部署及微調(diào)Mixtral-8x7B MoE模型
Mixtral-8x7B是Mistral AI最新發(fā)布的大語(yǔ)言模型,在許多基準(zhǔn)測(cè)試上表現(xiàn)優(yōu)于GPT-3.5,是當(dāng)前最為先進(jìn)的開(kāi)源大語(yǔ)言模型之一。PAI已對(duì)Mixtral-8x7B模型進(jìn)行全面支持,開(kāi)發(fā)者和企業(yè)用戶可以基于Model Gallery輕松完成對(duì)Mixtral-8x7B模型的微調(diào)和部署。
模型介紹
Mixtral-8x7B是基于編碼器(Decoder-Only)架構(gòu)的稀疏專家混合網(wǎng)絡(luò)(Sparse Mixture-of-Experts,SMoE)開(kāi)源大語(yǔ)言模型,使用Apache 2.0協(xié)議發(fā)布。它的獨(dú)特之處在于對(duì)于每個(gè)Token,路由器網(wǎng)絡(luò)選擇八組專家網(wǎng)絡(luò)中的兩組進(jìn)行處理,并且將其輸出累加組合,因此雖然Mixtral-8x7B擁有總共47B的參數(shù),但每個(gè)Token實(shí)際上只使用13B的活躍參數(shù),推理速度與參數(shù)規(guī)模為13B的模型相當(dāng)。
Mixtral-8x7B支持多種語(yǔ)言,包括法語(yǔ)、德語(yǔ)、西班牙語(yǔ)、意大利語(yǔ)和英語(yǔ),支持的上下文長(zhǎng)度為32 K 的Token,并且在所有的評(píng)估的基準(zhǔn)測(cè)試中均達(dá)到或優(yōu)于LLaMA2-70B和 GPT-3.5,特別是在數(shù)學(xué)、代碼生成和多語(yǔ)言基準(zhǔn)測(cè)試中,Mixtral大大優(yōu)于LLaMA2-70B。
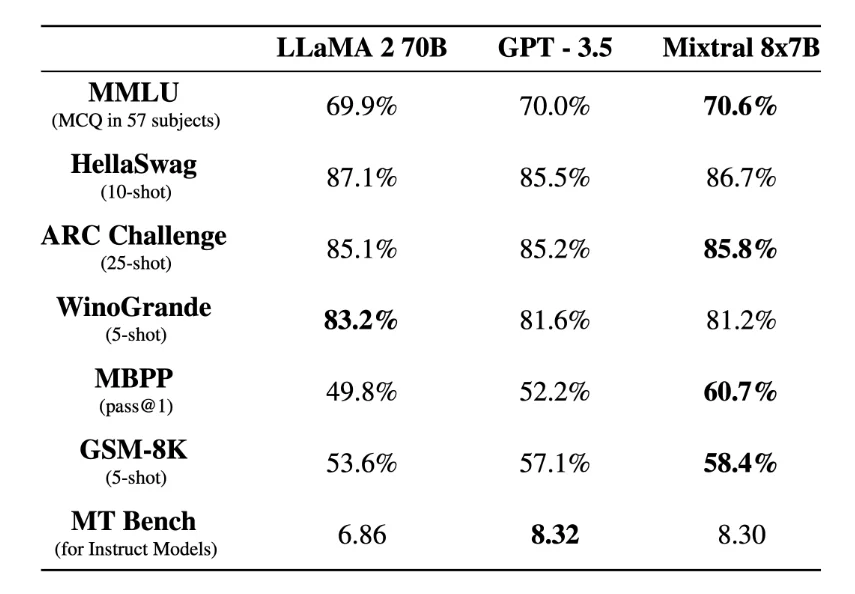
圖源:https://arxiv.org/abs/2401.04088
Mistral AI同時(shí)也發(fā)布了Mixtral-8x7B指令微調(diào)版本 Mixtral-8x7B-Instruct-v0.1,該版本通過(guò)監(jiān)督微調(diào)和直接偏好優(yōu)化算法(Direct Preference Optimization,DPO)進(jìn)行了優(yōu)化,以更好地遵循人類指令,對(duì)話能力領(lǐng)先于目前的其他開(kāi)源模型的指令微調(diào)版本。
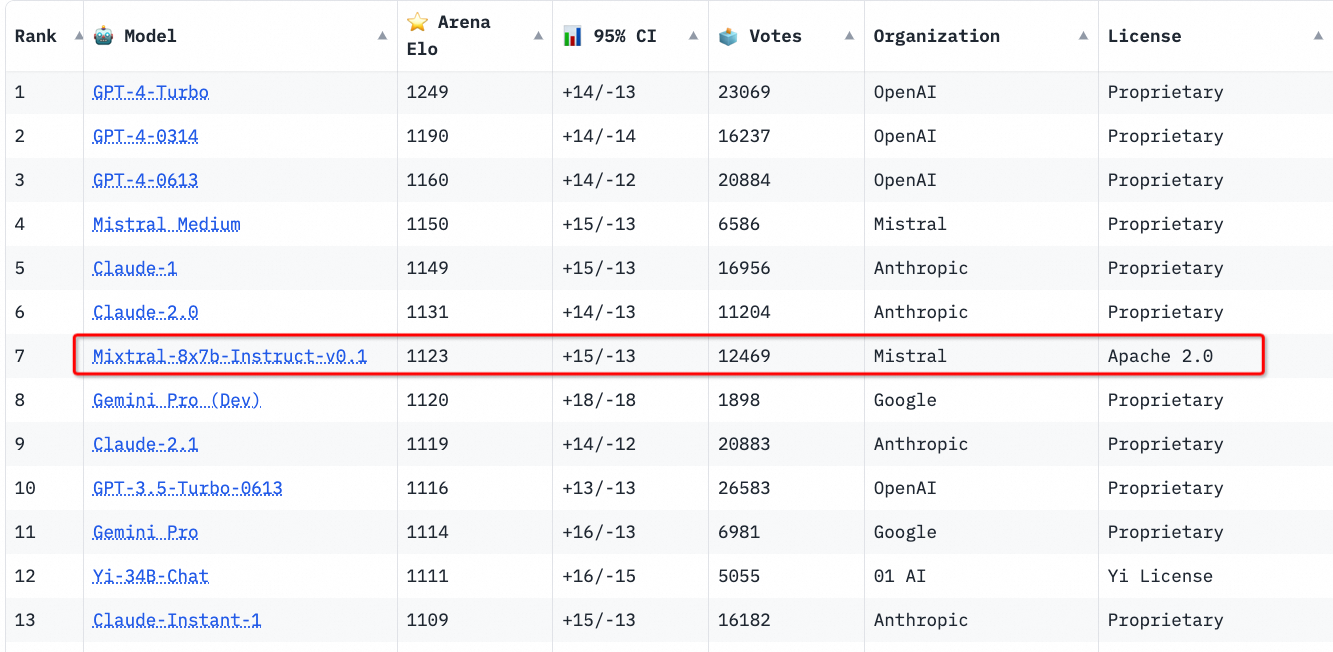
圖源:https://huggingface.co/spaces/lmsys/chatbot-arena-leaderboard
前提條件
已開(kāi)通靈駿智算資源,詳情請(qǐng)參見(jiàn)新建資源組并購(gòu)買(mǎi)靈駿智算資源。
運(yùn)行環(huán)境要求
由于模型本身較大,本示例目前僅支持在華北6(烏蘭察布)使用PAI靈駿集群環(huán)境運(yùn)行。
資源配置要求:GPU 推薦使用GU108(80 GB顯存),推理需要2卡及以上資源,LoRA微調(diào)需要4卡及以上資源。
通過(guò)PAI控制臺(tái)使用模型
模型部署和調(diào)用
進(jìn)入Model Gallery頁(yè)面。
登錄PAI控制臺(tái)。
選擇目標(biāo)地域?yàn)?b>華北6(烏蘭察布)。
在左側(cè)導(dǎo)航欄單擊工作空間列表,在工作空間列表頁(yè)面中單擊待操作的工作空間名稱,進(jìn)入對(duì)應(yīng)工作空間內(nèi)。
在左側(cè)導(dǎo)航欄單擊快速開(kāi)始 > Model Gallery,進(jìn)入Model Gallery頁(yè)面。
在Model Gallery頁(yè)面右側(cè)的模型列表中,單擊Mixtral-8x7B-Instruct-v0.1模型卡片,進(jìn)入模型詳情頁(yè)面。
單擊右上角模型部署,配置靈駿計(jì)算資源,單擊部署,即可將模型部署到EAS推理服務(wù)平臺(tái)。
當(dāng)前模型需要使用靈駿智算資源進(jìn)行部署,請(qǐng)確保選擇的資源配額(Quota)中至少有2張GU108 GPU卡的計(jì)算資源。
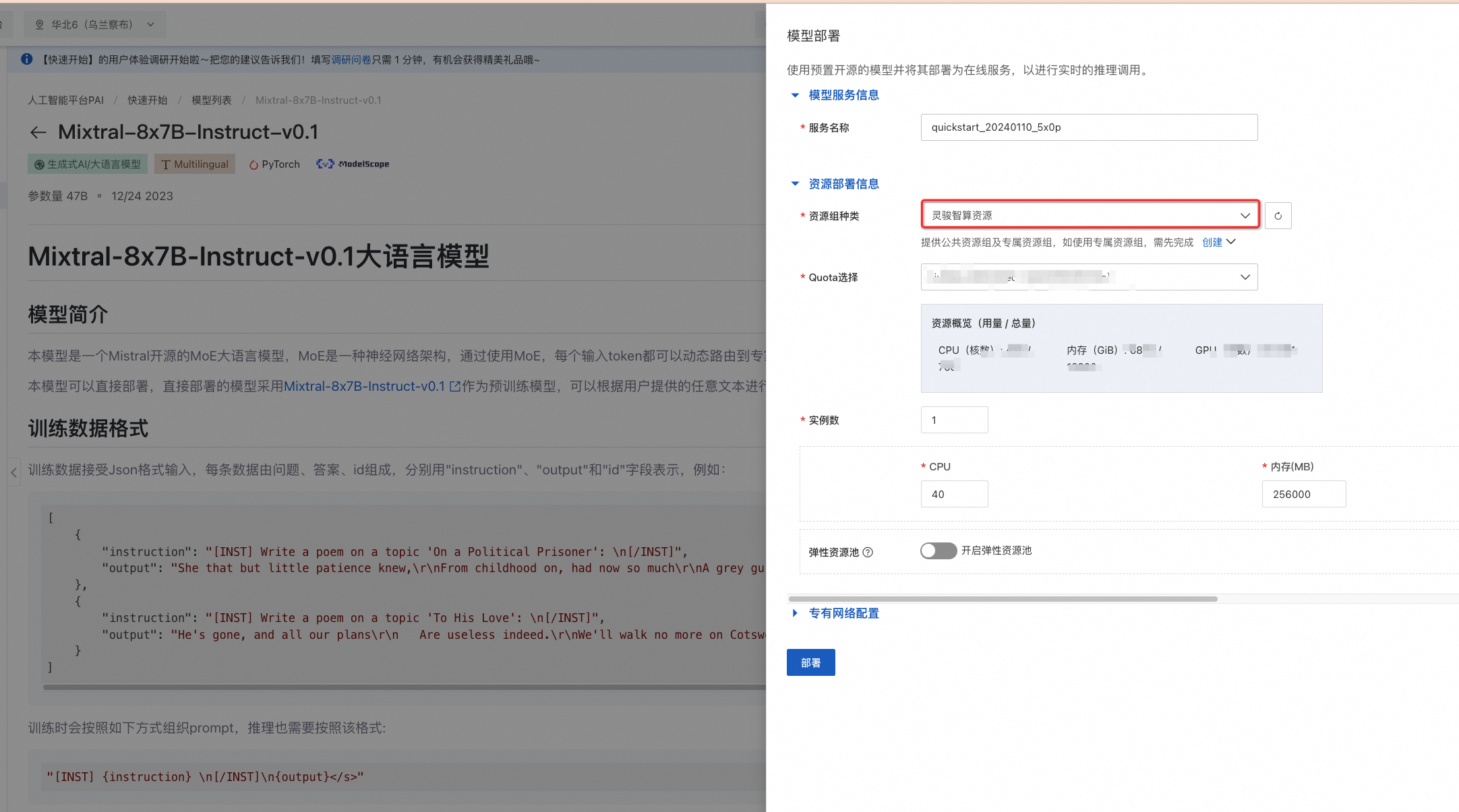
調(diào)用推理服務(wù)。
通過(guò)HTTP API調(diào)用
部署的推理服務(wù)支持OpenAI的API風(fēng)格進(jìn)行調(diào)用,通過(guò)部署的在線服務(wù)的詳情頁(yè),您可以獲得服務(wù)訪問(wèn)地址(Endpoint)和訪問(wèn)憑證(Token)。使用CURL調(diào)用推理服務(wù)的示例如下:
# 請(qǐng)注意替換為使用服務(wù)的Endpoint和Token export API_ENDPOINT="<ENDPOINT>" export API_TOKEN="<TOKEN>" # 查看模型list curl $API_ENDPOINT/v1/models \ -H "Content-Type: application/json" \ -H "Authorization: Bearer $API_TOKEN" # 調(diào)用通用的文本生成API curl $API_ENDPOINT/v1/completions \ -H "Content-Type: application/json" \ -H "Authorization: Bearer $API_TOKEN" \ -d '{ "model": "Mixtral-8x7B-Instruct-v0.1", "prompt": "San Francisco is a", "max_tokens": 256, "temperature": 0 }' curl $API_ENDPOINT/v1/chat/completions \ -H "Authorization: Bearer $API_TOKEN" \ -H "Content-Type: application/json" \ -d '{ "model": "Mixtral-8x7B-Instruct-v0.1", "messages": [ {"role": "user", "content": "介紹一下上海的歷史"} ] }'通過(guò)SDK調(diào)用
通過(guò)OpenAI的SDK進(jìn)行調(diào)用時(shí),首先需要安裝SDK:
# 安裝服務(wù)調(diào)用SDK python -m pip install openai通過(guò)SDK調(diào)用推理服務(wù)的示例代碼如下:
import openai # 請(qǐng)使用服務(wù)詳情頁(yè)獲取的訪問(wèn)地址(ENDPOINT)和訪問(wèn)憑證(TOKEN)替換以下代碼的配置。 openai.api_key = "<TOKEN>" openai.base_url = "<ENDPOINT>" + "/v1" # 調(diào)用對(duì)話API completion = openai.chat.completions.create( model="Mixtral-8x7B-Instruct-v0.1", temperature=0.0, top_p=0.8, frequency_penalty=0.0, messages=[{"role": "user", "content": "請(qǐng)介紹下你自己。"}], # stream=True, ) # 打印輸出內(nèi)容 print(completion.choices[0].message.content)
模型微調(diào)訓(xùn)練
PAI-Model Gallery為Mixtral-8x7B-Instruct-v0.1模型配置了微調(diào)算法,您可以通過(guò)開(kāi)箱即用的方式對(duì)Mixtral-8x7B-Instruct-v0.1進(jìn)行微調(diào)。
訓(xùn)練算法支持使用JSON格式輸入,每條數(shù)據(jù)由問(wèn)題、答案組成,分別用"instruction"、"output"字段表示,例如:
[
{
"instruction": "Write a poem on a topic 'On a Political Prisoner': \n",
"output": "She that but little patience knew,\r\nFrom childhood on, had now so much\r\nA grey gull lost its fear and flew\r\nDown to her cell and there alit,\r\nAnd there endured her fingers' touch\r\nAnd from her fingers ate its bit.\r\nDid she in touching that lone wing."
},
{
"instruction": "Write a poem on a topic 'To His Love': ",
"output": "He's gone, and all our plans\r\n Are useless indeed.\r\nWe'll walk no more on Cotswold\r\n Where the sheep feed\r\n Quietly and take no heed.\r\n His body that was so quick\r\n Is not as you\r\nKnew it, on Severn river\r\n Under the blue\r\n Driving our small boat through."
}
]在模型詳情頁(yè)單擊右上角訓(xùn)練。關(guān)鍵配置如下:
數(shù)據(jù)集配置:當(dāng)完成數(shù)據(jù)的準(zhǔn)備,您可以將數(shù)據(jù)上傳到對(duì)象存儲(chǔ)OSS Bucket中,或是通過(guò)指定一個(gè)數(shù)據(jù)集對(duì)象,選擇NAS或CPFS存儲(chǔ)上的數(shù)據(jù)集。您也可以使用PAI預(yù)置的公共數(shù)據(jù)集,直接提交任務(wù)測(cè)試算法。
計(jì)算資源配置:算法需要使用4張GU108(80 GB顯存)的GPU資源,請(qǐng)確保選擇使用的資源配額內(nèi)有充足的計(jì)算資源。
超參數(shù)配置:訓(xùn)練算法支持的超參信息如下,您可以根據(jù)使用的數(shù)據(jù),計(jì)算資源等調(diào)整超參,或是使用算法默認(rèn)配置的超參。
超參數(shù)
類型
默認(rèn)值
是否必須
描述
learning_rate
Float
1e-05
是
學(xué)習(xí)率,用于控制模型權(quán)重,調(diào)整幅度。
num_train_epochs
Int
5
是
訓(xùn)練數(shù)據(jù)集被重復(fù)使用的次數(shù)。
per_device_train_batch_size
Int
4
是
每個(gè)GPU在一次訓(xùn)練迭代中處理的樣本數(shù)量。較大的批次大小可以提高效率,也會(huì)增加顯存的需求。
lora_dim
Int
16
否
LoRA維度,控制LoRA模型使用的低秩矩陣的維度大小。
lora_alpha
Int
32
否
配置低秩矩陣插值的強(qiáng)度。
gradient_accumulation_steps
Int
1
否
梯度累積步驟數(shù)。
單擊訓(xùn)練,PAI-Model Gallery自動(dòng)跳轉(zhuǎn)到模型訓(xùn)練頁(yè)面,并開(kāi)始進(jìn)行訓(xùn)練,您可以查看訓(xùn)練任務(wù)狀態(tài)和訓(xùn)練日志。
單擊右上角Tensorboard,您也可以一鍵打開(kāi)TensorBoard查看模型的收斂情況。
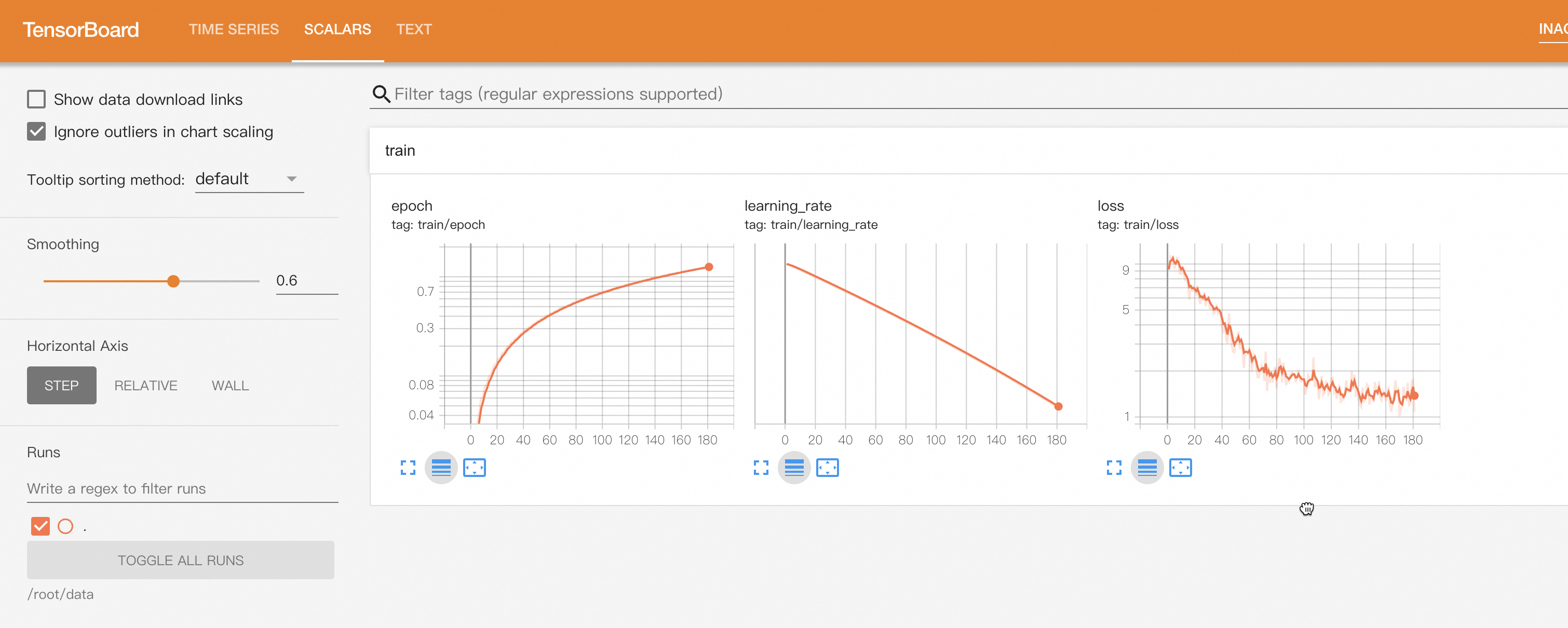
訓(xùn)練好的模型會(huì)自動(dòng)注冊(cè)到AI資產(chǎn)-模型管理中,您可以查看或部署對(duì)應(yīng)的模型,詳情請(qǐng)參見(jiàn)注冊(cè)及管理模型。
通過(guò)PAI Python SDK使用模型
PAI-Model Gallery提供的預(yù)訓(xùn)練模型也支持通過(guò)PAI Python SDK進(jìn)行調(diào)用,首先需要安裝和配置PAI Python SDK,您可以在命令行執(zhí)行以下代碼:
# 安裝PAI Python SDK
python -m pip install alipai --upgrade
# 交互式的配置訪問(wèn)憑證、PAI工作空間等信息
python -m pai.toolkit.config
如何獲取SDK配置所需的訪問(wèn)憑證(AccessKey)、PAI工作空間等信息請(qǐng)參考安裝和配置。
模型部署和調(diào)用
通過(guò)PAI-Model Gallery在模型上預(yù)置的推理服務(wù)配置,您只需提供使用的資源信息以及服務(wù)名稱,即可輕松的將Mixtral模型部署到PAI-EAS推理平臺(tái)。
from pai.session import get_default_session
from pai.model import RegisteredModel
from pai.common.utils import random_str
from pai.predictor import Predictor
session = get_default_session()
# 獲取PAI QuickStart 提供的模型
m = RegisteredModel(
model_name="Mixtral-8x7B-Instruct-v0.1",
model_provider="pai",
)
# 查看模型默認(rèn)的部署配置
print(m.inference_spec)
# 部署推理服務(wù)
# 需提供使用靈駿資源配額ID(QuotaId),要求至少 >= 2張GU108(80G顯存)GPU卡的計(jì)算資源.
predictor = m.deploy(
service_name="mixtral_8_7b_{}".format(random_str(6)),
options={
# 資源配額ID
"metadata.quota_id": "<LingJunResourceQuotaId>",
"metadata.quota_type": "Lingjun",
"metadata.workspace_id": session.workspace_id,
}
)
# 獲取推理服務(wù)的Endpoint和Token
endpoint = predictor.internet_endpoint
token = predictor.access_token
推理服務(wù)的調(diào)用請(qǐng)參見(jiàn)上述調(diào)用推理服務(wù),或是直接使用PAI Python SDK進(jìn)行調(diào)用。
from pai.predictor import Predictor
p = Predictor("<MixtralServiceName>")
res = p.raw_predict(
path="/v1/chat/completions",
method="POST",
data={
"model": "Mixtral-8x7B-Instruct-v0.1",
"messages": [
{"role": "user", "content": "介紹一下上海的歷史"}
]
}
)
print(res.json())
當(dāng)測(cè)試完成,需要?jiǎng)h除服務(wù)釋放資源,您可以通過(guò)控制臺(tái)或SDK完成。
# 刪除服務(wù)
predictor.delete_service()模型的微調(diào)訓(xùn)練
通過(guò)SDK獲取PAI-Model Gallery提供的預(yù)訓(xùn)練模型之后,您可以查看模型配置的微調(diào)算法,包括算法支持的超參配置以及輸入輸出數(shù)據(jù)。
from pai.model import RegisteredModel
# 獲取PAI QuickStart 提供的 Mixtral-8x7B-Instruct-v0.1 模型
m = RegisteredModel(
model_name="Mixtral-8x7B-Instruct-v0.1",
model_provider="pai",
)
# 獲取模型配置的微調(diào)算法
est = m.get_estimator()
# 查看算法支持的超參,以及算法輸入輸出信息
print(est.hyperparameter_definitions)
print(est.input_channel_definitions)
目前,Mixtral-8x7B-Instruct-v0.1提供的微調(diào)算法僅支持使用靈駿智算資源,您需要通過(guò)PAI的控制臺(tái)頁(yè)面查看當(dāng)前的資源配額ID,設(shè)置訓(xùn)練任務(wù)使用的資源信息。同時(shí)在提交訓(xùn)練作業(yè)之前,您可以根據(jù)算法的超參支持,配置合適的訓(xùn)練任務(wù)超參。
# 配置訓(xùn)練作業(yè)使用的靈駿資源配額ID
est.resource_id = "<LingjunResourceQuotaId>"
# 配置訓(xùn)練作業(yè)超參
hps = {
"learning_rate": 1e-5,
"per_device_train_batch_size": 2,
}
est.set_hyperparameters(**hps)
微調(diào)算法支持3個(gè)輸入,分別為:
model:預(yù)訓(xùn)練模型Mixtral-8x7B-Instruct-v0.1。train:微調(diào)使用的訓(xùn)練數(shù)據(jù)集。validation:微調(diào)使用的驗(yàn)證數(shù)據(jù)集。
數(shù)據(jù)集的格式請(qǐng)參見(jiàn)上述模型微調(diào)訓(xùn)練,您可以通過(guò)ossutils、控制臺(tái)操作等方式上傳數(shù)據(jù)到OSS Bucket,也可以使用SDK提供的方法上傳到您配置的OSS Bucket。
from pai.common.oss_utils import upload
# 查看模型微調(diào)算法的使用的輸入信息
# 獲取算法的輸入數(shù)據(jù),包括模型和供測(cè)試的公共讀數(shù)據(jù)集.
training_inputs = m.get_estimator_inputs()
print(training_inputs)
# {
# "model": "oss://pai-quickstart-cn-wulanchabu.oss-cn-wulanchabu-internal.aliyuncs.com/huggingface/models/Mixtral-8x7B-Instruct-v0.1/main/",
# "train": "oss://pai-quickstart-cn-wulanchabu.oss-cn-wulanchabu-internal.aliyuncs.com/huggingface/datasets/llm_instruct/en_poetry_train_mixtral.json",
# "validation": "oss://pai-quickstart-cn-wulanchabu.oss-cn-wulanchabu-internal.aliyuncs.com/huggingface/datasets/llm_instruct/en_poetry_test_mixtral.json",
# }
# 上傳用戶數(shù)據(jù),請(qǐng)注意替換一下的本地文件路徑和上傳的OSS Bucket路徑.
train_data_uri = upload("/path/to/local/train.json", "path/of/train/data")
validation_data_uri = upload("/path/to/local/validation.json", "path/of/validation/data")
# 替換使用開(kāi)發(fā)者的訓(xùn)練數(shù)據(jù)
# training_inputs["train"] = train_data_uri
# training_inputs["validation"] = validation_data_uri
您可以參考以上的訓(xùn)練數(shù)據(jù)格式準(zhǔn)備數(shù)據(jù),然后將train和validation輸入替換為自己的訓(xùn)練和驗(yàn)證數(shù)據(jù)集,即可輕松得提交模型微調(diào)訓(xùn)練作業(yè)。通過(guò)SDK打印的訓(xùn)練作業(yè)鏈接,您可以在PAI的控制臺(tái)上查看訓(xùn)練任務(wù)狀態(tài)以及日志信息,同時(shí)也可以通過(guò)Tensorboard 查看訓(xùn)練作業(yè)的進(jìn)度和模型收斂情況。
from pai.common.oss_utils import download
# 提交訓(xùn)練作業(yè),同時(shí)打印訓(xùn)練作業(yè)鏈接
est.fit(
inputs=training_inputs,
wait=False,
)
# 打開(kāi)TensorBoard查看訓(xùn)練進(jìn)度
est.tensorboard()
# 等待訓(xùn)練任務(wù)結(jié)束
est.wait()
# 查看保存在OSS Bucket上的模型路徑
print(est.model_data())
# 用戶可以通過(guò)ossutils,或是SDK提供的便利方法下載相應(yīng)的模型到本地
download(est.model_data())
更多關(guān)于如何通過(guò)SDK使用PAI-Model Gallery提供的預(yù)訓(xùn)練模型,請(qǐng)參見(jiàn)使用預(yù)訓(xùn)練模型 — PAI Python SDK。