特征數據庫(下文簡稱FeatureDB)是阿里云PAI平臺下特征平臺(PAI-FeatureStore)提供的數據庫服務,可以作為FeatureStore的在線數據源,提供在線特征存儲功能,并為搜索推薦廣告等服務提供高性能的讀寫優化。本文為您介紹什么是FeatureDB,以及FeatureDB的功能與優勢。
什么是FeatureDB
FeatureDB是FeatureStore提供的高性能分布式存儲數據庫,支持KV、KKV格式的數據,并支持以結構化的方式將數組存儲為Array,將KV存儲為Map類型。通過Array、Map類型存儲數據,可以為后續的讀寫、推理服務提供更高的性能。FeatureDB已經全面支持離線特征和實時特征的生產、更新與消費鏈路,同時也支持用戶行為序列特征。
產品特性
FeatureDB針對FeatureStore特征讀取特性實現了如下功能和優化:
支持讀寫KV、KKV類型特征。
支持讀寫MaxCompute復雜類型特征(Array、Map)。
支持全量拉取FeatureView下的所有特征數據。
支持毫秒級輪詢更新實時特征數據。
支持秒級TTL,自動清理過期數據。
按量計費,根據實際讀寫數據量進行計費。
FeatureDB可以對FeatureView的數據進行分片存儲,通過調整分片數來滿足不同場景的讀寫性能需求,并且支持副本,以保障數據的穩定與安全。其中,分片數量可以根據特征存儲的數據量進行調整:
5分片(默認):適用于千萬級以下的數據量。
10分片:適用于千萬級以上、億級以下的數據量。
20分片:適用于億級以上的數據量。

產品優勢
高性價比
對于特征存儲規模較小的客戶,使用FeatureDB可以降低使用成本。
滿足高頻更新需求
當使用實時統計特征時,需每隔幾秒及時更新實時特征到多個EasyRec Processor(模型推理服務)實例的存儲中,這對高頻更新有較高的要求,FeatureDB可以滿足這一需求。
支持復雜類型特征
在搜索推廣業務中,Array和Map類型的特征、用戶行為長序列特征及其SideInfo被廣泛使用。如果復雜類型特征以字符串形式存儲,在應用時需要進行序列化為Map類型,會降低性能。
FeatureDB支持存儲復雜類型數據,并支持同步MaxCompute2.0復雜類型數據到FeatureDB,進行高性能讀取操作。
支持彈性擴容
對于規模較大的客戶,能夠根據特征視圖靈活增加分片數量,提高讀寫性能。
解決監控盲點
當集成第三方數據源時,整個數據鏈路的監控變得困難,特別是在實時特征方面。FeatureDB能夠監控每個視圖粒度的讀寫QPS、RT、數據更新延時和存儲用量等關鍵性能指標。
產品功能
配置FeatureDB數據源
具體操作,請參見配置數據源。
寫入特征
對于離線特征,可以使用FeatureStore Python SDK通過DataWorks每天例行運行調度任務,將MaxCompute里的數據同步到FeatureDB中。
對于實時特征,目前可通過以下兩種方式同步數據。
方式一:直接通過Java SDK寫入特征數據。
// 配置 regionId, 阿里云賬號, FeatureStore project Configuration configuration = new Configuration("cn-beijing", Constants.accessId, Constants.accessKey,"fs_demo_featuredb" ); // 配置 FeatureDB 用戶名,密碼 configuration.setUsername(Constants.username); configuration.setPassword(Constants.password); // 如果使用公網鏈接 FeatureStore, 參考上面的域名信息 // 如果使用 VPC 環境,不需要設置 //configuration.setDomain(Constants.host); ApiClient client = new ApiClient(configuration); // 如果使用公網鏈接 設置 usePublicAddress = true, vpc 環境不需要設置 // FeatureStoreClient featureStoreClient = new FeatureStoreClient(client, Constants.usePublicAddress); FeatureStoreClient featureStoreClient = new FeatureStoreClient(client ); Project project = featureStoreClient.getProject("fs_demo_featuredb"); if (null == project) { throw new RuntimeException("project not found"); } FeatureView featureView = project.getFeatureView("user_test_2"); if (null == featureView) { throw new RuntimeException("featureview not found"); } List<Map<String, Object>> writeData = new ArrayList<>(); // 模擬構造數據寫入 for (int i = 0; i < 10; i++) { Map<String, Object> data = new HashMap<>(); data.put("user_id", i); data.put("string_field", String.format("test_%d", i)); data.put("int32_field", i); data.put("int64_field", Long.valueOf(i)); data.put("float_field", Float.valueOf(i)); data.put("double_field", Double.valueOf(i)); data.put("boolean_field", i % 2 == 0); writeData.add(data); } for (int i = 0; i < 100;i++) { featureView.writeFeatures(writeData); } // 這里只需要調用一次,如果全部數據寫完,確保全部寫入完成,調用此接口后,無法再調用 writeFeatures featureView.writeFlush();方式二:使用實時計算Flink生產實時特征,通過配置Flink Connector寫入。具體操作,請參見設置Flink Connector。
對于實時特征寫入,默認我們會進行整行數據更新。如果寫入數據只包含了部分字段,對于未寫入的字段我們會將其設置為空。如果想要只更新寫入字段的數據,并將其合并到原有數據上,您可以進行如下設置:
通過Java SDK寫入:指定 InsertMode 寫入模式,設置為 InsertMode.PartialFieldWrite。
for (int i = 0; i < 100;i++) { featureView.writeFeatures(writeData, InsertMode.PartialFieldWrite); }通過配置Flink Connector寫入:設置參數 insert_mode 值為 partial_field_write。
讀取特征
您可以使用FeatureStore SDK(Go/Java)或EasyRec Processor讀取特征。
FeatureStore SDK(Go/Java )支持離線/實時特征的KV點查。通過指定特征的JoinID(主鍵)值與特征名稱,即可在毫秒內完成鍵值對(KV)查詢,獲取目標特征數據。FeatureStore SDK(Go/Java)也支持行為序列特征的KKV查詢。通過指定UserID(用戶ID)值,即可查詢到拼裝好的序列特征結果。
EasyRec Processor已集成FeatureStore Cpp SDK,支持將FeatureDB的特征數據全量拉入內存,并支持毫秒級輪詢更新實時特征數據到內存,從而實現更高性能的讀取。
監控指標
如果使用FeatureDB作為在線數據源,創建特征視圖后,單擊目標視圖右側的數據監控,可查看該視圖的讀寫QPS和RT等指標。
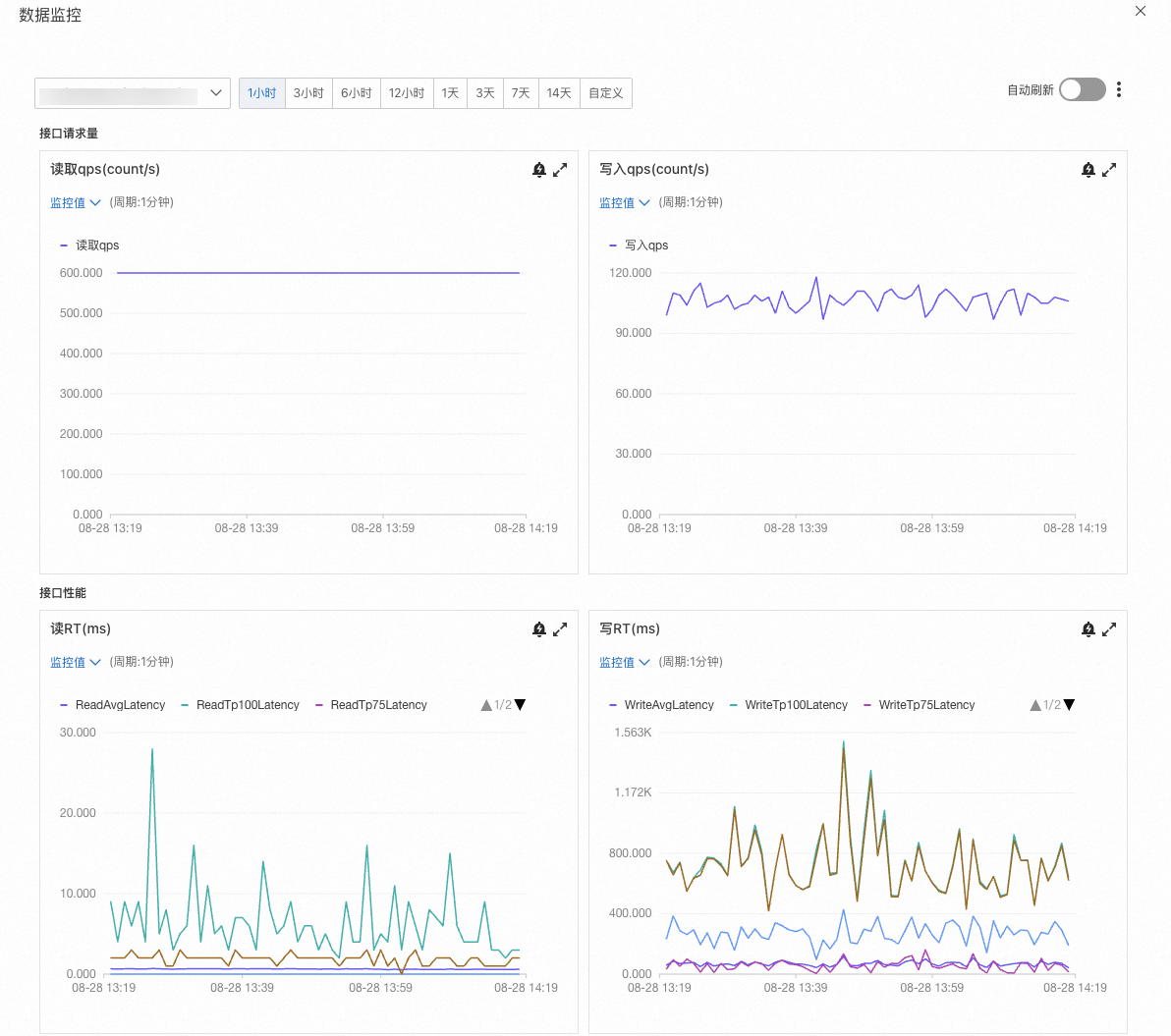
實時特征鏈路

FeatureStore提供的存儲服務主要包括三部分:Feature Service(接入層)、消息隊列(DataHub)和FeatureDB。
在實時特征中,用戶可以通過FeatureStore Java SDK或Flink Connector調用Feature Service服務,將特征數據寫入FeatureDB。通過Feature Service寫入的數據,也會同步到用戶的MaxCompute表中,可以用于實時特征的樣本導出,進一步的模型訓練。
對于存儲在FeatureDB中的特征數據, 用戶可以通過FeatureStore的Java/Go SDK讀取,也可以通過 EasyRec Processor全量拉取特征存入本地緩存中,以實現更高性能的讀取。對于實時特征,可以毫秒級獲取最新特征信息。
實時特征數據生命周期設置
在創建實時特征視圖時,可以通過特征生命周期來設置FeatureDB表的數據生命周期。當一行數據的生存時間到達生命周期后,它會在幾秒內被自動清理。
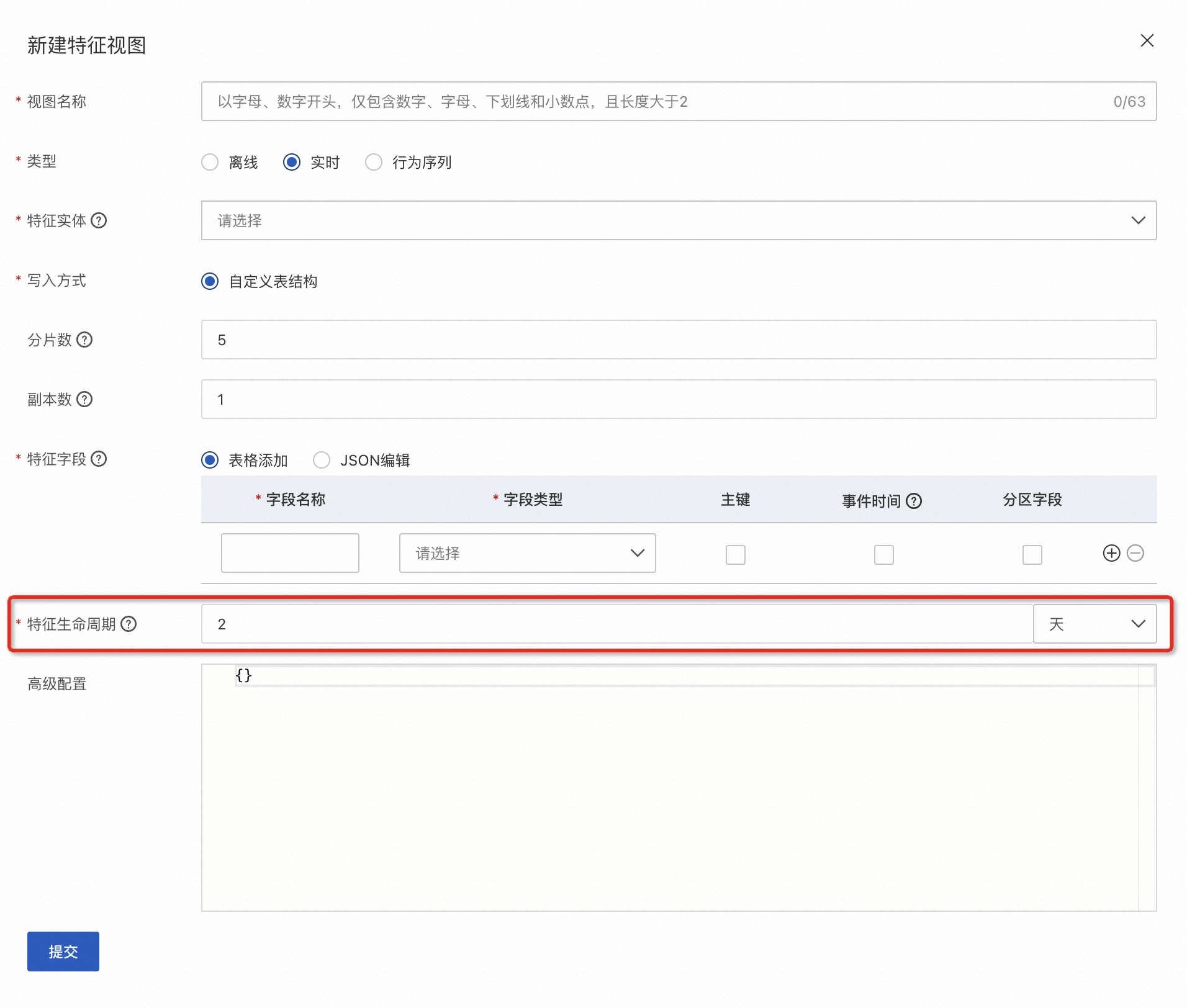
數據的生存時間目前支持兩種設置方式:
方式一:不設置事件時間字段。這種情況下,會根據數據的寫入時間開始計算生存時間,到達生命周期后,自動清理數據。
方式二:勾選了某個特征字段作為事件時間字段,單位是毫秒。假設 event_time 為事件時間字段的值, time_now 為現在的時間,time_ttl = time_now - ttl 為應該開始過期的 event_time 的值,這種情況下對于寫入的特征數據的具體處理方式如下:
如果使用 PartialFieldWrite 模式進行部分字段更新寫入,則會根據數據實際寫入時間計算生存時間。
event_time > time_now + 15min:數據不寫入。(這里防止不同系統之間時間戳有差異,放寬15分鐘)
time_ttl < event_time <= time_now + 15min:數據正常寫入,根據 event_time 開始計算生存時間,到達生命周期后,自動清理這行數據。
0 < event_time < time_ttl:數據寫入后會被自動清理。這里需要注意的是,event_time的單位是毫秒。如果您的事件時間字段的值是秒,那么會落入這種情況,導致數據寫入不成功。
event_time <= 0:根據數據實際寫入時間計算生存時間。
值非法(無法轉換成整型):數據不寫入。
注冊了事件時間字段但是沒有傳入事件時間字段的值:數據正常寫入,根據數據實際寫入時間計算生存時間。
不注冊事件時間字段:數據正常寫入,根據數據實際寫入時間計算生存時間。
另外,在FeatureDB中,我們會將 event_time 的值作為這行數據的ts,意味著如果需要更新一個 key 對應的數據,需要事件時間字段的值比之前的值大,這行數據才會更新。如果新的 event_time <= 原來 event_time 的值,則不會更新這個key對應的數據。
性能測試
以下是使用FeatureStore SDK讀取FeatureDB特征的性能壓測示例,特征表數據選取的推薦情景中user側數據,總數據行數是8671932,數據僅供參考。
在線數據源 | 特征字段數量(列數) | 讀取keys數量(行數) | 平均耗時 | TP99 |
FeatureDB | 260 | 1 | 3.25毫秒 | 4.34毫秒 |
FeatureDB | 260 | 10 | 3.52毫秒 | 4.62毫秒 |
FeatureDB | 260 | 50 | 4.51毫秒 | 6.05毫秒 |
FeatureDB | 260 | 200 | 8.23毫秒 | 10.52毫秒 |
FeatureDB | 260 | 500 | 12.96毫秒 | 16.55毫秒 |
FeatureDB | 260 | 1000 | 17.61毫秒 | 21.26毫秒 |