本文將介紹UNI_HASH的使用方式。
注意事項
UNI_HASH算法是簡單取模,要求拆分列的值的自身分布均衡才能保證哈希均衡。
使用限制
- 拆分鍵的數據類型必須是整數類型或字符串類型。
- PolarDB-X 1.0實例的版本需為5.1.28-1508068或以上,關于實例版本請參見版本說明。
路由方式
UNI_HASH主要用于以下場景:
- 使用UNI_HASH分庫時,根據分庫鍵的鍵值直接按分庫數取余。如果鍵值是字符串,則字符串會被計算成哈希值再進行計算,完成路由計算,例如
HASH('8')等價于8 % D(D 是分庫數目)。 - 分庫和分表都使用同一個拆分鍵進行UNI_HASH時,先根據分庫鍵鍵值按分庫數取余,再均勻散布到該分庫的各個分表上。
使用場景
- 適合于需要按用戶ID或訂單ID進行分庫的場景。
- 適合于拆分鍵是整數或字符串類型的場景。
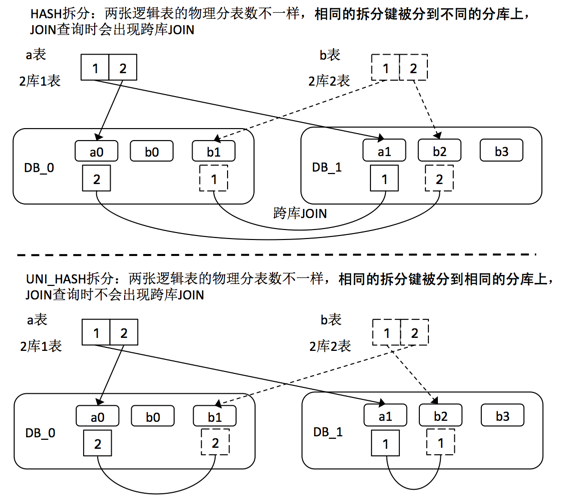
- 兩張邏輯表需要根據同一個拆分鍵進行分庫,兩張表的分表數不同,又經常會按該拆分鍵進行JOIN的場景。
使用示例
假設需要對ID列按UNI_HASH函數進行分庫分表,每庫包含4張表,則您可以使用如下DDL語句進行建表 :
create table test_hash_tb (
id int,
name varchar(30) DEFAULT NULL,
create_time datetime DEFAULT NULL,
primary key(id)
) ENGINE=InnoDB DEFAULT CHARSET=utf8
dbpartition by UNI_HASH(ID)
tbpartition by UNI_HASH(ID) tbpartitions 4;與HASH的比較
| 對比場景 | UNI_HASH | HASH |
|---|---|---|
| 分庫不分表。 | 此時兩個函數的路由方式一樣,都是根據分庫鍵的鍵值按分庫數取余。 | |
| 使用同一個拆分鍵進行分庫分表。 | 同一個鍵值分到的分庫的路由結果不會隨著分表數的變化而改變。 | 同一個鍵值分到的分庫會隨著分表數的變化而改變。 |
| 兩張邏輯表需要根據同一個拆分鍵進行分庫分表,但分表數不同。 | 當兩張表按該拆分鍵進行JOIN時,不會出現跨庫JOIN的情況。 | 當兩張表按該拆分鍵進行JOIN時,會出現跨庫JOIN的情況。 |
假設有2個物理分庫(DB_0和DB_1),2張邏輯表(a和b),其中a表每庫1張分表,b表每庫2張分表。下圖展示了分別使用HASH和UNI_HASH進行拆分后,a表和b表進行JOIN的情景: