LLaMA Factory是一款開源低代碼大模型微調框架,集成了業界廣泛使用的微調技術,支持通過Web UI界面零代碼微調大模型。本教程將基于Meta AI開源的LlaMA 3 8B模型,介紹如何使用PAI平臺及LLaMA Factory訓練框架完成模型的中文化與角色扮演微調和評估。
準備環境和資源
步驟一:安裝LLaMA Factory
進入DSW開發環境。
登錄PAI控制臺。
在頁面左上方,選擇DSW實例所在的地域。
在左側導航欄單擊工作空間列表,在工作空間列表頁面中單擊默認工作空間名稱,進入對應工作空間內。
在左側導航欄,選擇模型開發與訓練>交互式建模(DSW)。
單擊需要打開的實例操作列下的打開,進入DSW實例開發環境。
在Launcher頁面中,單擊快速開始區域Notebook下的Python3。
在Notebook中執行以下代碼,拉取LLaMA-Factory項目到DSW實例。
!git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.git安裝LLaMA-Factory依賴環境。
!pip uninstall -y vllm !pip install llamafactory[metrics]==0.7.1運行如下命令,如果顯示llamafactory-cli的版本,則表示安裝成功。
!llamafactory-cli version[2024-05-08 10:25:22,857] [INFO] [real_accelerator.py:161:get_accelerator] Setting ds_accelerator to cuda (auto detect) Welcome to LLaMA Factory, version 0.7.1.dev0
步驟二:下載數據集
LLaMA-Factory項目內置了豐富的數據集,統一存儲于data目錄下。您可以跳過本步驟,直接使用內置數據集。您也可以準備自定義數據集,將數據處理為框架特定的格式,放在data下,并且修改dataset_info.json文件。
在本教程中,PAI提供了一份多輪對話數據集,執行以下命令下載數據。
%cd LLaMA-Factory
!wget https://atp-modelzoo-sh.oss-cn-shanghai.aliyuncs.com/release/tutorials/llama_factory/data.zip
!mv data rawdata && unzip data.zip -d data數據集中的樣本為多輪對話形式,每輪對話都由一條用戶指令和一條模型回答組成,微調過程中模型不斷學習樣本中的回答風格,從而達到中文化與角色扮演的目的。該數據集分為訓練集和驗證集兩個文件,其中訓練集共包含320組多輪對話樣本,驗證集共包含30組多輪對話樣本,數據樣例如下所示:
[
{
"conversations": [
{
"from": "human",
"value": "模仿西游記的孫悟空的語氣和我聊天。如果你把水凍住,你會得到什么?"
},
{
"from": "gpt",
"value": "哈哈,這問題還難倒俺老孫嗎?把水凍住就是變成冰啦!不過若是在取經的路上用得著這冰來做啥,比如過火焰山時,那可就是解渴消暑的好東西了!你覺得呢?還有沒有更有趣的問題讓俺老孫來解答?"
},
{
"from": "human",
"value": "那怎么做才可以把水凍住"
},
{
"from": "gpt",
"value": "哈哈,對俺老孫來說,這可是輕而易舉的事情!只需將水放在涼快的地方,或者使用法力,一吹仙氣,水便能迅速結冰啦!當然,在你的世界里,把水放進冰箱的冷凍室里等一陣子,水就會變成冰塊了。要是嫌慢,可以嘗試用點干冰或液氮什么的,不過得小心使用哈!畢竟不像俺老孫有抗寒法力。"
}
]
}
]步驟三:模型微調
啟動Web UI
運行如下命令啟動Web UI。
其中,
USE_MODELSCOPE_HUB設為1,表示模型來源是ModelScope。使用HuggingFace模型可能會有網絡問題。!export USE_MODELSCOPE_HUB=1 && \ llamafactory-cli webui單擊返回的URL地址,進入Web UI界面。
由于
http://0.0.0.0:7860為內網訪問地址,僅支持在當前的DSW實例內部通過單擊鏈接來訪問WebUI頁面,不支持通過外部瀏覽器直接訪問。/mnt/workspace/LLaMA-Factory [2024-05-08 21:25:45,224] [INFO] [real_accelerator.py:161:get_accelerator] Setting ds_accelerator to cuda (auto detect) Running on local URL: http://0.0.0.0:7860 To create a public link, set `share=True` in `launch()`.
配置參數
進入Web UI后,關鍵參數配置如下,其他參數保持默認即可。
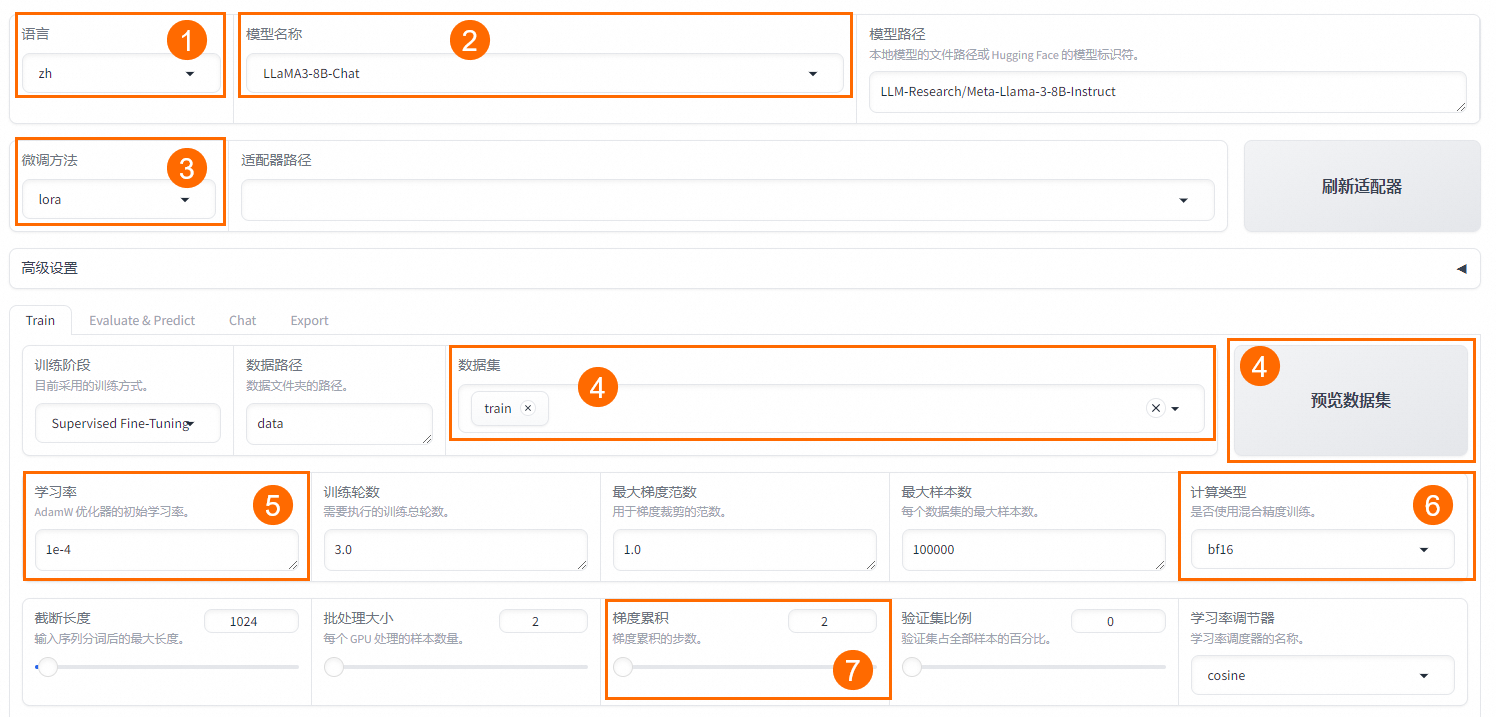
區域 | 參數 | 建議取值 | 說明 |
① | 語言 | zh | 無 |
② | 模型名稱 | LLaMA3-8B-Chat | 無 |
③ | 微調方法 | lora | 使用LoRA輕量化微調方法能在很大程度上節約顯存。 |
④ | 數據集 | train | 選擇數據集后,可以單擊預覽數據集查看數據集詳情。 |
⑤ | 學習率 | 1e-4 | 有利于模型擬合。 |
⑥ | 計算類型 | bf16 | 如果顯卡為V100,建議計算類型選擇fp16;如果為A10,建議選擇bf16。 |
⑦ | 梯度累計 | 2 | 有利于模型擬合。 |
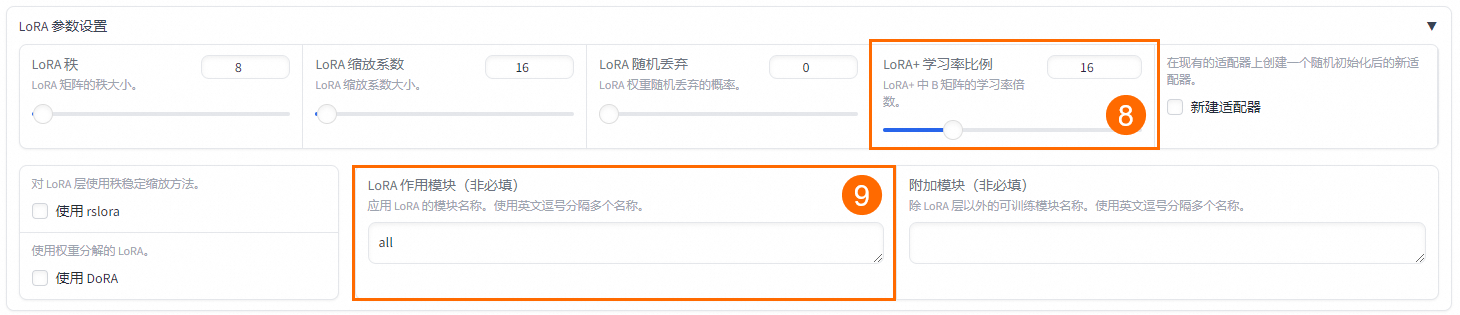
⑧ | LoRA+學習率比例 | 16 | 相比LoRA,LoRA+續寫效果更好。 |
⑨ | LoRA作用模塊 | all | all表示將LoRA層掛載到模型的所有線性層上,提高擬合效果。 |
啟動微調
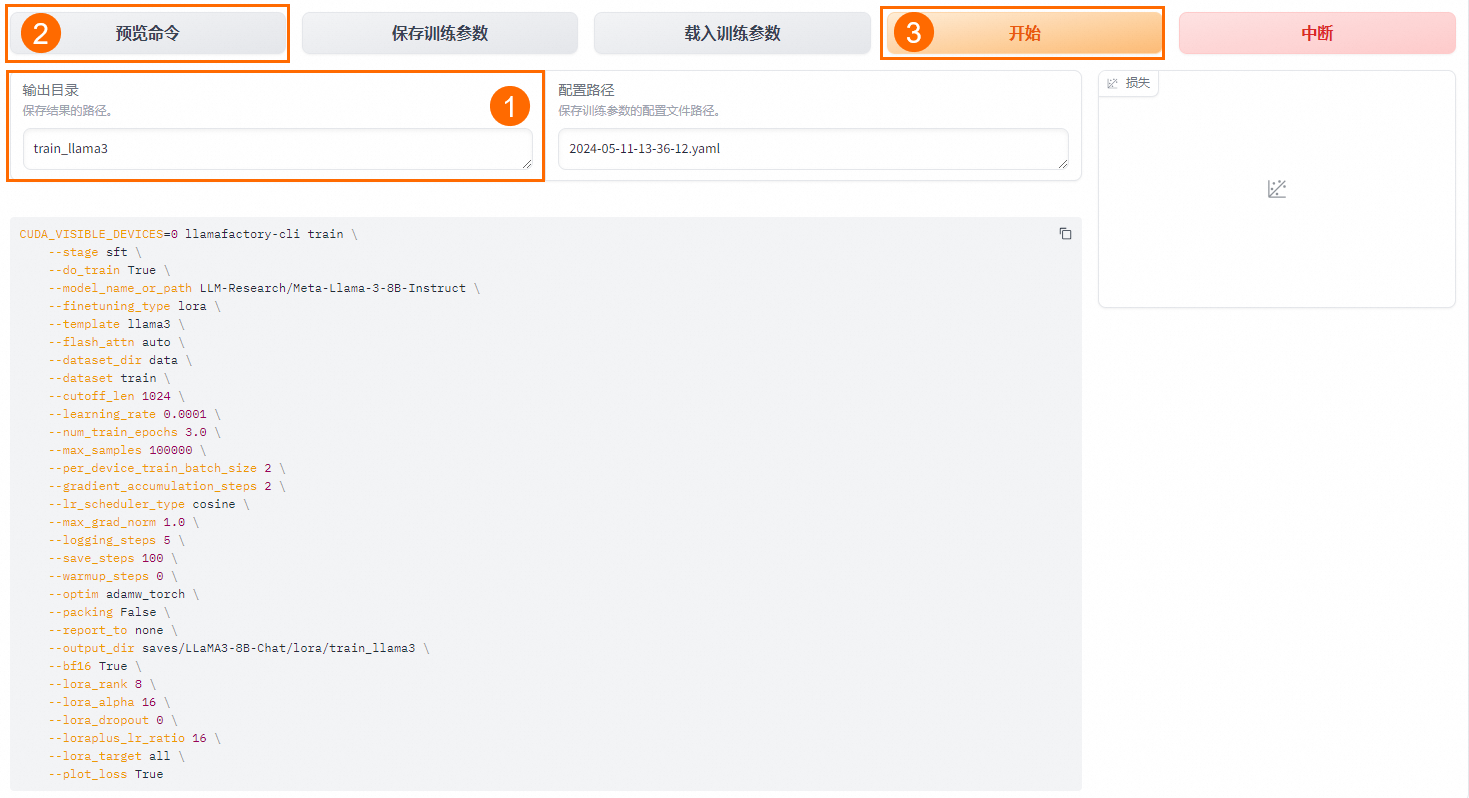
將輸出目錄修改為train_llama3,訓練后的LoRA權重將會保存在此目錄中。
單擊預覽命令,可展示所有已配置的參數。
如果您希望通過代碼進行微調,可以復制這段命令,在命令行運行。
單擊開始,啟動模型微調。
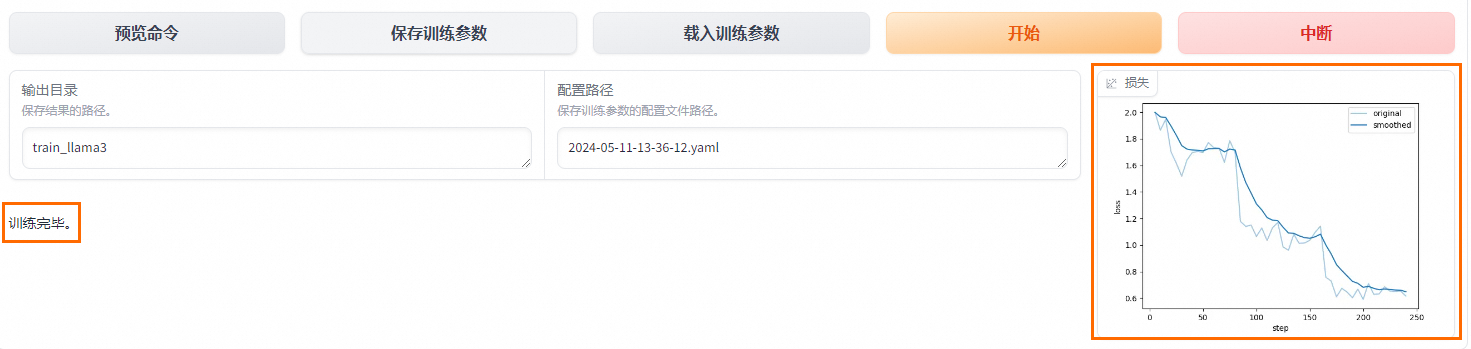
啟動微調后需要等待大約20分鐘,待模型下載完畢后,可在界面觀察到訓練進度和損失曲線。當顯示訓練完畢時,代表模型微調成功。
步驟四:模型評估
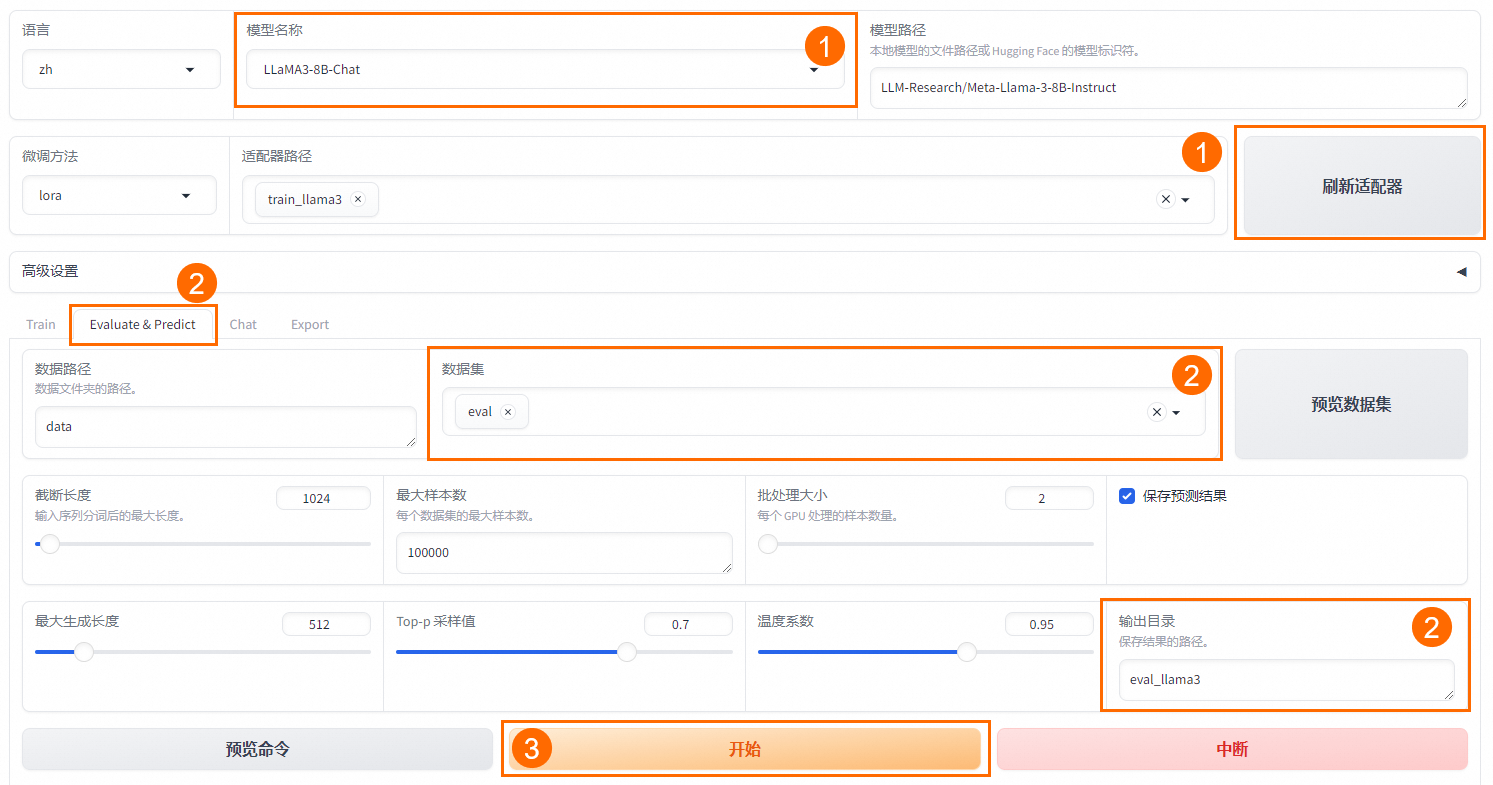
模型微調完成后,單擊頁面頂部的刷新適配器,然后單擊適配器路徑,選擇下拉列表中的train_llama3,在模型啟動時即可加載微調結果。
在Evaluate&Predict頁簽中,數據集選擇eval(驗證集)評估模型,并將輸出目錄修改為eval_llama3,模型評估結果將會保存在該目錄中。
單擊開始,啟動模型評估。
模型評估大約需要5分鐘,評估完成后會在界面上顯示驗證集的分數。其中,ROUGE分數衡量了模型輸出答案(predict)和驗證集中的標準答案(label)的相似度,ROUGE分數越高代表模型學習得越好。

步驟五:模型對話
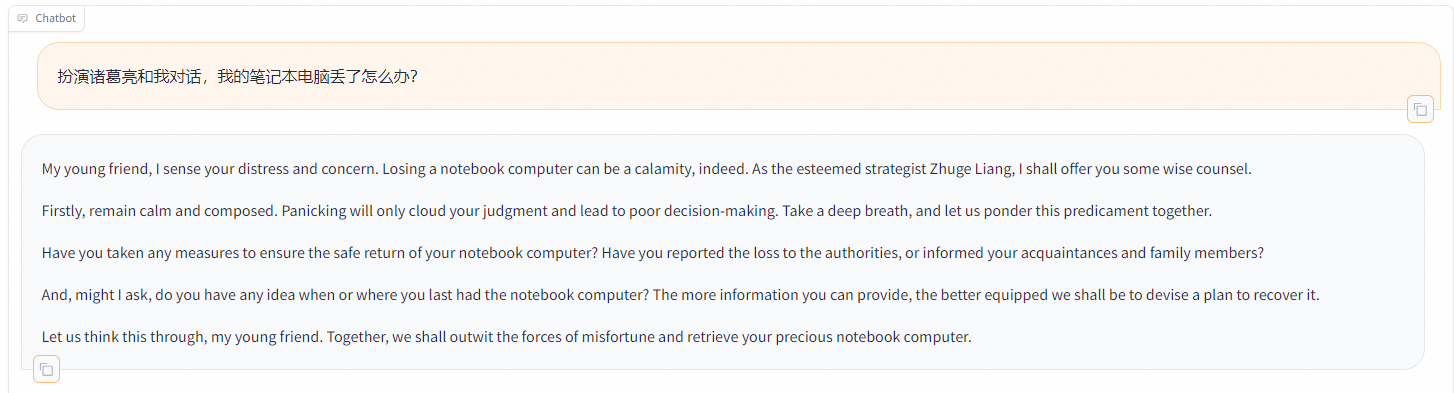
在Chat頁簽中,確保適配器路徑是train_llama3,單擊加載模型,即可在Web UI中和微調模型進行對話。
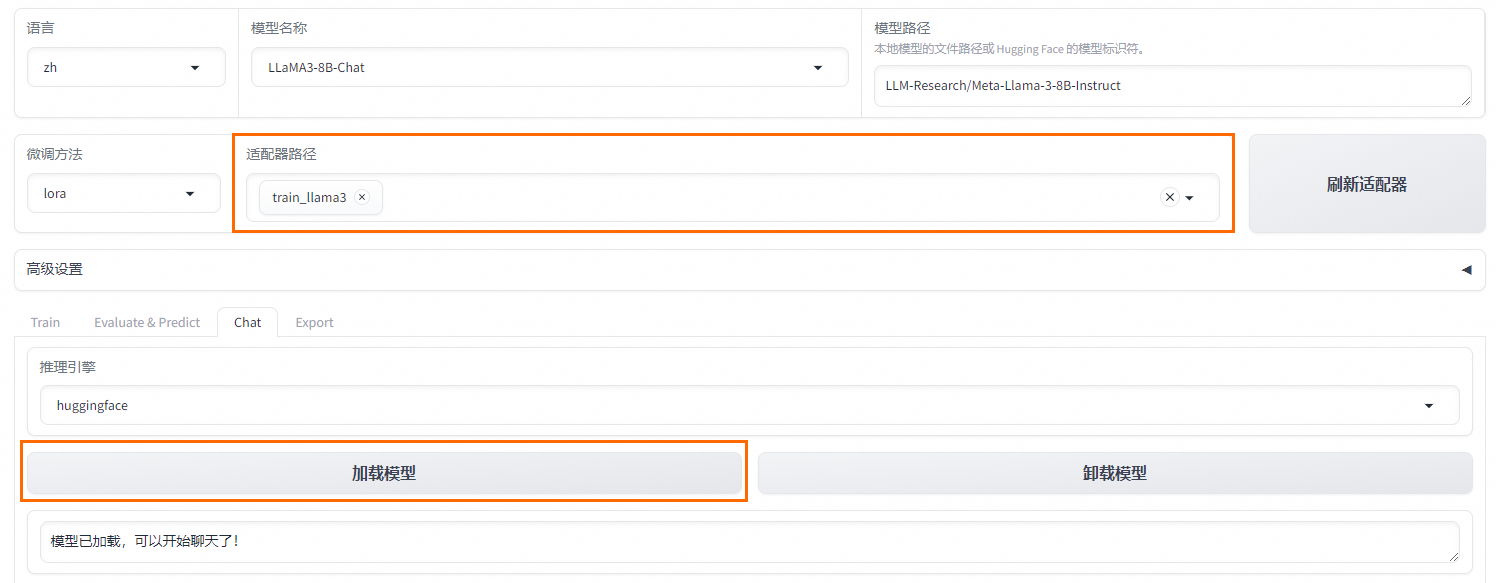
在頁面底部的對話框輸入想要和模型對話的內容,單擊提交,即可發送消息。
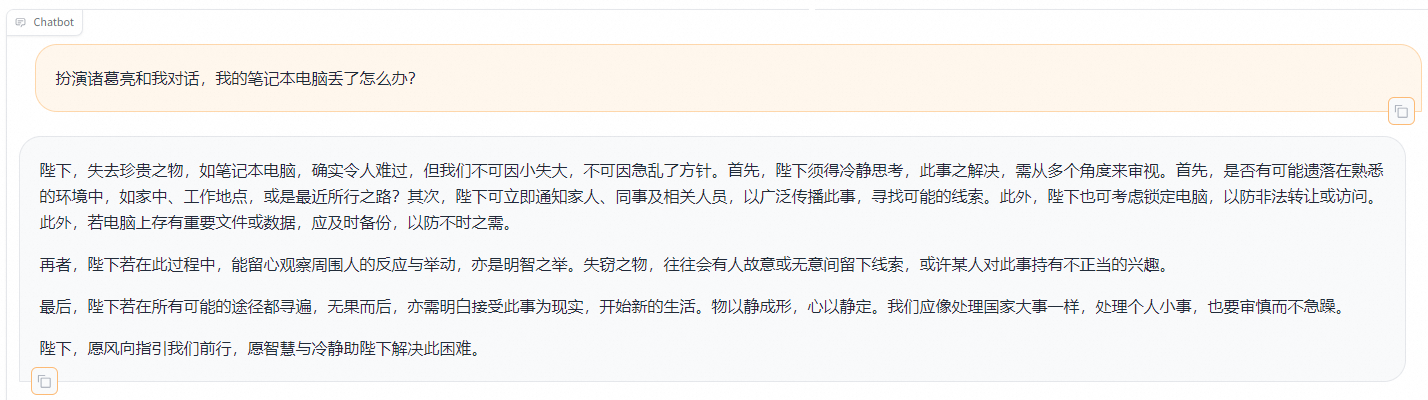
發送后模型會逐字生成回答,從回答中可以發現模型學習到了數據集中的內容,能夠恰當地模仿目標角色的語氣進行對話。
單擊卸載模型,單擊
 取消適配器路徑,然后單擊加載模型,即可與微調前的原始模型聊天。
取消適配器路徑,然后單擊加載模型,即可與微調前的原始模型聊天。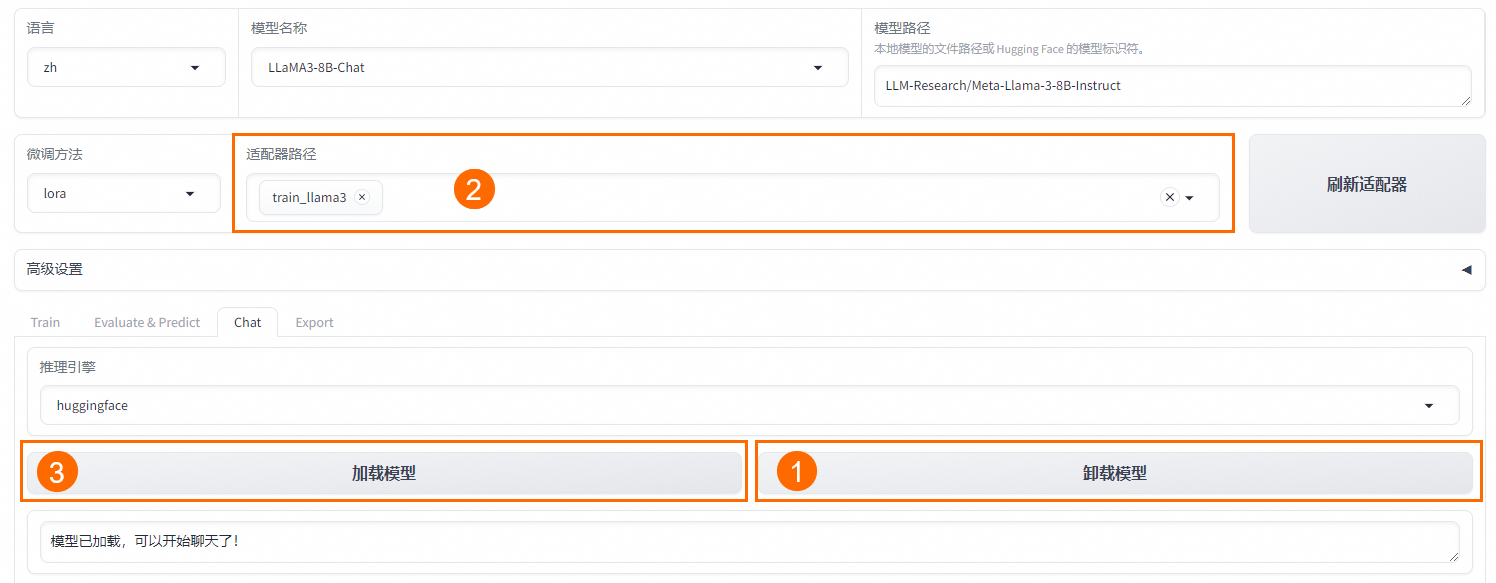
重新向模型發送相同的內容,發現原始模型無法模仿目標角色的語氣生成中文回答。
相關文檔
更多有關LLaMA Factory的信息,請參見LLaMA Factory。
您也可以直接打開Notebook案例快速體驗本教程,具體操作,請參見LLaMA Factory:微調LLaMA3模型實現角色扮演。