采集主機(jī)文本日志
本文介紹如何使用Logtail采集主機(jī)文本日志。
背景信息
本文介紹Logtail采集配置的詳細(xì)配置步驟,對于常見類型的日志采集,請參見最佳實踐:
前提條件
已創(chuàng)建Logtail機(jī)器組并添加相應(yīng)服務(wù)器,創(chuàng)建機(jī)器組的步驟,請參見創(chuàng)建用戶自定義標(biāo)識機(jī)器組(推薦)或創(chuàng)建IP地址機(jī)器組。
安裝Logtail的主機(jī)需要在出口方向開放80(HTTP)端口和443(HTTPS)端口。ECS實例的端口由安全組規(guī)則控制,添加安全組規(guī)則的步驟請參見添加安全組規(guī)則。
服務(wù)器日志的內(nèi)容持續(xù)新增。Logtail只采集增量日志,如果下發(fā)Logtail配置后日志文件無更新,則Logtail不會采集該文件中的日志。更多信息,請參見讀取日志。
操作步驟
登錄日志服務(wù)控制臺。
在接入數(shù)據(jù)區(qū)域中,根據(jù)需要選擇包含文本日志后綴的入口。本文以采集主機(jī)中的多行文本日志為例。

在選擇日志空間頁面,按照選擇目標(biāo)Project和Logstore,單擊下一步。
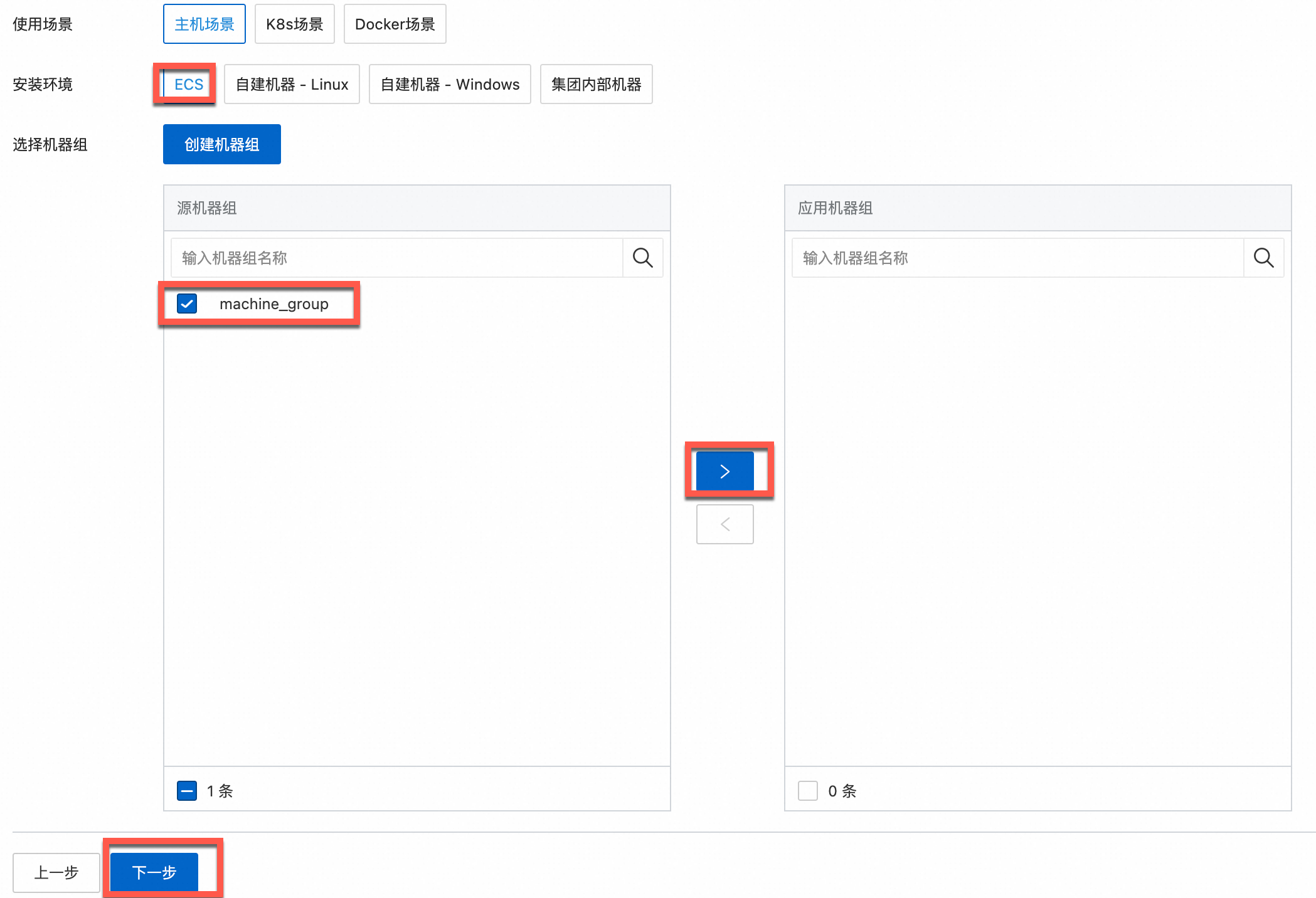
在機(jī)器組配置頁面,配置機(jī)器組。
根據(jù)實際需求,選擇使用場景和安裝環(huán)境。
重要無論是否已有機(jī)器組,都必須根據(jù)實際需求正確選擇使用場景和安裝環(huán)境,這將影響后續(xù)的頁面配置。
確認(rèn)目標(biāo)機(jī)器組已在應(yīng)用機(jī)器組區(qū)域,單擊下一步。
已有機(jī)器組
從源機(jī)器組列表選擇目標(biāo)機(jī)器組。
沒有可用機(jī)器組
單擊創(chuàng)建機(jī)器組,在創(chuàng)建機(jī)器組面板設(shè)置相關(guān)參數(shù)。機(jī)器組標(biāo)識分為IP地址和用戶自定義標(biāo)識,更多信息請參見創(chuàng)建用戶自定義標(biāo)識機(jī)器組(推薦)或創(chuàng)建IP地址機(jī)器組。
重要創(chuàng)建機(jī)器組后立刻應(yīng)用,可能因為連接未生效,導(dǎo)致心跳為FAIL,您可單擊重試。如果還未解決,請參見Logtail機(jī)器組無心跳進(jìn)行排查。
創(chuàng)建Logtail配置,單擊下一步,創(chuàng)建Logtail配置。Logtail配置生效時間最長需要3分鐘,請耐心等待。
配置項
說明
配置名稱
Logtail配置名稱,在其所屬Project內(nèi)必須唯一。創(chuàng)建Logtail配置成功后,無法修改其名稱。
日志主題類型
選擇日志主題(Topic)的生成方式。更多信息,請參見日志主題。
機(jī)器組Topic:設(shè)置為機(jī)器組的Topic屬性,用于明確區(qū)分不同機(jī)器組產(chǎn)生的日志。
文件路徑提取:設(shè)置為文件路徑正則,則需要設(shè)置自定義正則,用正則表達(dá)式從路徑里提取一部分內(nèi)容作為Topic。用于區(qū)分不同源產(chǎn)生的日志。
自定義:自定義日志主題。
高級參數(shù)
其它可選的與配置全局相關(guān)的高級功能參數(shù),請參見創(chuàng)建Logtail流水線配置。
配置項
說明
文件路徑
根據(jù)日志在主機(jī)(例如ECS)上的位置,設(shè)置日志目錄和文件名稱。
如果目標(biāo)主機(jī)是Linux系統(tǒng),則日志路徑必須以正斜線(/)開頭,例如
/apsara/nuwa/**/app.Log。如果目標(biāo)主機(jī)是Windows系統(tǒng),則日志路徑必須以盤符開頭,例如
C:\Program Files\Intel\**\*.Log。
目錄名和文件名均支持完整模式和通配符模式,文件名規(guī)則請參見Wildcard matching。其中,日志路徑通配符只支持星號(*)和半角問號(?)。
日志文件查找模式為多層目錄匹配,即符合條件的指定目錄(包含所有層級的目錄)下所有符合條件的文件都會被查找到。例如:
/apsara/nuwa/**/*.log表示/apsara/nuwa目錄(包含該目錄的遞歸子目錄)中后綴名為.log的文件。/var/logs/app_*/**/*.log表示/var/logs目錄下所有符合app_*格式的目錄(包含該目錄的遞歸子目錄)中后綴名為.log的文件。/var/log/nginx/**/access*表示/var/log/nginx目錄(包含該目錄的遞歸子目錄)中以access開頭的文件。
最大目錄監(jiān)控深度
設(shè)置日志目錄被監(jiān)控的最大深度,即文件路徑中通配符
**匹配的最大目錄深度。0代表只監(jiān)控本層目錄。文件編碼
選擇日志文件的編碼格式。
首次采集大小
配置首次生效時,匹配文件的起始采集位置距離文件結(jié)尾的大小。首次采集大小設(shè)定值為1024 KB。
首次采集時,如果文件小于1024 KB,則從文件內(nèi)容起始位置開始采集。
首次采集時,如果文件大于1024 KB,則從距離文件末尾1024 KB的位置開始采集。
您可以通過此處修改首次采集大小,取值范圍為0~10485760,單位為KB。
采集黑名單
打開采集黑名單開關(guān)后,可進(jìn)行黑名單配置,即可在采集時忽略指定的目錄或文件。支持完整匹配和通配符匹配目錄和文件名。其中,通配符只支持星號(*)和半角問號(?)。
重要如果您在配置文件路徑時使用了通配符,但又需要過濾掉其中部分路徑,則需在采集黑名單中填寫對應(yīng)的完整路徑來保證黑名單配置生效。
例如您配置文件路徑為
/home/admin/app*/log/*.log,但要過濾/home/admin/app1*目錄下的所有子目錄,則需選擇目錄黑名單,配置目錄為/home/admin/app1*/**。如果配置為/home/admin/app1*,黑名單不會生效。匹配黑名單過程存在計算開銷,建議黑名單條目數(shù)控制在10條內(nèi)。
目錄路徑不能以正斜線(/)結(jié)尾,例如將設(shè)置路徑為
/home/admin/dir1/,目錄黑名單不會生效。
支持按照文件路徑黑名單、文件黑名單、目錄黑名單設(shè)置,詳細(xì)說明如下:
文件路徑黑名單
選擇文件路徑黑名單,配置路徑為
/home/admin/private*.log,則表示在采集時忽略/home/admin/目錄下所有以private開頭,以.log結(jié)尾的文件。選擇文件路徑黑名單,配置路徑為
/home/admin/private*/*_inner.log,則表示在采集時忽略/home/admin/目錄下以private開頭的目錄內(nèi),以_inner.log結(jié)尾的文件。例如/home/admin/private/app_inner.log文件被忽略,/home/admin/private/app.log文件被采集。
文件黑名單
選擇文件黑名單,配置文件名為
app_inner.log,則表示采集時忽略所有名為app_inner.log的文件。目錄黑名單
選擇目錄黑名單,配置目錄為
/home/admin/dir1,則表示在采集時忽略/home/admin/dir1目錄下的所有文件。選擇目錄黑名單,配置目錄為
/home/admin/dir*,則表示在采集時忽略/home/admin/目錄下所有以dir開頭的子目錄下的文件。選擇目錄黑名單,配置目錄為
/home/admin/*/dir,則表示在采集時忽略/home/admin/目錄下二級目錄名為dir的子目錄下的所有文件。例如/home/admin/a/dir目錄下的文件被忽略,/home/admin/a/b/dir目錄下的文件被采集。
允許文件多次采集
默認(rèn)情況下,一個日志文件只能匹配一個Logtail配置。如果文件中的日志需要被采集多份,需要打開允許文件多次采集開關(guān)。
高級參數(shù)
其它可選的與文件輸入插件相關(guān)的高級功能參數(shù),請參見創(chuàng)建Logtail流水線配置。
配置項
說明
日志樣例
待采集日志的樣例,請務(wù)必使用實際場景的日志。日志樣例可協(xié)助您配置日志處理相關(guān)參數(shù),降低配置難度。支持添加多條樣例,總長度不超過1500個字符。
[2023-10-01T10:30:01,000] [INFO] java.lang.Exception: exception happened at TestPrintStackTrace.f(TestPrintStackTrace.java:3) at TestPrintStackTrace.g(TestPrintStackTrace.java:7) at TestPrintStackTrace.main(TestPrintStackTrace.java:16)多行模式
多行日志的類型:多行日志是指每條日志分布在連續(xù)的多行中,需要從日志內(nèi)容中區(qū)分出每一條日志。
自定義:通過行首正則表達(dá)式區(qū)分每一條日志。
多行JSON:每個JSON對象被展開為多行,例如:
{ "name": "John Doe", "age": 30, "address": { "city": "New York", "country": "USA" } }
切分失敗處理方式:
Exception in thread "main" java.lang.NullPointerException at com.example.MyClass.methodA(MyClass.java:12) at com.example.MyClass.methodB(MyClass.java:34) at com.example.MyClass.main(MyClass.java:?0)對于以上日志內(nèi)容,如果日志服務(wù)切分失敗:
丟棄:直接丟棄這段日志。
保留單行:將每行日志文本單獨保留為一條日志,保留為一共四條日志。
處理模式
處理插件組合,包括原生插件和拓展插件。有關(guān)處理插件的更多信息,請參見處理插件概述。
重要處理插件的使用限制,請以控制臺頁面的提示為準(zhǔn)。
2.0版本的Logtail:
原生處理插件可任意組合。
原生處理插件和擴(kuò)展處理插件可同時使用,但擴(kuò)展處理插件只能出現(xiàn)在所有的原生處理插件之后。
低于2.0版本的Logtail:
不支持同時添加原生插件和擴(kuò)展插件。
原生插件僅可用于采集文本日志。使用原生插件時,須符合如下要求:
第一個處理插件必須為正則解析插件、分隔符模式解析插件、JSON解析插件、Nginx模式解析插件、Apache模式解析插件或IIS模式解析插件。
從第二個處理插件到最后一個處理插件,最多包括1個時間解析處理插件,1個過濾處理插件和多個脫敏處理插件。
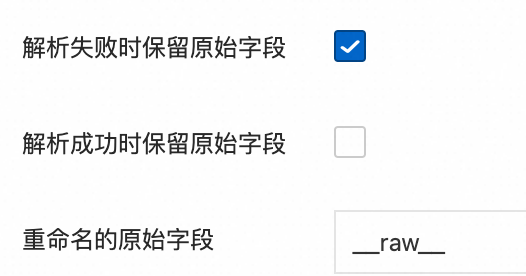
對于解析失敗時保留原始字段和解析成功時保留原始字段參數(shù),只有以下組合有效,其余組合無效。
只上傳解析成功的日志:

解析成功時上傳解析后的日志,解析失敗時上傳原始日志:
解析成功時不僅上傳解析后的日志,并且追加原始日志字段,解析失敗時上傳原始日志。
例如,原始日志
"content": "{"request_method":"GET", "request_time":"200"}"解析成功,追加原始字段是在解析后日志的基礎(chǔ)上再增加一個字段,字段名為重命名的原始字段(如果不填則默認(rèn)為原始字段名),字段值為原始日志{"request_method":"GET", "request_time":"200"}。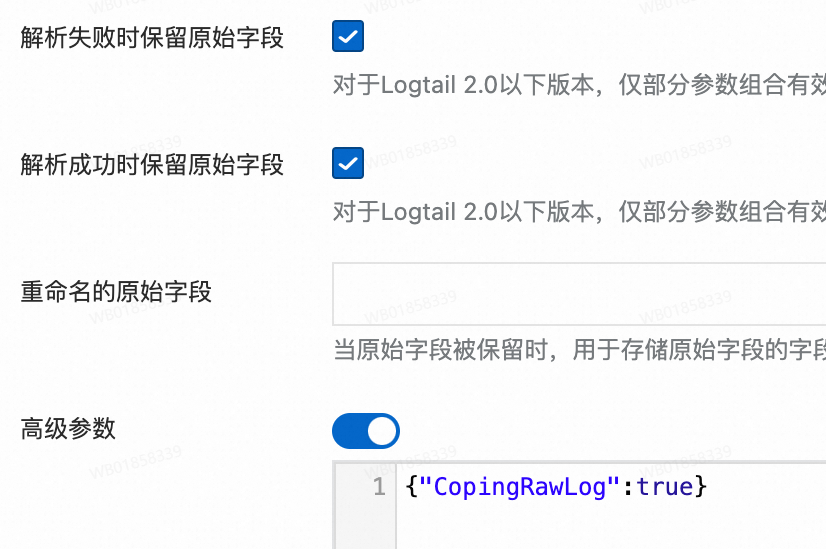
創(chuàng)建索引和預(yù)覽數(shù)據(jù),然后單擊下一步。日志服務(wù)默認(rèn)開啟全文索引。您也可以根據(jù)采集到的日志,手動創(chuàng)建字段索引,或者單擊自動生成索引,日志服務(wù)將自動生成字段索引。更多信息,請參見創(chuàng)建索引。
重要如果需要查詢?nèi)罩局械乃凶侄危ㄗh使用全文索引。如果只需查詢部分字段、建議使用字段索引,減少索引流量。如果需要對字段進(jìn)行分析(SELECT語句),必須創(chuàng)建字段索引。
單擊查詢?nèi)罩?/b>,系統(tǒng)將跳轉(zhuǎn)至Logstore查詢分析頁面。
您需要等待1分鐘左右,待索引生效后,才能在原始日志頁簽中,查看已采集到的日志。查詢和分析日志的詳細(xì)步驟,請參見查詢和分析日志。
相關(guān)文檔
使用Logtail采集日志后,如果預(yù)覽頁面為空或查詢頁面無數(shù)據(jù),請按照Logtail采集日志失敗的排查思路進(jìn)行排查。在使用Logtail采集日志時,可能遇到正則解析失敗、文件路徑不正確、流量超過Shard服務(wù)能力等錯誤。查看Logtail采集錯誤的步驟,請參見如何查看Logtail采集錯誤信息。采集數(shù)據(jù)常見的錯誤類型請參見日志服務(wù)采集數(shù)據(jù)常見的錯誤類型。
默認(rèn)情況下,一個日志文件只能匹配一個Logtail配置。如果同一份日志需要被采集多份,請參見如何實現(xiàn)文件中的日志被采集多份。
將企業(yè)內(nèi)網(wǎng)服務(wù)器日志采集到日志服務(wù),請參見采集企業(yè)內(nèi)網(wǎng)服務(wù)器日志。