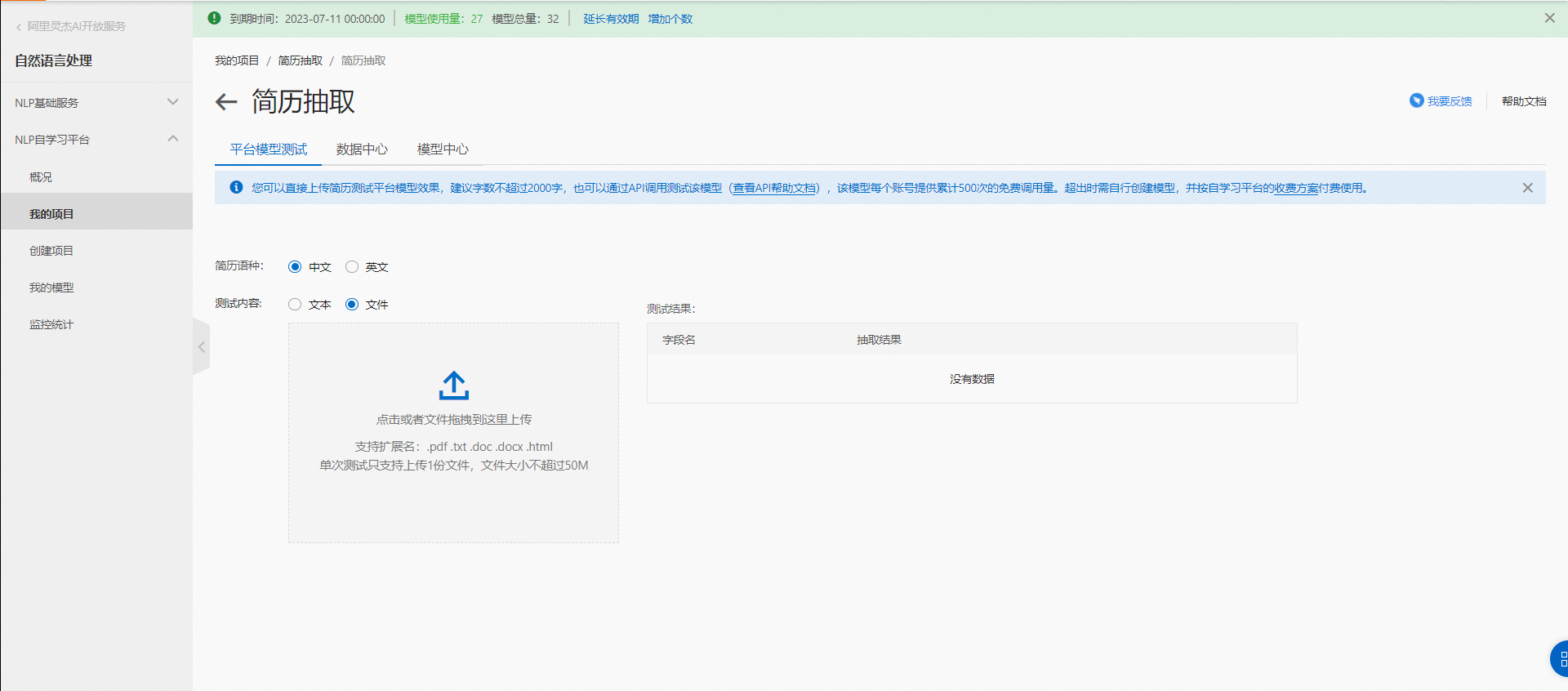
服務開通與資源包購買
預訓練模型使用前,請確認是否已經開通了NLP自學習平臺服務,開通后可購買資源包。
NLP自學習平臺:開通地址
自學習平臺資源包:購買地址
一、創建項目
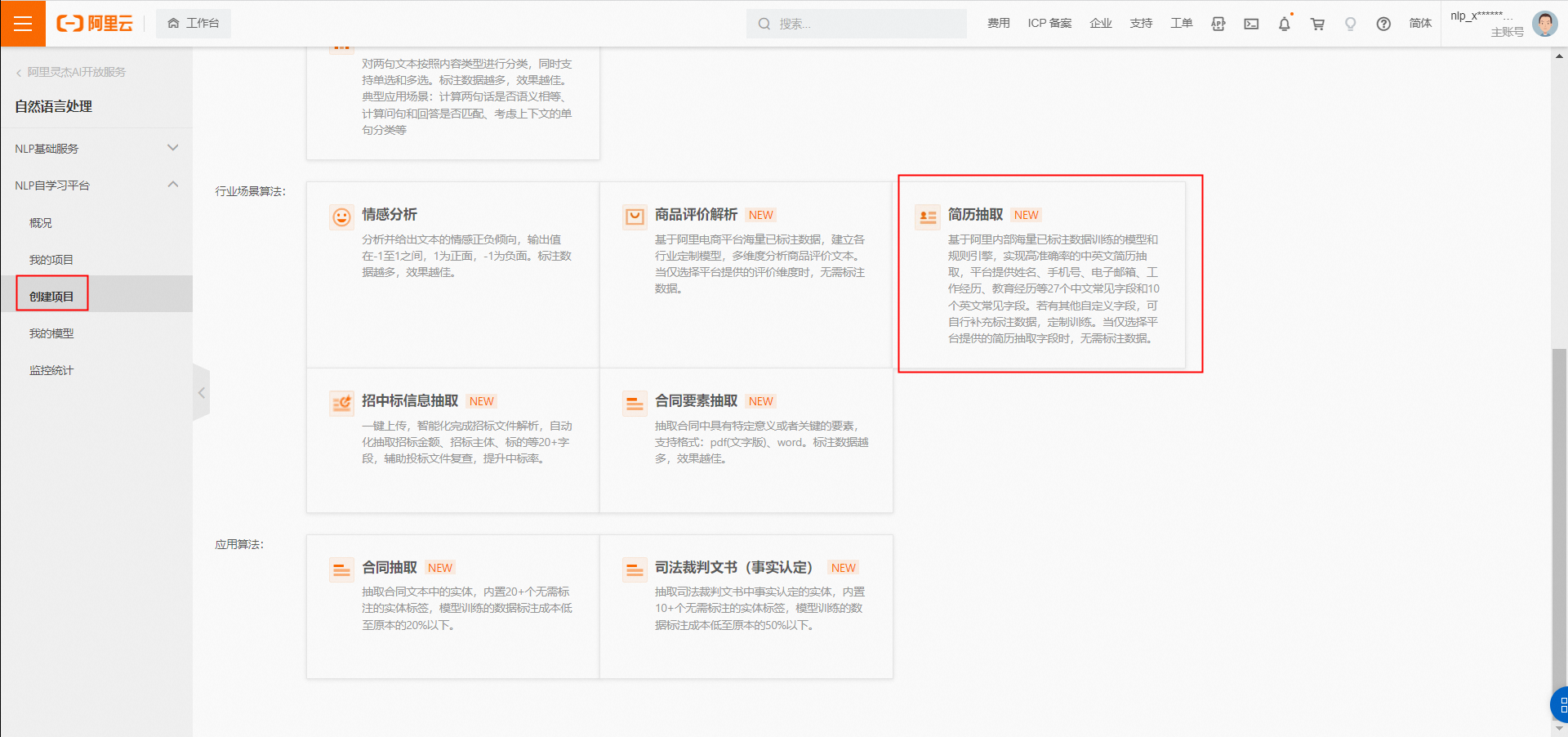
在NLP自學習平臺中【點擊進入自學習管控臺】,支持多個基本項目和應用算法。在本教程中,我們將引導您掌握通過自學習平臺創建一個“簡歷抽取”的項目。
進入“我的項目”或“創建項目”,選擇應用算法中的“簡歷抽取”點擊“創建”。
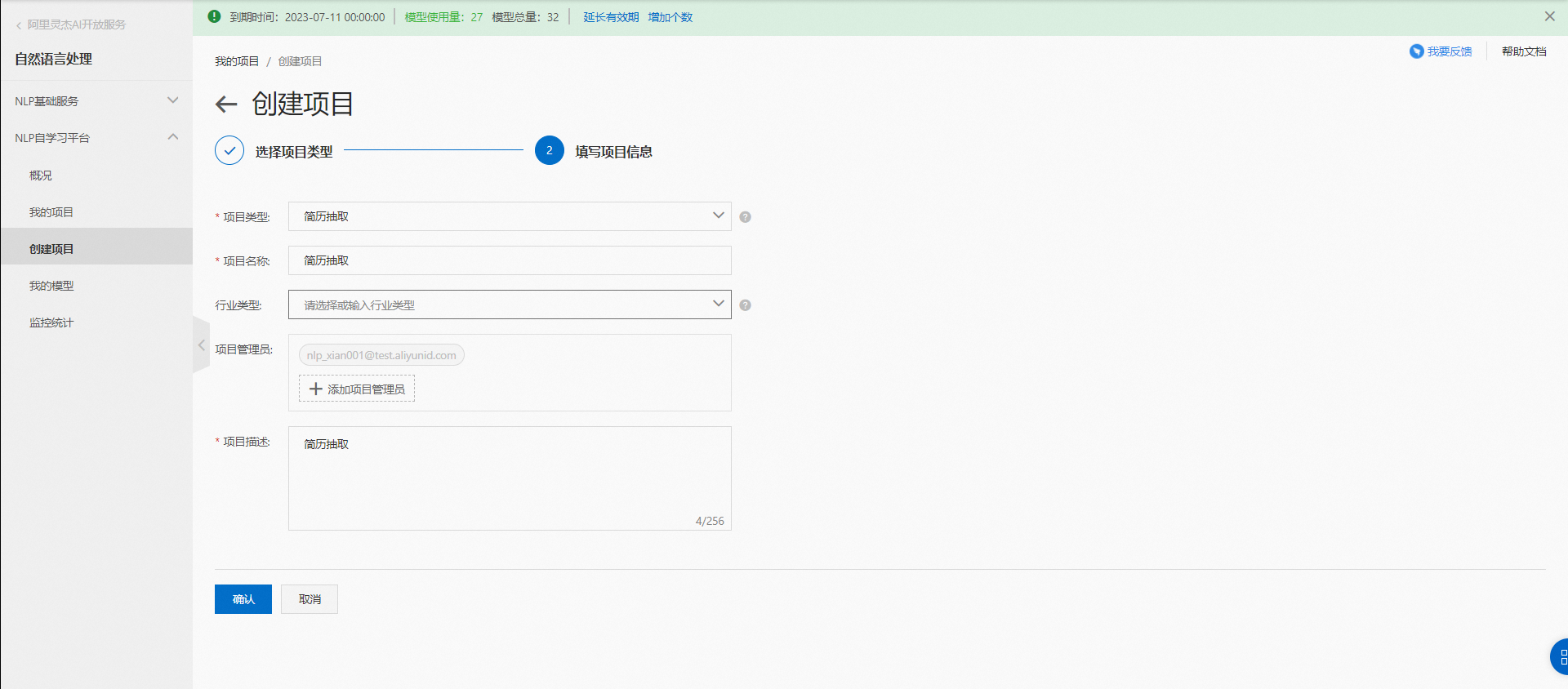
在接下來的頁面填寫項目名稱和項目描述即可。
二、數據準備
進入“我的項目”后,可以在數據中心中管理您的數據,有兩種方式可以創建數據:
1、創建標注任務;2、上傳數據集。
2.1創建標注任務
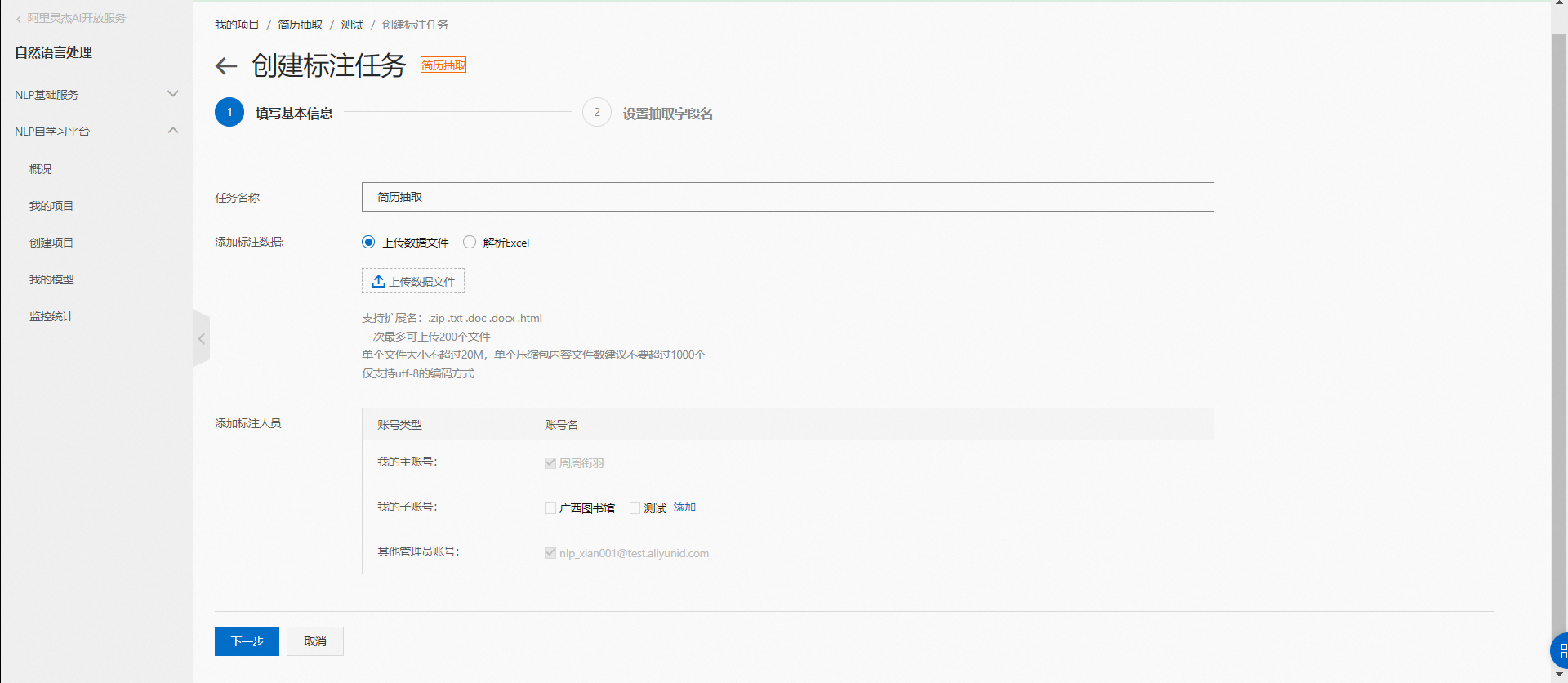
步驟一:上傳待標注文檔,添加標注人員
創建者和項目管理員默認為標注人員,同時,您也可以將標注任務分配給您創建的阿里云子賬號,被分配用戶通過子賬號的賬號密碼登錄本平臺,即可參與數據標注。
子賬號登錄說明:
1、子賬號登錄頁,登錄:https://signin.aliyun.com/login.htm
2、登錄后,點擊進入我的項目-創建標注任務。
注意:目前僅支持UTF-8編碼方式的數據文件
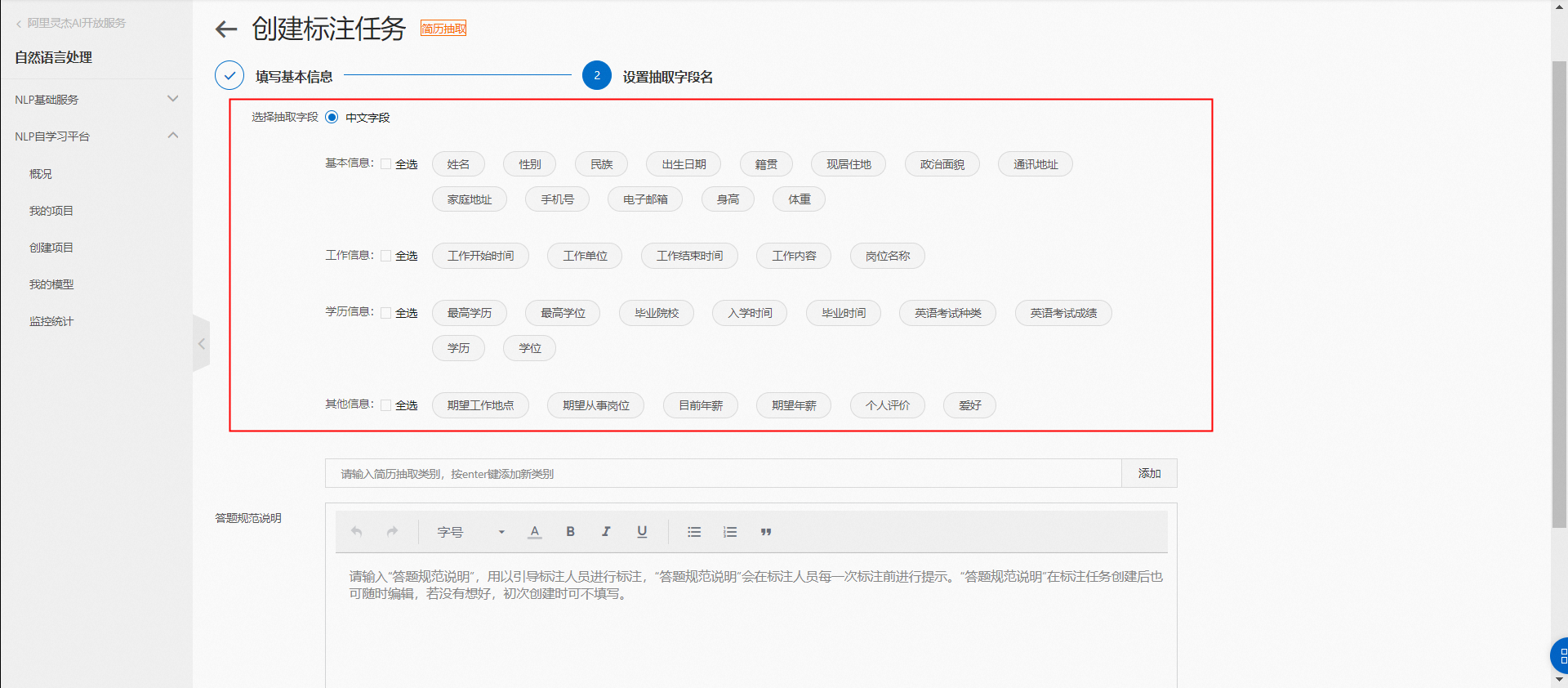
步驟二:添加自定義標簽
簡歷抽取內置27個中文常見字段和10個英文常見字段,模型訓練的數據標注成本低至原本的20%以下。
選擇本次標注需要優化的預置字段,并逐個添加需要標注的子那個定義標簽字段名;
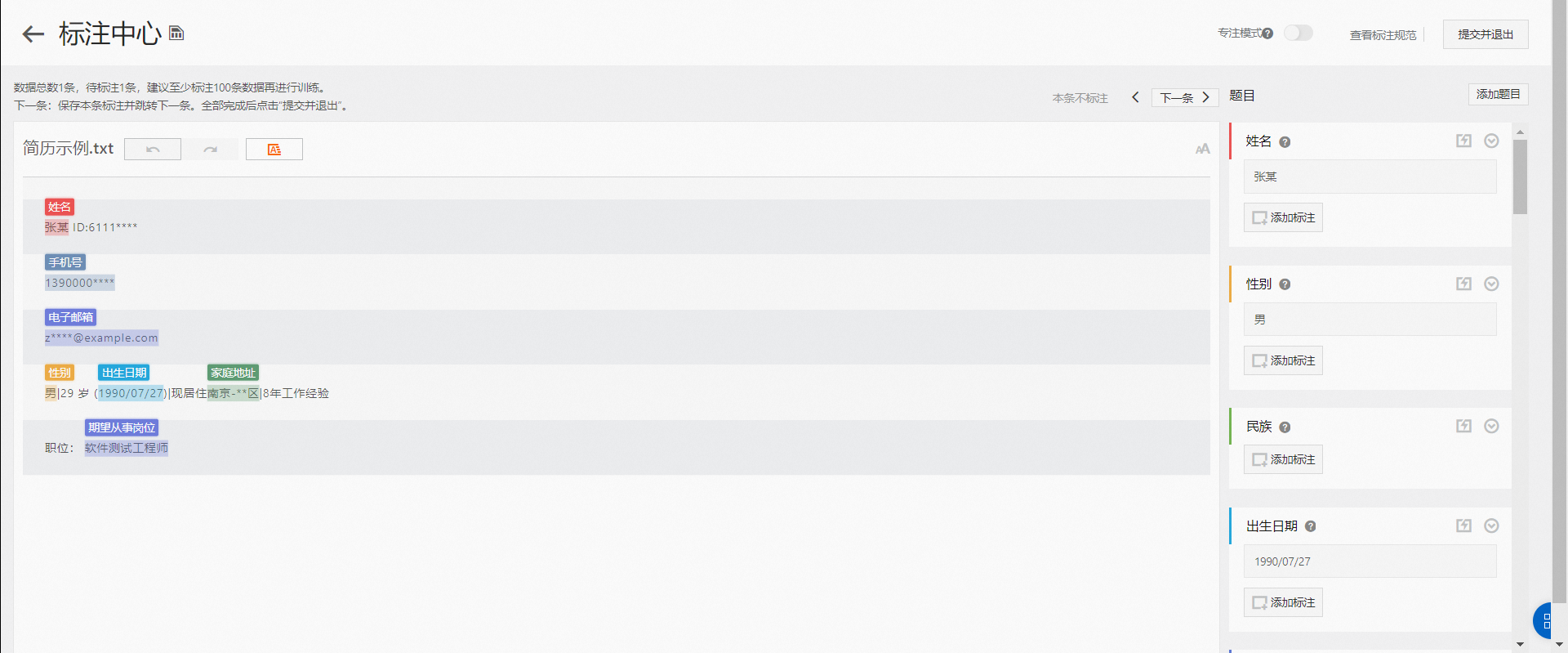
步驟三:標注數據
2.2 上傳數據集
由于模型需要通過標注數據來從中學習規律,因此我們首先要準備好一個標注數據集。
對于用戶已經積累了一部分標注數據的情況,我們需要您按照自學習平臺所支持的輸入格式進行組織,并且上傳。
自行上傳的標注數據為JSON格式,且需要符合以下格式,其中文本的內容放在“content”中,而標簽的內容放在“records”中,records 中key 為實體名,value 為標注內容在原文中的偏移量。
{
"51979692":
{
"records":
{
"姓名":[{"offset":[0,2],"span":"張某"}],
"手機號":[{"offset":[15,26],"span":"1390000****"}],
"出生日期":[{"offset":[53,63],"span":"1990/07/27"}],
"家庭地址":[{"offset":[68,74],"span":"南京-**區"}],
"期望從事崗位":[{"offset":[86,93],"span":"軟件測試工程師"}],
"電子郵箱":[{"offset":[27,44],"span":"z****@example.com"}],
"性別":[{"offset":[45,46],"span":"男"}]
},
"content":"張某 ID:6111****\n1390000****\nz****@example.com\n男|29 歲 (1990/07/27)|現居住南京-**區|8年工作經驗\n職位: 軟件測試工程師\n"
}
}三、創建模型
在“模型中心”點擊“創建模型”;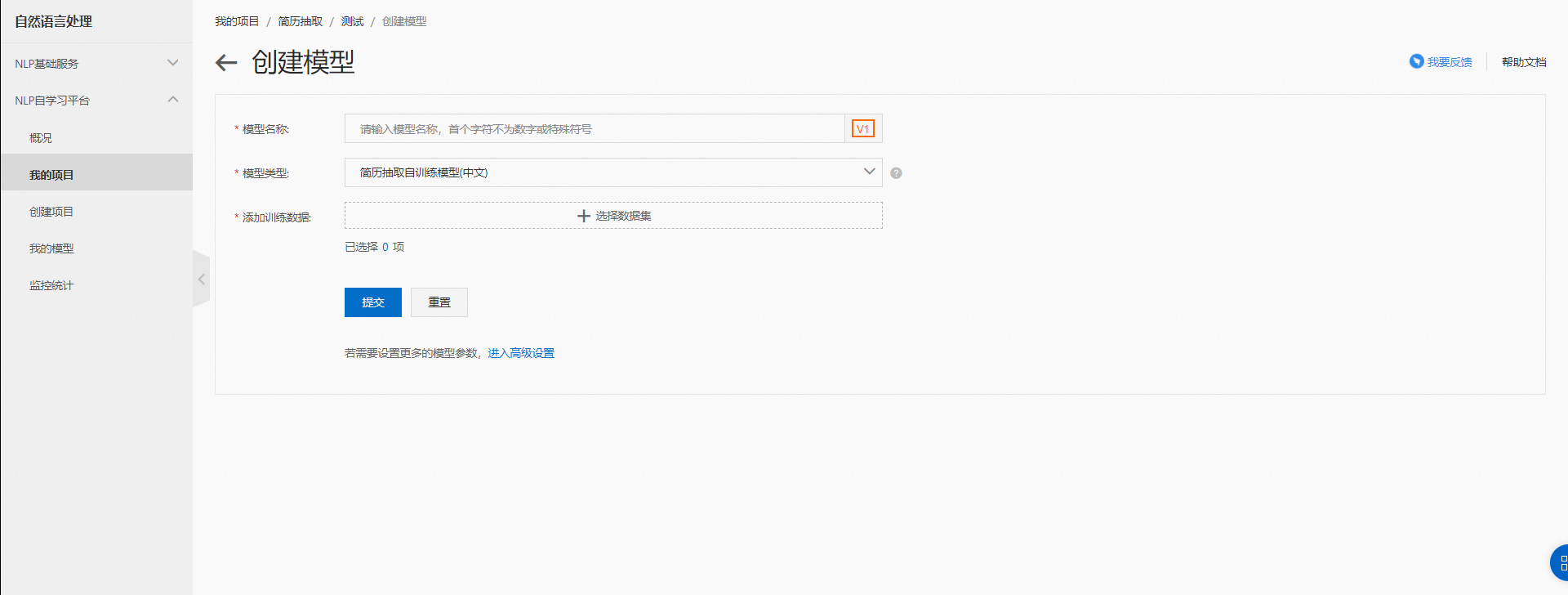
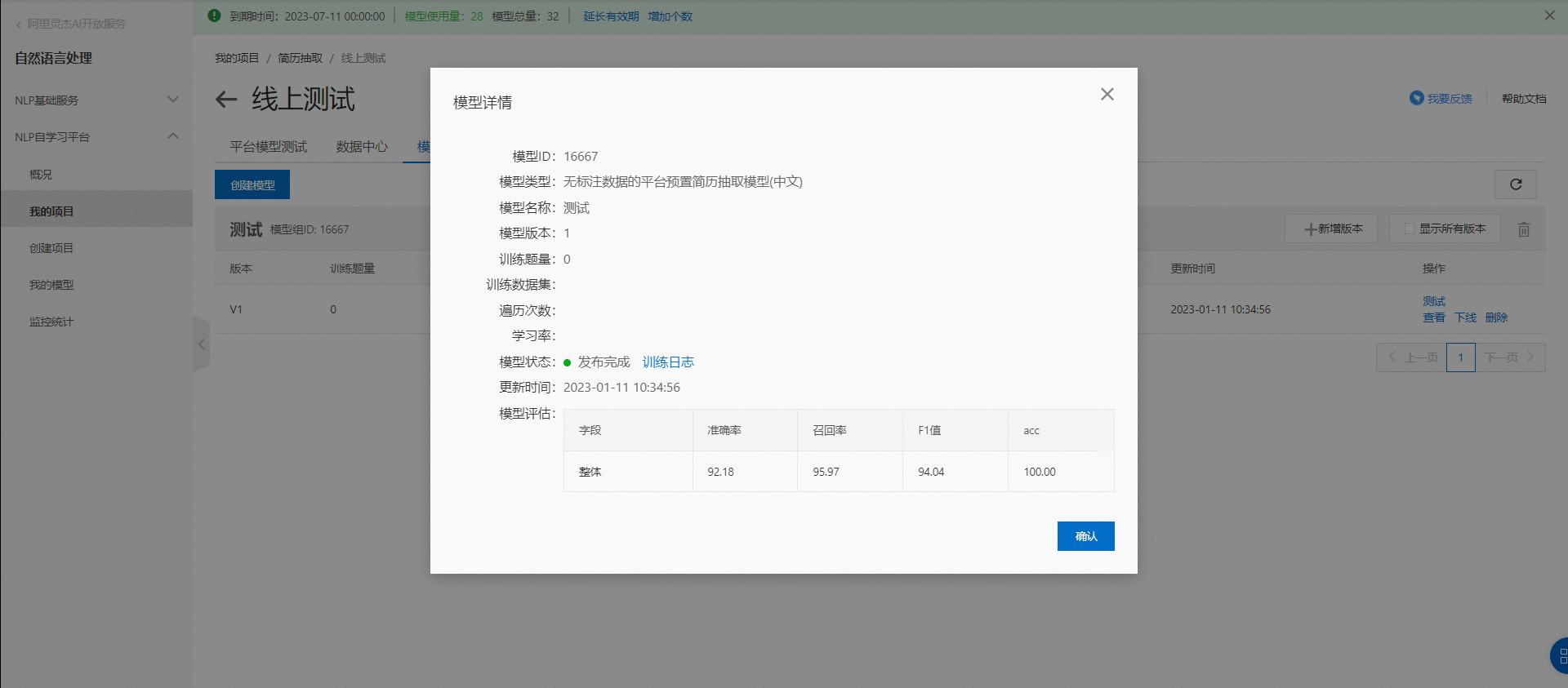
查看模型詳情,點擊模型右側“查看”按鈕查看模型詳情。
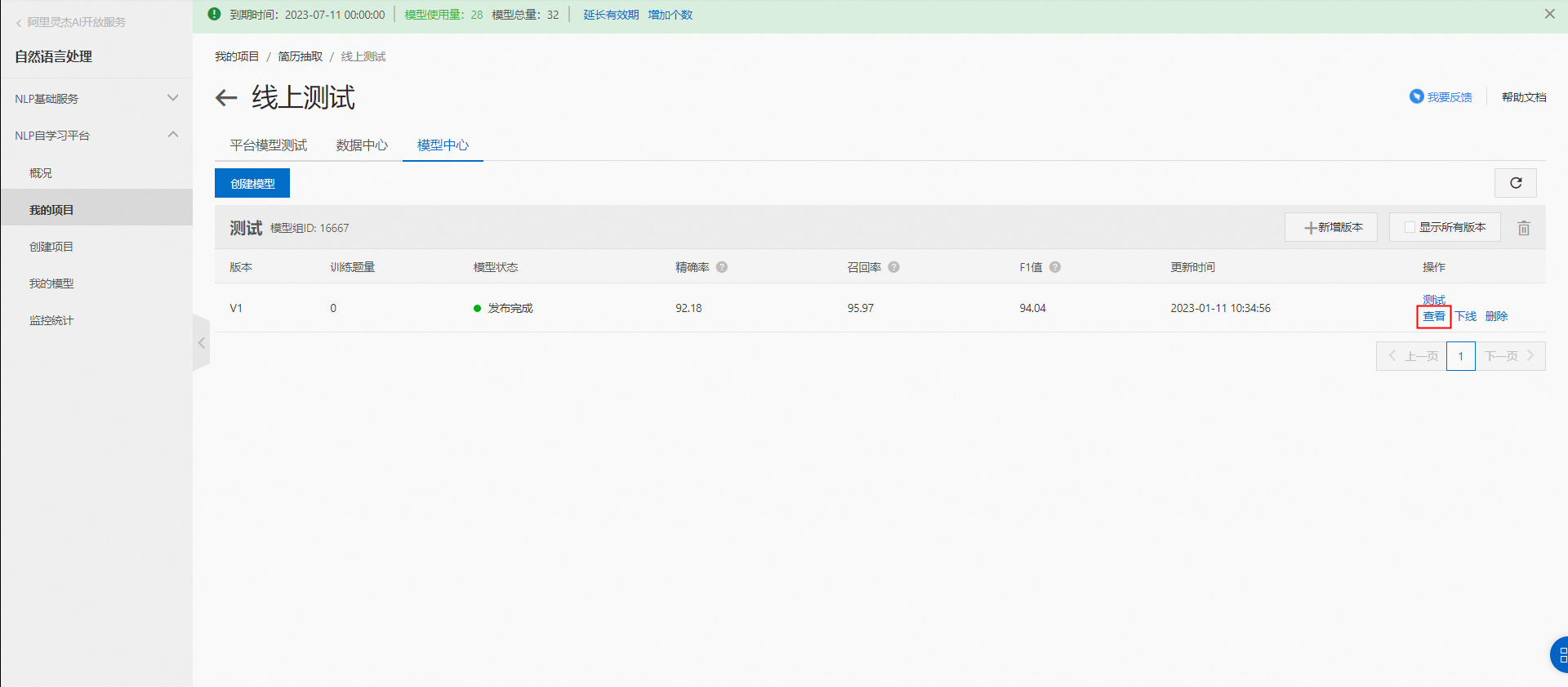
模型詳情頁
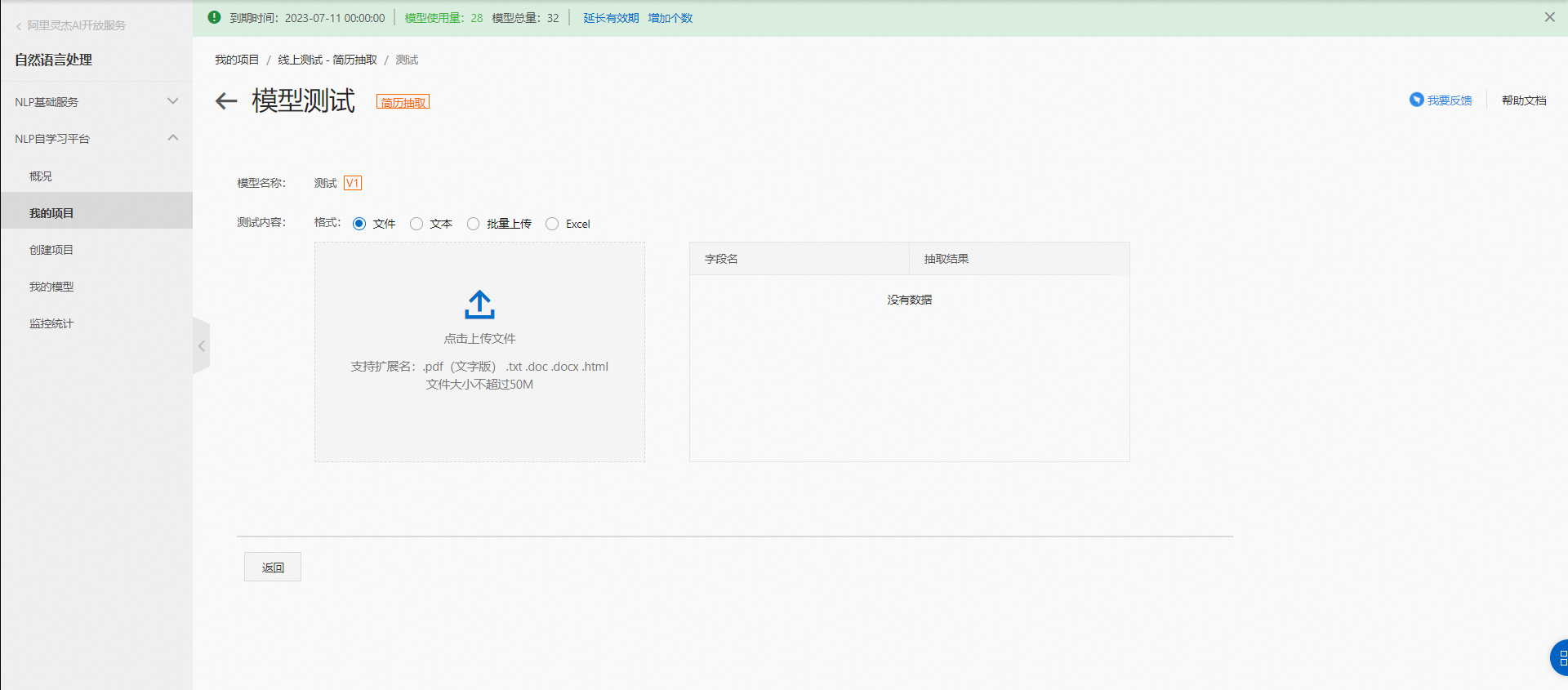
模型測試
模型訓練完成后,可對訓練好的模型進行線上測試模型效果;
平臺模型測試
基于平臺已訓練好的模型進行文本測試,可以針對需要提升的標簽準確率進行單獨訓練;