Hologres從V2.0版本開始支持Runtime Filter,在多表Join場景下自動優化Join過程的過濾行為,提升Join的查詢性能。本文為您介紹在Hologres中Runtime Filter的使用。
背景信息
應用場景
Hologres從V2.0版本開始支持Runtime Filter,通常應用在多表(兩表及以上)Join的Hash Join場景,尤其是大表Join小表的場景中,無需手動設置,優化器和執行引擎會在查詢時自動優化Join過程的過濾行為,從而降低I/O開銷,以提升Join的查詢性能。
原理介紹
在了解Runtime Filter原理之前,需先了解Join過程。兩個表Join的SQL示例如下:
select * from test1 join test2 on test1.x = test2.x;其對應的執行計劃如下。

如上執行計劃,兩個表Join時,會通過test2表構建Hash表,然后匹配test1表的數據,最后返回結果。在這個過程中,Join時會涉及到兩個名詞:
build端:兩表(或者子查詢)做Hash Join時,其中一張表(子查詢)的數據會構建成Hash表,這一部分稱為build端,對應計劃里的Hash節點。
probe端:Hash Join的另一邊,主要是讀取數據然后和build端的Hash表進行匹配,這一部分稱為probe端。
通常來說,在執行計劃正確的情況下,小表是build端,大表是probe端。
Runtime Filter的原理就是在HashJoin過程中,利用build端的數據分布,生成一個輕量的過濾器(filter),發送給probe端,對probe端的數據進行裁剪,從而減少probe端真正參與Hash Join以及網絡傳輸的數據量,以此來提升Hash Join性能。
因此Runtime Filter更適用于大小表Join,且表數據量相差較大的場景,性能將會比普通Join有更多的提升。
使用限制和觸發條件
使用限制
僅Hologres V2.0及以上版本支持Runtime Filter。
僅支持Join條件中只有一個字段,如果有多個字段將不會觸發Runtime Filter。從Hologres V2.1版本開始,Runtime Filter支持多個字段Join,如果多個Join字段滿足觸發條件,也會觸發Runtime Filter。
觸發條件
Hologres本身支持高性能的Join,因此Runtime Filter會根據查詢條件在底層自動觸發,但是需要SQL滿足下述所有條件才能觸發:
probe端的數據量在100000行及以上。
掃描的數據量比例:
build端 / probe端 <= 0.1(比例越小,越容易觸發Runtime Filter)。Join出的數據量比例:
build端 / probe端 <= 0.1(比例越小,越容易觸發Runtime Filter)。
Runtime Filter的類型
可以根據以下兩個維度對Runtime Filter進行分類。
按照Hash Join的probe端是否需要進行Shuffle,可分為Local和Global類型。
Local類型:Hologres V2.0及以上版本支持。當Hash Join的probe端不需要Shuffle時,build端數據有如下三種情況,均可以使用Local類型的Runtime Filter:
build端和probe端的Join Key是同一種分布方式。
build端數據broadcast給probe端。
build端數據按照probe端數據的分布方式Shuffle給Probe端。
Global類型:Hologres V2.2及以上版本支持。當probe端數據需要Shuffle時,Runtime Filter需要合并后才可以使用,這種情況需要使用Global類型的Runtime Filter。
Local類型的Runtime Filer僅可能減少數據掃描量以及參與Hash Join計算的數據量,Global類型的Runtime Filter由于probe端數據會Shuffle,在數據Shuffle之前做過濾還可以減少數據的網絡傳輸量。類型都無需手動指定,引擎會自適應。
按照Filter類型,可分為Bloom Filter、In Filter和MinMAX Filter。
Bloom Filter:Hologres V2.0及以上版本支持。Bloom Filter具有一定假陽性,導致少過濾一些數據,但其應用范圍廣,在build端數據量較多是仍能有較高的過濾效率,提升查詢性能。
In Filter:Hologres V2.0及以上版本支持。In Filter在build端數據NDV(Number of Distinct Value,列的非重復值的個數)較小時使用,其會使用build端數據構建一個HashSet發送給probe端進行過濾,In Filter的優勢是可以過濾所有應該過濾的數據,且可以和Bitmap索引結合使用。
MinMAX Filter:Hologres V2.0及以上版本支持。MinMAX Filter會根據build端數據得到最大值和最小值,發送給probe端做過濾,其優勢為可能根據元數據信息直接過濾掉文件或一個Batch的數據,減少I/O成本。
三種Filter類型無需您手動指定,Hologres會根據運行時Join情況自適應使用各種類型的Filter。
驗證Runtime Filter
如下示例幫助您更好地理解Runtime Filter。
示例1:Join條件中只有1列,使用Local類型Runtime Filter
示例代碼:
begin; create table test1(x int, y int); call set_table_property('test1', 'distribution_key', 'x'); create table test2(x int, y int); call set_table_property('test2', 'distribution_key', 'x'); end; insert into test1 select t, t from generate_series(1, 100000) t; insert into test2 select t, t from generate_series(1, 1000) t; analyze test1; analyze test2; explain analyze select * from test1 join test2 on test1.x = test2.x;執行計劃:

test2表只有1000行,test1表有100000行,build端和probe端的數據量比例是0.01,小于0.1,且Join出來的數據量build端和probe端比例是0.01,小于0.1,滿足Runtime Filter的默認觸發條件,因此引擎會自動使用Runtime Filter。probe端的
test1表有Runtime Filter Target Expr節點,表示probe端使用了Runtime Filter下推。probe端的scan_rows代表從存儲中讀取的數據,有100000行,rows代表使用Runtime Filter過濾后,scan算子的行數,為1000行,可以從這兩個數據上看Runtime Filter的過濾效果。
示例2:Join條件中有多列(Hologres V2.1版本支持),使用Local類型Runtime Filter
示例代碼:
drop table if exists test1, test2; begin; create table test1(x int, y int); create table test2(x int, y int); end; insert into test1 select t, t from generate_series(1, 1000000) t; insert into test2 select t, t from generate_series(1, 1000) t; analyze test1; analyze test2; explain analyze select * from test1 join test2 on test1.x = test2.x and test1.y = test2.y;執行計劃:

Join條件有多列,Runtime Filter也生成了多列。
build端broadcast,可以使用Local類型的Runtime Filter。
示例3:Global類型Runtime Filter支持Shuffle Join(Hologres V2.2版本支持)
示例代碼:
SET hg_experimental_enable_result_cache = OFF; drop table if exists test1, test2; begin; create table test1(x int, y int); create table test2(x int, y int); end; insert into test1 select t, t from generate_series(1, 100000) t; insert into test2 select t, t from generate_series(1, 1000) t; analyze test1; analyze test2; explain analyze select * from test1 join test2 on test1.x = test2.x;執行計劃:
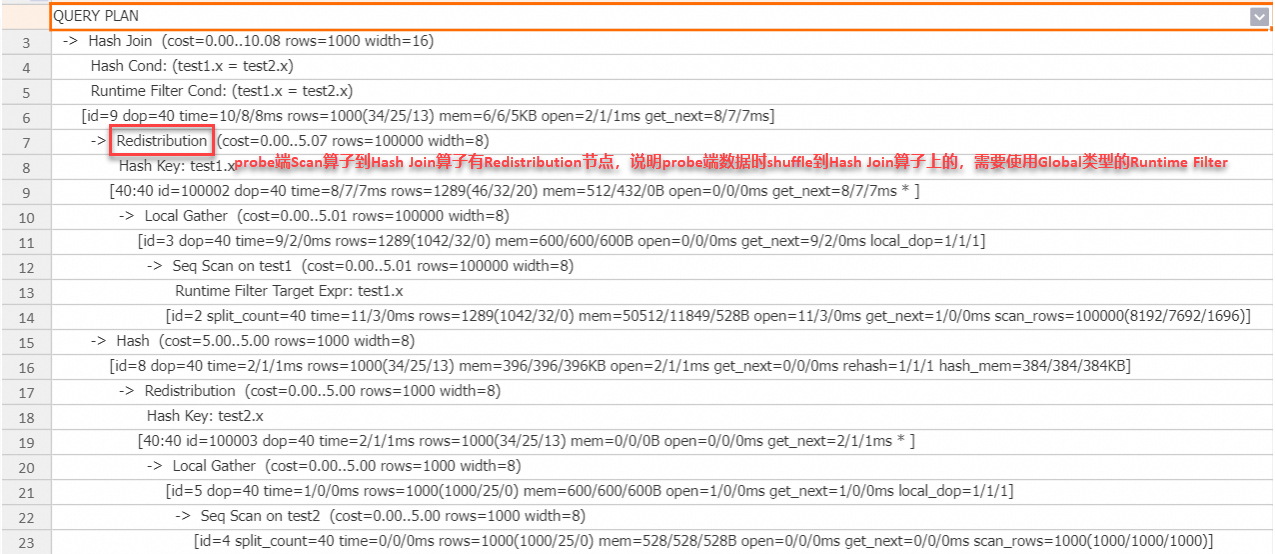
從上述執行計劃可以看出,probe端數據被Shuffle到Hash Join算子,引擎會自動使用Global Runtime Filter來加速查詢。
示例4:In類型的Filter結合bitmap索引(Hologres V2.2版本支持)
示例代碼:
set hg_experimental_enable_result_cache=off; drop table if exists test1, test2; begin; create table test1(x text, y text); call set_table_property('test1', 'distribution_key', 'x'); call set_table_property('test1', 'bitmap_columns', 'x'); call set_table_property('test1', 'dictionary_encoding_columns', ''); create table test2(x text, y text); call set_table_property('test2', 'distribution_key', 'x'); end; insert into test1 select t::text, t::text from generate_series(1, 10000000) t; insert into test2 select t::text, t::text from generate_series(1, 50) t; analyze test1; analyze test2; explain analyze select * from test1 join test2 on test1.x = test2.x;執行計劃:
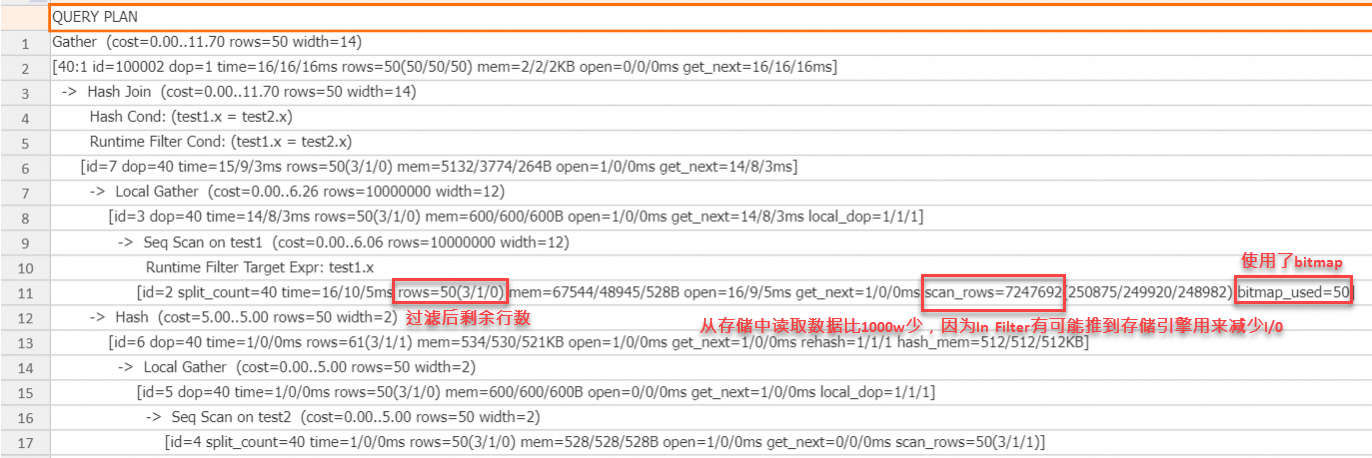
從上述執行計劃可以看出,在probe端的scan算子上,使用了bitmap,因為In Filter可以精確過濾,因此過濾后還剩50行,scan算子中的scan_rows為700多萬,比原始行數1000萬少,這是因為In Filter可以推到存儲引擎,有可能減少I/O成本,最終結果是從存儲引擎中讀取的數據變少了,In類型的Runtime Filter結合bitmap通常在Join Key為STRING類型時,有明顯作用。
示例5:MinMax類型的Filter減少I/O(Hologres V2.2版本支持)
示例代碼:
set hg_experimental_enable_result_cache=off; drop table if exists test1, test2; begin; create table test1(x int, y int); call set_table_property('test1', 'distribution_key', 'x'); create table test2(x int, y int); call set_table_property('test2', 'distribution_key', 'x'); end; insert into test1 select t::int, t::int from generate_series(1, 10000000) t; insert into test2 select t::int, t::int from generate_series(1, 100000) t; analyze test1; analyze test2; explain analyze select * from test1 join test2 on test1.x = test2.x;執行計劃:
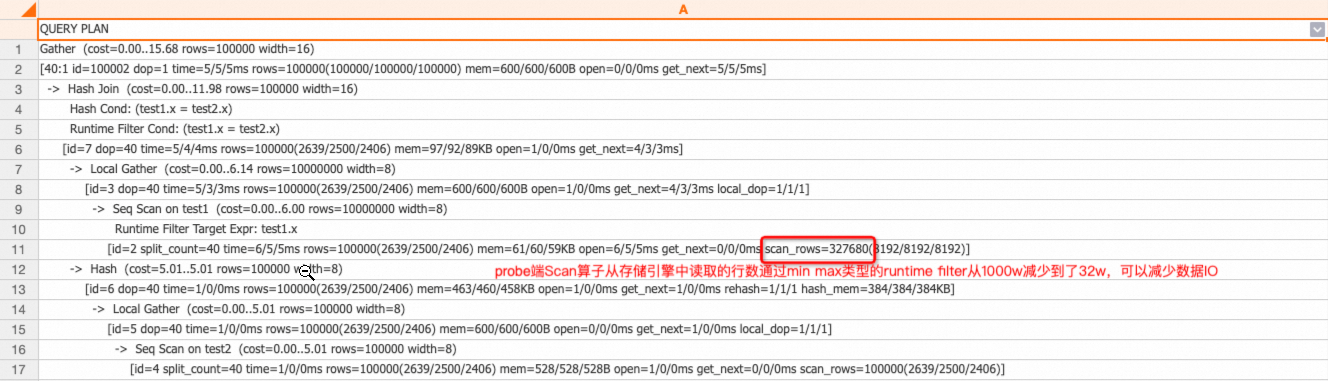
從上述執行計劃可以看出,probe端scan算子從存儲引擎讀取的行數為32萬多,比原始行數1000萬少了很多,這是因為Runtime Filter被下推到存儲引擎,利用一個batch數據的meta信息整批過濾數據,有可能大量減少I/O成本。通常在Join Key為數值類型,且build端值域范圍比probe端的值域范圍小時,有明顯效果。