AutoML是PAI提供的機器學習增強型服務,集成了多種算法和分布式計算資源,無需編寫代碼,通過創建實驗即可實現模型超參數調優,提高機器學習效率和性能。本文為您介紹如何新建實驗。
背景信息
AutoML的工作機制:
實驗會根據算法配置自動生成超參數組合。針對每組超參數組合,該實驗會創建一個Trial。同時,每個Trial可能會對應一個DLC任務,也可能對應1個或多個MaxCompute任務。任務的類型取決于實驗的執行配置。后續將通過配置的任務來執行Trial。實驗通過調度運行多個Trial,并比較這些Trial的結果,以找到較優的超參數組合。更詳細的原理介紹,請參見AutoML工作原理。
前提條件
首次使用AutoML功能時,需要完成AutoML相關權限授權。具體操作,請參見云產品依賴與授權:AutoML。
已創建工作空間,具體操作,請參見創建工作空間。
如果創建DLC任務,需要完成以下準備工作:
已完成DLC相關權限授權,授權方法詳情請參見云產品依賴與授權:DLC。
已準備資源組。準備通用計算資源公共資源組和專有資源組,請參見新建資源組并購買通用計算資源。準備靈駿智算資源專有資源組,請參見靈駿智算資源配額。
如果創建MaxCompute任務,則需要準備MaxCompute資源,并關聯到了工作空間。具體操作,請參見MaxCompute資源配額。
操作步驟
進入自動機器學習(AutoML)頁面。
登錄PAI控制臺。
在左側導航欄單擊工作空間列表,在工作空間列表頁面中單擊待操作的工作空間名稱,進入對應工作空間內。
在左側導航欄,選擇。
在實驗列表頁面,單擊新建實驗。
在新建實驗頁面,配置如下參數。
基本信息配置。
參數
描述
名稱
參考界面提示信息配置實驗名稱。
描述
對創建的實驗進行簡單描述,以區分不同的實驗。
可見范圍
實驗的可見性,支持以下取值:
僅自己可見:在工作空間中,僅對您和管理員可見。
工作空間內公開可見:在工作空間中,對所有人可見。
執行配置。
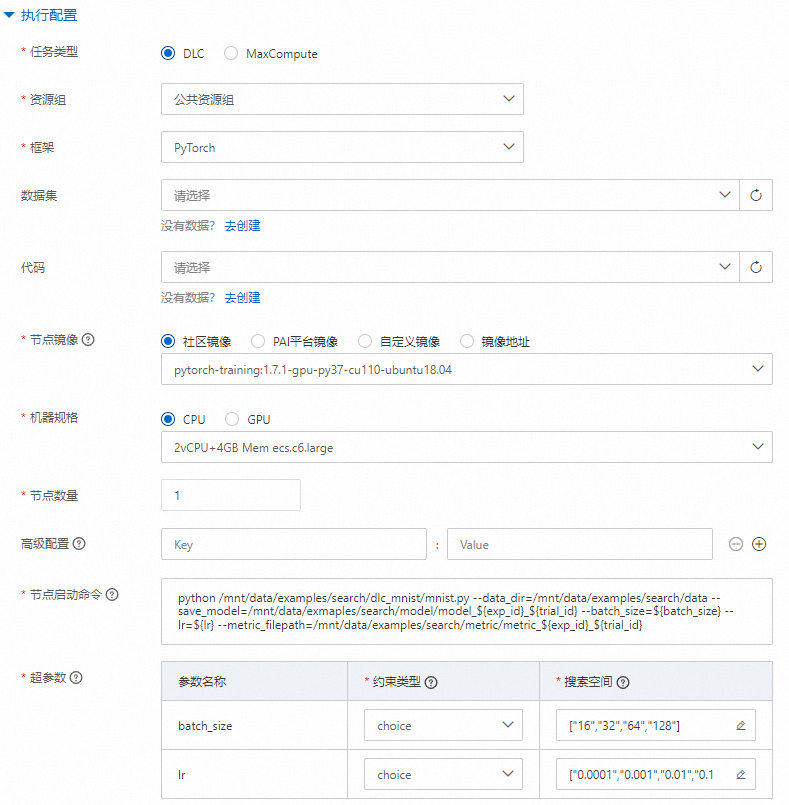
任務類型:是Trial的執行環境,支持選擇DLC和MaxCompute。
DLC:表示通過運行分布式訓練(DLC)任務,進行超參數調優。更多關于DLC任務的介紹,請參見創建訓練任務。
MaxCompute:表示在MaxCompute計算資源上,運行SQL命令或Designer算法組件的PAI命令,進行超參數調優。更多關于Designer算法組件以及每個組件支持的PAI命令的詳細信息,請參見組件參考:所有組件匯總。
DLC
任務類型選擇DLC時,參數配置如下表所示:
參數
描述
框架
支持選擇以下兩種框架類型:
Tensorflow
PyTorch
數據集
此處需配置為已準備好的數據集,數據集配置方式請參見創建及管理數據集。
代碼源
指定任務代碼文件的存儲位置(代碼倉庫信息)。此處需配置為已準備好的代碼配置,配置方式請參見代碼配置。
說明由于DLC會將代碼下載至指定工作路徑,所以您需要有代碼倉庫的訪問權限。
資源組
選擇公共資源組或已購買的專有資源組。如何準備資源組,請參見新建資源組并購買通用計算資源和靈駿智算資源配額。
機器規格
選擇任務運行所需的實例規格。不同規格的實例價格有所不同,關于各個規格的計費詳情,請參見DLC計費說明。
節點鏡像
工作節點的鏡像。當前支持選擇使用不同類型的鏡像:
節點數量
在DLC任務中所使用的計算節點的數量。
重要如果選擇配置多個節點,則每個節點都會獨立收取費用,而不是共享同一個機器規格。因此,在節點選擇過程中,您需要明確每個節點的費用,并綜合考慮成本和性能之間的平衡。
CPU(核數)
當資源組選擇已購買的專有資源組時,您可以根據購買的資源規格來配置這些參數。
內存(GB)
共享內存(GB)
GPU(卡數)
高級配置
支持通過高級配置提高訓練靈活性,或滿足一些特定的訓練場景。當框架選擇Pytorch時,您可以配置高級參數。支持的高級參數列表及取值說明,請參見附錄1:高級參數列表。
節點啟動命令
各個節點的啟動命令。您需要在命令中配置超參數變量
${自定義超參數變量},例如:python /mnt/data/examples/search/dlc_mnist/mnist.py --data_dir=/mnt/data/examples/search/data --save_model=/mnt/data/exmaples/search/model/model_${exp_id}_${trial_id} --batch_size=${batch_size} --lr=${lr} --metric_filepath=/mnt/data/examples/search/metric/metric_${exp_id}_${trial_id}其中:
${batch_size}和${lr}為定義的超參數變量。超參數
根據啟動命令中配置的超參數變量,自動加載超參數列表。您需要為每個超參數配置約束類型和搜索空間:
約束類型:為超參數添加的限制條件。您可以將鼠標懸停在約束類型后的
 圖標上,以查看支持選擇的約束類型及相關說明。
圖標上,以查看支持選擇的約束類型及相關說明。搜索空間:用于指定超參數的取值范圍。每種約束類型對應的搜索空間的配置方式不同,您可以單擊
 圖標并根據界面提示進行添加。
圖標并根據界面提示進行添加。
MaxCompute
任務類型選擇MaxCompute時,參數配置如下表所示:
參數
描述
命令
配置為SQL命令或運行Designer算法組件的PAI命令。您需要在命令中配置超參數變量
${自定義超參數變量},例如:pai -name kmeans -project algo_public -DinputTableName=pai_kmeans_test_input -DselectedColNames=f0,f1 -DappendColNames=f0,f1 -DcenterCount=${centerCount} -Dloop=10 -Daccuracy=0.01 -DdistanceType=${distanceType} -DinitCenterMethod=random -Dseed=1 -DmodelName=pai_kmeans_test_output_model_${exp_id}_${trial_id} -DidxTableName=pai_kmeans_test_output_idx_${exp_id}_${trial_id} -DclusterCountTableName=pai_kmeans_test_output_couter_${exp_id}_${trial_id} -DcenterTableName=pai_kmeans_test_output_center_${exp_id}_${trial_id};其中:
${centerCount}和${distanceType}為定義的超參數變量。更多配置示例,請參見附錄:參考說明。
超參數
根據命令中配置的超參數變量,自動加載超參數列表。您需要為每個超參數配置約束類型和搜索空間:
約束類型:為超參數添加的限制條件。您可以將鼠標懸停在約束類型后的
圖標上,以查看支持選擇的約束類型及相關說明。搜索空間:用于指定超參數的取值范圍。每種約束類型對應的搜索空間的配置方式不同,您可以單擊
圖標并根據界面提示進行添加。
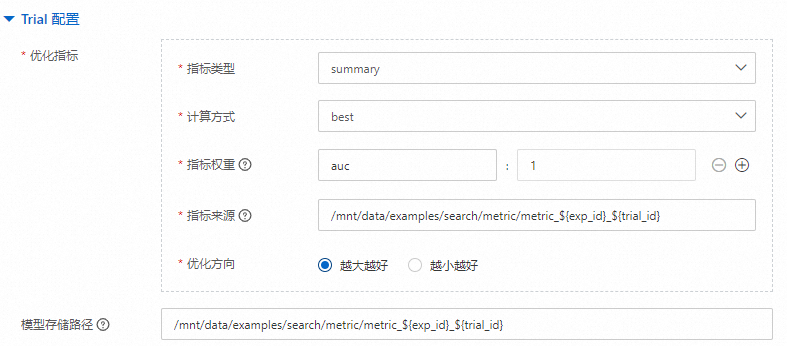
Trial配置。
使用某組超參來運行任務,參數配置如下:
參數
描述
指標類型
用來評估Trial的指標類型,取值如下:
summary:最終指標需要從來自OSS的Tensorflow summary文件中提取。
table:最終指標需要從MaxCompute表格中提取。
stdout:最終指標需要從運行過程中的stdout中提取。
json:最終指標以JSON格式的文件存儲在OSS中。
計算方式
在任務運行過程中,會逐步輸出多個中間指標,需要通過計算方式來確定最終指標。取值如下:
final:以最后一個指標作為整個Trial的最終指標。
best:以在任務運行過程中得到的最優指標作為整個Trial的最終指標。
avg:以在任務運行過程中得到的全部中間指標的均值作為Trial的最終指標。
指標權重
當需要同時考慮多個指標時,您可以通過配置指標名稱和對應權重的方式來實現,系統將使用加權求和值作為最終評估指標來比較優劣。
key:為指標名稱,支持正則表達式。
value:為對應的權重。
說明權重可以為負值,且權重之和可以不為1,支持自定義。
指標來源
指標的來源:
當指標類型選擇summary或json時,需要配置一個文件路徑。例如
oss://examplebucket/examples/search/pai/model/model_${exp_id}_${trial_id}。當指標類型選擇table時,需要配置一個能夠獲取具體結果的SQL語句。例如
select GET_JSON_OBJECT(summary, '$.calinhara') as vrc from pai_ft_cluster_evaluation_out_${exp_id}_${trial_id}。當指標類型選擇stdout時,需要配置一個命令關鍵字。僅支持配置為
cmdx或cmdx;xxx,such as cmd1;worker。
優化方向
用于評估Trial結果的優化方向,取值如下:
越大越好
越小越好
模型存儲路徑
存儲模型的路徑。該路徑必須包含
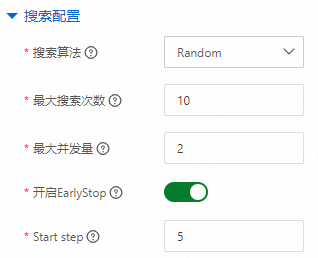
${exp_id}_${trial_id},用來區分不同超參數組合下生成的模型。例如oss://examplebucket/examples/search/pai/model/model_${exp_id}_${trial_id}。搜索配置。
參數
描述
搜索算法
是一種自動化機器學習算法,它根據超參數搜索空間以及先前Trial的結果和性能指標,尋找更優的超參數組合,以供下一個Trial運行使用。支持選擇的算法類型如下:
TPE
Random
GridSearch
Evolution
GP
PBT
算法詳情說明,請參見支持的搜索算法。
最大搜索次數
該實驗允許運行的最多Trial個數。
最大并發量
該實驗允許并行運行的最多Trial個數。
單擊提交。
您可以在實驗列表中查看已創建的實驗。
后續操作
附錄:參考說明
在使用MaxCompute類型的任務進行超參數調優時,提供了如下配置示例供您參考:
命令配置如下,其中cmd1和cmd2分別對應兩個組件的命令,按照順序依次排列。具體使用流程,請參見MaxCompute K均值聚類最佳實踐。
cmd1
pai -name kmeans -project algo_public -DinputTableName=pai_kmeans_test_input -DselectedColNames=f0,f1 -DappendColNames=f0,f1 -DcenterCount=${centerCount} -Dloop=10 -Daccuracy=0.01 -DdistanceType=${distanceType} -DinitCenterMethod=random -Dseed=1 -DmodelName=pai_kmeans_test_output_model_${exp_id}_${trial_id} -DidxTableName=pai_kmeans_test_output_idx_${exp_id}_${trial_id} -DclusterCountTableName=pai_kmeans_test_output_couter_${exp_id}_${trial_id} -DcenterTableName=pai_kmeans_test_output_center_${exp_id}_${trial_id};cmd2
PAI -name cluster_evaluation -project algo_public -DinputTableName=pai_cluster_evaluation_test_input -DselectedColNames=f0,f1 -DmodelName=pai_kmeans_test_output_model_${exp_id}_${trial_id} -DoutputTableName=pai_ft_cluster_evaluation_out_${exp_id}_${trial_id};