通過DaemonSet方式采集Kubernetes容器文本日志
本文中含有需要您注意的重要提示信息,忽略該信息可能對您的業(yè)務造成影響,請務必仔細閱讀。
如果需要只使用一個Logtail實例收集Kubernetes節(jié)點上所有容器的日志,可以使用DaemonSet方式在Kubernetes集群上部署Logtail。本文介紹DaemonSet方式采集容器文本日志的工作原理、使用限制、前提條件、操作步驟等信息。
工作原理

DaemonSet模式
在DaemonSet模式中,Kubernetes集群確保每個節(jié)點(Node)只運行一個Logtail容器,用于采集當前節(jié)點內所有容器(Containers)的日志。
當新節(jié)點加入集群時,Kubernetes集群會自動在新節(jié)點上創(chuàng)建Logtail容器;當節(jié)點退出集群時,Kubernetes集群會自動銷毀當前節(jié)點上的Logtail容器。通過DaemonSet的自動擴縮容機制以及標識型機器組,無需您手動管理Logtail實例。
容器發(fā)現(xiàn)
Logtail容器采集其他容器的日志,必須發(fā)現(xiàn)和確定哪些容器正在運行,這個過程稱為容器發(fā)現(xiàn)。在容器發(fā)現(xiàn)階段,Logtail容器不與Kubernetes集群的kube-apiserver進行通信,而是直接和節(jié)點上的容器運行時守護進程(Container Runtime Daemon)進行通信,從而獲取當前節(jié)點上的所有容器信息,避免容器發(fā)現(xiàn)對集群kube-apiserver產(chǎn)生壓力。
Logtail支持通過Namespace名稱、Pod名稱、Pod標簽、容器環(huán)境變量等條件指定或排除采集相應容器的日志。
容器文件路徑映射
在Kubernetes集群中,因為Pod之間資源隔離,所以Logtail容器無法直接訪問其他Pod中的容器的文件。但是,容器內的文件系統(tǒng)都是由宿主機的文件系統(tǒng)掛載形成,通過將宿主機根目錄所在的文件系統(tǒng)掛載到Logtail容器,就可以訪問宿主機上的任意文件,從而間接采集業(yè)務容器文件系統(tǒng)的文件。容器內文件路徑與宿主機文件路徑之間的關系被稱為文件路徑映射。
日志文件在當前容器內的路徑是/log/app.log,假設映射后的宿主機路徑是/var/lib/docker/containers/<container-id>/log/app.log。Logtail默認將宿主機根目錄所在的文件系統(tǒng)掛載到自身的/logtail_host目錄下,因此Logtail實際采集的文件路徑為/logtail_host/var/lib/docker/containers/<container-id>/log/app.log。
使用限制
容器運行時:Logtail只支持Docker和Containerd兩種容器引擎。對于Docker只支持overlay、overlay2這兩種存儲驅動,其他存儲驅動需將日志所在目錄通過數(shù)據(jù)卷掛載為臨時目錄。
存儲卷掛載方式:如果NAS以PVC的方式掛載到數(shù)據(jù)目錄,不支持使用DaemonSet方式部署Logtail,建議使用Sidecar方式或Deployment方式部署Logtail并完成日志采集。具體操作,請參見通過Sidecar方式采集Kubernetes容器文本日志和通過業(yè)務容器和Logtail容器共享PVC實現(xiàn)日志采集。
日志文件路徑:
容器內文件路徑暫不支持存在軟鏈接,請按實際路徑配置采集目錄。
如果業(yè)務容器的數(shù)據(jù)目錄通過數(shù)據(jù)卷(Volume)掛載,則填寫的文件路徑不能短于掛載點路徑。例如
/var/log/service目錄是數(shù)據(jù)卷掛載的路徑,則設置采集目錄為/var/log將無法采集該目錄下的日志,因為采集目錄比掛載路徑短。必須設置采集目錄為/var/log/service或更深的目錄。
日志文件采集停止:
docker:當容器被停止時,Logtail會立刻釋放容器文件句柄,容器可正常退出。如果在容器停止前,出現(xiàn)因網(wǎng)絡延遲、資源占用多等原因導致的采集延時,可能會丟失容器停止前的部分日志。
containerd:當容器被停止時,Logtail會持續(xù)持有容器內文件的句柄(即保持對日志文件的打開狀態(tài)),直至所有日志文件內容發(fā)送完畢。因此,當出現(xiàn)網(wǎng)絡延遲、資源占用多等原因導致的采集延時時,可能會導致業(yè)務容器不能及時銷毀。
前提條件
已安裝Logtail組件。具體操作,請參見安裝Logtail組件(阿里云Kubernetes集群)。
安裝Logtail的主機需要在出口方向開放80(HTTP)端口和443(HTTPS)端口。ECS實例的端口由安全組規(guī)則控制,添加安全組規(guī)則的步驟請參見添加安全組規(guī)則。
目標容器持續(xù)新增日志。Logtail只采集增量日志。如果下發(fā)logtail采集配置后,日志文件無更新,則Logtail不會采集該文件中的日志。更多信息,請參見讀取日志。
對于不同容器引擎,必須確認對應的UNIX域套接字存在,并確保Logtail有相應UNIX域套接字的訪問權限。
Docker:
/run/docker.sock。Containerd:
/run/containerd/containerd.sock。
創(chuàng)建Logtail采集配置
通過CRD方式創(chuàng)建的配置,在控制臺上對其修改不會同步到CRD中。因此,如需修改由CRD創(chuàng)建的配置內容,只能修改CRD資源,不要直接在控制臺操作,避免iLogtail采集配置不一致。
日志服務控制臺
登錄日志服務控制臺。
單擊控制臺右側的快速接入數(shù)據(jù),在接入數(shù)據(jù)區(qū)域單擊Kubernetes-文件卡片。

選擇目標Project和Logstore,單擊下一步。選擇您在安裝Logtail組件時所使用的Project。Logstore為您自定義創(chuàng)建的Logstore。
在機器組配置頁面。
根據(jù)實際場景,單擊以下頁簽:
- 重要
不同頁簽的后續(xù)配置步驟不同,請根據(jù)實際需求正確選擇。
確認目標機器組已在應用機器組列表中,然后單擊下一步。在ACK中安裝Logtail組件后,日志服務自動創(chuàng)建名為
k8s-group-${your_k8s_cluster_id}的機器組,您可以直接使用該機器組。重要如果需要新建機器組,請單擊創(chuàng)建機器組,按照右側面板進行創(chuàng)建。更多信息,請參見通過控制臺配置。
如果機器組心跳為FAIL,您可單擊自動重試。如果還未解決,請參見Logtail機器組無心跳進行排查。
創(chuàng)建Logtail采集配置,單擊下一步創(chuàng)建Logtail采集配置,日志服務開始采集日志。
說明Logtail采集配置生效時間最長需要3分鐘,請耐心等待。
配置項
說明
配置名稱
Logtail配置名稱,在其所屬Project內必須唯一。創(chuàng)建Logtail配置成功后,無法修改其名稱。
日志主題類型
選擇日志主題(Topic)的生成方式。更多信息,請參見日志主題。
機器組Topic:設置為機器組的Topic屬性,用于明確區(qū)分不同機器組產(chǎn)生的日志。
文件路徑提取:設置為文件路徑正則,則需要設置自定義正則,用正則表達式從路徑里提取一部分內容作為Topic。用于區(qū)分不同源產(chǎn)生的日志。
自定義:自定義日志主題。
高級參數(shù)
其它可選的與配置全局相關的高級功能參數(shù),請參見創(chuàng)建Logtail流水線配置。
配置項
說明
日志樣例
待采集日志的樣例,請務必使用實際場景的日志。日志樣例可協(xié)助您配置日志處理相關參數(shù),降低配置難度。支持添加多條樣例,總長度不超過1500個字符。
[2023-10-01T10:30:01,000] [INFO] java.lang.Exception: exception happened at TestPrintStackTrace.f(TestPrintStackTrace.java:3) at TestPrintStackTrace.g(TestPrintStackTrace.java:7) at TestPrintStackTrace.main(TestPrintStackTrace.java:16)多行模式
多行日志的類型:多行日志是指每條日志分布在連續(xù)的多行中,需要從日志內容中區(qū)分出每一條日志。
自定義:通過行首正則表達式區(qū)分每一條日志。
多行JSON:每個JSON對象被展開為多行,例如:
{ "name": "John Doe", "age": 30, "address": { "city": "New York", "country": "USA" } }
切分失敗處理方式:
Exception in thread "main" java.lang.NullPointerException at com.example.MyClass.methodA(MyClass.java:12) at com.example.MyClass.methodB(MyClass.java:34) at com.example.MyClass.main(MyClass.java:?0)對于以上日志內容,如果日志服務切分失敗:
丟棄:直接丟棄這段日志。
保留單行:將每行日志文本單獨保留為一條日志,保留為一共四條日志。
處理模式
處理插件組合,包括原生插件和拓展插件。有關處理插件的更多信息,請參見處理插件概述。
重要處理插件的使用限制,請以控制臺頁面的提示為準。
2.0版本的Logtail:
原生處理插件可任意組合。
原生處理插件和擴展處理插件可同時使用,但擴展處理插件只能出現(xiàn)在所有的原生處理插件之后。
低于2.0版本的Logtail:
不支持同時添加原生插件和擴展插件。
原生插件僅可用于采集文本日志。使用原生插件時,須符合如下要求:
第一個處理插件必須為正則解析插件、分隔符模式解析插件、JSON解析插件、Nginx模式解析插件、Apache模式解析插件或IIS模式解析插件。
從第二個處理插件到最后一個處理插件,最多包括1個時間解析處理插件,1個過濾處理插件和多個脫敏處理插件。
對于解析失敗時保留原始字段和解析成功時保留原始字段參數(shù),只有以下組合有效,其余組合無效。
只上傳解析成功的日志:

解析成功時上傳解析后的日志,解析失敗時上傳原始日志:
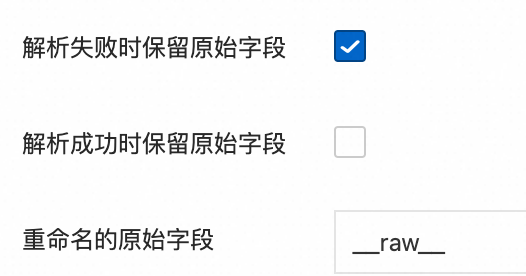
解析成功時不僅上傳解析后的日志,并且追加原始日志字段,解析失敗時上傳原始日志。
例如,原始日志
"content": "{"request_method":"GET", "request_time":"200"}"解析成功,追加原始字段是在解析后日志的基礎上再增加一個字段,字段名為重命名的原始字段(如果不填則默認為原始字段名),字段值為原始日志{"request_method":"GET", "request_time":"200"}。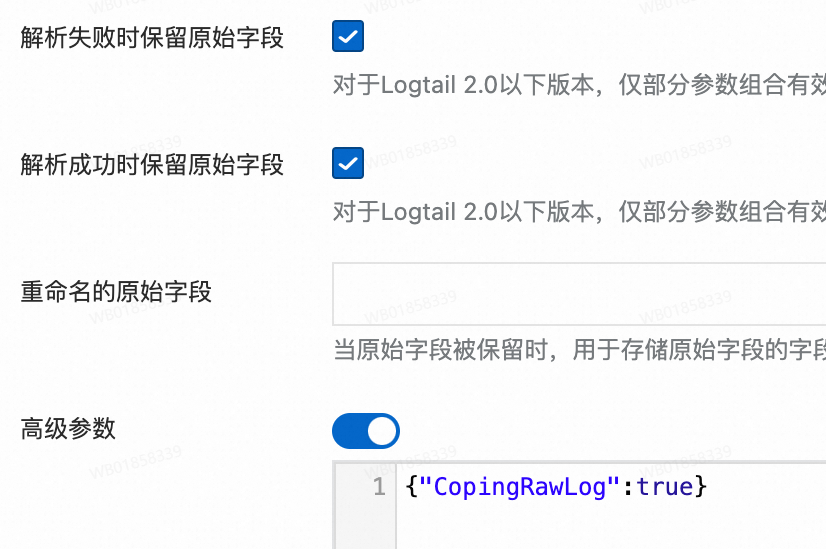
創(chuàng)建索引和預覽數(shù)據(jù),然后單擊下一步。日志服務默認開啟全文索引。您也可以根據(jù)采集到的日志,手動創(chuàng)建字段索引,或者單擊自動生成索引,日志服務將自動生成字段索引。更多信息,請參見創(chuàng)建索引。
重要如果需要查詢日志中的所有字段,建議使用全文索引。如果只需查詢部分字段、建議使用字段索引,減少索引流量。如果需要對字段進行分析(SELECT語句),必須創(chuàng)建字段索引。
單擊查詢日志,系統(tǒng)將跳轉至Logstore查詢分析頁面。
您需要等待1分鐘左右,待索引生效后,才能在原始日志頁簽中,查看已采集到的日志。更多信息,請參見查詢和分析日志。
(推薦)CRD-AliyunPipelineConfig
創(chuàng)建Logtail采集配置
使用AliyunPipelineConfig,需要日志組件版本最低為0.5.1。
您只需要創(chuàng)建AliyunPipelineConfig CR即可創(chuàng)建iLogtail采集配置,創(chuàng)建完成后自動生效。對于通過CR創(chuàng)建的iLogtail采集配置,其修改只能通過更新相應的CR來實現(xiàn)。
執(zhí)行如下命令創(chuàng)建一個YAML文件。
cube.yaml為文件名,請根據(jù)實際情況替換。vim cube.yaml在YAML文件輸入如下腳本,并根據(jù)實際情況設置其中的參數(shù)。
重要請確保
configName字段值在安裝Logtail組件的Project中唯一。每個iLogtail采集配置必須單獨設置一個對應的CR,如果多個CR關聯(lián)同一個Logtail配置,后配置的CR將不會生效。
AliyunPipelineConfig的參數(shù),請參見【推薦】使用AliyunPipelineConfig管理采集配置。本文的iLogtail采集配置樣例包含基礎的文本日志采集功能,參數(shù)說明參見CreateLogtailPipelineConfig - 創(chuàng)建Logtail流水線配置。請確保config.flushers.Logstore參數(shù)配置的Logstore已存在,可以通過配置spec.logstore參數(shù)自動創(chuàng)建Logstore。
采集指定容器內的單行文本日志
創(chuàng)建名為
example-k8s-file的iLogtail采集配置,對于集群內名稱包含app的所有容器,以單行文本模式采集/data/logs/app_1路徑下的test.LOG文件,直接發(fā)送到名稱為
k8s-file的Logstore,該Logstore屬于名稱為k8s-log-test的Project。apiVersion: telemetry.alibabacloud.com/v1alpha1 # 創(chuàng)建一個 ClusterAliyunPipelineConfig kind: ClusterAliyunPipelineConfig metadata: # 設置資源名,在當前Kubernetes集群內唯一。該名稱也是創(chuàng)建出的iLogtail采集配置名 name: example-k8s-file spec: # 指定目標project project: name: k8s-log-test # 創(chuàng)建用于存儲日志的 Logstore logstores: - name: k8s-file # 定義iLogtail采集配置 config: # 定義輸入插件 inputs: # 使用input_file插件采集容器內文本日志 - Type: input_file # 容器內的文件路徑 FilePaths: - /data/logs/app_1/**/test.LOG # 啟用容器發(fā)現(xiàn)功能。 EnableContainerDiscovery: true # 添加容器信息過濾條件,多個選項之間為“且”的關系。 ContainerFilters: # 指定待采集容器所在 Pod 所屬的命名空間,支持正則匹配。 K8sNamespaceRegex: default # 指定待采集容器的名稱,支持正則匹配。 K8sContainerRegex: ^(.*app.*)$ # 定義輸出插件 flushers: # 使用flusher_sls插件輸出到指定Logstore。 - Type: flusher_sls # 需要確保該 Logstore 存在 Logstore: k8s-file # 需要確保 endpoint 正確 Endpoint: cn-hangzhou.log.aliyuncs.com Region: cn-hangzhou TelemetryType: logs采集所有容器內的多行文本日志并正則解析
創(chuàng)建名為
example-k8s-file的iLogtail采集配置,以多行文本模式采集集群內所有容器內的/data/logs/app_1路徑下的test.LOG文件,對采集到的數(shù)據(jù)進行JSON解析,直接發(fā)送到名稱為k8s-file的Logstore,該Logstore屬于名稱為k8s-log-test的Project。下面樣例中的日志原文通過input_file插件讀取后格式為
{"content": "2024-06-19 16:35:00 INFO test log\nline-1\nline-2\nend"},會被正則解析插件解析為{"time": "2024-06-19 16:35:00", "level": "INFO", "msg": "test log\nline-1\nline-2\nend"}apiVersion: telemetry.alibabacloud.com/v1alpha1 # 創(chuàng)建一個 ClusterAliyunPipelineConfig kind: ClusterAliyunPipelineConfig metadata: # 設置資源名,在當前Kubernetes集群內唯一。該名稱也是創(chuàng)建出的iLogtail采集配置名 name: example-k8s-file spec: # 指定目標project project: name: k8s-log-test # 創(chuàng)建用于存儲日志的 Logstore logstores: - name: k8s-file # 定義iLogtail采集配置 config: # 日志樣例(可不填寫) sample: | 2024-06-19 16:35:00 INFO test log line-1 line-2 end # 定義輸入插件 inputs: # 使用input_file插件采集容器內多行文本日志 - Type: input_file # 容器內的文件路徑 FilePaths: - /data/logs/app_1/**/test.LOG # 啟用容器發(fā)現(xiàn)功能。 EnableContainerDiscovery: true # 開啟多行能力 Multiline: # 選擇自定義行首正則表達式模式 Mode: custom # 配置行首正則表達式 StartPattern: \d+-\d+-\d+.* # 定義處理插件 processors: # 使用正則解析插件解析日志 - Type: processor_parse_regex_native # 源字段名 SourceKey: content # 解析用的正則表達式,用捕獲組"()"捕獲待提取的字段 Regex: (\d+-\d+-\d+\s*\d+:\d+:\d+)\s*(\S+)\s*(.*) # 提取的字段列表 Keys: ["time", "level", "msg"] # 定義輸出插件 flushers: # 使用flusher_sls插件輸出到指定Logstore。 - Type: flusher_sls # 需要確保該 Logstore 存在 Logstore: k8s-file # 需要確保 endpoint 正確 Endpoint: cn-hangzhou.log.aliyuncs.com Region: cn-hangzhou TelemetryType: logs執(zhí)行如下命令使iLogtail采集配置生效。iLogtail采集配置生效后,Logtail開始采集各個容器上的文本日志,并發(fā)送到日志服務中。
cube.yaml為文件名,請根據(jù)實際情況替換。kubectl apply -f cube.yaml重要采集到日志后,您需要先創(chuàng)建索引,才能在Logstore中查詢和分析日志。具體操作,請參見創(chuàng)建索引。
CRD-AliyunLogConfig
您只需要創(chuàng)建AliyunLogConfig CR即可創(chuàng)建iLogtail采集配置,創(chuàng)建完成后自動生效。對于通過CR創(chuàng)建的iLogtail采集配置,其修改只能通過更新相應的CR來實現(xiàn)。
執(zhí)行如下命令創(chuàng)建一個YAML文件。
cube.yaml為文件名,請根據(jù)實際情況替換。vim cube.yaml在YAML文件輸入如下腳本,并根據(jù)實際情況設置其中的參數(shù)。
重要請確保
configName字段值在安裝Logtail組件的Project中唯一。如果多個CR關聯(lián)同一個iLogtail采集配置,則刪除或修改任意一個CR均會影響到該iLogtail采集配置,導致其他關聯(lián)該iLogtail采集配置的CR狀態(tài)與日志服務中iLogtail采集配置的狀態(tài)不一致。
CR字段的格式請參見使用AliyunLogConfig管理采集配置。本文的iLogtail采集配置樣例包含基礎的文本日志采集功能,具體參數(shù)參見CreateConfig - 創(chuàng)建Logtail采集配置。
采集指定容器內的單行文本日志
“創(chuàng)建名為
example-k8s-file的iLogtail采集配置,以單行文本模式采集集群內所有名稱開頭為app的Pod的容器內的/data/logs/app_1路徑下的test.LOG文件,直接發(fā)送到名稱為k8s-file的Logstore,該Logstore屬于名稱為k8s-log-test的Project。”apiVersion: log.alibabacloud.com/v1alpha1 kind: AliyunLogConfig metadata: # 設置資源名,在當前Kubernetes集群內唯一。 name: example-k8s-file namespace: kube-system spec: # 設置目標project名稱(可不填寫,默認為k8s-log-<your_cluster_id>) project: k8s-log-test # 設置Logstore名稱。如果您所指定的Logstore不存在,日志服務會自動創(chuàng)建。 logstore: k8s-file # 設置iLogtail采集配置。 logtailConfig: # 設置采集的數(shù)據(jù)源類型。采集文本日志時,需設置為file。 inputType: file # 設置iLogtail采集配置的名稱。 configName: example-k8s-file inputDetail: # 指定通過極簡模式采集文本日志。 logType: common_reg_log # 設置日志文件所在路徑。 logPath: /data/logs/app_1 # 設置日志文件的名稱。支持通配符星號(*)和半角問號(?),例如log_*.log。 filePattern: test.LOG # 采集容器的文本日志時,需設置dockerFile為true。 dockerFile: true #設置容器過濾條件。 advanced: k8s: K8sPodRegex: '^(app.*)$'執(zhí)行如下命令使其iLogtail采集配置生效。iLogtail采集配置生效后,Logtail開始采集各個容器上的文本日志,并發(fā)送到日志服務中。
cube.yaml為文件名,請根據(jù)實際情況替換。kubectl apply -f cube.yaml重要采集到日志后,您需要先創(chuàng)建索引,才能在Logstore中查詢和分析日志。具體操作,請參見創(chuàng)建索引。
查看Logtail采集配置
控制臺
登錄日志服務控制臺。
在Project列表區(qū)域,單擊目標Project。

在頁簽中,單擊目標日志庫前面的>,依次選擇。
單擊目標Logtail采集配置,查看Logtail采集配置詳情。
(推薦)CRD-AliyunPipelineConfig
查看由AliyunPipelineConfig創(chuàng)建的Logtail采集配置
執(zhí)行kubectl get clusteraliyunpipelineconfigs命令查看iLogtail采集配置。
查看由AliyunPipelineConfig創(chuàng)建的Logtail采集配置的詳細信息
您可以執(zhí)行以下命令進行查看。其中,<config_name>為AliyunPipelineConfig的名稱,請根據(jù)實際情況替換。
kubectl get clusteraliyunpipelineconfigs <config_name> -o yaml以采集指定容器內的單行文本日志的CR為例,返回結果參考如下所示,可以根據(jù)status查看iLogtail采集配置的應用情況:
apiVersion: telemetry.alibabacloud.com/v1alpha1
kind: ClusterAliyunPipelineConfig
metadata:
finalizers:
- finalizer.pipeline.alibabacloud.com
name: example-k8s-file
# 預期的配置
spec:
config:
flushers:
- Endpoint: cn-hangzhou.log.aliyuncs.com
Logstore: k8s-file
Region: cn-hangzhou
TelemetryType: logs
Type: flusher_sls
inputs:
- EnableContainerDiscovery: true
FilePaths:
- /data/logs/app_1/**/test.LOG
Type: input_file
logstores:
- encryptConf: {}
name: k8s-file
project:
name: k8s-log-clusterid
# CR的應用狀態(tài)
status:
# CR 是否應用成功
success: true
# CR 當前的狀態(tài)信息
message: success
# 當前 status 的更新時間
lastUpdateTime: '2024-06-19T09:21:34.215702958Z'
# 上次成功應用的配置信息,該配置信息為填充默認值后實際生效的配置
lastAppliedConfig:
# 上次成功應用的時間
appliedTime: '2024-06-19T09:21:34.215702958Z'
# 上次成功應用的配置詳情
config:
configTags:
sls.crd.cluster: e2e-cluster-id
sls.crd.kind: ClusterAliyunPipelineConfig
sls.logtail.channel: CRD
flushers:
- Endpoint: cn-hangzhou.log.aliyuncs.com
Logstore: k8s-file
Region: cn-hangzhou
TelemetryType: logs
Type: flusher_sls
inputs:
- EnableContainerDiscovery: true
FilePaths:
- /data/logs/app_1/**/test.LOG
Type: input_file
name: example-k8s-file
logstores:
- appendMeta: true
autoSplit: true
encryptConf: {}
maxSplitShard: 64
name: k8s-file
shardCount: 2
ttl: 30
machineGroups:
- name: k8s-group-clusterid
project:
description: 'k8s log project, created by alibaba cloud log controller'
endpoint: cn-hangzhou.log.aliyuncs.com
name: k8s-log-clusteridCRD-AliyunLogConfig
查看由AliyunLogConfig創(chuàng)建的iLogtail采集配置
您可以執(zhí)行kubectl get aliyunlogconfigs命令進行查看,返回結果如下圖所示。

查看由AliyunLogConfig創(chuàng)建的iLogtail采集配置的詳細信息
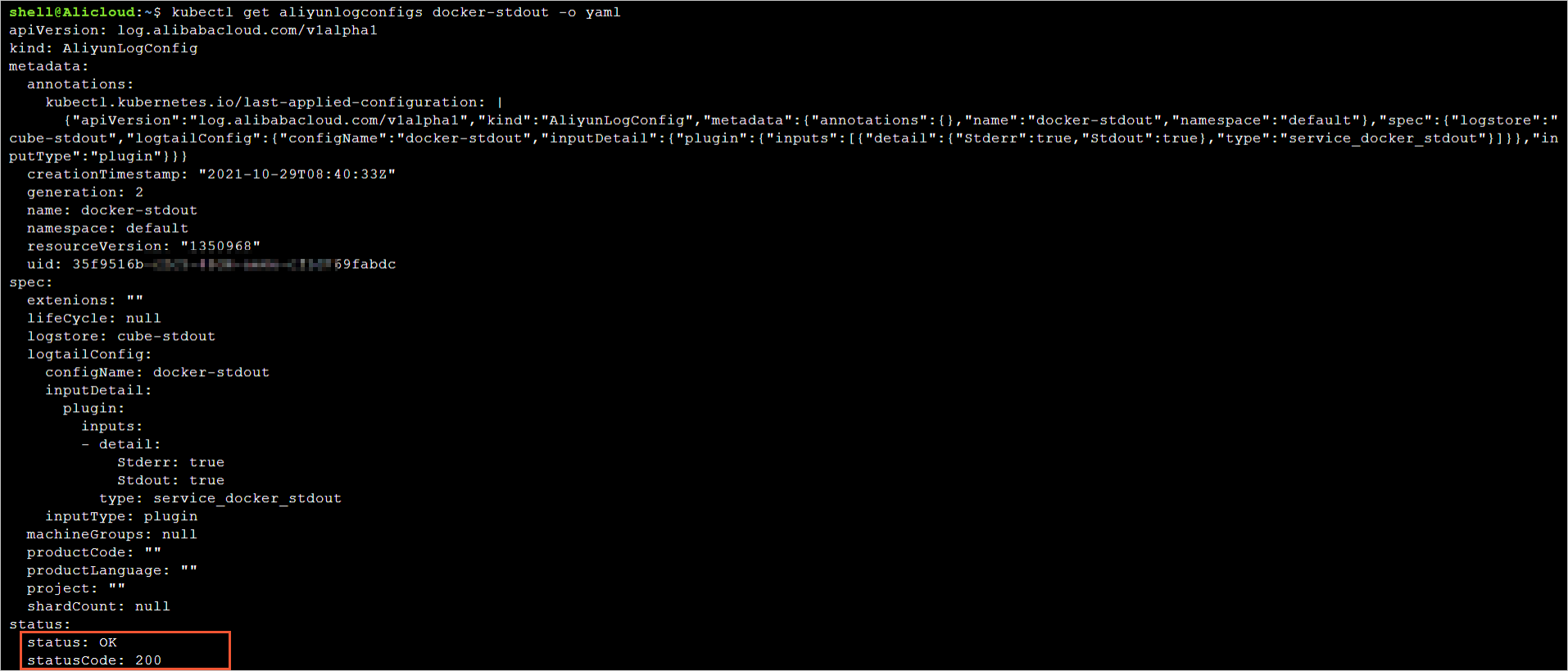
您可以執(zhí)行kubectl get aliyunlogconfigs <config_name> -o yaml命令進行查看。其中,<config_name>為AliyunLogConfig的名稱,請根據(jù)實際情況替換。 返回結果如下圖所示。
執(zhí)行結果中的status字段和statusCode字段表示iLogtail采集配置的狀態(tài)。
如果
statusCode字段的值為200,表示應用iLogtail采集配置成功。如果
statusCode字段的值為非200,表示應用iLogtail采集配置失敗。
查詢分析已采集的日志
在Project列表中,單擊目標Project,進入對應的Project詳情頁面。

在對應的日志庫右側的
 圖標,選擇查詢分析,查看Kubernetes集群輸出的日志。
圖標,選擇查詢分析,查看Kubernetes集群輸出的日志。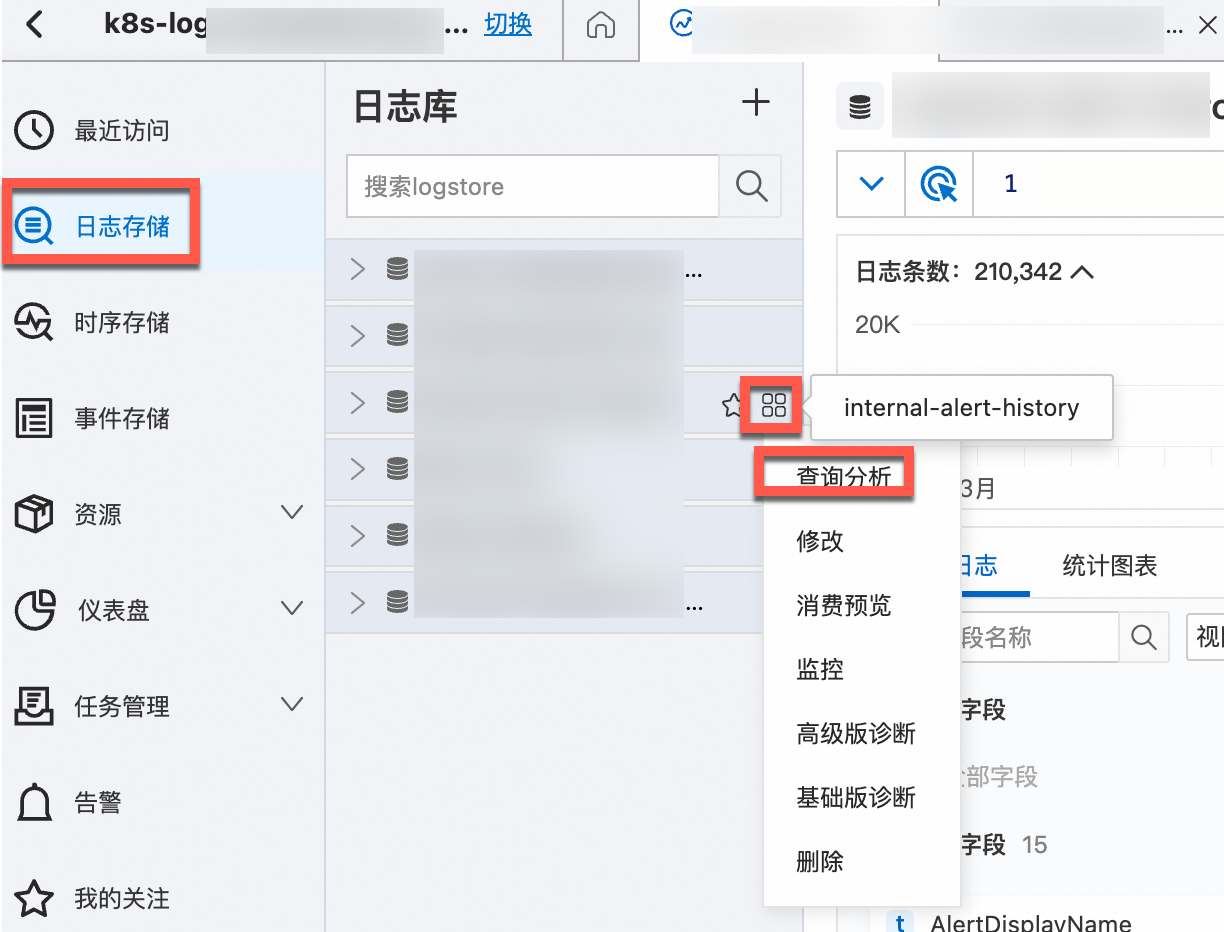
容器日志文本默認字段
每條容器文本日志默認包含的字段如下表所示。
字段名稱 | 說明 |
__tag__:__hostname__ | 容器宿主機的名稱。 |
__tag__:__path__ | 容器內日志文件的路徑。 |
__tag__:_container_ip_ | 容器的IP地址。 |
__tag__:_image_name_ | 容器使用的鏡像名稱。 |
__tag__:_pod_name_ | Pod的名稱。 |
__tag__:_namespace_ | Pod所屬的命名空間。 |
__tag__:_pod_uid_ | Pod的唯一標識符(UID)。 |
相關文檔
當您使用Logtail采集容器(標準容器、Kubernetes)日志遇到異常情況時,您可以參見如何排查容器日志采集異常和通過DaemonSet方式采集Kubernetes容器標準輸出進行排查。
采集Kubernetes容器標準輸出的步驟,請參見通過DaemonSet方式采集Kubernetes容器標準輸出。