X-Engine引擎
X-Engine是阿里云數據庫產品事業部自研的聯機事務處理OLTP(On-Line Transaction Processing)數據庫存儲引擎。目前已經廣泛應用在阿里集團內部諸多業務系統中,包括交易歷史庫、釘釘歷史庫等核心應用,大幅縮減了業務成本,同時也作為雙十一大促的關鍵數據庫技術,挺過了數百倍平時流量的沖擊。
X-Engine引擎已進入下線階段,詳情參見【停售/下線】2024年11月1日存儲引擎類型為X-Engine的云數據庫RDS MySQL版實例停止新購。
為什么設計一個新的存儲引擎
X-Engine的誕生是為了應對阿里內部業務的挑戰,早在2010年,阿里內部就大規模部署了MySQL數據庫,但是業務量的逐年爆炸式增長,數據庫面臨著極大的挑戰:
極高的并發事務處理能力(尤其是雙十一的流量突發式暴增)。
超大規模的數據存儲。
這兩個問題雖然可以通過擴展數據庫節點的分布式方案解決,但是堆機器不是一個高效的手段,我們更想用技術的手段將數據庫性價比提升,實現以少量資源換取性能大幅提高的目的。
傳統數據庫架構的性能已經被仔細的研究過,數據庫領域的泰斗,圖靈獎得主Michael Stonebreaker就此寫過一篇論文 《OLTP Through the Looking Glass, and What We Found There》,指出傳統關系型數據庫,僅有不到10%的時間是在做真正有效的數據處理工作,剩下的時間都浪費在其它工作上,例如加鎖等待、緩沖管理、日志同步等。
造成這種現象的原因是近年來我們所依賴的硬件體系發生了巨大的變化,例如多核(眾核)CPU、新的處理器架構(Cache/NUMA)、各種異構計算設備(GPU/FPGA)等,而架構在這些硬件之上的數據庫軟件卻沒有太大的改變,例如使用B-Tree索引的固定大小的數據頁(Page)、使用ARIES算法的事務處理與數據恢復機制、基于獨立鎖管理器的并發控制等,這些都是為了慢速磁盤而設計,很難發揮出現有硬件體系應有的性能。
基于以上原因,阿里開發了適合當前硬件體系的存儲引擎,即X-Engine。
X-Engine架構
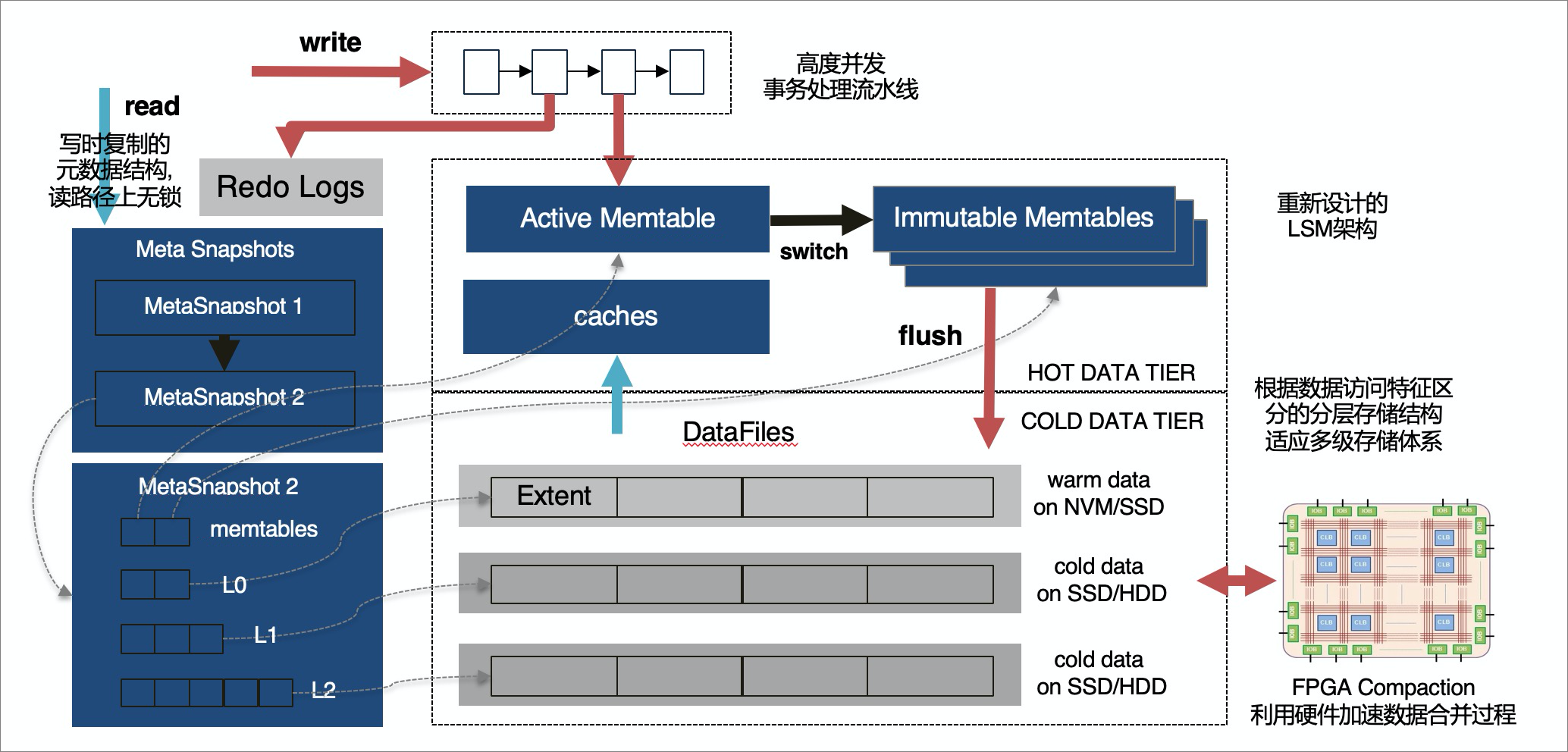
全新架構的X-Engine存儲引擎不僅可以無縫對接兼容MySQL(得益于MySQL Pluginable Storage Engine特性),同時X-Engine使用分層存儲架構。
因為目標是面向大規模的海量數據存儲,提供高并發事務處理能力和降低存儲成本,在大部分大數據量場景下,數據被訪問的機會是不均等的,訪問頻繁的熱數據實際上占比很少,X-Engine根據數據訪問頻度的不同將數據劃分為多個層次,針對每個層次數據的訪問特點,設計對應的存儲結構,寫入合適的存儲設備。
X-Engine使用了LSM-Tree作為分層存儲的架構基礎,并進行了重新設計:
熱數據層和數據更新使用內存存儲,通過內存數據庫技術(Lock-Free index structure/append only)提高事務處理的性能。
流水線事務處理機制,把事務處理的幾個階段并行起來,極大提升了吞吐。
訪問頻度低的數據逐漸淘汰或是合并到持久化的存儲層次中,并結合多層次的存儲設備(NVM/SSD/HDD)進行存儲。
對性能影響比較大的Compaction過程做了大量優化:
拆分數據存儲粒度,利用數據更新熱點較為集中的特征,盡可能的在合并過程中復用數據。
精細化控制LSM的形狀,減少I/O和計算代價,有效緩解了合并過程中的空間增大。
同時使用更細粒度的訪問控制和緩存機制,優化讀的性能。
X-Engine的架構和優化技術已經被總結成論文 《X-Engine: An Optimized Storage Engine for Large-scale E-Commerce Transaction Processing》,在數據管理國際會議SIGMOD'19發表,這是中國內地公司首次在國際性學術會議上發表OLTP數據庫內核相關的技術成果。
技術特點
利用FPGA硬件加速Compaction過程,使得系統上限進一步提升。這個技術屬首次將硬件加速技術應用到在線事務處理數據庫存儲引擎中,相關論文 《FPGA-Accelerated Compactions for LSM-based Key Value Store》已經被2020年的FAST'20國際會議接收。
通過數據復用技術減少數據合并代價,同時減少緩存被淘汰帶來的性能抖動。
使用多事務處理隊列和流水線處理技術,減少線程上下文切換代價,并計算每個階段任務量配比,使整個流水線充分流轉,極大提升事務處理性能。相對于其他類似架構的存儲引擎(例如RocksDB),X-Engine的事務處理性能有10倍以上提升。
X-Engine使用的Copy-on-write技術,避免原地更新數據頁,從而對只讀數據頁面進行編碼壓縮,相對于傳統存儲引擎(例如InnoDB),使用X-Engine可以將存儲空間降低至10%~50%。
Bloom Filter快速判定數據是否存在,Surf Filter判斷范圍數據是否存在,Row Cache緩存熱點行,加速讀取性能。
LSM基本邏輯
LSM的本質是所有寫入操作直接以追加的方式寫入內存。每次寫到一定程度,即凍結為一層(Level),并寫入持久化存儲。所有寫入的行,都以主鍵(Key)排序后存放,無論是在內存中,還是持久化存儲中。在內存中即為一個排序的內存數據結構(Skiplist、B-Tree等),在持久化存儲也作為一個只讀的全排序持久化存儲結構。
普通的存儲系統若要支持事務處理,需要加入一個時間維度,為每個事務構造出一個不受并發干擾的獨立視域。例如存儲引擎會對每個事務定序并賦予一個全局單調遞增的事務版本號(SN),每個事務中的記錄會存儲這個SN以判斷獨立事務之間的可見性,從而實現事務的隔離機制。
如果LSM存儲結構持續寫入,不做其他的動作,那么最終會成為如下結構。
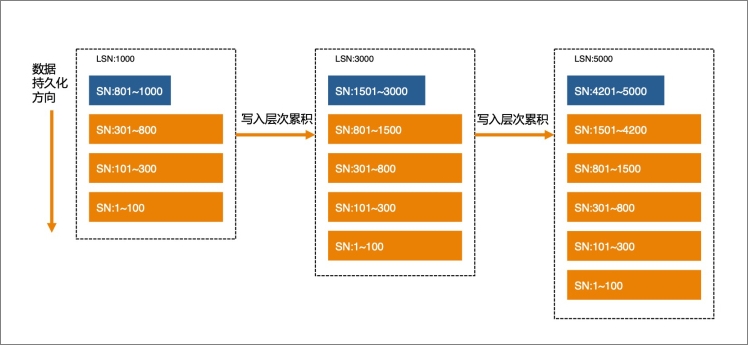
這種結構對于寫入是非常友好的,只要追加到最新的內存表中即完成,為實現故障恢復,只需記錄Redo Log,因為新數據不會覆蓋舊版本,追加記錄會形成天然的多版本結構。
但是如此累積,凍結的持久化層次越來越多,會對查詢產生不利的影響。例如對同一個key,不同事務提交產生的多版本記錄會散落在各個層次中;不同的key也會散落在不同層次中。讀操作需要查找各個層并合并才能得到最終結果。
因此LSM引入了Compaction操作解決這個問題,Compaction操作有2種作用:
控制LSM層次形狀
一般的LSM形狀都是層次越低,數據量越大(倍數關系),目的是為了提升讀性能。
通常存儲系統的數據訪問都有局部性,大量的訪問都集中在少部分數據上,這也是緩存系統能有效工作的基本前提。在LSM存儲結構中,如果把訪問頻率高的數據盡可能放在較高的層次上,存放在快速存儲設備中(例如NVM、DRAM),而把訪問頻率低的數據放在較低層次中,存放在廉價慢速存儲設備中。這就是X-Engine的冷熱分層概念。
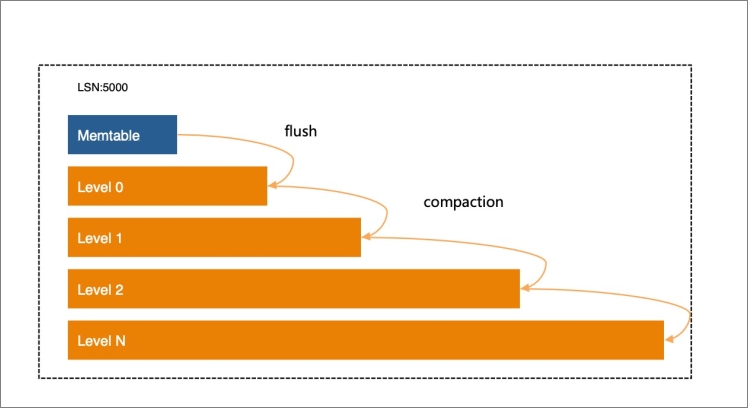
合并數據
Compaction操作不斷的把相鄰層次的數據合并,并寫入更低層次。合并的過程實際上是把要合并的相鄰兩層或多層的數據讀出來,按key排序,相同的key如果有多個版本,只保留新的版本(比當前正在執行的活躍事務中最小版本號新),丟掉舊版本數據,然后寫入新的層,這個操作非常耗費資源。
合并數據除了考慮冷熱分層以外,還需要考慮其他維度,例如數據的更新頻率,大量的多版本數據在查詢的時候會浪費更多的I/O和CPU,因此需要優先進行合并以減少記錄的版本數量。X-Engine綜合考慮了各種策略形成自己的Compaction調度機制。
高度優化的LSM
X-Engine的memory tables使用了無鎖跳表(Locked-free SkipList),并發讀寫的性能較高。在持久化層如何實現高效,就需要討論每層的細微結構。
數據組織
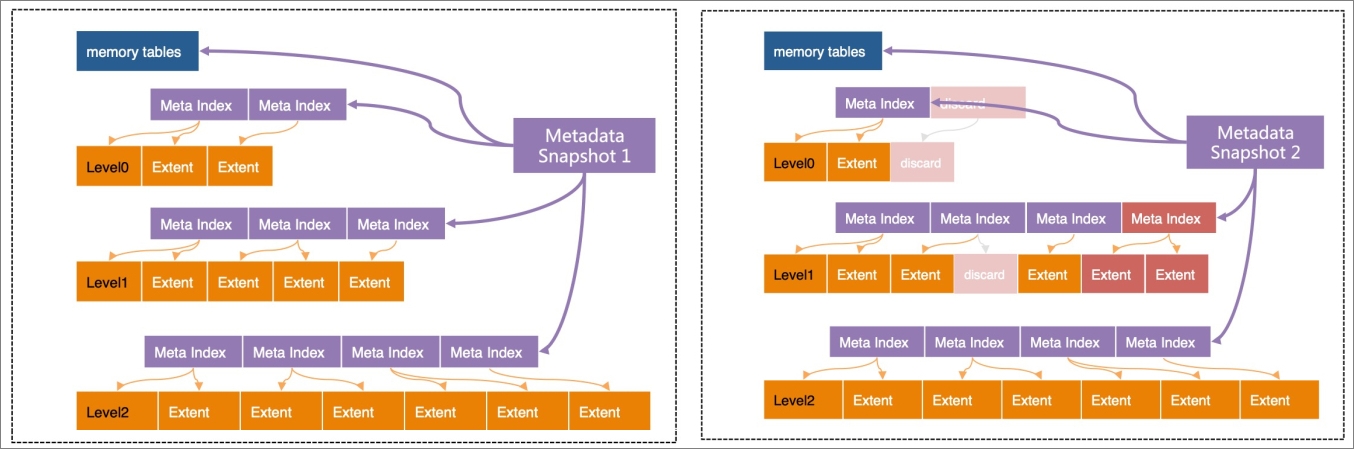
X-Engine的每層都劃分成固定大小的Extent,存放每個層次中的數據的一個連續片段(Key Range)。為了快速定位Extent,為每層Extents建立了一套索引(Meta Index),所有這些索引,加上所有的memory tables(active/immutable)一起組成了一個元數據樹(Metadata Tree),root節點為Metadata Snapshot,這個樹結構類似于B-Tree。
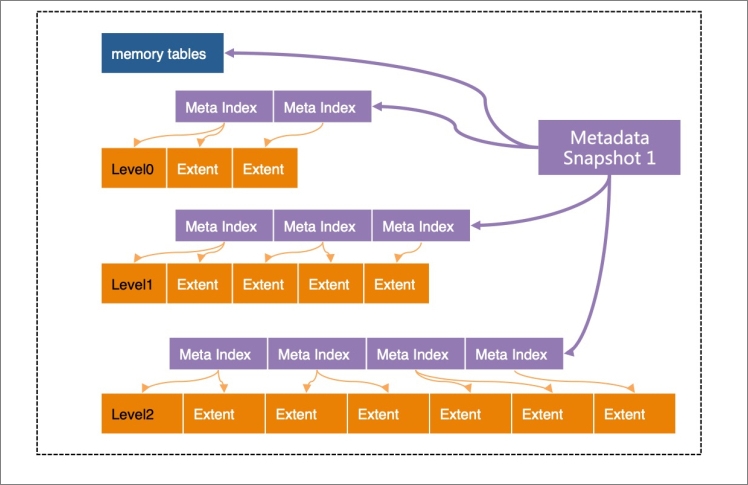
X-Engine中除了當前的正在寫入的active memory tables以外,其他結構都是只讀的,不會被修改。給定某個時間點,例如LSN=1000,上圖中的Metadata Snapshot 1引用到的結構即包含了LSN=1000時的所有的數據的快照,因此這個結構被稱為Snapshot。
即便是Metadata結構本身,也是一旦生成就不會被修改。所有的讀請求都是以Snapshot為入口,這是X-Engine實現Snapshot級別隔離的基礎。前文提到,隨著數據寫入,累積數據越多,會執行Compaction操作、凍結memory tables等,這些操作都是用Copy-on-write實現,即每次都將修改產生的結果寫入新的Extent,然后生成新的Meta Index結構,最終生成新的Metadata Snapshot。
例如執行一次Compaction操作會生成新的Metadata Snapshot,如下圖所示。
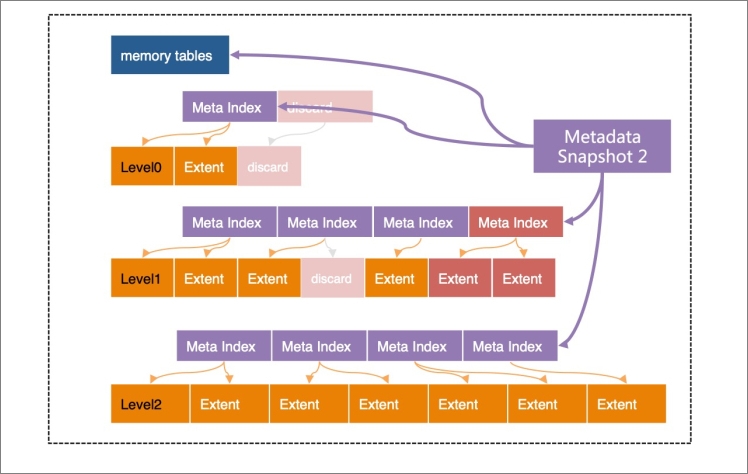
可以看到Metadata Snapshot 2相對于Metadata Snapshot 1并沒有太多的變化,僅僅修改了發生變更的一些葉子節點和索引節點。
說明這個技術頗有些類似 B-trees, shadowing, and clones,如果您閱讀那篇論文,會對理解這個過程有所幫助。
事務處理
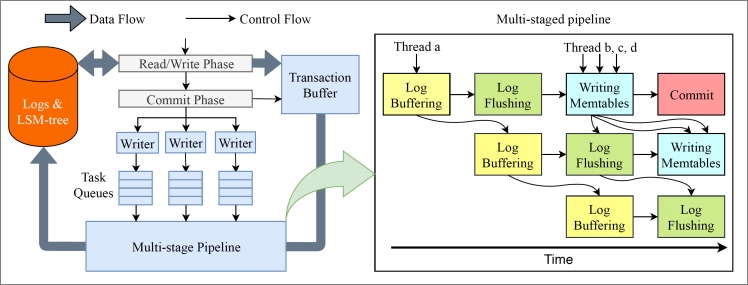
得益于LSM的輕量化寫機制,寫入操作固然是其明顯的優勢,但是事務處理不只是把更新的數據寫入系統那么簡單,還要保證ACID(原子性、一致性、隔離性、持久性),涉及到一整套復雜的流程。X-Engine將整個事務處理過程分為兩個階段:
讀寫階段
校驗事務的沖突(寫寫沖突、讀寫沖突),判斷事務是否可以執行、回滾重試或者等鎖。如果事務沖突校驗通過,則把修改的所有數據寫入Transaction Buffer。
提交階段
寫WAL、寫內存表,以及提交并返回用戶結果,這里面既有I/O操作(寫日志、返回消息),也有CPU操作(拷貝日志、寫內存表)。
為了提高事務處理吞吐,系統內會有大量事務并發執行,單個I/O操作比較昂貴,大部分存儲引擎會傾向于聚集一批事務一起提交,稱為Group Commit,能夠合并I/O操作。但是一組事務提交的過程中,還是有大量等待過程的,例如寫入日志到磁盤過程中,除了等待落盤無所事事。
X-Engine為了進一步提升事務處理的吞吐,使用流水線技術,把提交階段分為4個獨立的更精細的階段:
拷貝日志到緩沖區(Log Buffer)
日志落盤(Log Flush)
寫內存表(Write memory table)
提交返回(Commit)
事務到了提交階段,可以自由選擇執行流水線中任意一個階段,只要流水線任務的大小劃分得當,就能充分并行起來,流水線處于接近滿載狀態。另外這里利用的是事務處理的線程,而非后臺線程,每個線程在執行時,選擇流水線中的一個階段執行任務,或者空閑后處理其他請求,沒有等待,也無需切換,充分利用了每個線程的能力。
讀操作
LSM處理多版本數據的方式是新版本數據記錄會追加在老版本數據后面,從物理上看,一條記錄的不同版本可能存放在不同的層,在查詢的時候需要找到合適的版本(根據事務隔離級別定義的可見性規則),一般查詢都是查找最新的數據,總是由最高的層次往低層次查找。
對于單條記錄的查找而言,一旦找到便可以終止,如果記錄在比較高的層次,例如memory tables,很快便可以返回;如果記錄已經落入了很低的層次,那就得逐層查找,也許Bloom Filter可以跳過某些層次加快這個旅程,但畢竟還是有很多的I/O操作。X-Engine針對單記錄查詢引入了Row Cache,在所有持久化的層次的數據之上做了一個緩存,在memory tables中沒有命中的單行查詢,在Row Cache之中也會被捕獲。Row Cache需要保證緩存了所有持久化層次中最新版本的記錄,而這個記錄是可能發生變化的,例如每次flush將只讀的memory tables寫入持久化層次時,就需要恰當的更新Row Cache中的緩存記錄,這個操作比較微妙,需要精心的設計。
對于范圍掃描而言,因為沒法確定一個范圍的key在哪個層次中有數據,只能掃描所有的層次做合并之后才能返回最終的結果。X-Engine采用了一系列的手段,例如SuRF(SIGMOD'18 best paper)提供range scan filter減少掃描層數、異步I/O與預取。
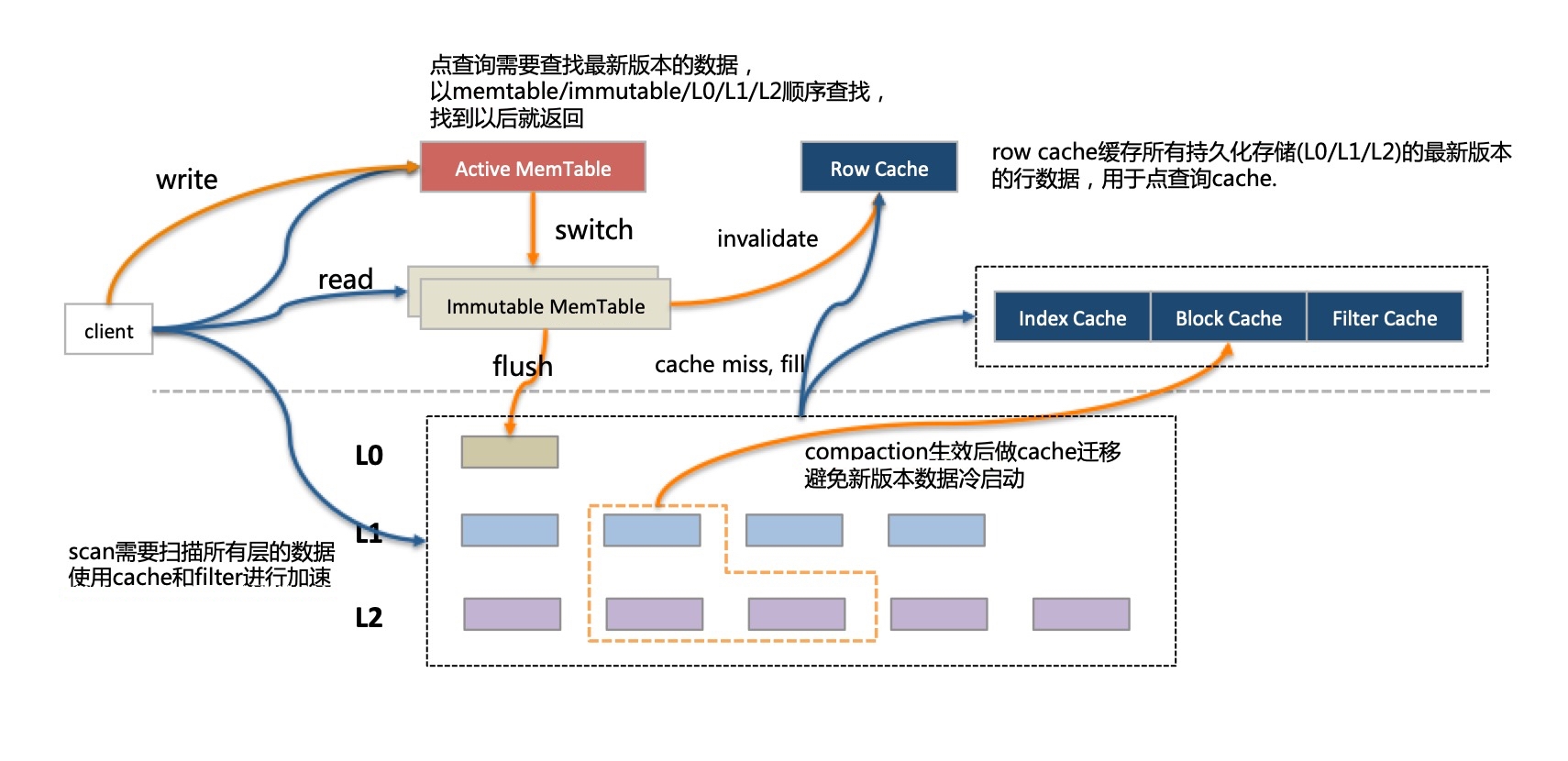
讀操作中最核心的是緩存設計,Row Cache負責單行查詢,Block Cache負責Row Cache的漏網之魚,也用來進行范圍掃描。由于LSM的Compaction操作會一次更新大量的Data Block,導致Block Cache中大量數據短時間內失效,導致性能的急劇抖動,因此X-Engine做了很多的優化:
減少Compaction的粒度。
減少Compaction過程中改動的數據。
Compaction過程中針對已有的緩存數據做定點更新。
Compaction
Compaction操作是比較重要的,需要把相鄰層次交叉的Key Range數據讀取合并,然后寫到新的位置。這是為前面簡單的寫入操作付出的代價。X-Engine為優化這個操作重新設計了存儲結構。
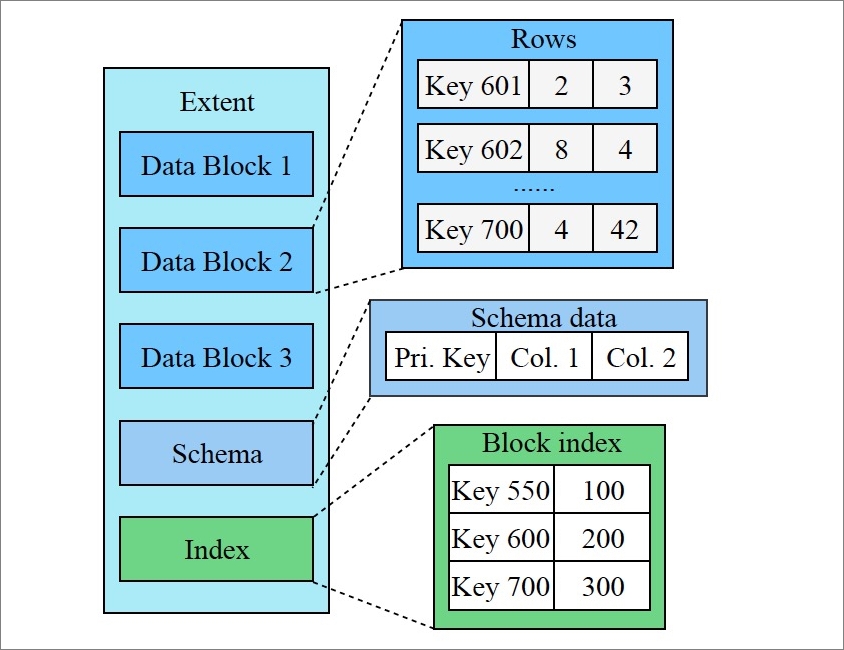
如前文所述,X-Engine將每一層的數據劃分為固定大小的Extent,一個Extent相當于一個小而完整的排序字符串表(SSTable),存儲了一個層次中的一個連續片段,連續片段又進一步劃分為一個個連續的更小的片段Data Block,相當于傳統數據庫中的Page,只不過Data Block是只讀而且不定長的。
回看并對比Metadata Snapshot 1和Metadata Snapshot 2,可以發現Extent的設計意圖。每次修改只需要修改少部分有交疊的數據,以及涉及到的Meta Index節點。兩個Metadata Snapshot結構實際上共用了大量的數據結構,這被稱為數據復用技術(Data Reuse),而Extent大小正是影響數據復用率的關鍵,Extent作為一個完整的被復用的物理結構,需要盡可能的小,這樣與其他Extent數據交叉點會變少,但又不能非常小,否則需要索引過多,管理成本太大。
X-Engine中Compaction的數據復用是非常徹底的,假設選取兩個相鄰層次(Level1, Level2)中的交叉的Key Range所涵蓋的Extents進行合并,合并算法會逐行進行掃描,只要發現任意的物理結構(包括Data Block和Extent)與其他層中的數據沒有交疊,則可以進行復用。只不過Extent的復用可以修改Meta Index,而Data Block的復用只能拷貝,即便如此也可以節省大量的CPU。
一個典型的數據復用在Compaction中的過程可以參見下圖。
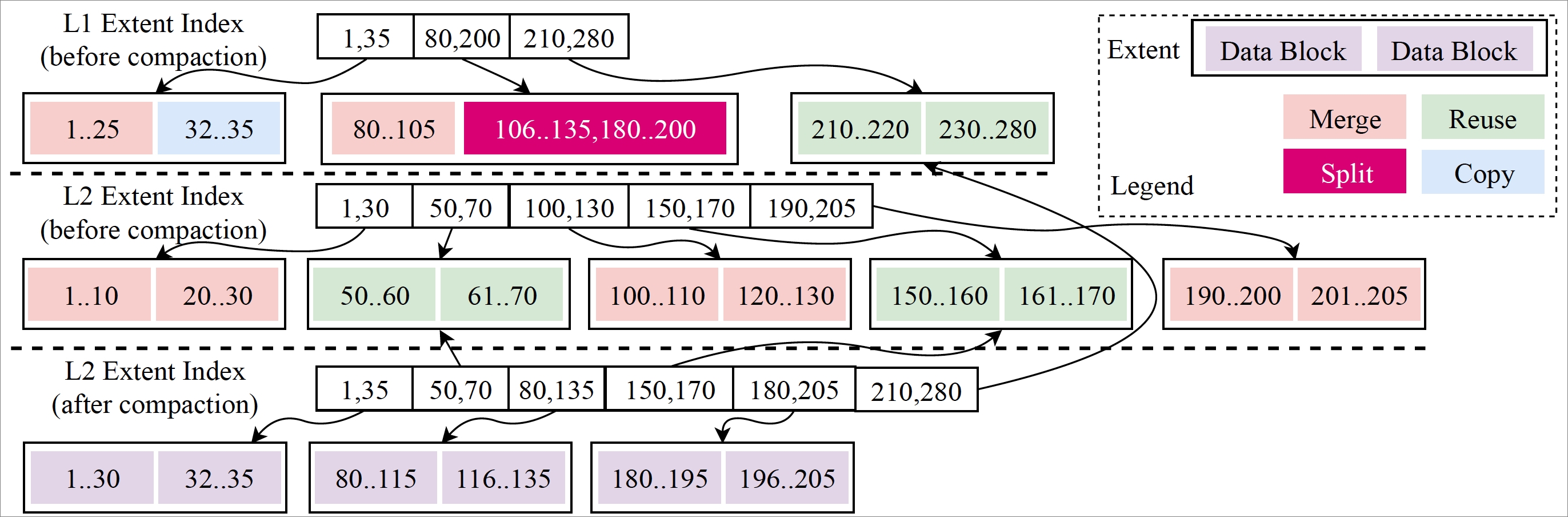
可以看出數據復用的過程是在逐行迭代的過程中完成的,不過這種精細的數據復用帶來另一個副作用,即數據的碎片化,所以在實際操作的過程中也需要根據實際情況進行分析。
數據復用不僅給Compaction操作本身帶來好處,降低操作過程中的I/O與CPU消耗,更對系統的綜合性能產生一系列的影響。例如Compaction過程中數據不用完全重寫,大大降低了寫入時空間的增大;大部分數據保持原樣,數據緩存不會因為數據更新而失效,減少合并過程中因緩存失效帶來的讀性能抖動。
實際上,優化Compaction的過程只是X-Engine工作的一部分,更重要的是優化Compaction調度的策略,選什么樣的Extent、定義compaction任務的粒度、執行的優先級等,都會對整個系統性能產生影響,可惜并不存在什么完美的策略,X-Engine積累了一些經驗,定義了很多規則,而探索更合理的調度策略是未來一個重要方向。
適用場景
請參見X-Engine最佳實踐。
如何使用X-Engine
請參見X-Engine引擎使用須知。
后續發展
作為MySQL的存儲引擎,持續地提升MySQL系統的兼容能力是一個重要目標,后續會根據需求的迫切程度逐步加強原本取消的一些功能,例如外鍵,以及對一些數據結構、索引類型的支持。
X-Engine作為存儲引擎,核心的價值還在于性價比,持續提升性能降低成本,是一個長期的根本目標,X-Engine還在Compaction調度、緩存管理與優化、數據壓縮、事務處理等方向上進行深層次的探索。
X-Engine不僅僅局限為一個單機的數據庫存儲引擎,未來還將作為自研分布式數據庫PolarDB分布式版本的核心,提供企業級數據庫服務。