Kafka是應(yīng)用較為廣泛的分布式、高吞吐量、高可擴展性消息隊列服務(wù),普遍用于日志收集、監(jiān)控數(shù)據(jù)聚合、流式數(shù)據(jù)處理、在線和離線分析等大數(shù)據(jù)領(lǐng)域,是大數(shù)據(jù)生態(tài)中不可或缺的產(chǎn)品之一。通過數(shù)據(jù)傳輸服務(wù)DTS(Data Transmission Service),您可以將PolarDB MySQL版同步至自建Kafka集群,擴展消息處理能力。
前提條件
- Kafka集群的版本為0.10.1.0~2.7.0版本。
- PolarDB MySQL版已開啟Binlog,詳情請參見如何開啟Binlog。
注意事項
如果源數(shù)據(jù)庫沒有主鍵或唯一約束,且所有字段沒有唯一性,可能會導(dǎo)致目標數(shù)據(jù)庫中出現(xiàn)重復(fù)數(shù)據(jù)。
費用說明
| 同步類型 | 鏈路配置費用 |
|---|---|
| 庫表結(jié)構(gòu)同步和全量數(shù)據(jù)同步 | 不收費。 |
| 增量數(shù)據(jù)同步 | 收費,詳情請參見計費概述。 |
功能限制
- 僅支持表粒度的數(shù)據(jù)同步。
- 不支持自動調(diào)整同步對象。 說明 如果在同步的過程中,對源庫中待同步的表執(zhí)行了重命名操作,且重命名后的名稱不在同步對象中,那么該表將不再被同步到目標Kafka集群中。如果該表還需要同步,那么您需要新增同步對象。
操作步驟
- 購買數(shù)據(jù)同步作業(yè),詳情請參見購買流程。說明 購買時,選擇源實例為PolarDB、目標實例為Kafka,并選擇同步拓撲為單向同步。
- 登錄數(shù)據(jù)傳輸控制臺。說明 若數(shù)據(jù)傳輸控制臺自動跳轉(zhuǎn)至數(shù)據(jù)管理DMS控制臺,您可以在右下角的
 中單擊
中單擊 ,返回至舊版數(shù)據(jù)傳輸控制臺。
,返回至舊版數(shù)據(jù)傳輸控制臺。 - 在左側(cè)導(dǎo)航欄,單擊數(shù)據(jù)同步。
- 在同步作業(yè)列表頁面頂部,選擇同步的目標實例所屬地域。
- 定位至已購買的數(shù)據(jù)同步實例,單擊配置同步鏈路。
- 配置源實例及目標實例信息。
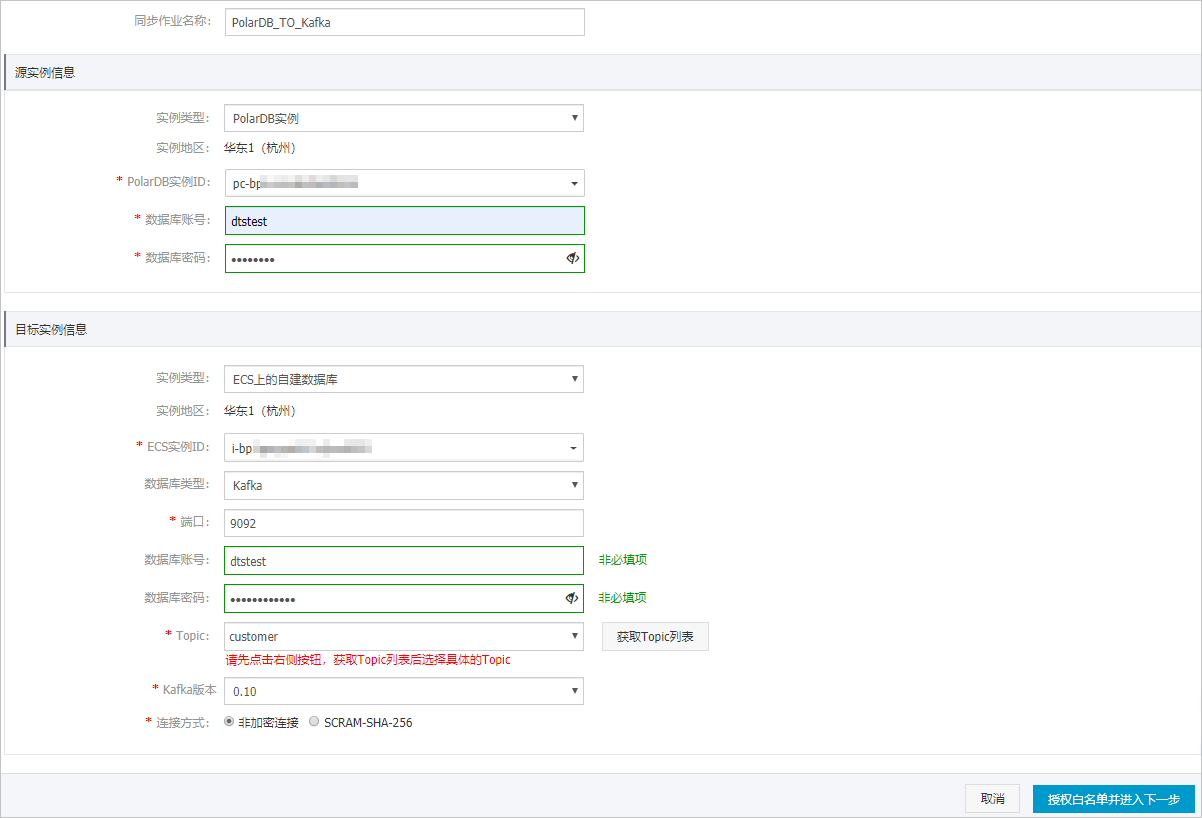
類別 配置 說明 無 同步作業(yè)名稱 DTS會自動生成一個同步作業(yè)名稱,建議配置具有業(yè)務(wù)意義的名稱(無唯一性要求),便于后續(xù)識別。 源實例信息 實例類型 固定為PolarDB實例,不可變更。 實例地區(qū) 購買數(shù)據(jù)同步實例時選擇的源實例地域,不可變更。 PolarDB實例ID 選擇PolarDB MySQL版集群ID。 數(shù)據(jù)庫賬號 填入PolarDB MySQL版集群的數(shù)據(jù)庫賬號,需要具備待同步數(shù)據(jù)庫的讀權(quán)限。 數(shù)據(jù)庫密碼 填入該數(shù)據(jù)庫賬號的密碼。 目標實例信息 實例類型 根據(jù)Kafka集群的部署位置選擇,本文以ECS上的自建數(shù)據(jù)庫為例介紹配置流程。 說明 當選擇為其他實例類型時,您還需要執(zhí)行相應(yīng)的準備工作,詳情請參見準備工作概覽。實例地區(qū) 購買數(shù)據(jù)同步實例時選擇的目標實例地域,不可變更。 ECS實例ID 選擇部署了Kafka集群的ECS實例ID。 數(shù)據(jù)庫類型 選擇為Kafka。 端口 Kafka集群對外提供服務(wù)的端口,默認為9092。 數(shù)據(jù)庫賬號 填入Kafka集群的用戶名,如Kafka集群未開啟驗證可不填寫。 數(shù)據(jù)庫密碼 填入Kafka集群用戶名對應(yīng)的密碼,如Kafka集群未開啟驗證可不填寫。 Topic 單擊右側(cè)的獲取Topic列表,然后在下拉框中選擇具體的Topic。 Kafka版本 根據(jù)目標Kafka集群版本,選擇對應(yīng)的版本信息。 連接方式 根據(jù)業(yè)務(wù)及安全需求,選擇非加密連接或SCRAM-SHA-256。 - 單擊頁面右下角的授權(quán)白名單并進入下一步。說明
- 如果源或目標數(shù)據(jù)庫是阿里云數(shù)據(jù)庫實例(例如RDS MySQL、云數(shù)據(jù)庫MongoDB版等)或ECS上的自建數(shù)據(jù)庫,DTS會自動將對應(yīng)地區(qū)DTS服務(wù)的IP地址添加到阿里云數(shù)據(jù)庫實例的白名單或ECS的安全規(guī)則中,您無需手動添加,請參見DTS服務(wù)器的IP地址段。
- DTS任務(wù)完成或釋放后,建議您手動刪除添加的DTS服務(wù)器IP地址段。
- 配置同步策略和同步對象信息。
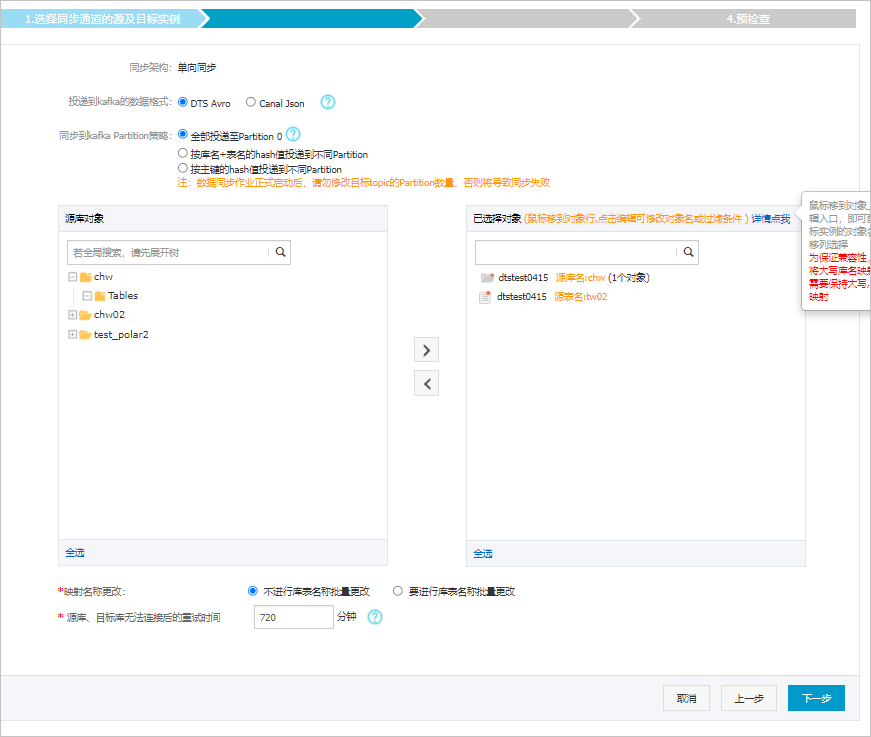
配置 說明 投遞到kafka的數(shù)據(jù)格式 同步到Kafka集群中的數(shù)據(jù)以avro格式或者Canal Json格式存儲,定義詳情請參見Kafka集群的數(shù)據(jù)存儲格式。 同步到Kafka Partition策略 根據(jù)業(yè)務(wù)需求選擇同步的策略,詳細介紹請參見Kafka Partition同步策略說明。 同步對象 在源庫對象區(qū)域框中,選擇需要同步的對象(選擇的粒度為表),然后單擊  圖標將其移動到已選對象區(qū)域框中。說明 DTS會自動將表名映射為步驟6選擇的Topic名稱。如果需要更換同步的目標Topic,請參見步驟9 。
圖標將其移動到已選對象區(qū)域框中。說明 DTS會自動將表名映射為步驟6選擇的Topic名稱。如果需要更換同步的目標Topic,請參見步驟9 。映射名稱更改 如需更改同步對象在目標實例中的名稱,請使用對象名映射功能,詳情請參見庫表列映射。
源、目標庫無法連接重試時間 當源、目標庫無法連接時,DTS默認重試720分鐘(即12小時),您也可以自定義重試時間。如果DTS在設(shè)置的時間內(nèi)重新連接上源、目標庫,同步任務(wù)將自動恢復(fù)。否則,同步任務(wù)將失敗。說明 由于連接重試期間,DTS將收取任務(wù)運行費用,建議您根據(jù)業(yè)務(wù)需要自定義重試時間,或者在源和目標庫實例釋放后盡快釋放DTS實例。 - 可選:在已選擇對象區(qū)域框中,將鼠標指針放置在目標Topic名上,然后單擊Topic名后出現(xiàn)的編輯,在彈出的對話框中設(shè)置源表在目標Kafka集群中的Topic名稱、Topic的Partition數(shù)量、Partition Key等信息。
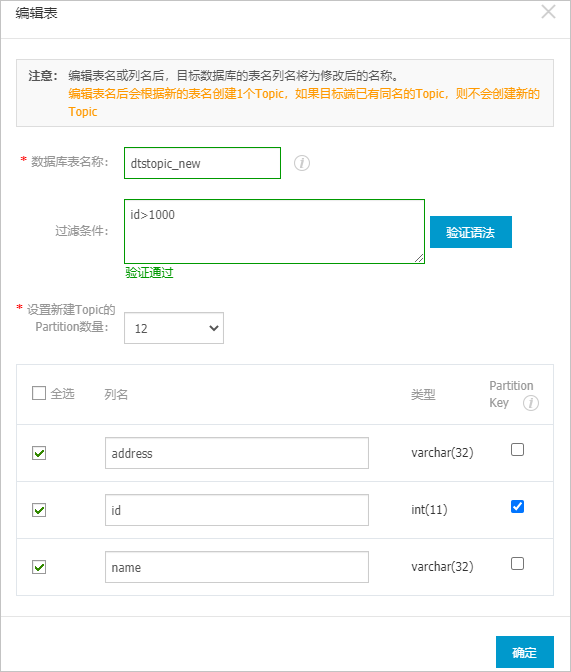
配置 說明 數(shù)據(jù)庫表名稱 設(shè)置源表同步到的目標Topic名稱。 說明 如果設(shè)置的Topic名稱在目標Kafka集群中不存在,您還需要設(shè)置該Topic的Partition數(shù)量。過濾條件 - 過濾條件支持標準的SQL WHERE語句(僅支持
=、!=、<和>操作符),只有滿足WHERE條件的數(shù)據(jù)才會被同步到目標Topic。本案例填入id>1000。 - 過濾條件中如需使用引號,請使用單引號('),例如
address in('hangzhou','shanghai')。
設(shè)置新Topic的Partition數(shù)量 在下拉列表中,選擇新Topic的Partition數(shù)量。 說明 只有當設(shè)置的目標Topic名稱在目標Kafka集群中不存在時,您才需要配置本參數(shù)。設(shè)置Partition Key 當您在步驟8中選擇同步策略為按主鍵的hash值投遞到不同Partition時,您可以配置本參數(shù),指定單個或多個列作為Partition Key來計算Hash值,DTS將根據(jù)計算得到的Hash值將不同的行投遞到目標Topic的各Partition中。 - 過濾條件支持標準的SQL WHERE語句(僅支持
- 上述配置完成后單擊頁面右下角的下一步。
- 配置同步初始化的高級配置信息。

配置 說明 同步初始化 默認選擇結(jié)構(gòu)初始化和全量數(shù)據(jù)初始化,DTS會在增量數(shù)據(jù)同步之前,將源庫中待同步對象的結(jié)構(gòu)和存量數(shù)據(jù),同步到目標庫。 過濾選項 默認選擇忽略增量同步階段的 DDL,即增量同步階段源庫執(zhí)行的DDL操作不會被DTS同步至目標庫。 - 上述配置完成后,單擊頁面右下角的預(yù)檢查并啟動。說明
- 在同步作業(yè)正式啟動之前,會先進行預(yù)檢查。只有預(yù)檢查通過后,才能成功啟動同步作業(yè)。
- 如果預(yù)檢查失敗,單擊具體檢查項后的
 ,查看失敗詳情。
,查看失敗詳情。- 您可以根據(jù)提示修復(fù)后重新進行預(yù)檢查。
- 如無需修復(fù)告警檢測項,您也可以選擇確認屏蔽、忽略告警項并重新進行預(yù)檢查,跳過告警檢測項重新進行預(yù)檢查。
- 在預(yù)檢查對話框中顯示預(yù)檢查通過后,關(guān)閉預(yù)檢查對話框,數(shù)據(jù)同步作業(yè)正式開始。您可以在數(shù)據(jù)同步頁面,查看數(shù)據(jù)同步狀態(tài)。
