MaxCompute中不同類型計算任務的操作對象(輸入、輸出)都是表。表設計是否合理將影響存儲和計算的性能,進而影響到存儲和計算的計費。
聲明
本文中介紹的非功能性規范均為建議性規范,產品功能無限制,僅供參考。
表設計主要目標
降低存儲成本
合理的表設計可以降低數據分層設計上的冗余存儲,減少中間表的數據量大小。對表數據的生命周期進行正確的管理,也能夠直接降低存儲的數據量及存儲成本。
降低計算成本
規范化的表設計可以幫助您優化數據的讀取,從而減少計算過程中的冗余讀寫和計算,提升計算性能,降低計算成本。
降低維護成本
規范化的表分層設計能夠直接體現業務的特點。例如,在規范化設計表的同時對數據通道中的數據采集方式進行優化,可以減少分布式系統中小文件的問題,降低表和分區的維護數量。
表設計主要影響
表設計影響的操作有:創建表、導入數據、更新表、刪除表及管理表。
其中,導入數據場景按照實時數據采集和離線導入批量數據的方式分為如下三種:
導入后立即查詢與計算。導入后立即查詢與計算,需要考慮每次導入的數據量,減少流式小量數據導入。
多次導入并定時查詢與計算。
導入后生成中間表進行計算。
合理的表設計和數據集成周期管理能夠降低數據在存儲期間的成本。不合理的數據導入及存儲(小文件)會影響整體的存儲性能、計算性能、運維穩定性。MaxCompute優先按照業務邏輯對批量數據進行計算,例如,按照分區進行計算。
表設計步驟
確定所屬項目空間,依據業務過程規劃表類型,分析數據層次。
定義表描述,進行權限定義與Owner定義。
依據數據量、數據集成特點定義分區表或非分區表。
定義字段或分區字段。
創建表和轉換表。
明確導入數據場景的相關因素(包括批量數據寫入、流式數據寫入、周期性條式數據插入)。
定義表和分區的生命周期。
創建完表后,您可以根據業務變化修改表的Schema。例如,設置生命周期RangeClustering。
在表設計階段,需要特別注意區分數據的場景(批量數據寫入、流式數據寫入、周期性條式數據插入)。
合理使用非分區表和分區表。建議采用分區表來設計日志表、事實表和原始采集表等,并按照時間進行分區。
注意表和分區的限制條件。
表數據存儲規范
按數據層規劃數據的生命周期:
源表ODS層:每天從業務系統同步過來的數據,全部保留,生命周期定義永久保存。當下游數據受損時,可以從ODS恢復數據。若ODS每天同步過來的是全量表,則可以通過全表拉鏈的方式來壓縮存儲。
數據倉庫(基礎)層:至少保留一份完整的全量數據(不必像ODS那樣存儲冗余的全量表)。您可以通過拆表或者做分區來提升性能。
數據集市層:數據將被按需保留1~3年。數據集市的數據比較容易生成,所以無需保留久遠的歷史數據。
按數據變更規劃數據的保存方式:
記錄客戶屬性、產品屬性的歷史變化情況,以便追溯某個時點的值。
在事實表里冗余維表的字段,即把事件發生時的各種維度屬性值與該事件綁定起來。使用者無需關聯多張表就可以使用數據。此方式僅可應用于數據應用層。
任意用拉鏈表或者日快照的形式,記錄維表的變化情況。這使得數據結構變得靈活、易于擴展,數據一致性得到了增強,數據加工者可以更加方便地管理數據。此方式僅可應用于數據基礎層。
數據導入通道與表設計
通道類型有以下幾種:
DataHub
規劃寫入的分區與寫入流量之間的關系。數據達到64 MB會執行1次Commit。
數據集成或DataX
規劃寫入表分區的頻率。數據達到64 MB會執行1次Commit,以免Commit空目錄。
DTS
規劃寫入的表存量分區與增量分區的關系。設置Commit頻率。
客戶端(Run SQL or Tunnel upload)
需要避免高頻小數據量文件的插入或者上傳。
SDK
SDK執行INSERT INTO語句,數據上傳至表或者分區后,使用MERGE語句整理小文件。
MaxCompute導入數據的通道只能是Tunnel SDK或執行INSERT INTO語句,請避免流式插入數據。
以上各通道本身均由自身邏輯進行流式數據寫入、批量數據寫入和周期調度寫入。
當使用數據通道寫入表或分區時,需將1次寫入的數據量控制在合理范圍,例如,64 MB以上。
分區設計與存儲邏輯
一張表里有很多個一級分區,每個一級分區都會按時間存儲二級分區,每個二級分區都會存儲所有的列,如下圖所示。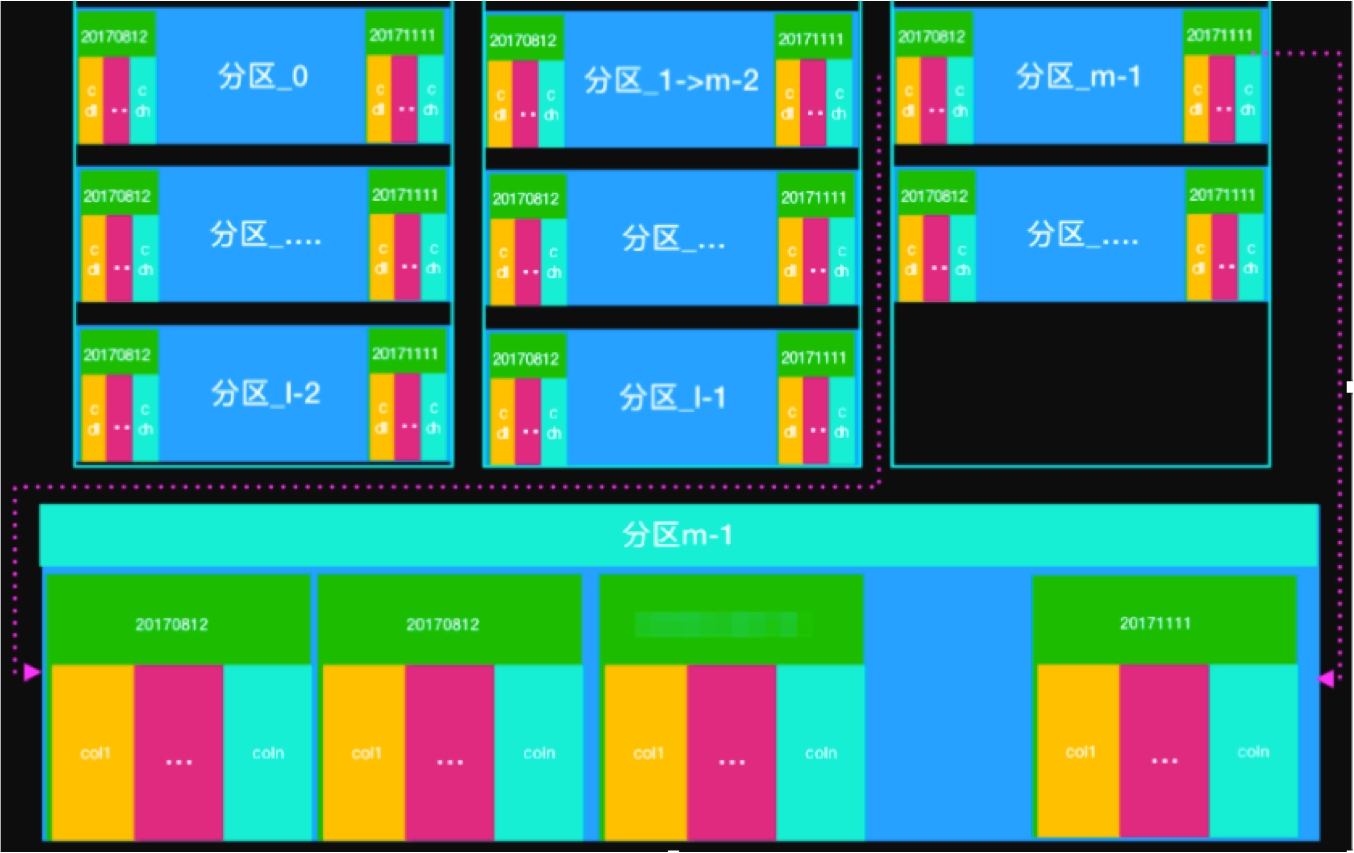 分區設計需要注意:
分區設計需要注意:
設置分區的數量上限。
避免每個分區中只存少量數據。
以方便數據查詢和計算為前提設置分區列。
避免每個分區中出現多次數據寫入。
表和分區設計的基本規則
所有的表和字段名要使用統一的命名規范。命名要求如下:
能區分該表的業務類型。
能區分該表是事實表、維度表、日志表或極限存儲表。
能區分該表的實體信息。
不同表中具有相同業務含義的字段要定義成統一的數據類型,避免不必要的類型轉換。
分區設計及使用規則如下:
支持新增分區,不支持新增分區字段。
單表支持的分區數量上限為6萬個。
對于多級分區的表,如果想添加新的分區,則必須指明全部的分區值。
不支持修改分區列的列名,只能修改分區列對應的值。修改多級分區的一個或者多個分區值時,多級分區的每一級的分區值都必須寫上。
分區設計
在計算的時候可以使用分區裁剪是分區的優勢。分區設計需要關注如下內容:
分區字段和普通字段選擇
通過分區字段,您可以劃分數據掃描范圍,更加方便地管理數據。
您可以在創建表時設置普通字段和分區字段。普通字段可以被理解為數據文件的數據,而分區字段可以被理解為文件系統的目錄。表的存儲空間主要是普通字段占用的空間。設置分區字段時,您可以從數據管理和數據掃描方面考慮,來選擇對應的字段。不具備規律、類型數量大于10000且不經常作為查詢條件的字段,應該被設置成普通字段。
分區列雖不直接存儲數據,但如同文件系統里的目錄,可以方便您管理數據。例如,在計算時如果指定具體的分區,則計算過程中只需查詢對應分區,從而減少計算輸入量。
分區表的分區列級數不能超過6級,即底層存儲數據的目錄層數不能超過6層。因此應為分區表設置合適的生命周期。當部分數據的生命周期與其它數據不同時,您可以通過細粒度分區實現對部分數據的管理。
分區字段定義依據
按優先級高低排序如下:
分區列的選擇應充分考慮時間因素,盡量避免更新存量分區。
如果有多個事實表(不包括維度表)進行JOIN,應將作為查詢條件的字段置為分區列。
選擇GROUP BY或DISTINCT包含的列作為分區列。
選擇值分布均勻的列,而不要選擇數據傾斜的列作為分區列。
常用SQL語句中如果包含某列的等值或IN的查詢條件,則選擇該列作為分區列。
select … from table where id=123 and ….;
分區個數定義依據
時間分區
建議按天或月進行分區。如果按小時進行分區,則二級分區的平均數量不應超過8個。
地域分區
如果對省、市、縣進行分區,則應考慮進行多級分區。23個省,5個自治區,4個直轄市,2個特別行政區,50個地區(州、盟),661個市(其中直轄市4個、地級市283個、縣級市374個),1636個縣(自治縣、旗、自治旗、特區和林區),按照最細粒度縣進行分區后,不應再按照更細粒度的小時進行分區。
單分區與多級分區
在單分區下,建議每次寫入的數據量不超過64 MB。如果為多級分區,則需保證每個最細粒度級分區下的二級分區數據都遵循單分區個數規則。
單表分區
單表分區數(包括下級分區)不能超過6萬。
分區數量和數據量建議
建議單個分區中的數據量不要太大。
應盡量避免分區數據傾斜,避免單個表不同分區的數據量差異超過100萬。
分區設計時應合理規劃分區個數,較細粒度的分區在跨分區掃描時會影響SQL的執行性能。
單個分區中數據量較大的情況下,MaxCompute執行任務時會進行分片處理而不影響分區裁剪的優勢。
單個分區中文件數較多時,會影響MaxCompute Instance數量,造成資源浪費和SQL性能的下降。
采用多級分區時,建議先按日期分區,然后按交易類型分區。
多種交易類型混合的表,建議您拆表,一種交易類型獨立成一張表,然后每張表按日期分區。
維度表不進行分區。