推薦系統和搜索引擎是現代App解決信息過載的標配系統,如果從零開發推薦系統,不僅需要耗費大量金錢和時間,而且很難滿足快速上線推薦系統及不斷迭代各種算法的業務要求。本文為您介紹如何使用阿里云產品創建推薦系統的數據和模型,從而快速搭建自己的推薦系統。
架構
完整的推薦流程包括召回和排序。召回是指從海量的待推薦候選集中,選取待推薦列表。排序是指對待推薦列表的每個Item與User的關聯程度進行排序。推薦系統的架構如下。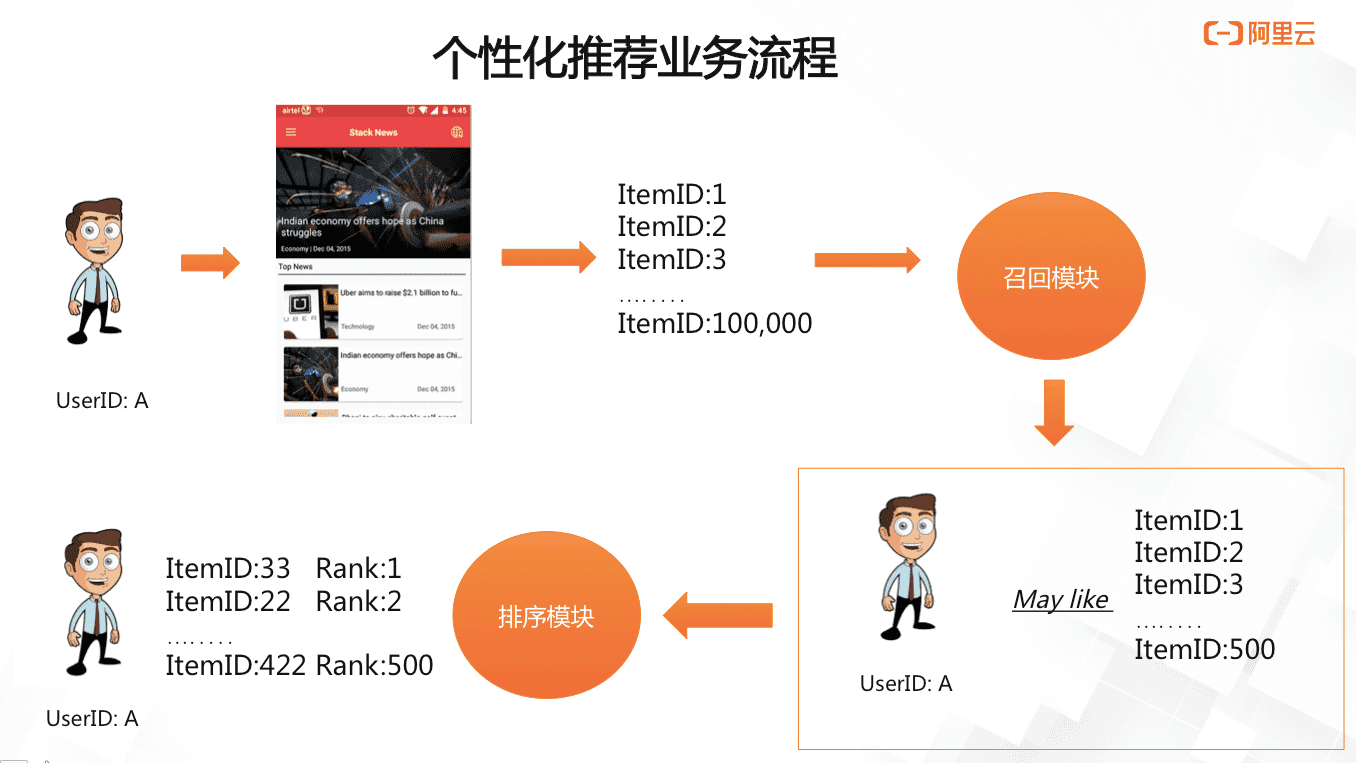
基于PAI產品實現推薦系統的架構如下。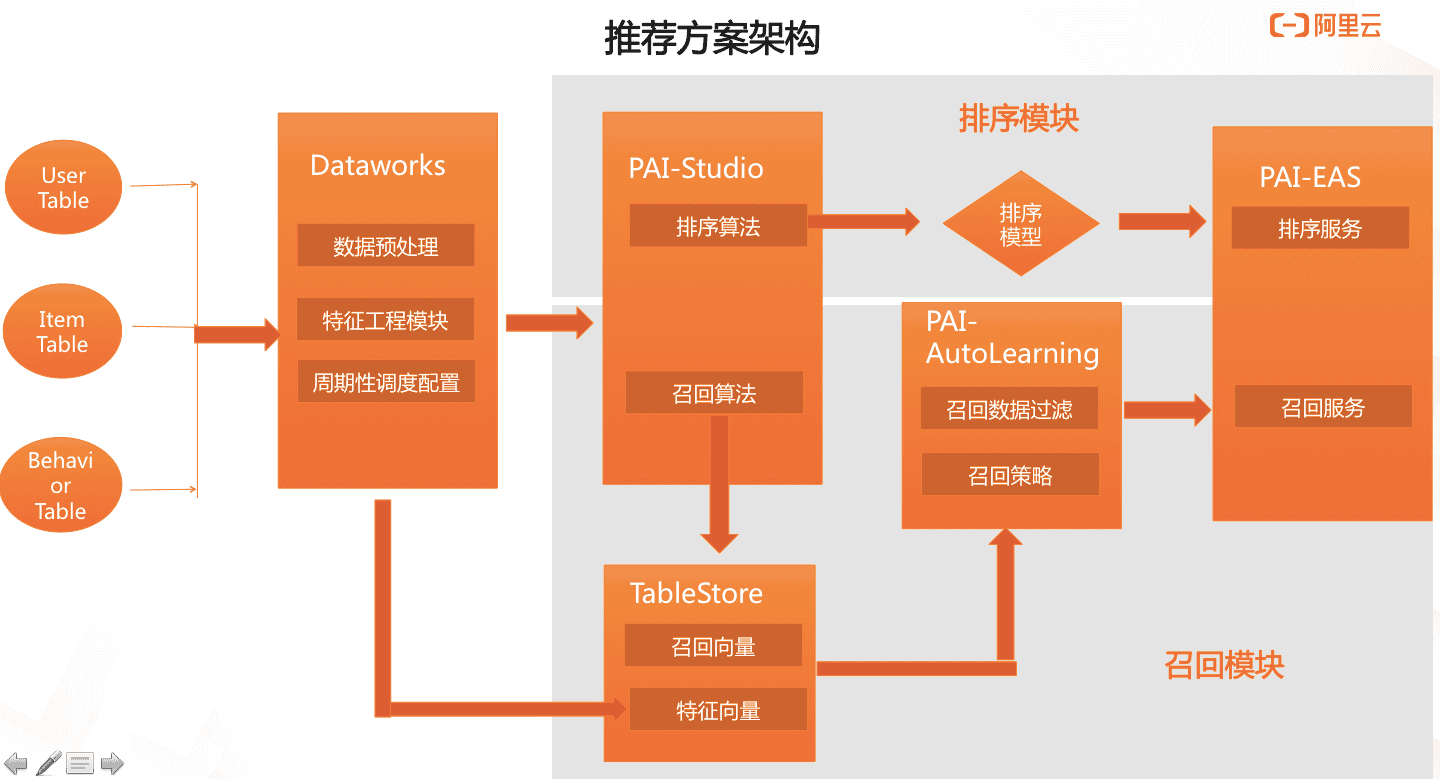 其中:
其中:
數據分為User、Item及Behavior,均存儲于MaxCompute。
使用DataWorks進行數據預處理和基礎特征構建。
部分特征向量寫入Tablestore。
使用Designer進行召回和排序算法相關計算。
排序模型可以直接通過EAS部署為RESTful API。
可以先將召回結果寫入Tablestore,再使用PAI-AutoLearning進行配置,最終將結果傳入EAS并部署為RESTful API。
完整的推薦流程如下。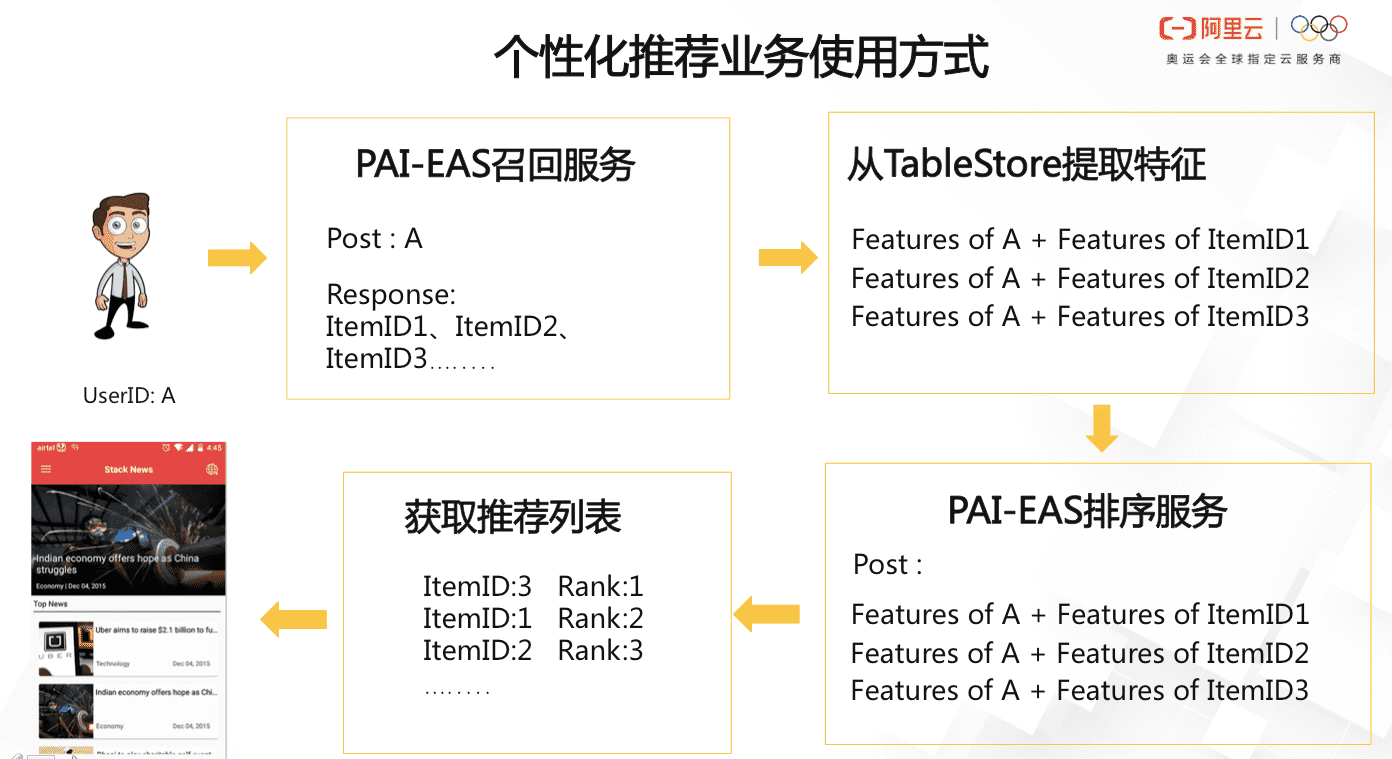 用戶進入PAI平臺,首先調用EAS的召回服務獲取召回列表,然后在Tablestore中,使用User ID和Item ID讀取特征,并將拼接好的樣本傳入EAS排序服務,最終獲取排序結果。
用戶進入PAI平臺,首先調用EAS的召回服務獲取召回列表,然后在Tablestore中,使用User ID和Item ID讀取特征,并將拼接好的樣本傳入EAS排序服務,最終獲取排序結果。
推薦系統的相關資料
【強烈推薦】完整的推薦解決方案(基于該資料,一個人僅需一周即可搭建一套完整的企業級推薦系統):PAI平臺搭建企業級個性化推薦系統。
【強烈推薦】通過視頻,介紹如何快速搭建一套基于協同過濾的簡單推薦系統;從零構建推薦系統。
FM-Embedding用法:使用FM-Embedding實現推薦召回。
冷啟動場景
如果需要推薦很多Item,則可以考慮使用文章的標題和正文訓練一個Doc2vec模型,并對每個Item生成一個向量,詳情請參見文本分析。
您可以將向量放至ES引擎中,并添加向量檢索插件,從而使每個向量可以召回相似向量。建議先對Item進行分類,再在同一個大類中查找相似向量。如果沒有對Item進行分類,則可以標注部分Item,并將其作為分類模型。
基于用戶行為的推薦場景
擁有冷啟動及用戶點擊數據后,您可以按照如下方法構建推薦場景:
使用用戶點擊序列計算物品和物品之間的關系。您可以通過自然語言處理中的Word2vec算法,將每個用戶點擊的多個Item作為一個句子,并對該Item序列進行清洗(例如,訪問的Item屬于同一個大類、訪問的Item在同一個Session中或兩次訪問Item的時間間隔不超過30分鐘),詳情請參見文本分析。
獲得足夠的User和Item數據后,您可以通過協同過濾etrec算法或矩陣分解算法計算得到Item-Item數據,詳情請參見組件配置。
說明etrec算法中可以設置權重weight。例如,對點擊、收藏及購買設置不同的權重。
獲得用戶點擊Item的日志和曝光日志后,您可以使用GBDT模型(避免特征工程)或樹模型(例如PS-SMART)整理用戶特征和Item特征,詳情請參見組件配置或GBDT回歸。
使用如下任何一種算法挖掘特征(User和Item本身特征、User-Item交叉特征及Context特征):
挖掘特征工程:特征工程。
自動挖掘Autocross特征:Auto ML自動特征工程使用說明。
使用FM算法自動挖掘二階交叉特征:使用FM-Embedding實現推薦召回。
模型訓練完成后,使用EAS將其部署為RESTful API,詳情請參見服務部署:控制臺。
使用TextRank算法提取關鍵詞,從而挖掘Item中的標簽信息,詳情請參見文本分析。
深度學習推薦算法
在PAI-TensorFlow基礎上,PAI開發了經典的深度學習推薦算法,即源碼級開源的DeepFM代碼,詳情請參見使用TensorFlow實現分布式DeepFM算法。DeepFM中詳細描述了讀取MaxCompute數據表、特征處理、構造Graph、訓練及評估等過程。為了降低阿里云用戶應用深度學習解決推薦問題的難度,PAI推出了EasyRec算法包,包含DeepFM、DIN、MultiTower及DSSM等經典推薦排序和召回算法,可以幫助您在PAI平臺上快速訓練推薦算法模型、驗證模型效果及部署模型,詳情請參見使用EasyRec構建推薦模型。