常見問題
本文匯總了云數(shù)據(jù)庫ClickHouse的常見問題及解決方案。
選型與購買
擴(kuò)容與縮容
連接
遷移與同步
數(shù)據(jù)寫入與查詢
數(shù)據(jù)存儲
監(jiān)控、升級、系統(tǒng)參數(shù)
其他
云數(shù)據(jù)庫ClickHouse和官方版本對比多了哪些功能和特性?
云數(shù)據(jù)庫ClickHouse主要對社區(qū)版本進(jìn)行穩(wěn)定性Bug修復(fù),同時提供資源隊列進(jìn)行用戶角色級別的資源使用優(yōu)先級配置。
購買云數(shù)據(jù)庫ClickHouse實例時,推薦選擇哪一個版本?
云數(shù)據(jù)庫ClickHouse根據(jù)開源社區(qū)公開的LTS內(nèi)核穩(wěn)定版提供服務(wù),通常在版本推出3個月相對穩(wěn)定后啟動云服務(wù)售賣。當(dāng)前建議購買21.8及以上版本。更多版本功能對比,請參見版本功能對比。
單雙副本實例各有什么特點?
單副本實例每一個Shard節(jié)點無副本節(jié)點,無高可用服務(wù)保障。數(shù)據(jù)安全性基于云盤多副本存儲,性價比高。
雙副本實例每一個Shard節(jié)點對應(yīng)一個副本服務(wù)節(jié)點,在主節(jié)點故障不能提供服務(wù)時副本節(jié)點可提供容災(zāi)服務(wù)支持。
購買鏈路資源時顯示“當(dāng)前區(qū)域資源不足”,應(yīng)該如何處理?
解決方案:您可以選擇同地域的其他區(qū)域購買。VPC網(wǎng)絡(luò)支持相同區(qū)域不同可用區(qū)之間打通,同區(qū)域網(wǎng)絡(luò)延遲無感知。
水平擴(kuò)縮容耗時受什么影響?
水平擴(kuò)縮容過程涉及數(shù)據(jù)搬遷,實例里面數(shù)據(jù)越多搬得越多,耗時時間越長。
擴(kuò)縮容期間對實例有什么影響?
為保證擴(kuò)縮容中數(shù)據(jù)搬遷后的數(shù)據(jù)一致性,擴(kuò)縮容期間實例處于可讀不可寫狀態(tài)。
水平擴(kuò)縮容升級有什么建議?
水平擴(kuò)縮容耗時較長,當(dāng)集群性能不滿足時,請優(yōu)先選擇垂直升配。如何進(jìn)行垂直升配,請參見社區(qū)兼容版集群垂直變配和水平擴(kuò)縮容。
每個端口的含義是什么?
版本支持 | 協(xié)議 | 端口號 | 適用場景 |
社區(qū)兼容版/企業(yè)版 | TCP | 3306 | 使用clickhouse-client工具連接云數(shù)據(jù)庫ClickHouse時配置,詳細(xì)操作請參見通過命令行工具連接ClickHouse。 |
社區(qū)兼容版/企業(yè)版 | HTTP | 8123 | 使用JDBC方式連接云數(shù)據(jù)庫ClickHouse進(jìn)行應(yīng)用開發(fā)時配置,詳細(xì)操作請參見通過JDBC方式連接ClickHouse。 |
社區(qū)兼容版 | MySQL | 9004 | 使用MySQL協(xié)議連接云數(shù)據(jù)庫ClickHouse時配置,詳細(xì)操作請參見通過MySQL協(xié)議連接ClickHouse。 |
社區(qū)兼容版/企業(yè)版 | HTTPS | 8443 | 使用HTTPS協(xié)議訪問云數(shù)據(jù)庫ClickHouse時配置,詳細(xì)操作請參見通過HTTPS協(xié)議連接ClickHouse。 |
每種開發(fā)語言通過SDK連接云數(shù)據(jù)庫ClickHouse對應(yīng)的端口是什么?
開發(fā)語言 | HTTP協(xié)議 | TCP協(xié)議 |
Java | 8123 | 3306 |
Python | ||
Go |
Go、Python語言對應(yīng)推薦什么SDK?
詳情請參見第三方開發(fā)庫。
如何處理客戶端工具連接集群時報錯:connect timed out?
您可以采取如下解決方案。
檢查網(wǎng)絡(luò)是否暢通。通過
ping命令檢查網(wǎng)絡(luò)是否通暢,通過telnet命令探測數(shù)據(jù)庫3306和8123端口是否開放。檢查是否配置了ClickHouse白名單,配置方法請參見 設(shè)置白名單。
檢查客戶端機(jī)器IP是否正確。通常公司辦公網(wǎng)內(nèi)的機(jī)器IP經(jīng)常變動,用戶看到的不是正確的IP地址。通過訪問專業(yè)IP探查服務(wù)確定真實IP,示例請參見whatsmyip。
為什么MySQL、HDFS、Kafka等外表無法連通?
目前20.3和20.8版本在創(chuàng)建相關(guān)外表時程序內(nèi)會自動進(jìn)行驗證,如果創(chuàng)建表成功,那說明網(wǎng)絡(luò)是通的。如果無法創(chuàng)建成功,常見原因如下。
目標(biāo)端和ClickHouse不在同一個VPC內(nèi),網(wǎng)絡(luò)無法連通。
MySQL端存在白名單相關(guān)設(shè)置,需要在MySQL端添加ClickHouse的白名單。
對于Kafka外表,表創(chuàng)建成功,但查詢沒有結(jié)果。常見原因是Kafka中數(shù)據(jù)通過表結(jié)構(gòu)給出的字段和格式解析失敗,報錯信息會給出解析失敗的具體位置。
為什么程序無法連接ClickHouse?
常見原因及解決方案如下。
常見原因1:VPC網(wǎng)絡(luò)、公網(wǎng)網(wǎng)絡(luò)環(huán)境不對。同一VPC內(nèi)可用內(nèi)網(wǎng)連接,不在同一VPC內(nèi)需開設(shè)公網(wǎng)后連接。
解決方案:開通公網(wǎng)詳情請參見申請和釋放外網(wǎng)地址。
常見原因2:白名單未配置。
解決方案:設(shè)置白名單詳情請參見設(shè)置白名單。
常見原因3:ECS安全組未放開。
解決方案:開放安全組詳情請參見安全組操作指引。
常見原因4:公司設(shè)置了網(wǎng)絡(luò)防火墻。
解決方案:修改防火墻規(guī)則。
常見原因5:連接串中的賬號密碼包含特殊字符
!@#$%^&*()_+=,這些特殊字符在連接時無法被識別,導(dǎo)致實例連接失敗。解決辦法:您需要在連接串中對特殊字符進(jìn)行轉(zhuǎn)義處理,轉(zhuǎn)義規(guī)則如下。
! : %21 @ : %40 # : %23 $ : %24 % : %25 ^ : %5e & : %26 * : %2a ( : %28 ) : %29 _ : %5f + : %2b = : %3d示例:密碼為
ab@#c時,在連接串中對特殊字符進(jìn)行轉(zhuǎn)義處理,密碼對應(yīng)為ab%40%23c。常見原因6:云數(shù)據(jù)庫ClickHouse會默認(rèn)為您掛載CLB。CLB為按量付費,如果您的賬號欠費可能會導(dǎo)致您的云數(shù)據(jù)庫ClickHouse無法訪問。
解決辦法:查詢阿里云賬號是否欠費。如果欠費請及時進(jìn)行繳費,阿里云賬戶查詢詳情請參見資金賬戶查詢?nèi)肟?/a>。
如何處理ClickHouse超時問題?
云數(shù)據(jù)庫ClickHouse內(nèi)核中有很多超時相關(guān)的參數(shù)設(shè)置,并且提供了多種協(xié)議進(jìn)行交互,例如您可以設(shè)置HTTP協(xié)議和TCP協(xié)議的相關(guān)參數(shù)處理云數(shù)據(jù)庫ClickHouse超時問題。
HTTP協(xié)議
HTTP協(xié)議是云數(shù)據(jù)庫ClickHouse在生產(chǎn)環(huán)境中最常使用的交互方式,包括官方提供的jdbc driver、阿里云DMS、DataGrip,后臺使用的都是HTTP協(xié)議。HTTP協(xié)議常用的端口號為8123。
如何處理distributed_ddl_task_timeout超時問題
分布式DDL查詢(帶有 on cluster)的執(zhí)行等待時間,系統(tǒng)默認(rèn)是180s。您可以在DMS上執(zhí)行以下命令來設(shè)置全局參數(shù),設(shè)置后需要重啟集群。
set global on cluster default distributed_ddl_task_timeout = 1800;由于分布式DDL是基于ZooKeeper構(gòu)建任務(wù)隊列異步執(zhí)行,執(zhí)行等待超時并不代表查詢失敗,只表示之前發(fā)送還在排隊等待執(zhí)行,用戶不需要重復(fù)發(fā)送任務(wù)。
如何處理max_execution_time超時問題
一般查詢的執(zhí)行超時時間,DMS平臺上默認(rèn)設(shè)置是7200s,jdbc driver、DataGrip上默認(rèn)是30s。超時限制觸發(fā)之后查詢會自動取消。用戶可以進(jìn)行查詢級別更改,例如
select * from system.numbers settings max_execution_time = 3600,也可以在DMS上執(zhí)行以下命令來設(shè)置全局參數(shù)。set global on cluster default max_execution_time = 3600;
如何處理socket_timeout超時問題
HTTP協(xié)議在監(jiān)聽socket返回結(jié)果時的等待時間,DMS平臺上默認(rèn)設(shè)置是7200s,jdbc driver、DataGrip上默認(rèn)是30s。該參數(shù)不是Clickhouse系統(tǒng)內(nèi)的參數(shù),它屬于jdbc在HTTP協(xié)議上的參數(shù),但它是會影響到前面的max_execution_time參數(shù)設(shè)置效果,因為它決定了客戶端在等待結(jié)果返回上的時間限制。所以一般用戶在調(diào)整max_execution_time參數(shù)的時候也需要配套調(diào)整socket_timeout參數(shù),略微高于max_execution_time即可。用戶設(shè)置參數(shù)時需要在jdbc鏈接串上添加socket_timeout這個property,單位是毫秒,例如:'jdbc:clickhouse://127.0.0.1:8123/default?socket_timeout=3600000'。
使用ClickHouse服務(wù)端IP直接鏈接時的Client異常hang住
阿里云上的ECS在跨安全組鏈接時,有可能陷入靜默鏈接錯誤。具體原因是jdbc客戶端所在ECS機(jī)器的安全組白名單并沒有開放給ClickHouse服務(wù)端機(jī)器。當(dāng)客戶端的請求經(jīng)過超長時間才得到查詢結(jié)果時,返回的報文可能因為路由表不通無法發(fā)送到客戶端。此時客戶端就陷入了異常hang住狀態(tài)。
該問題的處理辦法和SLB鏈接異常斷鏈問題一樣,開啟send_progress_in_http_headers可以解決大部分問題。在極少數(shù)情況下,開啟send_progress_in_http_headers仍不能解決問題的,您可以嘗試配置jdbc客戶端所在ECS機(jī)器的安全組白名單,把ClickHouse服務(wù)端地址加入到白名單中。
TCP協(xié)議
TCP協(xié)議最常使用的場景是ClickHouse自帶的命令行工具進(jìn)行交互分析時,社區(qū)兼容版集群常見端口號為3306,企業(yè)版集群常見端口號為9000。因為TCP協(xié)議里有鏈接定時探活報文,所以它不會出現(xiàn)socket層面的超時問題。您只需關(guān)注distributed_ddl_task_timeout和max_execution_time參數(shù)的超時,設(shè)置方法和HTTP協(xié)議一致。
為什么OSS外表導(dǎo)入ORC、PARQUET等格式的數(shù)據(jù),出現(xiàn)內(nèi)存報錯或OOM掛掉?
常見原因:內(nèi)存使用率比較高。
您可以采取如下解決方案。
把OSS上的文件拆分為一個一個的小文件,然后再進(jìn)行導(dǎo)入。
進(jìn)行內(nèi)存的升配。如何升配,請參見社區(qū)兼容版集群垂直變配和水平擴(kuò)縮容。
如何處理導(dǎo)入數(shù)據(jù)報錯:too many parts?
ClickHouse每次寫入都會生成一個data part,如果每次寫入一條或者少量的數(shù)據(jù),那會造成ClickHouse內(nèi)部有大量的data part(會給merge和查詢造成很大的負(fù)擔(dān))。為了防止出現(xiàn)大量的data part,ClickHouse內(nèi)部做了很多限制,這就是too many parts報錯的內(nèi)在原因。出現(xiàn)該錯誤,請增加寫入的批量大小。如果無法調(diào)整批量大小,可以在控制臺修改參數(shù):merge_tree.parts_to_throw_insert,將參數(shù)的取值設(shè)置的大一些。
為什么DataX導(dǎo)入速度慢?
常見原因及解決方案如下。
常見原因1:參數(shù)設(shè)置不合理。ClickHouse適合使用大batch、少數(shù)幾個并發(fā)進(jìn)行寫入。多數(shù)情況下batch可以高達(dá)幾萬甚至幾十萬(取決于您的單行RowSize大小,一般按照每行100Byte進(jìn)行評估,您需要根據(jù)實際數(shù)據(jù)特征進(jìn)行估算)。
解決方案:并發(fā)數(shù)建議不超過10個。您可以調(diào)整不同參數(shù)進(jìn)行嘗試。
常見原因2:DataWorks獨享資源組的ECS規(guī)格太小。比如獨享資源的CPU、Memory太小,導(dǎo)致并發(fā)數(shù)、網(wǎng)絡(luò)出口帶寬受限;或者是batch設(shè)置太大而Memory太小,引起DataWorks進(jìn)程Java GC等。
解決方案:您可以通過DataWorks的輸出日志對ECS規(guī)格大小進(jìn)行確認(rèn)。
常見原因3:從數(shù)據(jù)源中讀取慢。
解決方案:您可以在DataWorks輸出日志中搜索totalWaitReaderTime、totalWaitWriterTime,如果發(fā)現(xiàn)totalWaitReaderTime明顯大于totalWaitWriterTime,則表明主要耗時在讀取端,而不是寫入端。
常見原因4:使用了公網(wǎng)Endpoint。公網(wǎng)Endpoint的帶寬非常有限,無法承載高性能的數(shù)據(jù)導(dǎo)入導(dǎo)出。
解決方案:您需要替換為VPC網(wǎng)絡(luò)的Endpoint。
常見原因5:有臟數(shù)據(jù)。在沒有臟數(shù)據(jù)的情況下,數(shù)據(jù)以batch方式寫入。但是遇到了臟數(shù)據(jù),正在寫入的batch就會失敗,并回退到逐行寫入,生成大量的data part,大幅度降低了寫入速度。
您可以參考如下兩種方式判斷是否有臟數(shù)據(jù)。
查看報錯信息,如果返回信息包含
Cannot parse,則存在臟數(shù)據(jù)。代碼如下。
SELECT written_rows, written_bytes, query_duration_ms, event_time, exception FROM system.query_log WHERE event_time BETWEEN '2021-11-22 22:00:00' AND '2021-11-22 23:00:00' AND lowerUTF8(query) LIKE '%insert into <table_name>%' and type != 'QueryStart' and exception_code != 0 ORDER BY event_time DESC LIMIT 30;查看batch行數(shù),如果batch行數(shù)變?yōu)?,則存在臟數(shù)據(jù)。
代碼如下。
SELECT written_rows, written_bytes, query_duration_ms, event_time FROM system.query_log WHERE event_time BETWEEN '2021-11-22 22:00:00' AND '2021-11-22 23:00:00' AND lowerUTF8(query) LIKE '%insert into <table_name>%' and type != 'QueryStart' ORDER BY event_time DESC LIMIT 30;
解決方案:您需要在數(shù)據(jù)源刪除或修改臟數(shù)據(jù)。
為什么Hive導(dǎo)入后其數(shù)據(jù)行數(shù)跟ClickHouse對不上?
您可以通過以下手段進(jìn)行排查。
首先通過系統(tǒng)表query_log來查看導(dǎo)入的過程中是否有報錯,如果有報錯,那很有可能出現(xiàn)數(shù)據(jù)丟失的情況。
確定使用的表引擎是否可以去重,比如使用ReplacingMergeTree,那很可能出現(xiàn)ClickHouse中的Count小于Hive中的情況。
重新確認(rèn)Hive中數(shù)據(jù)行數(shù)的正確性,很有可能出現(xiàn)源頭的行數(shù)確定錯誤的情況。
為什么Kafka導(dǎo)入后其數(shù)據(jù)行數(shù)跟ClickHouse對不上?
您可以通過以下手段進(jìn)行排查。
首先通過系統(tǒng)表query_log來查看導(dǎo)入的過程中是否有報錯,如果有報錯,那很有可能出現(xiàn)數(shù)據(jù)丟失的情況。
確定使用的表引擎是否可以去重,比如使用ReplacingMergeTree,那很可能出現(xiàn)ClickHouse中的Count小于Kafka中的情況。
查看Kafka外表的配置是否有kafka_skip_broken_messages參數(shù)的配置,如果有該參數(shù),那可能會跳過解析失敗的Kafka消息,導(dǎo)致ClickHouse總的行數(shù)是小于Kafka中的。
如何使用Spark、Flink導(dǎo)入數(shù)據(jù)?
如何使用Spark導(dǎo)入數(shù)據(jù)請參見從Spark導(dǎo)入。
如何使用Flink導(dǎo)入數(shù)據(jù)請參見從Flink SQL導(dǎo)入。
如何從現(xiàn)有ClickHouse導(dǎo)入數(shù)據(jù)到云數(shù)據(jù)庫ClickHouse?
您可以采取如下方案。
通過ClickHouse Client以導(dǎo)出文件的形式進(jìn)行數(shù)據(jù)遷移,詳情請參見將自建ClickHouse數(shù)據(jù)遷移到云ClickHouse中。
通過Remote函數(shù)進(jìn)行數(shù)據(jù)的遷移。
INSERT INTO <目的表> SELECT * FROM remote('<連接串>', '<庫>', '<表>', '<username>', '<password>');
使用MaterializeMySQL引擎同步MySQL數(shù)據(jù)時,為什么出現(xiàn)如下報錯:The slave is connecting using CHANGE MASTER TO MASTER_AUTO_POSITION = 1, but the master has purged binary logs containing GTIDs that the slave requires?
常見原因:MaterializeMySQL引擎停止同步的時間太久,導(dǎo)致MySQL Binlog日志過期被清理掉。
解決方案:刪除報錯的數(shù)據(jù)庫,重新在云數(shù)據(jù)庫ClickHouse中創(chuàng)建同步的數(shù)據(jù)庫。
使用MaterializeMySQL引擎同步MySQL數(shù)據(jù)時,為什么出現(xiàn)表停止同步?為什么系統(tǒng)表system.materialize_mysql中sync_failed_tables字段不為空?
常見原因:同步過程中使用了云數(shù)據(jù)庫ClickHouse不支持的MySQL DDL語句。
解決方案:重新同步MySQL數(shù)據(jù),具體步驟如下。
刪除停止同步的表。
DROP TABLE <table_name> ON cluster default;說明table_name為停止同步的表名。如果停止同步的表有分布式表,那么本地表和分布式表都需要刪除。重啟同步進(jìn)程。
ALTER database <database_name> ON cluster default MODIFY SETTING skip_unsupported_tables = 1;說明<database_name>為云數(shù)據(jù)庫ClickHouse中同步的數(shù)據(jù)庫。
如何處理報錯:“Too many partitions for single INSERT block (more than 100)”?
常見原因:單個INSERT操作中超過了max_partitions_per_insert_block(最大分區(qū)插入塊,默認(rèn)值為100)。ClickHouse每次寫入都會生成一個data part(數(shù)據(jù)部分),一個分區(qū)可能包含一個或多個data part,如果單個INSERT操作中插入了太多分區(qū)的數(shù)據(jù),那會造成ClickHouse內(nèi)部有大量的data part(會給合并和查詢造成很大的負(fù)擔(dān))。為了防止出現(xiàn)大量的data part,ClickHouse內(nèi)部做了限制。
解決方案:請執(zhí)行以下操作,調(diào)整分區(qū)數(shù)或者max_partitions_per_insert_block參數(shù)。
調(diào)整表結(jié)構(gòu),調(diào)整分區(qū)方式,或避免單次插入的不同分區(qū)數(shù)超過限制。
避免單次插入的不同分區(qū)數(shù)超過限制,可根據(jù)數(shù)據(jù)量適當(dāng)修改max_partitions_per_insert_block參數(shù),放大單個插入的不同分區(qū)數(shù)限制,修改語法如下:
單節(jié)點實例
SET GLOBAL max_partitions_per_insert_block = XXX;多節(jié)點實例
SET GLOBAL ON cluster DEFAULT max_partitions_per_insert_block = XXX;說明ClickHouse社區(qū)推薦默認(rèn)值為100,分區(qū)數(shù)不要設(shè)置得過大,否則可能對性能產(chǎn)生影響。在批量導(dǎo)入數(shù)據(jù)后可修改值為默認(rèn)值。
如何處理insert into select XXX內(nèi)存超限報錯?
常見原因及解決方案如下。
常見原因1:內(nèi)存使用率比較高。
解決方案:調(diào)整參數(shù)max_insert_threads,減少可能的內(nèi)存使用量。
常見原因2:當(dāng)前是通過
insert into select把數(shù)據(jù)從一個ClickHouse集群導(dǎo)入到另外一個集群。解決方案:通過導(dǎo)入文件的方式來遷移數(shù)據(jù),更多信息請參見將自建ClickHouse數(shù)據(jù)遷移到云ClickHouse中。
如何查詢CPU使用量和內(nèi)存使用量?
您可以在system.query_log系統(tǒng)表里自助查看CPU和MEM在查詢時的使用日志,里面有每個查詢的CPU使用量和內(nèi)存使用量統(tǒng)計。更多信息請參見system.query_log。
如何處理查詢時內(nèi)存超出限制?
ClickHouse服務(wù)端對所有查詢線程都配有memory tracker,同一個查詢下的所有線程tracker會匯報給一個memory tracker for query,再上層還是memory tracker for total。您可以根據(jù)情況采取如下解決方案。
遇到
Memory limit (for query)超限報錯說明是查詢內(nèi)存占用過多(實例總內(nèi)存的70%)導(dǎo)致失敗,這種情況下您需要垂直升配提高實例內(nèi)存規(guī)模。遇到
Memory limit (for total)超限報錯說明是實例總內(nèi)存使用超限(實例總內(nèi)存的90%),這種情況下您可以嘗試降低查詢并發(fā),如果仍然不行則可能是后臺異步任務(wù)占用了比較大的內(nèi)存(常常是寫入后主鍵合并任務(wù)),您需要垂直升配提高實例內(nèi)存規(guī)模。
如何處理查詢報并發(fā)超限?
默認(rèn)Server查詢最大并發(fā)數(shù)為100,您可以在控制臺上進(jìn)行修改。修改運(yùn)行參數(shù)值具體操作步驟如下。
在集群列表頁面,選擇社區(qū)版實例列表,單擊目標(biāo)集群ID。
單擊左側(cè)導(dǎo)航欄的參數(shù)配置。
在參數(shù)配置頁面,單擊max_concurrent_queries參數(shù)的運(yùn)行參數(shù)值后面的編輯按鈕。
在懸浮框中填寫目標(biāo)值,單擊確定。
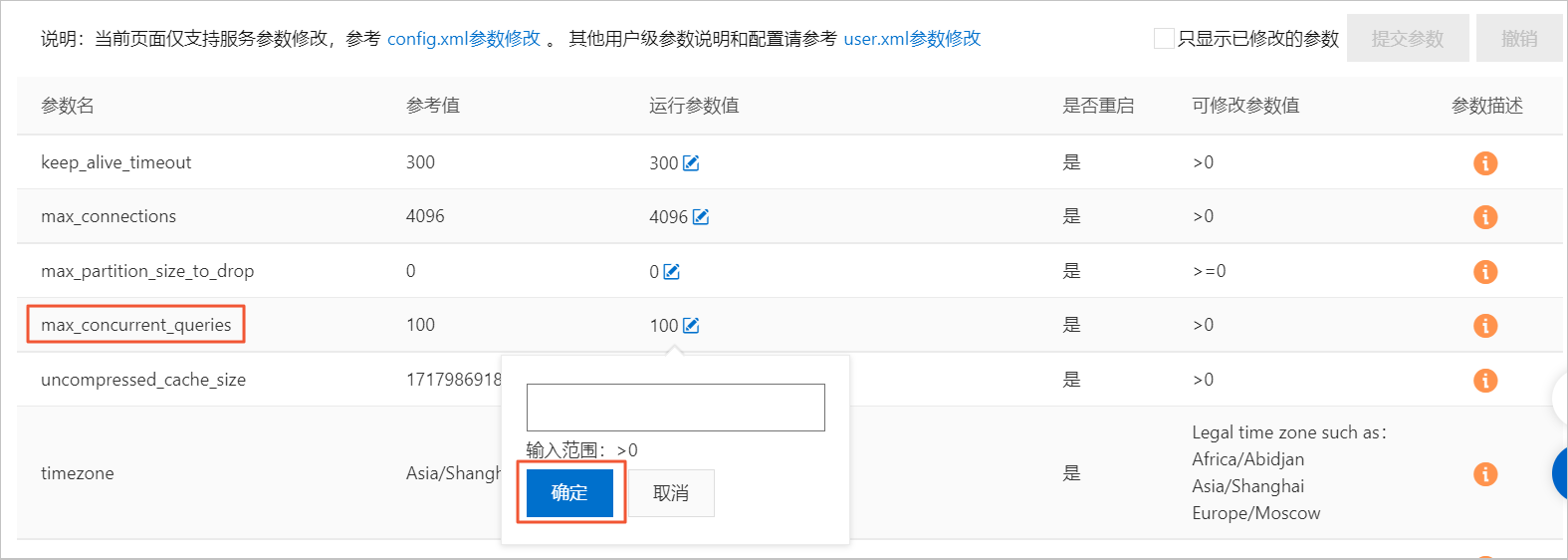
單擊提交參數(shù)。
單擊確定。
在數(shù)據(jù)停止寫入時,同一個查詢語句每次查詢的結(jié)果不一致,應(yīng)該如何處理?
問題詳細(xì)描述:通過select count(*) 查詢數(shù)據(jù)時只有整體數(shù)據(jù)的大概一半,或者數(shù)據(jù)一直在跳變。
您可以采取如下解決方案。
檢查是否是多節(jié)點集群。多節(jié)點集群需要創(chuàng)建分布式表,往分布式表里寫入數(shù)據(jù)并查詢,每次查詢結(jié)果一致。否則每次查詢到不同分片的數(shù)據(jù),結(jié)果不一致。如何創(chuàng)建分布式表請參見創(chuàng)建分布式表。
檢查是否是多副本集群。多副本集群需要建Replicated系列表引擎的表,才能實現(xiàn)副本間數(shù)據(jù)同步。否則每次查到不同副本,結(jié)果不一致。如何創(chuàng)建Replicated系列表引擎的表請參見表引擎。
為什么有時看不到已經(jīng)創(chuàng)建好的表并且查詢結(jié)果一直抖動時多時少?
常見原因及解決方案如下。
常見原因1:建表流程存在問題。ClickHouse的分布式集群搭建并沒有原生的分布式DDL語義。如果您在自建ClickHouse集群時使用
create table創(chuàng)建表,查詢雖然返回了成功,但實際這個表只在當(dāng)前連接的Server上創(chuàng)建了。下次連接重置換一個Server,您就看不到這個表了。解決方案:
建表時,請使用
create table <table_name> on cluster default語句,on cluster default聲明會把這條語句廣播給default集群的所有節(jié)點進(jìn)行執(zhí)行。示例代碼如下。CREATE TABLE test ON cluster default (a UInt64) Engine = MergeTree() ORDER BY tuple();在test表上再創(chuàng)建一個分布式表引擎,建表語句如下。
CREATE TABLE test_dis ON cluster default AS test Engine = Distributed(default, default, test, cityHash64(a));
常見原因2:ReplicatedMergeTree存儲表配置有問題。ReplicatedMergeTree表引擎是對應(yīng)MergeTree表引擎的主備同步增強(qiáng)版,在單副本實例上限定只能創(chuàng)建MergeTree表引擎,在雙副本實例上只能創(chuàng)建ReplicatedMergeTree表引擎。
解決方案:在雙副本實例上建表時,請使用
ReplicatedMergeTree('/clickhouse/tables/{database}/{table}/{shard}', '{replica}')或ReplicatedMergeTree()配置ReplicatedMergeTree表引擎。其中,ReplicatedMergeTree('/clickhouse/tables/{database}/{table}/{shard}', '{replica}')為固定配置,無需修改。
如何處理往表里寫入時間戳數(shù)據(jù)后查詢出來的結(jié)果與實際數(shù)據(jù)不同?
用SELECT timezone()語句,查看時區(qū)是否為當(dāng)?shù)貢r區(qū),如果不是修改timezone配置項的值為當(dāng)?shù)貢r區(qū)。如何修改請參見修改配置項運(yùn)行參數(shù)值。
如何處理建表后查詢表不存在?
常見原因:DDL語句只在一個節(jié)點上執(zhí)行。
解決方案:檢查DDL語句是否有on cluster關(guān)鍵字。更多信息,請參見建表語法。
為什么Kafka外表建表后數(shù)據(jù)不增加?
您可以先對Kafka外表進(jìn)行select * from的查詢,如果查詢報錯,那可以根據(jù)報錯信息確定原因(一般是數(shù)據(jù)解析失敗)。如果查詢正常返回結(jié)果,那需要進(jìn)一步查看目的表(Kafka外表的具體存儲表)和Kafka源表(Kafka外表)的字段是否匹配。如果數(shù)據(jù)寫入失敗,那說明字段是匹配不上的。示例語句如下。
insert into <目的表> as select * from <kafka外表>;為什么客戶端看到的時間結(jié)果和時區(qū)顯示的不一樣?
客戶端設(shè)置了use_client_time_zone,并設(shè)定在了錯誤時區(qū)上。
為什么數(shù)據(jù)寫入后不可見?
一般原因是分布式表和本地表的表結(jié)構(gòu)不一致造成的。您可以通過查詢系統(tǒng)表system.distribution_queue來查看寫入分布式表的時候是否發(fā)生錯誤。
為什么optimize任務(wù)很慢?
optimize任務(wù)非常占用CPU和磁盤吞吐,查詢和optimize任務(wù)都會相互影響,在機(jī)器節(jié)點負(fù)載壓力較大的時候就會表現(xiàn)出optimize很慢問題,目前沒有特殊優(yōu)化方法。
為什么optimize后數(shù)據(jù)仍未主鍵合并?
首先為了讓數(shù)據(jù)有正確的主鍵合并邏輯,需要保證以下兩個前提條件。
存儲表里的partition by定義字段必須是包含在
order by里的,不同分區(qū)的數(shù)據(jù)不會主鍵合并。分布式表里定義的Hash算法字段必須是包含在
order by里的,不同節(jié)點的數(shù)據(jù)不會主鍵合并。
optimize常用命令及相關(guān)說明如下。
命令 | 說明 |
| 嘗試選取MergeTree的data parts進(jìn)行合并,有可能沒有執(zhí)行任務(wù)就返回。執(zhí)行了也并不保證全表的記錄都完成了主鍵合并,一般不會使用。 |
| 指定某個分區(qū),選取分區(qū)中所有的data parts進(jìn)行合并,有可能沒有執(zhí)行任務(wù)就返回。任務(wù)執(zhí)行后代表某個分區(qū)下的數(shù)據(jù)都合并到了同一個data part,單分區(qū)下已經(jīng)完成主鍵合并。但是在任務(wù)執(zhí)行期間寫入的數(shù)據(jù)不會參與合并,若是分區(qū)下只有一個data part也不會重復(fù)執(zhí)行任務(wù)。 說明 對于沒有分區(qū)鍵的表,其默認(rèn)分區(qū)就是partition tuple()。 |
| 對全表所有分區(qū)強(qiáng)制進(jìn)行合并,即使分區(qū)下只有一個data part也會進(jìn)行重新合并,可以用于強(qiáng)制移除TTL過期的記錄。任務(wù)執(zhí)行代價最高,但也有可能沒有執(zhí)行合并任務(wù)就返回。 |
對于上面三種命令,您可以設(shè)置參數(shù)optimize_throw_if_noop通過異常報錯感知是否執(zhí)行任務(wù)。
為什么optimize后數(shù)據(jù)TTL仍未生效?
常見原因及解決方案如下。
常見原因1:數(shù)據(jù)的TTL淘汰是在主鍵合并階段執(zhí)行的,如果data part遲遲沒有進(jìn)行主鍵合并,那過期的數(shù)據(jù)就無法淘汰。
解決方案:
您可以通過手動
optimize final或者optimize 指定分區(qū)的方式觸發(fā)合并任務(wù)。您可以在建表時設(shè)置merge_with_ttl_timeout、ttl_only_drop_parts等參數(shù),提高含有過期數(shù)據(jù)data parts的合并頻率。
常見原因2:表的TTL經(jīng)過修改或者添加,存量的data part里缺少TTL信息或者不正確,這樣也可能導(dǎo)致過期數(shù)據(jù)淘汰不掉。
解決方案:
您可以通過
alter table materialize ttl命令重新生成TTL信息。您可以通過
optimize 分區(qū)更新TTL信息。
為什么optimize后更新刪除操作沒有生效?
云數(shù)據(jù)庫ClickHouse中的更新刪除都是異步執(zhí)行的,目前沒有機(jī)制可以干預(yù)其進(jìn)度。您可以通過system.mutations系統(tǒng)表查看進(jìn)度。
如何進(jìn)行DDL增加列、刪除列、修改列操作?
本地表的修改直接執(zhí)行即可。如果要對分布式表進(jìn)行修改,需分如下情況進(jìn)行。
如果沒有數(shù)據(jù)寫入,您可以先修改本地表,然后修改分布式表。
如果數(shù)據(jù)正在寫入,您需要區(qū)分不同的類型進(jìn)行操作。
類型
操作步驟
增加Nullable的列
修改本地表。
修改分布式表。
修改列的數(shù)據(jù)類型(類型可以相互轉(zhuǎn)換)
刪除Nullable列
修改分布式表。
修改本地表。
增加非Nullable的列
停止數(shù)據(jù)的寫入。
執(zhí)行SYSTEM FLUSH DISTRIBUTED分布式表。
修改本地表。
修改分布式表。
重新進(jìn)行數(shù)據(jù)的寫入。
刪除非Nullable的列
修改列的名稱
為什么DDL執(zhí)行慢,經(jīng)常卡住?
常見原因:DDL全局的執(zhí)行是串行執(zhí)行,復(fù)雜查詢會導(dǎo)致死鎖。
您可以采取如下解決方案。
等待運(yùn)行結(jié)束。
在控制臺嘗試終止查詢。
如何處理分布式DDL報錯:longer than distributed_ddl_task_timeout (=xxx) seconds?
您可以通過使用set global on cluster default distributed_ddl_task_timeout=xxx命令修改默認(rèn)超時時間,xxx為自定義超時時間,單位為秒。全局參數(shù)修改請參見集群參數(shù)修改。
如何處理語法報錯:set global on cluster default?
常見原因及解決方案如下。
常見原因1:ClickHouse客戶端會進(jìn)行語法解析,而
set global on cluster default是服務(wù)端增加的語法。在客戶端尚未更新到與服務(wù)端對齊的版本時,該語法會被客戶端攔截。解決方案:
使用JDBC Driver等不會在客戶端解析語法的工具,比如DataGrip、DBeaver。
編寫JDBC程序來執(zhí)行該語句。
常見原因2:
set global on cluster default key = value;中value是字符串,但是漏寫了引號。解決方案:在字符串類型的value兩側(cè)加上引號。
有什么BI工具推薦?
Quick BI。
有什么數(shù)據(jù)查詢IDE工具推薦?
DataGrip、DBEaver。
云數(shù)據(jù)庫ClickHouse支持向量檢索嗎?
云數(shù)據(jù)庫ClickHouse支持向量檢索。更多詳情,參見以下文檔:
如何查看每張表所占的磁盤空間?
您可以通過如下代碼查看每張表所占的磁盤空間。
SELECT table, formatReadableSize(sum(bytes)) as size, min(min_date) as min_date, max(max_date) as max_date FROM system.parts WHERE active GROUP BY table; 如何查看冷數(shù)據(jù)大小?
示例代碼如下。
SELECT * FROM system.disks;如何查詢哪些數(shù)據(jù)在冷存上?
示例代碼如下。
SELECT * FROM system.parts WHERE disk_name = 'cold_disk';如何移動分區(qū)數(shù)據(jù)到冷存?
示例代碼如下。
ALTER TABLE table_name MOVE PARTITION partition_expr TO DISK 'cold_disk';為什么監(jiān)控中存在數(shù)據(jù)中斷情況?
常見原因如下。
查詢觸發(fā)OOM。
修改配置觸發(fā)重啟。
升降配后的實例重啟。
20.8后的版本是否支持平滑升級,不需要遷移數(shù)據(jù)?
ClickHouse的集群是否支持平滑升級,主要取決于集群的創(chuàng)建時間。對于2021年12月01日之后購買的集群,支持原地平滑升級內(nèi)核大版本,無需遷移數(shù)據(jù)。而對于2021年12月01日之前購買的集群,則需要通過數(shù)據(jù)遷移的方式進(jìn)行內(nèi)核大版本升級。如何升級版本,請參見升級內(nèi)核大版本。
常用系統(tǒng)表有哪些?
常用系統(tǒng)表及作用如下。
名稱 | 作用 |
system.processes | 查詢正在執(zhí)行的SQL。 |
system.query_log | 查詢歷史執(zhí)行過的SQL。 |
system.merges | 查詢集群上的merge信息。 |
system.mutations | 查詢集群上的mutation信息。 |
如何修改系統(tǒng)級別的參數(shù)?是否要重啟,有什么影響?
系統(tǒng)級別的參數(shù)對應(yīng)config.xml內(nèi)的部分配置項,具體修改步驟如下。
在集群列表頁面,選擇社區(qū)版實例列表,單擊目標(biāo)集群ID。
單擊左側(cè)導(dǎo)航欄的參數(shù)配置。
在參數(shù)配置頁面,單擊max_concurrent_queries參數(shù)的運(yùn)行參數(shù)值后面的編輯按鈕。
在懸浮框中填寫目標(biāo)值,單擊確定。
單擊提交參數(shù)。
單擊確定。
單擊確定后,自動重啟clickhouse-server,重啟會造成約1min閃斷。
如何修改用戶級別的參數(shù)?
用戶級別的參數(shù)對應(yīng)users.xml內(nèi)的部分配置項,你需要執(zhí)行如下示例語句。
SET global ON cluster default ${key}=${value};無特殊說明的參數(shù)執(zhí)行成功后即可生效。
如何修改Quota?
您可以在執(zhí)行語句的settings里增加,示例代碼如下。
settings max_memory_usage = XXX;如何解決目標(biāo)集群與數(shù)據(jù)源網(wǎng)絡(luò)互通問題?
如果目標(biāo)集群與數(shù)據(jù)源使用相同的VPC并位于同一地域。您需檢查二者是否將IP地址添加到了對方的白名單中。如果沒有,請?zhí)砑影酌麊巍?/p>
ClickHouse中如何添加白名單,請參見設(shè)置白名單。
其他數(shù)據(jù)源如何添加白名單,請參見自身產(chǎn)品文檔。
如果目標(biāo)集群與數(shù)據(jù)源不屬于上述情況,選擇合適的網(wǎng)絡(luò)解決方案,解決網(wǎng)絡(luò)問題后再將彼此IP地址添加到對方的白名單中。
場景 | 解決方案 |
云上云下互通 | |
跨地域跨賬號VPC互通 | |
同地域不同VPC互通 | |
跨地域跨賬號VPC互通 |
ClickHouse社區(qū)版集群支持遷移至企業(yè)版集群嗎?
ClickHouse社區(qū)版集群支持遷移至企業(yè)版集群。
企業(yè)版集群與社區(qū)版集群相互遷移數(shù)據(jù)的主要方式有兩種,通過remote函數(shù)和通過文件導(dǎo)出導(dǎo)入方式。具體操作,請參見將自建ClickHouse數(shù)據(jù)遷移到云ClickHouse中。
相同的SQL,在原有實例中未報錯,但在企業(yè)版的24.5或更新的版本實例中,卻發(fā)生錯誤,應(yīng)該如何處理?
新建的企業(yè)版24.5及以后的版本實例,其查詢引擎默認(rèn)使用新analyzer。新analyzer具有更好的查詢性能,但可能與部分舊版SQL不兼容,從而導(dǎo)致解析錯誤。如遇該錯誤,您可執(zhí)行以下語句,將新analyzer回退至舊analyzer。更多新analyzer詳情,請參見進(jìn)一步了解全新analyzer。
SET allow_experimental_analyzer = 0;如何暫停云數(shù)據(jù)庫ClickHouse集群?
ClickHouse社區(qū)版集群暫不支持暫停功能,企業(yè)版集群支持此功能。如果您需要暫停企業(yè)版集群,您可前往企業(yè)版集群列表,在集群列表頁面左上角,選中目標(biāo)地域,在集群列表找到目標(biāo)集群,單擊目標(biāo)集群操作列的 >暫停。
>暫停。