其實HBase還是比較靈活的,關鍵看你是否使用得當,以下主要列舉一些讀的優化。HBase在生產中往往會遇到Full GC、進程OOM、RIT問題、讀取延遲較大等一些問題,使用更好的硬件往往可以解決一部分問題,但是還是需要使用的方式。
我們把優化分為:
客戶端優化、服務端優化、平臺優化(ApsaraDB for HBase)
客戶端優化
get請求是否可以使用批量請求
這樣可以成倍減小客戶端與服務端的rpc次數,顯著提高吞吐量。
Result[] re= table.get(List<Get> gets)大scan緩存是否設置合理
scan一次性需求從服務端返回大量的數據,客戶端發起一次請求,服務端會分多批次返回客戶端,這樣的設計是避免一次性傳輸較多的數據給服務端及客戶端有較大的壓力。目前數據會加載到本地的緩存中,默認100條數據大小。一些大scan需要獲取大量的數據,傳輸數百次甚至數萬的rpc請求。我們建議可以適當放開緩存的大小。
scan.setCaching(int caching) //大scan可以設置為1000請求指定列族或者列名
HBase是列族數據庫,同一個列族的數據存儲在一塊,不同列族是分開的,為了減小IO,建議指定列族或者列名。
離線計算訪問Hbase建議禁止緩存
當離線訪問HBase時,往往就是一次性的讀取,此時讀取的數據沒有必要存放在blockcache中,建議在讀取時禁止緩存。
scan.setBlockCache(false)服務端優化
請求是否均衡
讀取的壓力是否都在一臺或者幾臺之中,在業務高峰期間可以查看下,可以到HBase管控平臺查看HBase的UI。如果有明顯的熱點,一勞永逸的做法是重新設計rowkey,短期是把熱點地域嘗試拆分。
BlockCache是否合理
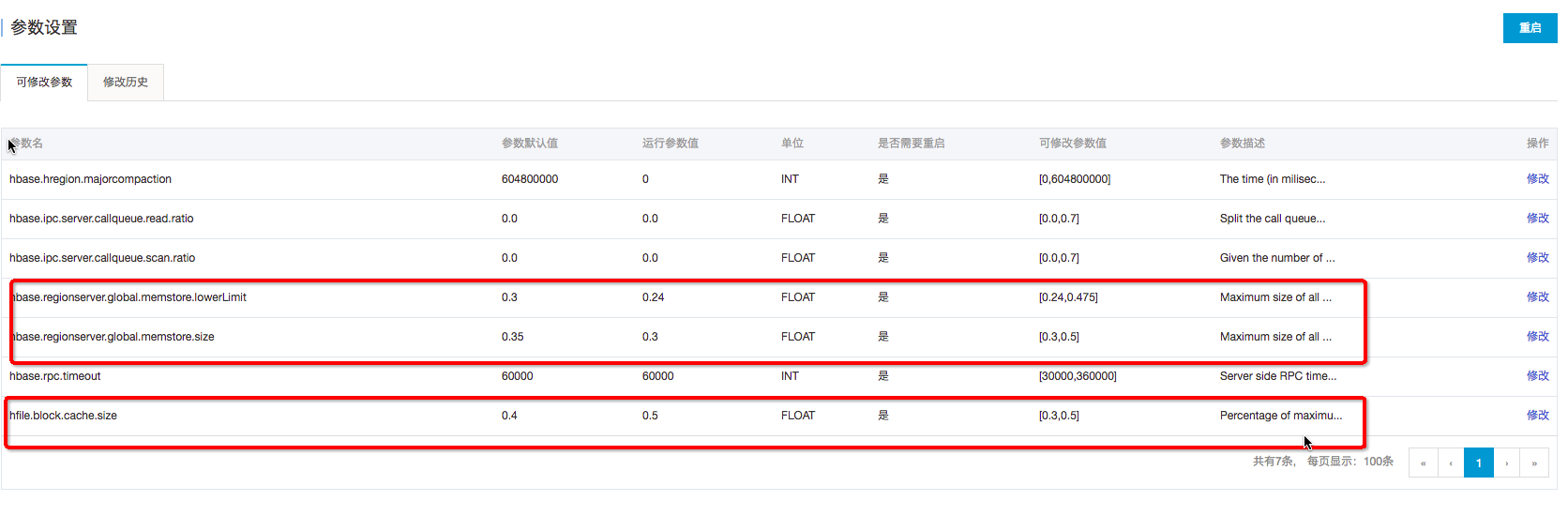
BlockCache作為讀緩存,對于讀的性能比較重要,如果讀比較多,建議內存使用1:4的機器,比如:8cpu32g或者16pu64g的機器。當前可以調高BlockCache的數值,降低Memstore的數值。
在ApsaraDB for HBase控制臺可以完成:hfile.block.cache.size改為0.5 ; hbase.regionserver.global.memstore.size 改為0.3;再重啟。
HFile文件數目
因為讀取需要頻繁打開HFile,如果文件越多,IO次數就越多,讀取的延遲就越高,此時需要定時做major compaction,如果晚上的業務壓力不大,可以在晚上做major compaction。
Compaction是否消耗較多的系統資源
compaction主要是將HFile的小文件合并成大文件,提高后續業務的讀性能,但是也會帶來較大的資源消耗。Minor Compaction一般情況下不會帶來大量的系統資源消耗,除非因為配置不合理。切勿在高峰期間做 major compaction。建議在業務低峰期做major compaction。
Bloomfilter設置是否合理
Bloomfilter主要用來在查詢時,過濾HFile的,避免不需要的IO操作。Bloomfilter能提高讀取的性能,一般情況下創建表,都會默認設置為:BLOOMFILTER =>‘ROW’
平臺端優化
數據本地率是否太低?(平臺已經優化)
Hbase 的HFile,在本地是否有文件,如果有文件可以用Short-Circuit Local Read,目前平臺在重啟、磁盤擴容時,都會自動拉回移動出去的地域,不降低數據本地率;另外定期做major compaction也有益于提高本地化率。
Short-Circuit Local Read (已經默認開啟)
當前HDFS讀取數據需要經過DataNode,開啟Short-Circuit Local Read后,客戶端可以直接讀取本地數據。
Hedged Read (已經默認開啟)
優先會通過Short-Circuit Local Read功能嘗試本地讀。但是在某些特殊情況下,有可能會出現因為磁盤問題或者網絡問題引起的短時間本地讀取失敗,為了應對這類問題,開發出了Hedged Read。該機制基本工作原理為:客戶端發起一個本地讀,一旦一段時間之后還沒有返回,客戶端將會向其他DataNode發送相同數據的請求。哪一個請求先返回,另一個就會被丟棄。
關閉swap區(已經默認關閉)
swap是當物理內存不足時,拿出部分的硬盤空間當做swap使用,解決內存不足的情況。但是會有較大的延遲的問題,所以我們HBase平臺默認關閉。 但是關閉swap導致anon-rss很高,page reclaim沒辦法reclaim足夠的page,可能導致內核掛住,平臺已經采取相關隔離措施避免此情況。