擴展性原理
擴展性本質在于分而治之,PolarDB-X 1.0計算資源通過水平拆分(分庫分表)和垂直拆分,將數據分散到多個存儲資源MySQL以實現獲取數據讀寫并發和存儲容量分散的效果。
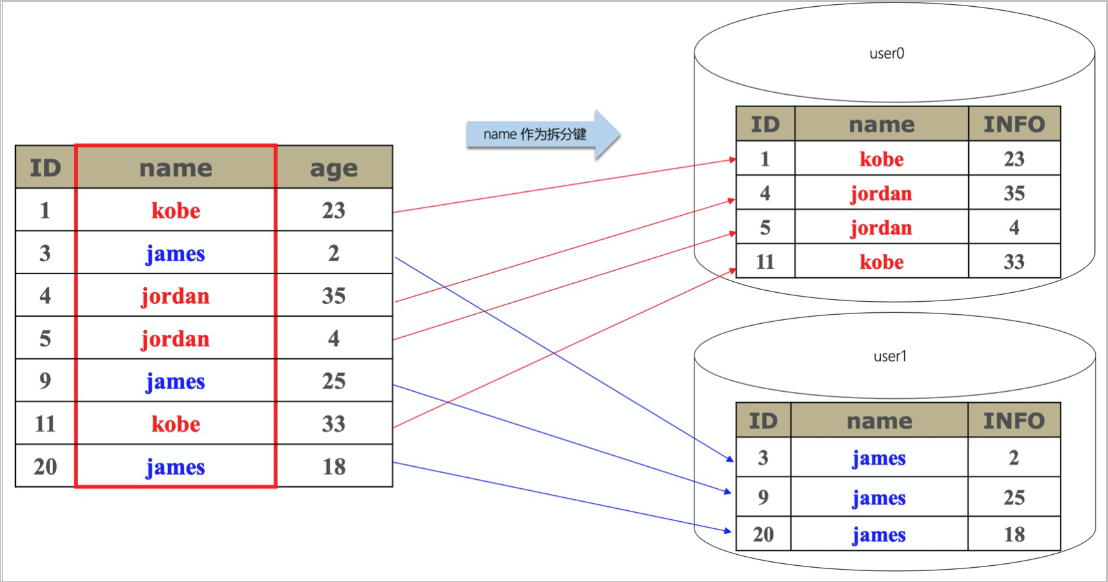
水平拆分(分庫分表)PolarDB-X 1.0具備數據水平拆分的能力,將數據庫數據按某種規則分散存儲到多個穩定的MySQL數據庫上。這些MySQL數據庫可分布于多臺機器乃至跨機房,對外服務(增刪改查)盡可能保證如同單MySQL數據庫體驗。拆分后,在MySQL上物理存在的數據庫稱為分庫,物理的表稱為分表(每個分表數據是完整數據的一部分)。PolarDB-X 1.0通過在不同MySQL實例上挪動分庫,實現數據庫擴容,提升PolarDB-X 1.0數據庫總體訪問量和存儲容量。
您可以通過一定的計算或路由規則放置數據,實現將數據分散到多個存儲資源MySQL中。PolarDB-X 1.0具備豐富的算法來應對各種場景。
數據拆分原理如下圖所示:
 計算擴展性
計算擴展性無論是水平拆分還是垂直拆分,PolarDB-X 1.0常常碰到需要對遠超單機容量數據進行復雜計算的需求,例如需要執行多表JOIN、多層嵌套子查詢、Grouping、Sorting、Aggregation等組合的SQL操作語句。
針對這類在線數據庫上復雜SQL的處理, PolarDB-X 1.0額外擴展了單機并行處理器(Symmetric Multi-Processingy,簡稱SMP)和多機并行處理器(DAG)。前者完全集成在PolarDB-X 1.0內核中;而對于后者,PolarDB-X 1.0構建了一個計算集群,能夠在運行時動態獲取執行計劃并進行分布式計算,通過增加節點提升計算能力。
平滑擴容
PolarDB-X 1.0擴容是通過增加RDS/PolarDB MySQL實例數,將原有的分庫遷移到新的RDS/PolarDB MySQL實例上,達到擴容的目標。PolarDB-X 1.0采用基于存儲計算分離的Shared-Nothing架構,最大限度地發揮了云數據庫的彈性擴展能力。
- 創建擴容計劃
選擇新增加RDS/PolarDB MySQL,并選定需要遷移到新RDS/PolarDB MySQL實例上的分庫,提交任務后系統自動在目標RDS/PolarDB MySQL上創建數據庫和賬號,并提交任務進行數據遷移同步。
- 全量遷移
系統選擇當前時間之前的一個時間點,將這個時間點之前的數據進行全量的數據復制遷移。
- 增量數據同步
完成全量遷移后,基于全量遷移開始之前時間點的增量變更日志進行增量同步,最終原分庫和目標分庫數據實時同步。
- 數據校驗
增量達到準實時同步后,系統自動做全數據校驗,并且訂正因為同步延遲造成的不一致數據。
- 應用停寫和路由切換
校驗完成后,并且增量依然維持準實時同步,業務選定時間進行切換,為確保數據嚴格一致,建議應用停服(也可以不停,但可能面臨同一條數據高并發寫入覆蓋問題),引擎層進行分庫規則的路由切換,將后續流量轉向新庫,切換過程秒級完成。
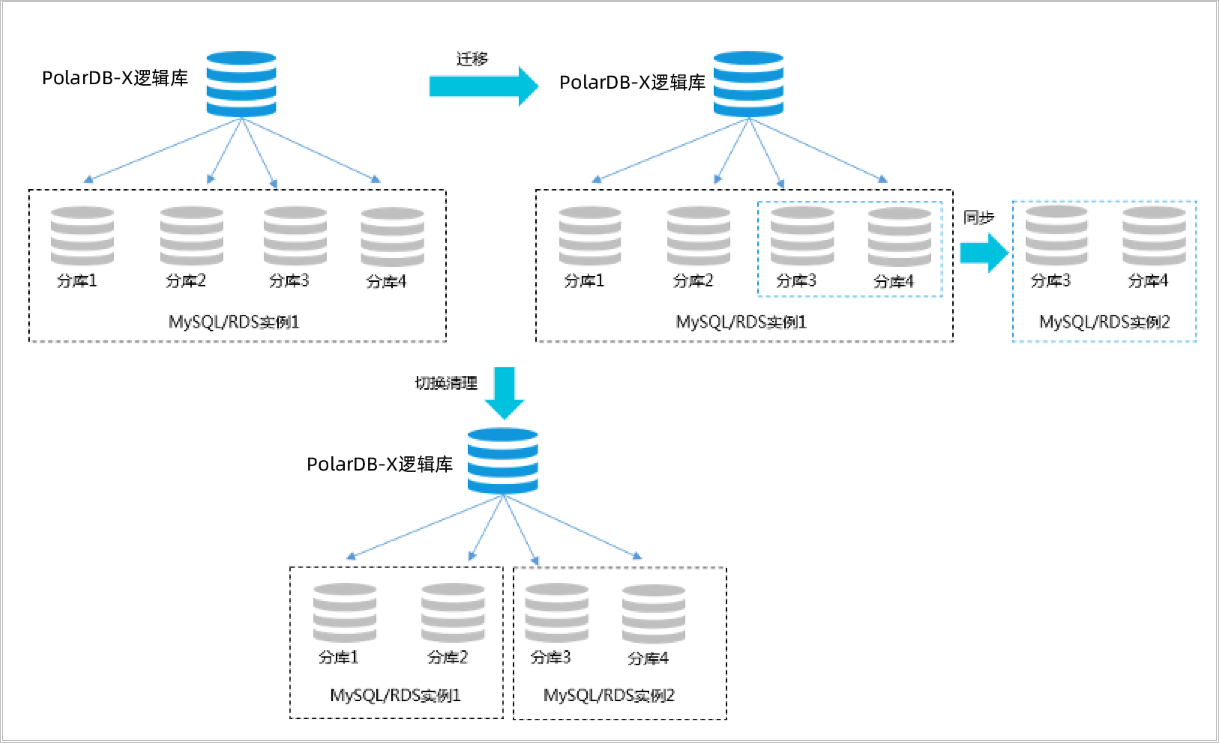
為了保證數據本身的安全,便于擴容回滾,在路由規則切換完成后,數據同步依然會運行,直到數據運維人員確認服務正常后在控制臺主動發起舊分庫數據的清理。
整個擴容過程對上層的業務正常服務幾乎沒有影響(如果RDS/MySQL實例規格過小或者壓力過大則可能造成部分影響),切換時如果應用不停服,建議操作選擇在數據庫訪問低谷期進行,降低同一條數據并發更新覆蓋的概率。
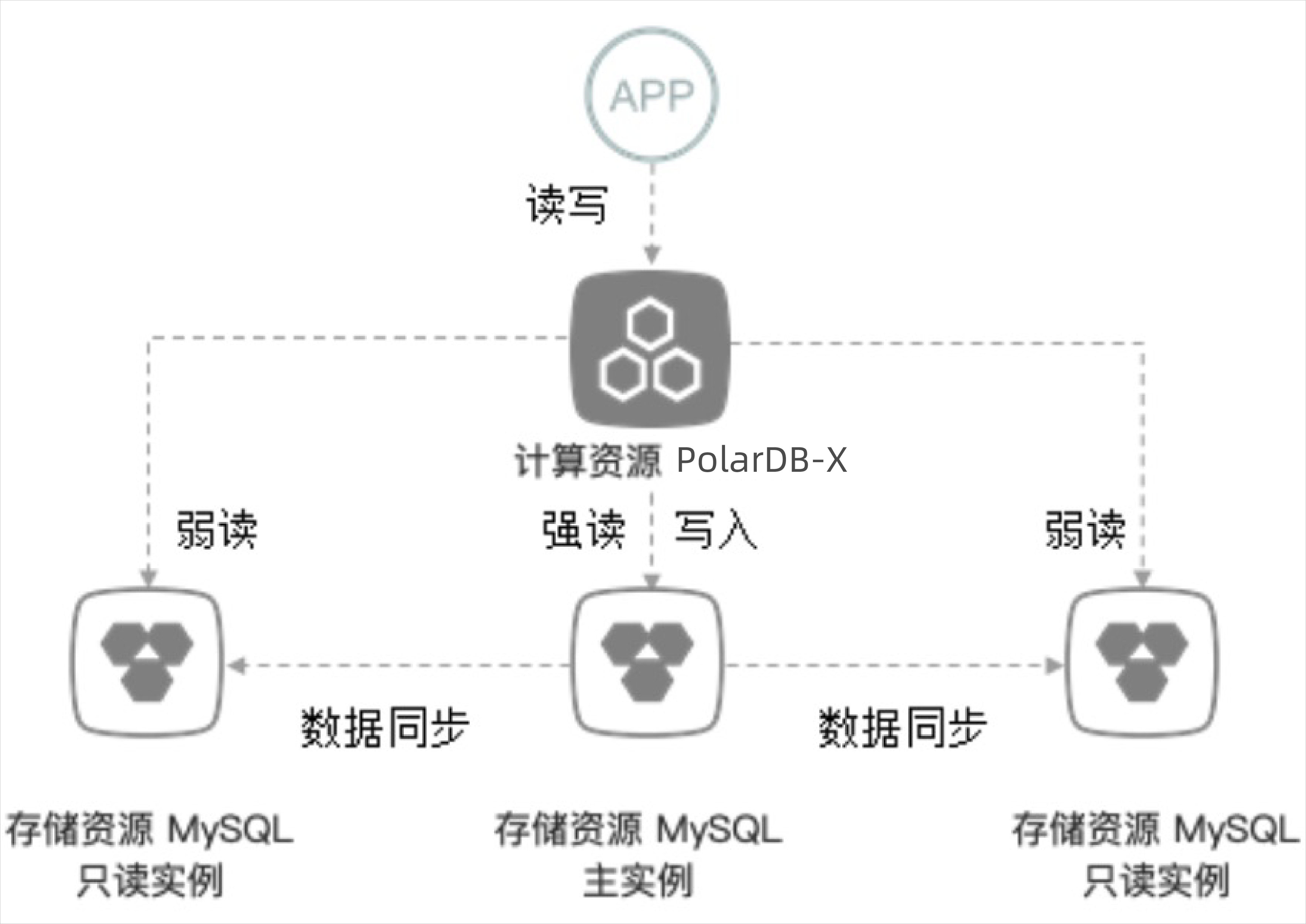
讀寫分離
PolarDB-X 1.0的讀寫分離功能是基于RDS/MySQL只讀實例所做的一種相對透明讀流量切換策略。當PolarDB-X 1.0存儲資源MySQL主實例的讀請求較多、讀壓力比較大時,您可以通過讀寫分離功能對讀流量進行分流,減輕存儲層的讀壓力。
業務應用在能夠忍受只讀實例相對于主實例數據同步延遲的前提下,不需要修改代碼,即可在PolarDB-X 1.0控制臺中增加RDS/MySQL只讀實例和調整讀權重,將讀流量按照需要的比例在RDS/MySQL主實例與多個RDS/MySQL只讀實例之間調整,寫操作和事務操作則統一走RDS/MySQL主實例。需要注意的是,主RDS/MySQL實例和只讀RDS/MySQL存在數據同步延遲,并且在發生大的DDL或者數據訂正時,有可能導致分鐘級別以上的延遲,所以需要業務忍受該情況所帶來的影響。添加只讀實例可以使讀性能線性提升。例如在初始有一個只讀實例的情況下,掛載一個只讀實例,讀性能提升至原來兩倍,掛載2個只讀實例,則讀性能為單個主庫讀性能的三倍。
讀寫分離流量分配與擴展PolarDB-X 1.0讀寫分離功能采用了對應用透明的設計。在不修改應用程序任何代碼的情況下,只需在控制臺中調整讀權重,即可實現將讀流量按自定義的權重比例在存儲資源MySQL/RDS主實例與多個存儲資源只讀實例之間進行分流,而寫流量則不做分流全部到指向主實例。
讀寫分離對事務的支持
讀寫分離僅對顯式事務(即需要顯式提交或回滾的事務)以外的讀請求(即查詢請求)有效,寫請求和顯式事務中的讀請求(包括只讀事務)均在主實例中執行,不會被分流到只讀實例。
- 讀請求:SELECT、SHOW、EXPLAIN、DESCRIBE。
- 寫請求:INSERT、REPLACE、UPDATE、DELETE、CALL。
PolarDB-X 1.0的讀寫分離可以在非拆分模式下獨立使用。
PolarDB-X 1.0控制臺上創建PolarDB-X 1.0數據庫時,在選定一個數據庫實例的情況下,可以選擇將底層數據庫實例下的一個邏輯數據庫直接引入PolarDB-X 1.0做讀寫分離,不需要做數據遷移。
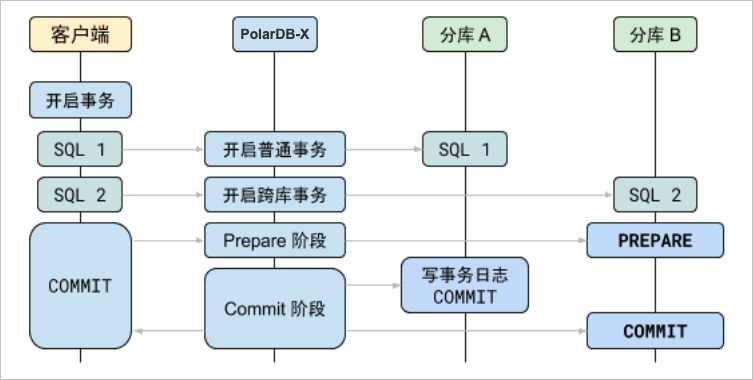
分布式事務
分布式事務通常使用二階段提交來保證事務的原子性(Atomicity)和一致性(Consistency)。
- 準備(PREPARE)階段:在PREPARE階段,數據節點會準備好所有事務提交所需的資源(例如加鎖、寫日志等)。
- 提交(COMMIT)階段:在COMMIT階段,各個數據節點才會真正提交事務。
當提交一個分布式事務時,PolarDB-X 1.0服務器會作為事務管理器的角色,等待所有數據節點(MySQL服務器)PREPARE成功,之后再向各個數據節點發送COMMIT請求。
全局二級索引
全局二級索引(Global Secondary Index,GSI)支持按需增加拆分維度,提供全局唯一約束。每個GSI對應一張索引表,使用XA多寫保證主表和索引表之間數據強一致。
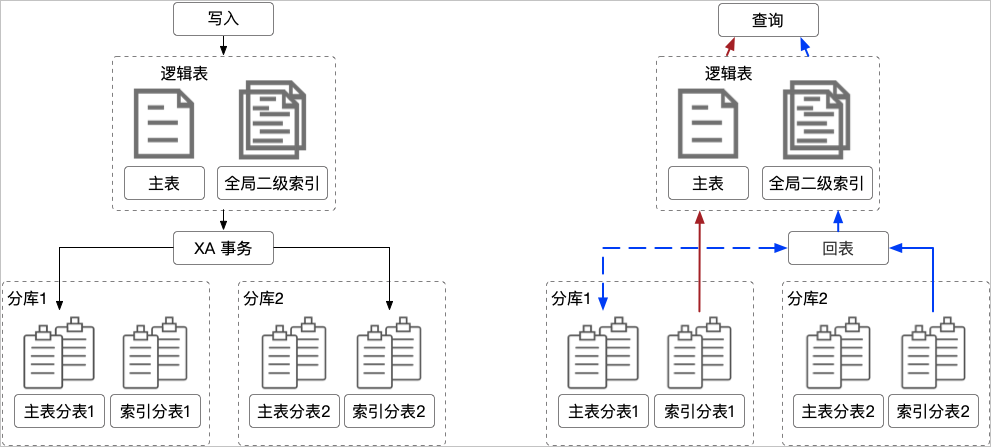
- 增加拆分維度。
- 支持全局唯一索引。
- XA多寫,保證主表與索引表數據強一致。
- 支持覆蓋列,減少回表操作,避免額外開銷。
- Online Schema Change,添加GSI不鎖主表。
- 支持通過HINT指定索引,自動判斷是否需要回表。
HTAP
PolarDB-X 1.0解決了OLTP數據庫面對海量數據下的存儲、并發方面的擴展性問題,但由于缺失多機并行查詢加速能力和列存儲等能力,無法滿足對實時性計算和復雜查詢都要求較高的在線業務場景,同時還面臨著ETL(Extract-Transform-Loa)數據異步傳輸鏈路運維復雜度高、數據一致性和查詢實時性無法嚴格保障等挑戰。
PolarDB-X 1.0由多個節點構成計算、存儲內核一體化實例,在共用一份數據的基礎上避免了ETL(Extract-Transform-Load)操作,實現了在線高并發OLTP聯機事務處理以及OLAP海量數據分析,即HTAP。
原理架構
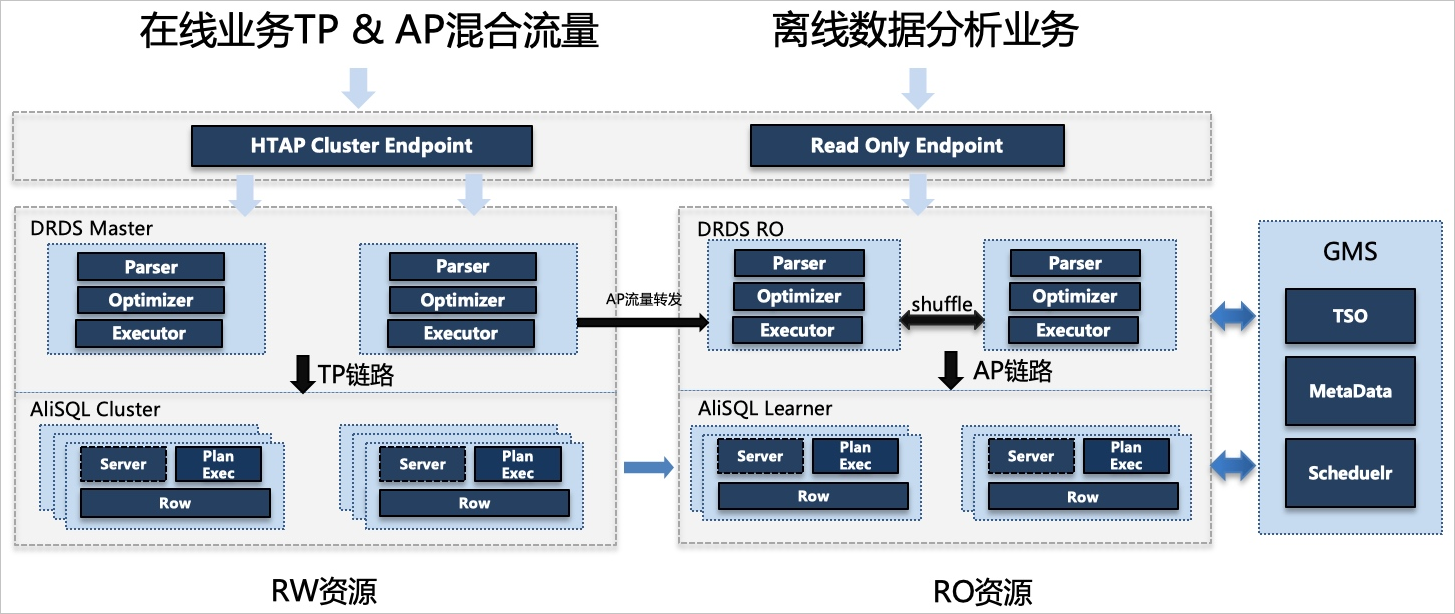
- MPP和只讀資源
PolarDB-X 1.0通過多組DRDS計算節點提供大規模多級并行處理能力(Massively Parallel Processing,簡稱MPP),針對計算節點進行Scale-out完成MPP處理能力的線性擴展。
同時通過AiSQL三節點基于Paxos構建Row-based只讀Learner配合DRDS只讀計算節點,提供TP、AP資源鏈路隔離機制。
- 連接地址和數據源
PolarDB-X 1.0的TP和AP請求提供了統一連接地址(Endpoint),保持SQL語義以及兼容性完全一致。
主實例提供HTAP集群地址(Cluster Endpoint)面向在線通用業務場景,提供了智能讀寫分離和強一致讀特性。只讀實例提供HTAP只讀地址(Private Read Only Endpoint),專注離線拖數、跑批等資源鏈路隔離場景,確保只讀資源可被獨享。
若PolarDB-X 1.0已添加只讀實例,默認將AP workload轉發至只讀實例進行MPP并行加速;若未添加任何只讀實例,則轉發至主實例內部所有計算節點完成執行。
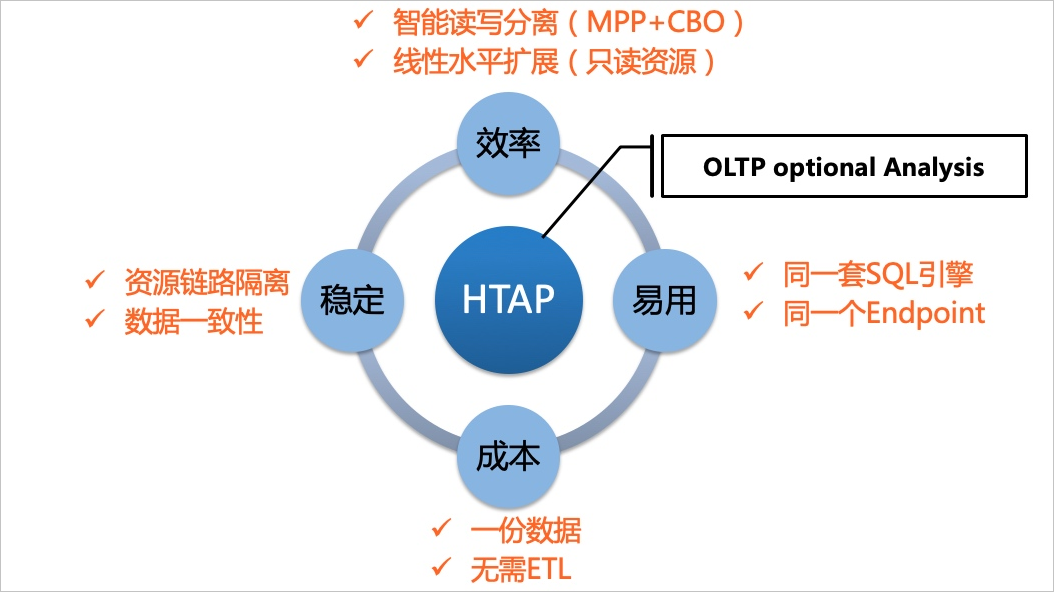
- 一份數據,一個數據源,一個Endpoint即可覆蓋TP和AP業務場景,降低數據庫選型成本。
- 支持線性水平擴展提升HTAP復雜查詢加速能力,通過橫向增加只讀實例即可提高復雜查詢速率。
- 避免數據異步傳輸,滿足全局數據查詢一致性,提升業務實時分析效率。
- 資源鏈路隔離,確保在線核心業務鏈路穩定性。