\?:'"進行分割,得到的詞是Mozilla、5.0、Windows、NT、6.1、AppleWebKit、537.2、KHTML、like、Gecko、Chrome、192.0.2.0、Safari、537.2。
日志服務Project基于這些切分出的關鍵詞建立索引。創建索引后,您才能對日志數據進行查詢和分析。
索引類型
全文索引
重要分詞符不支持中文,開啟包含中文選項,日志服務會自動按照中文分詞。
如果只配置全文索引,則只能使用查詢功能。更多信息,請參見查詢語法。
根據分詞符直接將整個日志切分成多個text類型的詞語。可以通過關鍵詞進行查詢,例如查詢語句:
Chrome or Safari,查詢包括Chrome或Safari的日志。更多信息,請參見查詢語法。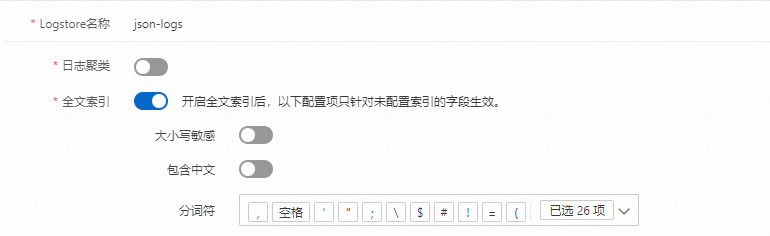
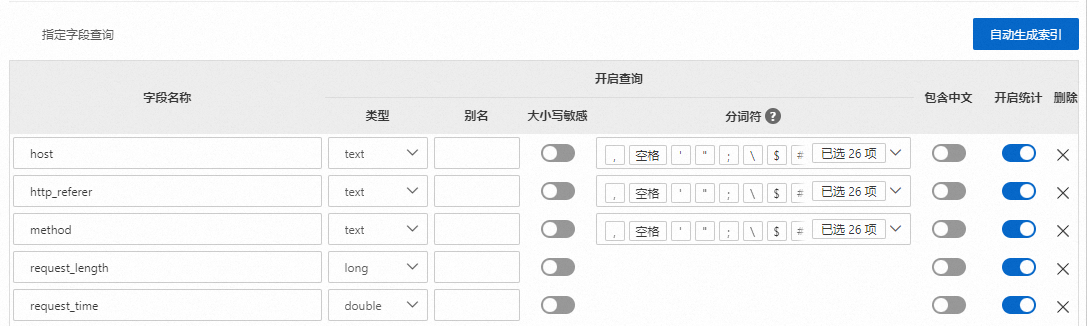
字段索引
說明在采集日志或投遞數據到其他云產品時,日志服務會將日志來源、時間戳等信息以Key-Value對的形式添加到日志中。這些字段是日志服務的保留字段。
先將日志根據字段名稱(KEY)進行區分,然后在字段內使用分詞符進行分割,字段類型包括
text、long、double和json。text類型的字段,可以使用全文查詢語句、字段查詢語句、分析語句(SELECT)。如果未開啟全文索引,全文查詢語句是從所有text類型的字段中查詢結果。如果已開啟全文索引,全文查詢語句是從所有日志中查詢結果。long、double類型的字段,可以使用字段查詢語句、分析語句(SELECT)進行查詢和分析。
創建字段索引后,您可以指定字段名稱和字段值(Key:Value)進行查詢,也可以使用SELECT語句。更多信息,請參見字段查詢語法和查詢與分析概述。
創建索引
不同的索引配置,會產生不同的查詢和分析結果,請根據您的需求,合理創建索引。如果您同時創建了全文索引和字段索引,以字段索引的配置為準。
配置索引只對新增日志生效,對于已有日志需要重建索引,配置索引后需要大約一分鐘生效。
登錄日志服務控制臺,在Project列表,單擊打開目標Project。
在左側導航欄單擊日志存儲,然后在打開的日志庫頁簽中,單擊目標Logstore。
在Logstore的查詢和分析頁面,單擊開啟索引。
說明開啟后等待1min左右即可查詢最新數據。

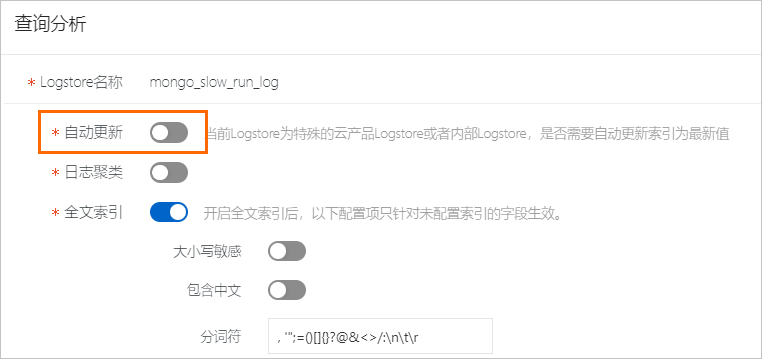
關閉自動更新索引
當Logstore為云產品專屬Logstore或內部Logstore時,默認打開索引自動更新開關,后續如有版本更新時可以升級到內置索引最新版本。如果需要創建索引,請在查詢分析面板中,關閉自動更新開關。
警告刪除云產品專屬Logstore的索引會影響相關報表、告警等功能的使用。
配置索引
在查詢分析頁面,打開全文索引開關,并單擊自動生成索引。日志服務會根據采集時預覽數據中的第一條內容,自動生成字段索引。單擊頁面下方的
+也可手動創建字段索引。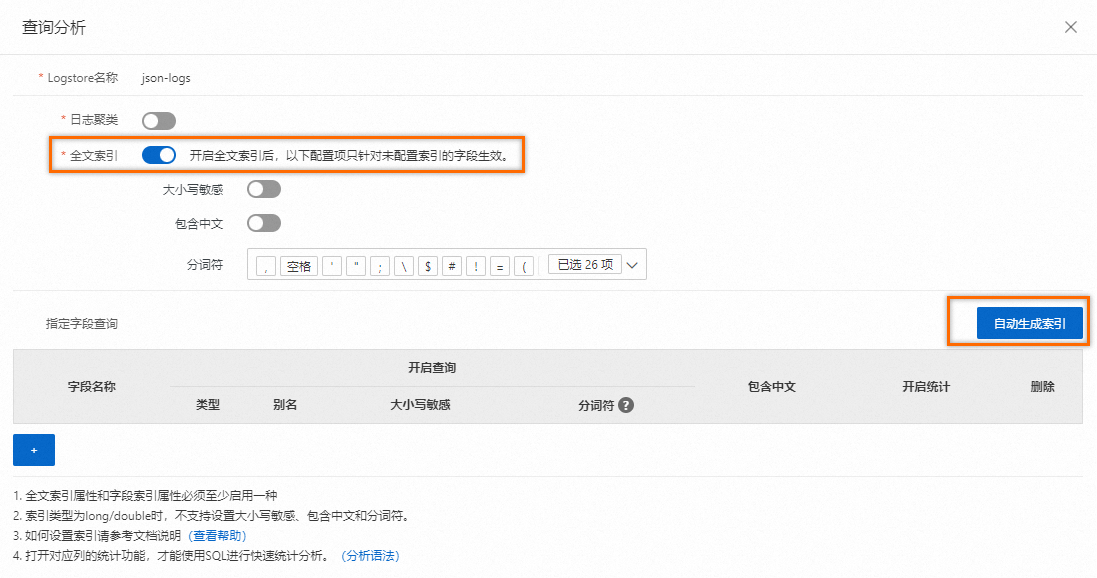 重要
重要如果需要對字段進行分析(SELECT語句),必須創建字段索引,字段索引的配置項優先級高于全文索引的配置項。
日志服務已為部分保留字段創建索引。更多信息,請參見保留字段。
其中
__topic__和__source__的索引分詞符為空,查詢這兩個字段時,關鍵字必須完全匹配。__tag__為前綴的字段不支持全文索引。您需要創建字段索引后,才能執行查詢和分析操作,例如*| select "__tag__:__receive_time__"。日志中存在同名字段(例如都為request_time)時,日志服務會將其中一個字段名顯示為request_time_0,底層存儲的字段名仍為request_time。因此在創建索引、查詢、分析、投遞、加工時,只能使用原始字段名request_time。
全文索引配置項說明如下所示:
參數
說明
日志聚類
打開日志聚類開關后,日志服務在采集文本日志時會自動聚合相似度高的日志,提取共同的日志模式,幫助您快速掌握日志整體情況。更多信息,請參見日志聚類。
大小寫敏感
查詢時是否區分英文字母的大小寫。
打開大小寫敏感開關,則查詢時區分大小寫。例如某條日志含有
internalError,那么您只能使用internalError才能查詢到該日志。關閉大小寫敏感開關,則查詢時不區分大小寫。例如某條日志含有
internalError,那么您使用關鍵字INTERNALERROR和internalerror都能查到該日志。
包含中文
查詢時是否區分中英文。
打開包含中文開關后,如果日志中包含中文,則按照中文語法拆分中文內容,按照分詞符的設置拆分英文內容。
重要中文分詞對寫入速度會有一定影響,請根據需求謹慎設置。
關閉包含中文開關后,按照分詞符的設置拆分所有內容。
例如日志內容為user:SLS日志服務用戶張先生。
關閉包含中文開關后,按照分詞符半角冒號(:)進行拆分,日志會被拆分為
user、SLS日志服務用戶張先生,您可以通過user或SLS日志服務用戶張先生查找該日志。打開包含中文開關后,日志服務后臺分詞器將日志拆分為
user、SLS、日志服務、用戶和張先生,您通過日志服務或張先生等詞都可以查找到該日志。
分詞符
根據指定分詞符,將日志內容拆分成多個詞。日志服務的默認分詞符為
, '";=()[]{}?@&<>/:\n\t\r。當默認設置不能滿足您的需求時,您可以自定義設置分詞符。所有的ASCII碼都可被定義為分詞符。如果設置分詞符為空,則字段值將被當成一個整體,您只能通過完整字符串或模糊查詢查找對應的日志。
例如日志內容為
/url/pic/abc.gif。如果不設置任何分詞符,整條日志被作為一個詞
/url/pic/abc.gif,您只能通過完整字符串/url/pic/abc.gif或模糊查詢/url/pic/*查找該日志。如果設置分詞符為正斜線(/),則原始日志被拆分為
url、pic和abc.gif三個詞,您通過任意一個詞或詞的模糊查詢都可以找到該日志,例如url、abc.gif、pi*、/url/pic/abc.gif。如果設置分詞符為正斜線(/)和半角句號(.),則原始日志被拆分為
url、pic、abc和gif四個詞,您通過任意一個詞或詞的模糊查詢都可以找到該日志。
字段索引配置項說明如下所示:
參數
說明
字段名稱
日志字段名稱(KEY),例如
client_ip。字段名稱只能包括字母、數字或下劃線(_),且只能以字母或下劃線(_)開頭。
重要設置公網IP地址、Unix時間戳等__tag__字段的索引時,需設置字段名稱為__tag__:KEY形式,例如__tag__:__receive_time__。更多信息,請參見保留字段。
__tag__字段不支持數值類型索引,請將所有__tag__字段的索引的類型設置為text。
類型
日志字段值(Value)的數據類型,可選值為text、long、double和json。更多信息,請參見數據類型。
long類型和double類型不支持設置大小寫敏感、包含中文和分詞符。
別名
字段的別名,例如設置client_ip字段的別名為ip。
字段別名只能包括字母、數字或下劃線(_),且只能以字母或下劃線(_)開頭。
重要別名僅用于分析語句(SELECT語句),查詢語句中仍需使用原始字段名稱。更多信息,請參見列的別名。
大小寫敏感
查詢時是否區分英文字母的大小寫。
打開大小寫敏感開關,則查詢時區分大小寫。例如某條日志含有
internalError,那么您只能使用internalError才能查詢到該日志。關閉大小寫敏感開關,則查詢時不區分大小寫。例如某條日志含有
internalError,那么您使用關鍵字INTERNALERROR和internalerror都能查到該日志。
分詞符
根據指定分詞符,將日志內容拆分成多個詞。日志服務的默認分詞符為
, '";=()[]{}?@&<>/:\n\t\r。當默認設置不能滿足您的需求時,您可以自定義設置分詞符。所有的ASCII碼都可被定義為分詞符。如果設置分詞符為空,則字段值將被當成一個整體,您只能通過完整字符串或模糊查詢查找對應的日志。
例如日志內容為
/url/pic/abc.gif。如果不設置任何分詞符,整條日志被作為一個詞
/url/pic/abc.gif,您只能通過完整字符串/url/pic/abc.gif或模糊查詢/url/pic/*查找該日志。如果設置分詞符為正斜線(/),則原始日志被拆分為
url、pic和abc.gif三個詞,您通過任意一個詞或詞的模糊查詢都可以找到該日志,例如url、abc.gif、pi*、/url/pic/abc.gif。如果設置分詞符為正斜線(/)和半角句號(.),則原始日志被拆分為
url、pic、abc和gif四個詞,您通過任意一個詞或詞的模糊查詢都可以找到該日志。
包含中文
查詢時是否區分中英文。
打開包含中文開關后,如果日志中包含中文,則按照中文語法拆分中文內容,按照分詞符的設置拆分英文內容。
重要中文分詞對寫入速度會有一定影響,請根據需求謹慎設置。
關閉包含中文開關后,按照分詞符的設置拆分所有內容。
例如日志內容為user:SLS日志服務用戶張先生。
關閉包含中文開關后,按照分詞符半角冒號(:)進行拆分,日志會被拆分為
user、SLS日志服務用戶張先生,您可以通過user或SLS日志服務用戶張先生查找該日志。打開包含中文開關后,日志服務后臺分詞器將日志拆分為
user、SLS、日志服務、用戶和張先生,您通過日志服務或張先生等詞都可以查找到該日志。
開啟統計
打開開啟統計功能后,您才能對該字段進行統計分析。
索引配置示例
日志內容中有
request_time字段,執行字段查詢語句request_time>100。只建立全文索引,返回同時包含
request_time、>(非分詞符)、100這三個詞的日志。只建立double、long類型的字段索引,返回結果是
request_time大于100的日志。建立全文索引和double、long類型的字段索引,
request_time的全文索引失效,返回結果是request_time大于100的日志。
日志內容中有
request_time字段,執行全文查詢語句request_time。只建立double、long類型的字段索引,無法查詢到相關日志。
只建立全文索引,從所有日志文本中查詢包括
request_time的日志。只建立text類型的字段索引,從字段索引是text類型的字段中查詢包括
request_time的日志。
日志內容中有
status字段,執行分析語句* | SELECT status, count(*) AS PV GROUP BY status。只建立全文索引,無法查詢到相關日志。
為
status建立字段索引,返回結果是不同的狀態碼及對應的PV總數。
索引流量
全文索引
所有字段名和字段值都將作為text類型存儲,即字段名和字段值都被計入索引流量。
字段索引
不同數據類型的字段的索引流量計算方式不同。
text類型:字段名和字段值都被計入索引流量中。
long類型和double類型:字段名不計入索引流量中,每個字段值所占的索引流量統一為8字節。
例如對
status字段設置了索引(long類型),字段值為200,則字符串status不會被計入在索引流量中,200的索引流量統一為8字節。JSON類型:字段名和字段值都被計入到索引流量中,包括未被創建索引的子節點。更多信息,請參見如何計算JSON類型字段的索引流量。
如果未對子節點設置索引,則其索引流量按照text類型進行計算。
如果對子節點設置了索引,則其索引流量按照其子節點數據類型(text類型、long類型或double類型)進行計算。
計費說明
按寫入數據量計費的logstore
創建的索引會占用存儲空間,存儲類型請參見管理智能存儲分層。
重建索引不產生費用。
索引流量計費請參見按寫入數據量計費模式計費項。
按使用功能計費的logstore
創建的索引會占用存儲空間,存儲類型請參見管理智能存儲分層。
創建索引會產生流量,索引流量計費請參見按使用功能計費模式計費項中的索引流量-日志索引和索引流量-日志索引-查詢型。降低索引流量的建議,請參見如何降低索引流量費用?。
重建索引會產生費用。計費項、計費價格和創建索引相同。
后續步驟
查詢和分析日志
查詢和分析的示例,請參見:
設置字段的最大長度
分析時,日志服務默認支持的字段值最大長度為
2048字節,即2KB。如果您需要修改字段值的最大長度,可設置統計字段(text)最大長度,取值范圍為64~16384字節。重要當單個字段值長度超過最大長度時,超出部分被截斷,不參與分析。

日志聚類
打開日志聚類開關,日志服務在采集文本日志時會自動聚合相似度高的日志,提取共同的日志模式,幫助您快速掌握日志整體情況。更多信息,請參見日志聚類。
關閉索引
關閉索引后,歷史索引的存儲空間將在當前Logstore的數據保存時間到期后,自動被清除。
相關文檔
優化查詢的方法,請參見提高查詢分析日志速度的方法。
查詢和分析JSON類型的網站日志,請參見查詢和分析JSON日志。
使用API管理索引,請參見:
常見問題
檢查已設置的分詞符是否符合要求。
索引配置只對新增日志生效,如果您要查詢和分析歷史數據,請使用重建索引功能。具體操作,請參見重建索引。
需要使用兩個條件查詢日志時,只需同時輸入兩個語句即可。需要在Logstore中查詢數據狀態不是OK或者Unknown的日志。 直接搜索not OK not Unknown即可得到符合條件的日志。
以查詢http_user_agent字段值中包含like Gecko的日志為例。
短語查詢。http_user_agent:#"like Gecko"。短語查詢
like語法。* | Select * where http_user_agent like '%like Gecko%'
例如,當您搜索POS version時,會得到包含POS或者version的所有日志。如果使用雙引號包裹,例如“POS version”,則會得到包含關鍵字POS version的所有日志。