本文通過PAI提供的文本分析組件,實現簡單的商品標簽自動歸類系統。
背景信息
通常每件商品的描述會包含很多維度標簽。例如,一雙鞋子的商品描述可能是“少女英倫風系帶馬丁靴女磨砂真皮厚底休閑短靴”。一個包的商品描述可能是“天天特價包包2016新款秋冬斜挎包韓版手提包流蘇貝殼包女包單肩包”。這些維度可以包含時間、產地及款式等,如何按照特定維度將數以萬計的商品進行歸類是電商平臺的難題之一,其中最大的挑戰是如何從商品描述中抽取維度標簽。PAI提供的文本分析組件可以自動學習標簽詞語,從而實現標簽自動歸類。
前提條件
準備數據集
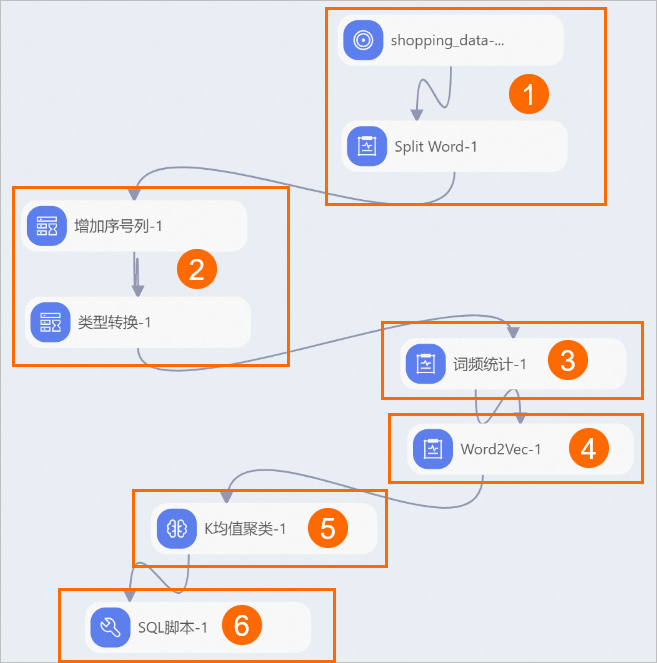
本工作流數據是整理的一份2016年雙十一購物清單,共兩千多條商品描述,每一行表示一件商品的標簽聚合。如下圖所示。
您需要前往DataWorks數據開發模塊,新建一個只包含一個列名為content的表,并將上述準備好的數據上傳至該表中。具體操作,請參見建表并上傳數據。
相似標簽自動歸類
進入Designer頁面。
登錄PAI控制臺。
在左側導航欄單擊工作空間列表,在工作空間列表頁面中單擊待操作的工作空間名稱,進入對應工作空間內。
在工作空間頁面的左側導航欄選擇,進入Designer頁面。
新建自定義工作流,并進入工作流頁面,詳情請參見新建自定義工作流。
構建并運行工作流。
在左側組件列表,將源/目標下的讀數據表組件拖入畫布中,并重命名為shopping_data-1。
在左側組件列表,將下的Split Word、詞頻統計及Word2Vec組件拖入畫布中。
在左側組件列表,將數據預處理下的增加序號列和類型轉換組件拖入畫布中。
在左側組件列表,將下的K均值聚類組件拖入畫布中。
在左側組件列表,將自定義腳本下的SQL腳本組件拖入畫布中。
將以上組件拼接為如下工作流,參照下表配置組件的關鍵參數,并運行組件。
在畫布中單擊shopping_data-1組件,并在右側表選擇頁簽配置已準備好的表名。
在畫布中單擊Split Word-1組件,并在右側字段設置頁簽,選擇列名為content。
首先單擊shopping_data-1組件,在快捷菜單,單擊執行該節點。待該組件執行完成后,再以相同的方式執行Split Word-1組件。
在畫布中單擊詞頻統計-1組件,在右側字段設置頁簽,分別設置選擇文檔ID列為append_id,選擇文檔內容列為content。
單擊詞頻統計-1組件,在快捷菜單,單擊執行該節點。
向量距離近的兩個詞,其真實含義比較相近。
不同詞之間的距離差值具有一定意義。
在畫布中單擊Word2Vec-1組件,在右側字段設置頁簽,設置選擇單詞列為word,在參數設置頁簽,選中采用hierarchical softmax。
單擊Word2Vec-1組件,在快捷菜單,單擊執行該節點。
在畫布中單擊K均值聚類-1組件,在右側字段設置頁簽,選擇特征列為f0,附加列為word。
說明該組件在運行時,其上游輸入數據表的行數必須大于或等于該組件參數中設定的聚類數目。
單擊K均值聚類-1組件,在快捷菜單,單擊執行該節點。
序號
描述
①
上傳shopping_data數據,并通過分詞組件對數據進行分詞,具體操作步驟如下:
②
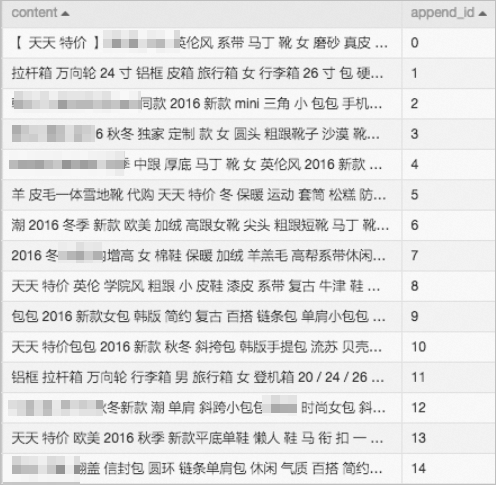
增加序號列。由于上傳的數據只有一個字段,需要通過增加序號列為每個數據增加主鍵。
首先單擊增加序號列-1組件,在快捷菜單,單擊執行該節點。待該組件執行完成后,再以相同的方式執行類型轉換-1組件。
處理后的結果示例如下圖所示。
③
統計詞頻,展示每個商品中出現的各種詞語數量。
④
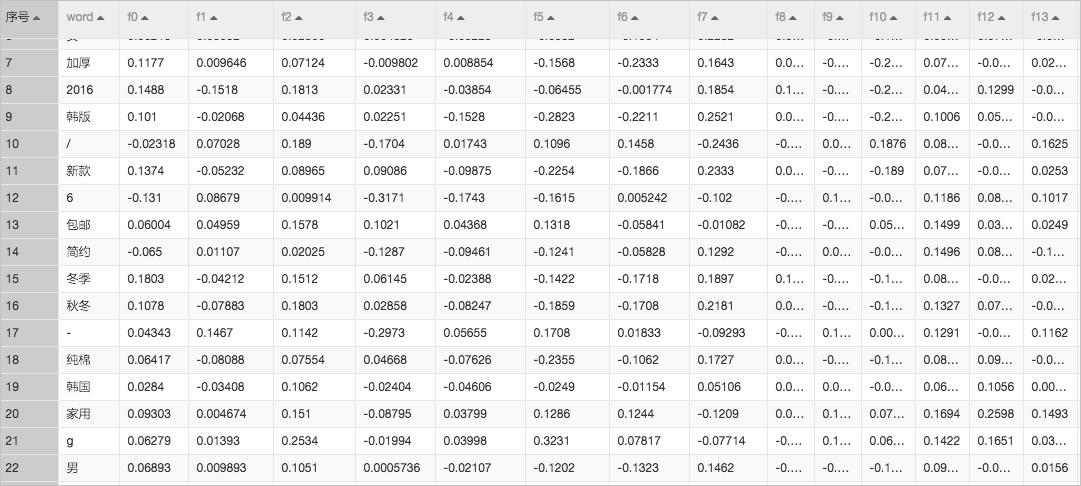
使用Word2Vec組件將每個詞語按照意義在向量維度展開,生成詞向量。詞向量的含義包括:
經過Word2Vec組件將每個詞映射到百維空間上。
結果示例如下圖所示。
⑤
詞向量聚類。使用K均值聚類算法,在已經產生的詞向量基礎上,計算詞向量的距離,并按照意義將標簽詞自動歸類。
其結果展示每個詞所屬的聚類簇,結果示例如下圖所示。
⑥
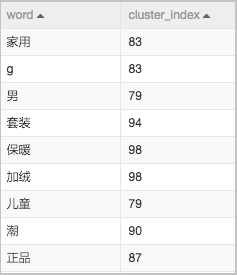
結果驗證。通過SQL腳本-1組件,在聚類簇中隨意挑選一個類別,判斷是否對同一類別的標簽進行了自動歸類。本工作流選用第10組聚類簇,在畫布中單擊SQL腳本-1組件,在右側參數設置頁簽,配置SQL腳本為
select * from ${t1} where cluster_index=10。結果示例如下圖所示。
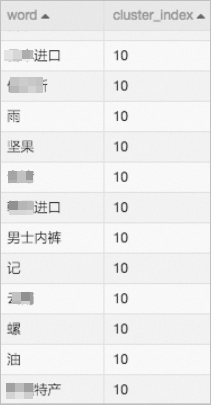
上述結果中,系統自動將與地理相關的標簽進行了歸類,但是混入了堅果等明顯與類別不符的標簽,可能是訓練樣本數量不足導致的。如果訓練樣本足夠大,則標簽聚類結果會非常準確。
相關文檔
關于算法組件更詳細的內容介紹,請參見: