通過阿里云Milvus和LangChain快速構建LLM問答系統
本文介紹如何通過整合阿里云Milvus、阿里云DashScope Embedding模型與阿里云PAI(EAS)模型服務,構建一個由LLM(大型語言模型)驅動的問題解答應用,并著重演示了如何搭建基于這些技術的RAG對話系統。
前提條件
已創建Milvus實例。具體操作,請參見快速創建Milvus實例。
已開通PAI(EAS)并創建了默認工作空間。具體操作,請參見開通PAI并創建默認工作空間。
已開通服務并獲得API-KEY。具體操作,請參見API-KEY的獲取與配置。
使用限制
Milvus實例和PAI(EAS)須在相同地域下。
請確保您的運行環境中已安裝Python 3.8或以上版本,以便順利安裝并使用DashScope。
方案架構
該方案架構如下圖所示,主要包含以下幾個處理過程:
知識庫預處理:您可以借助LangChain SDK對文本進行分割,作為Embedding模型的輸入數據。
知識庫存儲:選定的Embedding模型(DashScope)負責將輸入文本轉換為向量,并將這些向量存入阿里云Milvus的向量數據庫中。
向量相似性檢索:Embedding模型處理用戶的查詢輸入,并將其向量化。隨后,利用阿里云Milvus的索引功能來識別出相應的Retrieved文檔集。
RAG(Retrieval-Augmented Generation)對話驗證:您使用LangChain SDK,并將相似性檢索的結果作為上下文,將問題導入到LLM模型(本例中用的是阿里云PAI EAS),以產生最終的回答。此外,結果可以通過將問題直接查詢LLM模型得到的答案進行核實。
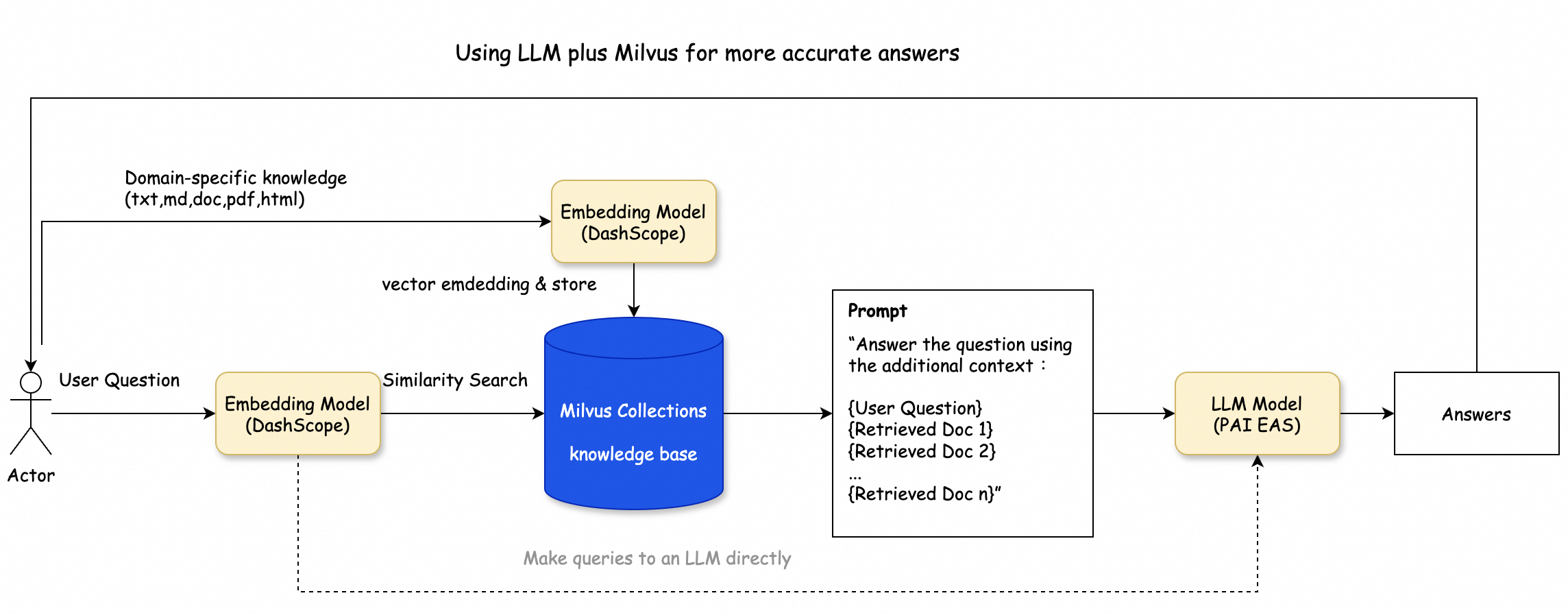
操作流程
步驟一:部署對話模型推理服務
進入模型在線服務頁面。
登錄PAI控制臺。
在左側導航欄單擊工作空間列表,在工作空間列表頁面中單擊待操作的工作空間名稱,進入對應工作空間內。
在工作空間頁面的左側導航欄選擇模型部署>模型在線服務(EAS),進入模型在線服務(EAS)頁面。

在模型在線服務頁面,單擊部署服務。
在部署服務頁面,選擇大模型RAG對話系統。
在部署大模型RAG對話系統頁面,配置以下關鍵參數,其余參數可使用默認配置,更多參數詳情請參見大模型RAG對話系統。
參數
描述
基本信息
服務名稱
您可以自定義。
模型來源
使用默認的開源公共模型。
模型類別
通常選擇通義千問7B。例如,Qwen1.5-7b。
資源配置
實例數
使用默認的1。
資源配置選擇
按需選擇GPU資源配置。例如,ml.gu7i.c16m30.1-gu30。
向量檢索庫設置
版本類型
選擇Milvus。
訪問地址
Milvus實例的內網地址。您可以在Milvus實例的實例詳情頁面查看。
代理端口
Milvus實例的Proxy Port。您可以在Milvus實例的實例詳情頁面查看。
賬號
配置為root。
密碼
配置為創建Milvus實例時,您自定義的root用戶的密碼。
數據庫名稱
配置為數據庫名稱,例如default。創建Milvus實例時,系統會默認創建數據庫default,您也可以手動創建新的數據庫,具體操作,請參見管理Databases。
Collection名稱
輸入新的Collection名稱或已存在的Collection名稱。對于已存在的Collection,Collection結構應符合PAI-RAG要求,例如您可以填寫之前通過EAS部署RAG服務時自動創建的Collection。
專有網絡配置
VPC
創建Milvus實例選擇時的VPC、交換機和安全組。您可以在Milvus實例的實例詳情頁面查看。
交換機
安全組名稱
單擊部署。
當服務狀態變為運行中時,表示服務部署成功。
獲取VPC地址調用的服務訪問地址和Token。
單擊服務名稱,進入概覽頁面。
在基本信息區域,單擊查看調用信息。
在調用信息對話框的VPC地址調用頁簽,獲取服務訪問地址和Token,并保存到本地。
步驟二:創建并執行Python文件
(可選)在ECS控制臺創建并啟動一個開通公網的ECS實例,用于運行Python文件,詳情請參見通過控制臺使用ECS實例(快捷版)。
您也可以在本地機器執行Python文件,具體請根據您的實際情況作出合適的選擇。
執行以下命令,安裝相關依賴庫。
pip3 install pymilvus langchain dashscope beautifulsoup4執行以下命令,創建
milvusr-llm.py文件。vim milvusr-llm.pymilvusr-llm.py文件內容如下所示。from langchain_community.document_loaders import WebBaseLoader from langchain.text_splitter import RecursiveCharacterTextSplitter from langchain.vectorstores.milvus import Milvus from langchain.schema.runnable import RunnablePassthrough from langchain.prompts import PromptTemplate from langchain_community.embeddings import DashScopeEmbeddings from langchain_community.llms.pai_eas_endpoint import PaiEasEndpoint # 設置Milvus Collection名稱。 COLLECTION_NAME = 'doc_qa_db' # 設置向量維度。 DIMENSION = 768 loader = WebBaseLoader([ 'https://milvus.io/docs/overview.md', 'https://milvus.io/docs/release_notes.md', 'https://milvus.io/docs/architecture_overview.md', 'https://milvus.io/docs/four_layers.md', 'https://milvus.io/docs/main_components.md', 'https://milvus.io/docs/data_processing.md', 'https://milvus.io/docs/bitset.md', 'https://milvus.io/docs/boolean.md', 'https://milvus.io/docs/consistency.md', 'https://milvus.io/docs/coordinator_ha.md', 'https://milvus.io/docs/replica.md', 'https://milvus.io/docs/knowhere.md', 'https://milvus.io/docs/schema.md', 'https://milvus.io/docs/dynamic_schema.md', 'https://milvus.io/docs/json_data_type.md', 'https://milvus.io/docs/metric.md', 'https://milvus.io/docs/partition_key.md', 'https://milvus.io/docs/multi_tenancy.md', 'https://milvus.io/docs/timestamp.md', 'https://milvus.io/docs/users_and_roles.md', 'https://milvus.io/docs/index.md', 'https://milvus.io/docs/disk_index.md', 'https://milvus.io/docs/scalar_index.md', 'https://milvus.io/docs/performance_faq.md', 'https://milvus.io/docs/product_faq.md', 'https://milvus.io/docs/operational_faq.md', 'https://milvus.io/docs/troubleshooting.md', ]) docs = loader.load() text_splitter = RecursiveCharacterTextSplitter(chunk_size=1024, chunk_overlap=0) # 使用LangChain將輸入文檔安照chunk_size切分 all_splits = text_splitter.split_documents(docs) # 設置embedding模型為DashScope(可以替換成自己模型)。 embeddings = DashScopeEmbeddings( model="text-embedding-v2", dashscope_api_key="your_api_key" ) # 創建connection,host為阿里云Milvus的訪問域名。 connection_args = {"host": "c-xxxx.milvus.aliyuncs.com", "port": "19530", "user": "your_user", "password": "your_password"} # 創建Collection vector_store = Milvus( embedding_function=embeddings, connection_args=connection_args, collection_name=COLLECTION_NAME, drop_old=True, ).from_documents( all_splits, embedding=embeddings, collection_name=COLLECTION_NAME, connection_args=connection_args, ) # 利用Milvus向量數據庫進行相似性檢索。 query = "What are the main components of Milvus?" docs = vector_store.similarity_search(query) print(len(docs)) # 聲明LLM 模型為PAI EAS(可以替換成自己模型)。 llm = PaiEasEndpoint( eas_service_url="your_pai_eas_url", eas_service_token="your_token", ) # 將上述相似性檢索的結果作為retriever,提出問題輸入到LLM之后,獲取檢索增強之后的回答。 retriever = vector_store.as_retriever() template = """Use the following pieces of context to answer the question at the end. If you don't know the answer, just say that you don't know, don't try to make up an answer. Use three sentences maximum and keep the answer as concise as possible. Always say "thanks for asking!" at the end of the answer. {context} Question: {question} Helpful Answer:""" rag_prompt = PromptTemplate.from_template(template) rag_chain = ( {"context": retriever, "question": RunnablePassthrough()} | rag_prompt | llm ) print(rag_chain.invoke("Explain IVF_FLAT in Milvus."))以下參數請根據實際環境替換。
參數
說明
COLLECTION_NAME
設置Milvus Collection名稱,您可以自定義。
model
模型名稱。
本文示例使用的Embedding模型(text-embedding-v2),您也可以替換成您實際使用的模型。有關Embedding的更多信息,請參見Embedding。
dashscope_api_key
百煉的API-KEY。
connection_args
"host":Milvus實例的公網地址。您可以在Milvus實例的實例詳情頁面查看。"port":Milvus實例的Proxy Port。您可以在Milvus實例的實例詳情頁面查看。"user":配置為創建Milvus實例時,您自定義的用戶名。"password":配置為創建Milvus實例時,您自定義用戶的密碼。
eas_service_url
配置為步驟1中獲取的服務訪問地址。本文示例聲明LLM模型為PAI(EAS),您也可以替換成您實際使用的模型。
eas_service_token
配置為步驟1中獲取的服務Token。
執行以下命令運行文件。
python3 milvusr-llm.py返回如下類似信息。
4 IVF_FLAT is a type of index in Milvus that divides vector data into nlist cluster units and compares distances between the target input vector and the center of each cluster. It uses a smaller number of clusters than IVF_FLAT, which means it may have slightly higher query time but also requires less memory. The encoded data stored in each unit is consistent with the original data.
相關文檔
更多關于Milvus的介紹,請參見什么是向量檢索服務Milvus版。
更多關于EAS的介紹,請參見EAS模型服務概述。
更多關于Embedding和LLM模型的介紹,請參見LangChain官方網站。