Bloom是一種概率性數據結構(space-efficient probabilistic data structure),在大規模數據中,僅需消耗較低的內存來判斷一個元素是否存在。而TairBloom基于Scalable Bloom Filter實現,具有動態擴容的能力,并且可以在擴容時維持誤判率的穩定性。
TairBloom簡介
在傳統的Redis數據結構中,可以使用Hash、Set、String的Bitset等實現類似功能,但這些實現方式不是內存占用量非常大,就是無法動態伸縮和保持誤判率不變。因此,TairBloom非常適合需要高效判斷大量數據是否存在且允許一定誤判率的業務場景。業務可以直接使用TairBloom提供的Bloom Filter(布隆過濾器)接口,無需二次封裝,更無需在本地實現布隆過濾器的功能。
主要特性
內存占用低。
可動態擴容。
可自定義的誤判率(False Positive Rate)且在擴容時保持不變。
典型場景
適用于直播、音樂、電商等行業的推薦系統或爬蟲系統等,例如:
推薦系統:將用戶讀過的文章通過TairBloom記錄,并在給用戶推薦新文章前進行查詢,實現給用戶推薦感興趣,且沒讀過的文章。
爬蟲系統:在面對海量的URL時,將已經爬取過的URL進行過濾、去重操作,減少重復爬取的無效工作量。
最佳實踐
基于TairBloom打造推薦系統
將已推薦給用戶的文章ID通過TairBloom記錄,并在推薦新文章前進行查詢、判斷,輕松實現給用戶推薦感興趣,且未推薦過的文章,偽代碼如下:
void recommendedSystem(userid) {
while (true) {
// 從系統中隨機(或者根據用戶興趣)獲取一篇文章ID。
docid = getDocByRandom()
if (bf.exists(userid, docid)) {
// 如果發現可能已向用戶推薦過該文章,則推薦下一篇文章。
continue;
} else {
// 確認未向用戶推薦過該文章,則向用戶發送推薦。
sendRecommendMsg(docid);
// 同時將已推薦的文章ID記錄至TairBloom。
bf.add(userid, docid);
break;
}
}
}基于TairBloom優化爬蟲系統
在面對海量的URL時,將已經爬取過的URL進行過濾、去重操作,減少重復爬取的無效工作量,偽代碼如下:
bool crawlerSystem( ) {
while (true) {
// 獲取待爬取的URL。
url = getURLFromQueue()
if (bf.exists(url_bloom, url)) {
// 如果該URL可能已被爬取,則跳過。
continue;
} else {
// 爬取該URL內容。
doDownload(url)
// 并將該URL加入TairBloom。
bf.add(url_bloom, url);
}
}
}更多最佳實踐
原理介紹
TairBloom作為一種Scalable Bloom Filter的實現,具有動態擴容的能力,同時誤判率(False Positive Rate)維持不變。而Scalable Bloom Filter是在Bloom Filter的基礎上進行優化的,下文將簡單介紹Bloom Filter與Scalable Bloom Filter的基本原理。
Bloom Filter
布隆過濾器是一個高空間利用率的概率性數據結構,由Burton Bloom于1970年提出,用于測試一個元素是否在集合中。
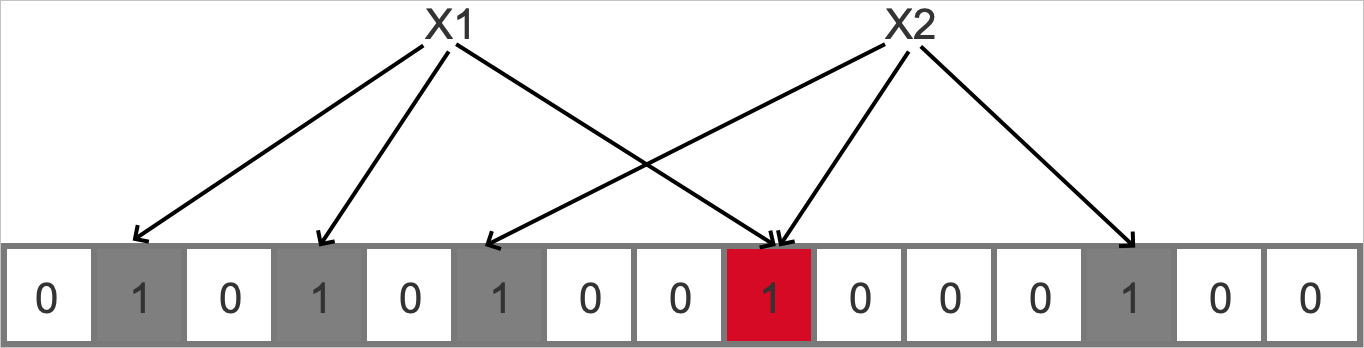
新創建的布隆過濾器是一串被置為0的Bit數組(假設有m位),同時聲明k個不同的Hash函數生成統一的隨機分布(k是一個小于m的常數)。向布隆過濾器中添加元素時,通過k個Hash函數將元素映射到Bit中的k個點,并將這些位置的值設置為1,一個Bit位可能被不同數據共享。下圖展示了假設布隆過濾器的k為3,向其插入X1、X2的過程。
查詢元素時,仍通過k個Hash函數得到對應的k個位,判斷目標位置是否為1,若目標位置全為1則認為該元素在布隆過濾器內,否則認為該元素不存在,下圖展示了在布隆過濾器中查詢Y1和Y2是否存在的過程。
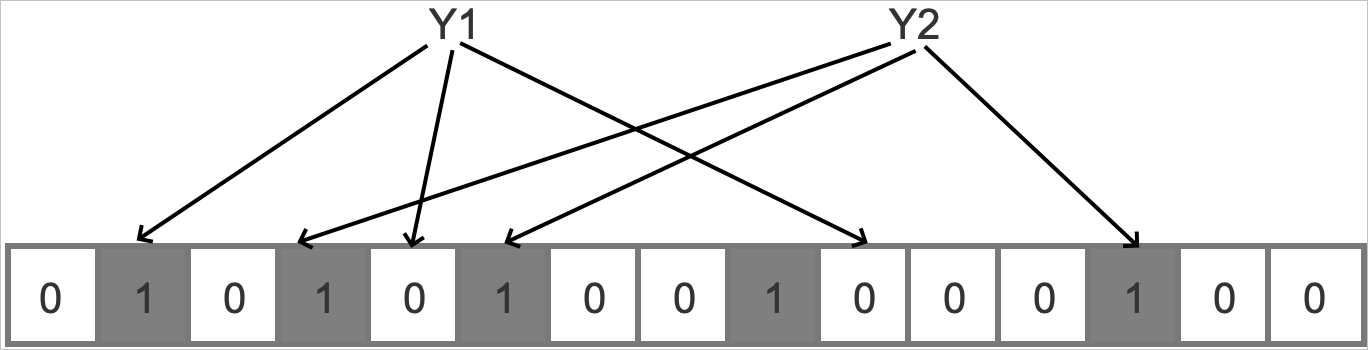
由上圖可以發現,雖然從未向布隆過濾器中插入過Y2這個元素,但是布隆過濾器卻判斷Y2存在,因此,布隆過濾器是可能存在誤判的,即存在假陽性(false positive)。至此,可以得出關于布隆過濾器的幾個特性:
Bit位可能被不同數據共享。
存在假陽性(false positive),且布隆過濾器中的元素越多,假陽性的可能性越大,但不存在假陰性(false negative),即不會將存在的元素誤判為不存在。
元素可以被加入布隆過濾器,但無法被刪除,因為Bit位是可以共享的,刪除時有可能會影響到其他元素。
Scalable Bloom Filter
隨著布隆過濾器中添加的元素越來越多,誤判率也越來越高,若希望誤判率穩定不變,需同步增加布隆過濾器的大小,但是布隆過濾器由于結構限制無法進行擴容。因此,Scalable Bloom Filter提出創建新的布隆過濾器,將多個布隆過濾器組裝成一個布隆過濾器使用。
下圖展示了一個Scalable Bloom Filter的基本模型(下文簡稱SBF)。該SBF一共包含BF0和BF1兩層。在一開始,SBF只包含BF0層,假設在插入a、b、c三個元素后,BF0層已經無法保證用戶設定的誤判率,此時會創建新的一層(BF1層)進行擴容。因此,后面的d、e、f元素會插入到BF1層中。同理,當BF1層也無法滿足誤判率時,會創建新的一層(BF2層),如此進行下去。
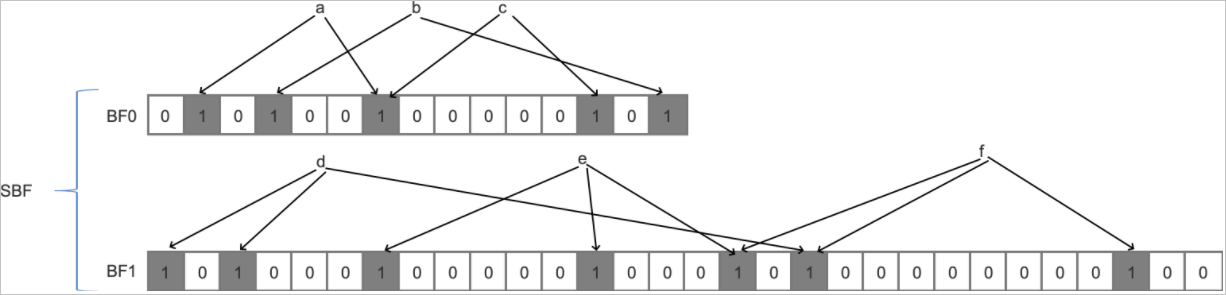
Scalable Bloom Filter只會向最后一層插入數據,同時也從最后一層開始查詢,直到查詢至BF0層。更多信息,請參見Scalable Bloom Filter。
前提條件
注意事項
操作對象為Tair實例中的TairBloom數據。
提前規劃好初始容量與錯誤率,若目標key的預計容量遠大于100,請通過
BF.RESERVE創建TairBloom,不建議直接執行BF.ADD命令。直接執行
BF.ADD與執行BF.RESERVE的區別如下。BF.ADD(或BF.MADD):執行時若目標key不存在,Tair會自動創建TairBloom,默認容量(capacity)為100,錯誤率(error_rate)為0.01。若您的容量遠遠大于100,后續僅能通過擴容增加元素。而TairBloom的擴容是通過增加Bloom Filter的層數來完成,每一層容量將增長,但是隨著不斷的擴容,TairBloom內部的層數會越來越多,此時會導致完成查詢任務需要遍歷多層Bloom Filter,性能將嚴重下降。
BF.RESERVE(或BF.INSERT):執行時需要設置capacity(初始容量),該命令會在TairBloom的第一層初始化設置的容量,在TairBloom內部的Bloom Filter層數少,查詢速度快。
說明以插入10,000,000個元素、錯誤率為0.01為例,直接通過
BF.ADD創建,TairBloom需占用176 MB;而通過BF.RESERVE創建時僅占用16 MB。雖然TairBloom支持擴容,但在實際使用過程中請避免發生擴容操作,建議將該功能視為保障措施,若實際容量超過預設容量時,TairBloom能通過擴容操作,保障業務正常寫入,規避線上事故。
下表為通過
BF.RESERVE創建不同初始容量和錯誤率的key所占用的內存,僅供參考。容量(元素的個數)
false positive:0.01
false positive:0.001
false positive:0.0001
100,000
0.12 MB
0.25 MB
0.25 MB
1,000,000
2 MB
2 MB
4 MB
10,000,000
16 MB
32 MB
32 MB
100,000,000
128 MB
256 MB
256 MB
1,000,000,000
2 GB
2 GB
4 GB
由于TairBloom只能插入新元素且無法刪除已有元素,因此TairBloom的內存占用量只會增加不會減少。為防止TairBloom越來越大,甚至導致Redis內存溢出(Out Of Memory),向您提供如下使用建議。
拆分業務數據:拆分、細化業務數據,避免將大量數據存入一個TairBloom中,這樣不僅會導致這個key過大,影響查詢性能,同時也會由于這個key中插入了過多數據,大部分的查詢流量都會請求到這個key所在的Redis實例上,從而造成熱點key,甚至發生訪問傾斜的情況。
請拆分業務數據,將數據分散到多個TairBloom中,若您的實例為集群實例,您可以將TairBloom分散到集群內的各個實例上,均衡內存容量與流量,充分發揮分布式集群的優勢。
定期重建:如果業務允許,您可以定期重建TairBloom,通過
DEL刪除TairBloom,從后端數據庫拉取數據并重建TairBloom,以控制TairBloom的大小。您也可以在初期創建多個TairBloom,并采用多個TairBloom輪轉切換的方式實現控制單個TairBloom的大小。該方案的優點為僅需創建一次TairBloom,無需頻繁地重建TairBloom,缺點是需要創建多個TairBloom,會浪費部分內存空間。
命令列表
表 1. TairBloom命令
命令 | 語法 | 說明 |
| 創建一個大小為capacity,錯誤率為error_rate的空的TairBloom。 | |
| 在Key指定的TairBloom中添加一個元素。 | |
| 在Key指定的TairBloom中添加多個元素。 | |
| 檢查一個元素是否存在于Key指定的TairBloom中。 | |
| 同時檢查多個元素是否存在于Key指定的TairBloom中。 | |
| 在Key指定的TairBloom中一次性添加多個元素,添加時可以指定大小和錯誤率,且可以控制在TairBloom不存在的時候是否自動創建。 | |
| 查看Key指定的TairBloom內部信息,如當前層數和每一層的元素個數、錯誤率等。 | |
| 使用原生Redis的DEL命令可以刪除一條或多條TairBloom數據。 說明 已加入TairBloom數據中的元素無法單獨刪除,您可以使用DEL命令刪除整條TairBloom數據。 |
本文的命令語法定義如下:
大寫關鍵字:命令關鍵字。斜體:變量。[options]:可選參數,不在括號中的參數為必選。A|B:該組參數互斥,請進行二選一或多選一。...:前面的內容可重復。
BF.RESERVE
類別 | 說明 |
語法 |
|
時間復雜度 | O(1) |
命令描述 | 創建一個大小為capacity,錯誤率為error_rate的空的TairBloom。 |
選項 |
|
返回值 |
|
示例 | 命令示例: 返回示例: |
BF.ADD
類別 | 說明 |
語法 |
|
時間復雜度 | O(log N) ,其中N是TairBloom的層數。 |
命令描述 | 在Key指定的TairBloom中添加一個元素。 說明 若目標Key不存在,Tair會自動創建一個TairBloom,創建TairBloom的默認容量(capacity)為100,錯誤率(error_rate)為0.01。 |
選項 |
|
返回值 |
|
示例 | 命令示例: 返回示例: |
BF.MADD
類別 | 說明 |
語法 |
|
時間復雜度 | O(log N) ,其中N是TairBloom的層數。 |
命令描述 | 在Key指定的TairBloom中添加多個元素。 說明 若目標Key不存在,Tair會自動創建一個TairBloom,創建TairBloom的默認容量(capacity)為100,錯誤率(error_rate)為0.01。 |
選項 |
|
返回值 |
|
示例 | 命令示例: 返回示例: |
BF.EXISTS
類別 | 說明 |
語法 |
|
時間復雜度 | O(log N) ,其中N是TairBloom的層數。 |
命令描述 | 檢查一個元素是否存在于Key指定的TairBloom中。 |
選項 |
|
返回值 |
|
示例 | 命令示例: 返回示例: |
BF.MEXISTS
類別 | 說明 |
語法 |
|
時間復雜度 | O(log N) ,其中N是TairBloom的層數。 |
命令描述 | 同時檢查多個元素是否存在于Key指定的TairBloom中。 |
選項 |
|
返回值 |
|
示例 | 命令示例: 返回示例: |
BF.INSERT
類別 | 說明 |
語法 |
|
時間復雜度 | O(log N) ,其中N是TairBloom的層數。 |
命令描述 | 在Key指定的TairBloom中一次性添加多個元素,添加時可以指定大小和錯誤率,且可以控制在TairBloom不存在的時候是否自動創建。 |
選項 |
|
返回值 |
|
示例 | 命令示例: 返回示例: |
BF.INFO
類別 | 說明 |
語法 |
|
時間復雜度 | O(log N) ,其中N是TairBloom的層數。 |
命令描述 | 查看Key指定的TairBloom內部信息,如當前層數和每一層的元素個數、錯誤率等。 |
選項 |
|
返回值 |
|
示例 | 命令示例: 返回示例: BF.INFO返回參數說明:
|