Milvus資源估算與配置建議
在使用向量檢索服務Milvus版前,合理估算所需的計算資源對于保障系統穩定運行和優化成本至關重要。向量檢索服務Milvus提供了資源計算器功能,您可以根據提供的實驗數據(向量規模、向量維度、索引類型等),幫助您理解如何推算所需的資源規模,但實際部署時還需您根據測試結果進行調整。
資源計算器
阿里云Milvus服務當前支持的計算資源配置比例為1:4。為確保實例運行穩定性,分配的內存資源將高于實際所需的內存容量。
通過資源計算器,您能夠方便地估算所需實例資源。您只需要輸入向量數據規模和維度,并選擇合適的索引類型,系統將為您推薦適宜的實例配置。例如,若您輸入數據規模為8(百萬)個向量,每個向量768維,并選擇HNSW索引類型,設置索引參數M為4,頁面將實時顯示推薦配置。根據這些建議,您可以輕松進行實例選型和性能測試。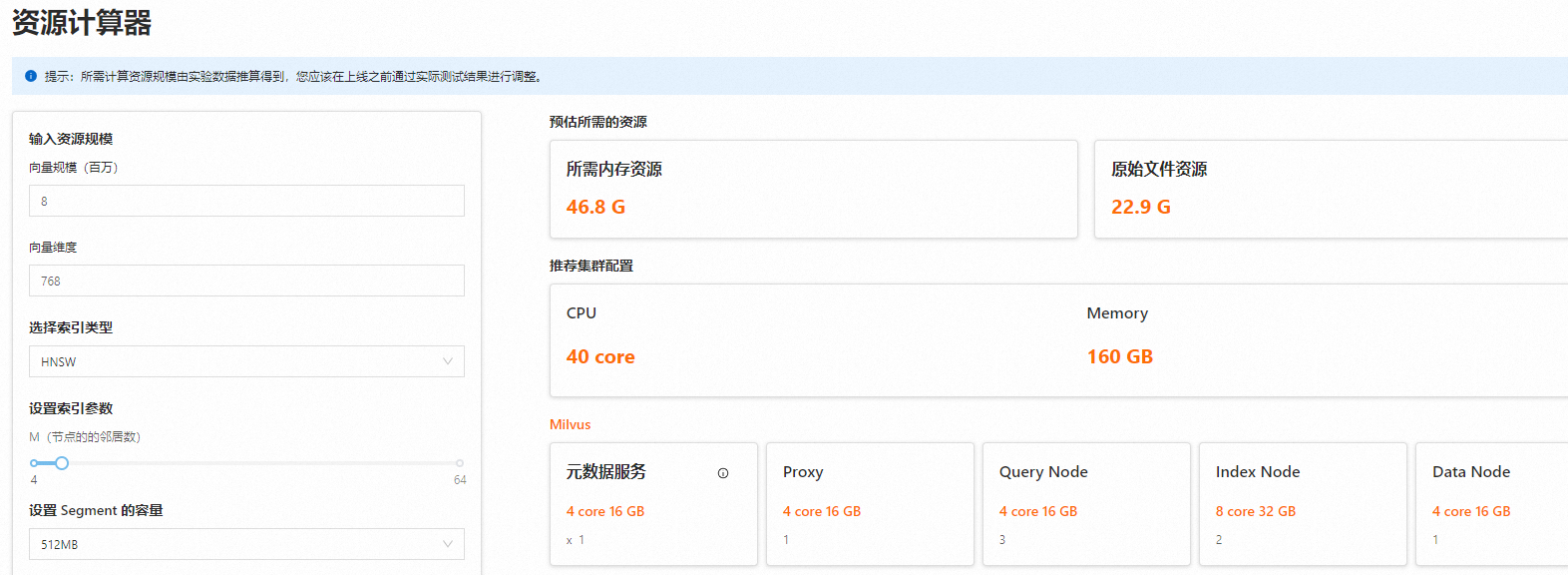
資源參數
輸入資源規模
參數 | 說明 |
向量規模(百萬) | 向量規模直接決定了索引的大小和查詢時需要遍歷的數據量。規模越大,所需的存儲空間越多,同時構建索引和查詢時的計算復雜度也相應增加,可能導致更長的處理時間和更高的硬件資源需求。 |
向量維度 | 向量的維度影響著索引的復雜度和精度。高維向量增加了索引的復雜性,因為每個向量在高維空間中需要更多的計算資源來比較相似度。這不僅會增加存儲成本,還會降低查詢速度,特別是在沒有有效降維或量化策略的情況下。 |
選擇索引類型
索引類型是決定資源需求和查詢性能的關鍵因素之一。不同的索引算法對內存、CPU和查詢時間的需求不同,支持的索引類型如下表所示。
參數 | 說明 |
HNSW | HNSW(Hierarchical Navigable Small World)是基于圖結構的索引,能夠提供非常高的查詢效率,尤其在高維數據空間中表現出色。但是,它對計算資源和內存的需求較高。適合需要獲得最快的查詢速度,且資源充足,特別是處理高維度數據的場景。 |
FLAT | 提供最高的查詢精度,因為它是精確匹配,但犧牲了查詢速度,尤其是在大規模數據集上,性能可能不理想。適合數據量相對較小(例如千萬級別),且對查詢精度有嚴格要求,不介意較慢的查詢速度的場景。 |
IVF_FLAT | 提供了一種平衡準確率與查詢速度的方案,適用于大多數場景。它通過量化操作減少了計算復雜度,相比Flat索引在查詢性能上有顯著提升,同時資源消耗相對較低。適合需要在查詢性能與資源成本間取得平衡,且數據量較大的場景。 |
IVF_SQ8 | 通過量化技術加速檢索過程,適合資源受限但需要較高召回率的場景。然而,與HNSW相比,其查詢精度可能會有所下降。適合在資源有限且對查詢召回率有較高要求的場景,特別是在大規模數據集上的應用。 |
設置索引參數
HNSW:需設置M值,M決定了每個節點的鄰居數量。較大的M值會增加索引的召回率和精度,但同時也會增加索引的構建時間和內存占用。較小的M值則相反,會使得索引構建更快、占用更少的內存,但可能犧牲一些精度。通常,M的推薦初始值為
lg(N),其中N為總的向量數量,然后可以根據實際查詢效果進行微調。例如,可以嘗試設置M為16、32或64,觀察效果并進行調整。IVF_FLAT和IVF_SQ8:需設置每個聚類(invert list)中的向量數量,invert list決定了將向量空間劃分為多少個子空間(聚類)。較大的invert list值會增加索引的準確性和召回率,但會增加構建索引的時間和查詢時的計算成本。較小的invert list則會降低索引的復雜度,但可能導致精度下降。
設置Segment的容量
Segment容量是指索引被劃分成的各個小塊(Segment)的大小。合理的Segment大小可以平衡查詢效率和內存使用:
較大的Segment可以減少索引的元數據量,從而減少內存占用,但可能降低查詢時的靈活性和效率,尤其是在更新索引或處理動態數據集時。
較小的Segment有利于快速查詢和更新,但可能增加索引的總體內存需求。