本文為您介紹MaxCompute數據開發規范,包括項目空間、表、視圖、工作流節點和編碼規范。
在進行數據開發前,請做好數據倉庫研發流程的階段規劃,了解各種角色及其職責,具體內容請參見數據倉庫研發規范概述。
項目空間管理規范
關于項目劃分和命名規范的詳解,請參見MaxCompute項目分配、項目命名規范。
關于項目安全管理規范的詳解,請參見權限概述。
DataWorks項目空間目錄構建建議:
數據開發時建議建立兩層目錄:
第一層目錄表示數據域(對于中間層項目)或業務線(對于應用層項目),例如日志、會員等。
第二層目錄表示層次,如DWD、DWS、DIM以及數據同步任務。
為避免臨時查詢文件列表過多,建議以開發人員姓名作為文件夾的名稱進行管理。
表和視圖相關規范
表設計規范
表(Table)和字段命名規范請參見ODS層設計規范、CDM公共維度層設計規范、CDM明細層設計規范、CDM匯總層設計規范。
表(Table)整體設計規范請參見表設計規范。
說明建議通過DataWorks數據管理中的管理配置模塊進行表的分類管理,同時通過DataWorks數據開發中的表管理模塊將表與對應分類關聯。
視圖設計規范
視圖的命名規范與表保持一致。
建議創建獨立的刷新任務以產生視圖,創建視圖的腳本如下。
create or replace view ***;
DataWorks工作流節點設計規范
工作流節點類型和命名
工作流節點的輸出表命名規范
projectname.tablename工作流節點命名規范
節點類型
命名規范
備注
虛擬節點
vt_{虛擬節點含義}
任務根節點。
同步節點導入任務
imp{表名}[{源庫標示}]
如果多個源庫存在表名重復的情況,可以增加源庫標識的后綴。
同步節點導出任務
exp{表名}[{目標庫標示}]
如果存在多個目標庫,可以增加目標庫標識的后綴。
數據處理節點
{輸出表名}
多個目標表輸出任務時,選定一個主要表名作為節點名。
多個任務插入同一張表的不同分區時,可以建一個虛擬目標表任務。
Shell節點
sh_{腳本命名}
不涉及
MapReduce節點
mr_{腳本命名}
不涉及
資源文件命名規范
資源名稱需有后綴表示資源類型,例如.JAVA、.PY、.SH等。
任務設計規范
SQL任務:
每個MaxCompute SQL任務至少有一個輸出表。
腳本需支持重跑,例如使用INSERT OVERWRITE等語句,以便在系統錯誤時,重跑任務不會出現重復數據等臟數據。
代碼如果有時間或日期參數,需采用類似
{bdp.system.cyctime}的調度參數,以方便調試。自定義參數,采用${變量名}在發布任務時進行配置。變量名即為調度參數。
編碼規范
編寫原則
代碼行清晰、整齊,具有一定的可觀賞性。
代碼編寫要充分考慮執行速度最優原則。
代碼行整體層次分明、結構化強。
代碼中應有必要的注釋以增強代碼的可讀性。
規范要求非強制性地約束代碼開發人員的代碼編寫行為。在實際應用中,只要不違反常規要求,允許存在可理解的偏差。
基本要求
代碼中應用到的所有SQL關鍵字、保留字都需使用全大寫或小寫,例如select/SELECT、from/FROM、where/WHERE、and/AND、or/OR、union/UNION、insert/INSERT、delete/DELETE、group/GROUP、having/HAVING、count/COUNT等。不能使用大小寫混合的方式,例如Select或seLECT等方式。
代碼中應用到的除關鍵字、保留字之外的代碼,都要求使用小寫。
四個空格為一個縮進量,所有的縮進均為一個縮進量的整數倍。
禁止使用
SELECT *操作,所有操作必須明確指定列名。通常要求對應的括號在同一列上。
說明通過DataWorks或MaxCompute Studio編碼時,可以用格式化工具對SQL代碼進行格式化。
數據類型
MaxCompute Project的表字段類型應盡量與業務系統一致。
不推薦大量使用STRING類型,以免數據加工環節的數據質量問題無法及時暴露。
在對精度要求極其嚴格的場景下,請使用DECIMAL類型。
關于貨幣類型
中國貨幣單位統一為人民幣元,國際貨幣單位統一為美元。
除非模型有特殊說明,否則中間層金額相關的數據不執行任何四舍五入操作,以避免后續的匯總計算中出現不同口徑的匯總結果不一致的情況。
DataWorks編碼規范
通過DataWorks進行數據開發時,在DataWorks的數據開發工作臺上進行代碼編輯的規范。
代碼頭部
代碼頭部添加主題、功能描述、作者、日期等信息。并提供修改日志及標題欄的功能,以便后續修改人員添加修改記錄。每一行不能超過80個字符。
DataWorks中針對不同的任務類型提供了不同的代碼頭部模板,也可以在配置中心自定義頭部模板。例如,SQL類型任務頭部模板默認為如下。
--odps sql --********************************************************************-- --author:${author} --create time:${createTime} --********************************************************************--字段排列要求
SELECT語句選擇的字段按每行一個字段方式編排。
SELECT單字后面一個縮進量后應直接跟首個選擇的字段,即字段離首起二個縮進量。
其它字段前導二個縮進量再跟一個逗號(,)后放置字段名。
兩個字段之間的逗號(,)分割符緊跟在第二個字段的前面。
AS語句應與相應的字段在同一行,多個字段的AS建議盡量對齊在同一列上。
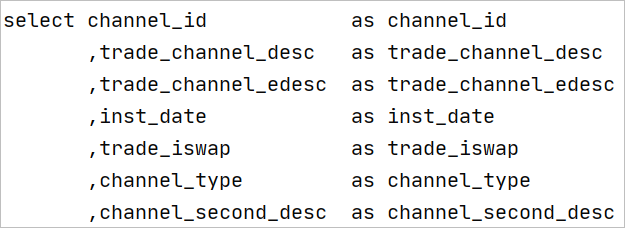
SELECT子句排列要求
SELECT語句中所用到的FROM、WHERE、GROUP BY、HAVING、ORDER BY、JOIN、UNION等子句,需遵循如下要求:
換行編寫。
與相應的SELECT語句左對齊編排。
子句后續的代碼離子句首字母二個縮進量起編寫。
WHERE子句下的邏輯判斷符AND、OR等與WHERE左對齊編排。
超過兩個縮進量長度的子句加一空格后編寫后續代碼。例如ORDER BY、GROUP BY等。

運算符前后間隔要求
算術運算符、邏輯運算符的前后要保留一個空格。
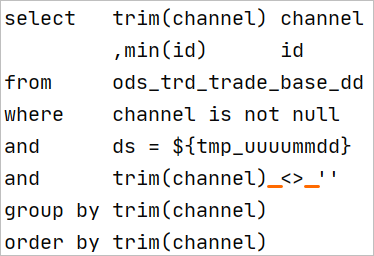
CASE語句的編寫
SELECT語句中對字段值進行判斷取值的操作將用到CASE語句,正確的編排CASE語句對加強代碼行的可讀性也是很關鍵的一部分。對CASE語句編排的約定如下:
WHEN子句在CASE語句的同一行并縮進一個縮進量后開始編寫。
每個WHEN子句單獨一行編寫,如果語句較長可換行編寫。
CASE語句必須包含ELSE子語,ELSE子句與WHEN子句對齊。
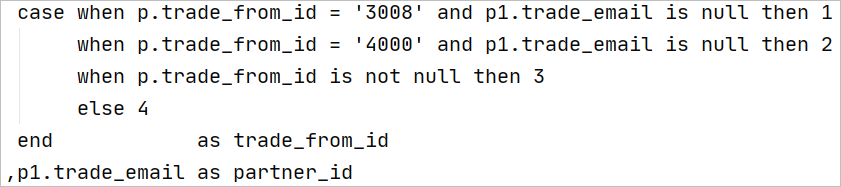
子查詢嵌套編寫規范
在數據倉庫系統ETL開發中經常需要用到子查詢嵌套,因此代碼的分層編排變得非常重要。

表別名定義約定
建議對所有的表加上別名。一旦在SELECT語句中對表定義了別名,在整個語句中對此表的引用都必須以別名替代。考慮到編寫代碼的便捷性,約定別名盡量簡潔,同時避免使用關鍵字。 表別名定義約定如下:
表別名采用簡單字符命名。
多層次的嵌套子查詢,在別名之前要體現層次關系。SQL語句別名或分層的命名,從第一層次至第四層次,分別用P、S、U、D表示,取意為Part,Segment,Unit,Detail。也可用a、b、c、d來表示第一層次到第四層次。對于同一層次的多個子句,可以在字母后加1、2、3、4區分。
必要時,為表別名添加注釋。

SQL注釋
每條SQL語句均應添加注釋說明。
每條SQL語句的注釋單獨成行并置于語句前面。
字段注釋緊跟在字段后面。
應該為不易理解的分支條件表達式添加注釋。
應說明重要計算的功能。
過長的函數實現,應將其語句按實現的功能分段加以概括性說明。
常量及變量注釋時,必須注釋被保存值的含義,按需注釋合法的取值范圍。
MaxCompute項目空間名稱的編寫
本項目空間(Project)的名稱不需在編碼中體現。如果引用了其他項目空間的表,則需要在表名前加上項目空間名稱。示例如下。
--當前Project為prj_bi。 INSERT OVERWRITE TABLE test_2 SELECT c1 ,c2 ,c3 FROM prj_ods.test_1 WHERE ds = 20181212 ;
DataWorks任務發布規范
發布上線的時間根據業務定義。
無QA人員參與的項目,由開發負責自測,開發測試環境通過后再自行發布到生產環境。
有QA人員參與的項目,開發負責提交到調度開發環境并測試通過,而正式上線則由QA負責打包發布到生產環境。