云數據庫HBase增強版支持冷熱分離功能,可以將冷熱數據存儲在不同的介質中,有效提升熱數據的查詢效率,同時降低數據存儲成本。
背景信息
在海量大數據場景下,一張表中的部分業務數據隨著時間的推移僅作為歸檔數據或者訪問頻率很低,同時這部分歷史數據體量非常大,比如訂單數據或者監控數據,降低這部分數據的存儲成本將會極大的節省企業的成本。因此,如何以極簡的運維配置最大程度地降低存儲成本,成為了數據庫產品新的課題。為實現這一目標,阿里云HBase增強版冷熱分離功能應運而生。阿里云HBase增強版為冷數據提供新的存儲介質,新的存儲介質存儲成本僅為高效云盤的1/3。
HBase增強版在同一張表里實現了數據的冷熱分離,系統會自動根據用戶設置的冷熱分界線自動將表中的冷數據歸檔到冷存儲中。在用戶的訪問方式上和訪問普通表沒有任何差異,在查詢的過程中,用戶只需配置查詢的Hint或者TimeRange,系統會根據條件自動地判斷數據應該在熱數據區還是冷數據區。
原理介紹
用戶在表上配置數據冷熱時間分界點后,HBase增強版會依賴用戶寫入數據的時間戳(毫秒)和時間分界點來判斷數據的冷熱。數據開始存儲在熱存儲上,隨意時間的推移慢慢往冷存儲上遷移。同時用戶可以任意變更數據的冷熱分界點,數據可以從熱存儲到冷存儲,也可以從冷存儲到熱存儲。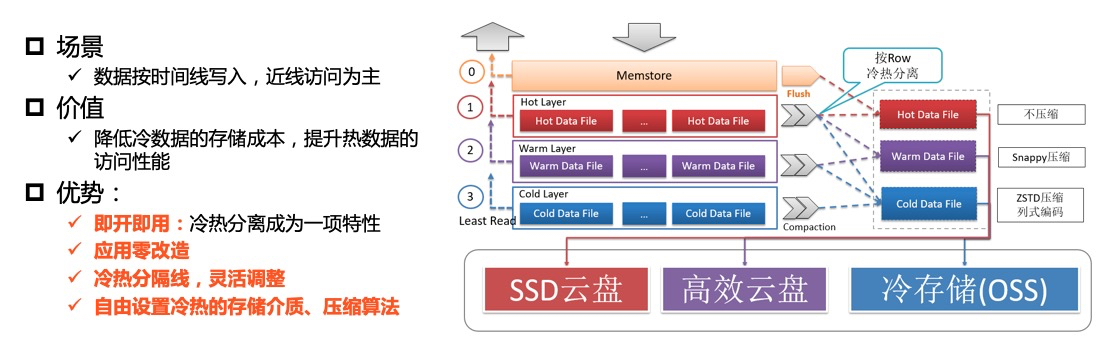
注意事項
參見使用冷存儲中的注意事項。
使用方法
冷存儲功能需要HBase增強版服務端升級到2.1.8及以上版本,但無需修改數據讀寫鏈路的客戶端依賴,只需要選擇以下一種方式修改表結構即可:
使用Java API:要求AliHBase-Connector 1.0.7/2.0.7以上,請參考使用Java API訪問增強版集群中的步驟完成Java SDK安裝和參數配置。
使用HBase Shell:要求alihbase-2.0.7-bin.tar.gz以上,請按照使用HBaseue Shell訪問增強版集群中的步驟完成Shell的下載和配置。
開通冷存儲功能
請參照使用冷存儲開通集群的冷存儲功能。
為表設置冷熱分界線
用戶在使用過程中可以隨時調整COLD_BOUNDARY來劃分冷熱的邊界。COLD_BOUNDARY的單位為秒,如COLD_BOUNDARY => 86400 代表86400秒(一天)前寫入的數據會被自動歸檔到冷存儲介質上。
在冷熱分離使用過程中,無需把列簇的屬性設置為COLD,如果已經把列簇的屬性設置為了COLD,請參見使用冷存儲將冷存儲的屬性去除。
Shell
// 創建冷熱分離表
hbase(main):002:0> create 'chsTable', {NAME=>'f', COLD_BOUNDARY=>'86400'}
// 取消冷熱分離
hbase(main):004:0> alter 'chsTable', {NAME=>'f', COLD_BOUNDARY=>""}
// 為已經存在的表設置冷熱分離,或者修改冷熱分離分界線,單位為秒
hbase(main):005:0> alter 'chsTable', {NAME=>'f', COLD_BOUNDARY=>'86400'}Java API方式
// 新建冷熱分離表
Admin admin = connection.getAdmin();
TableName tableName = TableName.valueOf("chsTable");
HTableDescriptor descriptor = new HTableDescriptor(tableName);
HColumnDescriptor cf = new HColumnDescriptor("f");
// COLD_BOUNDARY 設置冷熱分離時間分界點,單位為秒, 示例表示1天之前的數據歸檔為冷數據
cf.setValue(AliHBaseConstants.COLD_BOUNDARY, "86400");
descriptor.addFamily(cf);
admin.createTable(descriptor);
// 取消冷熱分離
// 注意:需要做major compaction,數據才能從冷存儲上回到熱存儲上
HTableDescriptor descriptor = admin
.getTableDescriptor(tableName);
HColumnDescriptor cf = descriptor.getFamily("f".getBytes());
// 取消冷熱分離
cf.setValue(AliHBaseConstants.COLD_BOUNDARY, null);
admin.modifyTable(tableName, descriptor);
// 為已經存在的表設置冷熱分離功能,或者修改冷熱分離分界線
HTableDescriptor descriptor = admin
.getTableDescriptor(tableName);
HColumnDescriptor cf = descriptor.getFamily("f".getBytes());
// COLD_BOUNDARY 設置冷熱分離時間分界點,單位為秒, 示例表示1天之前的數據歸檔為冷數據
cf.setValue(AliHBaseConstants.COLD_BOUNDARY, "86400");
admin.modifyTable(tableName, descriptor);數據寫入
冷熱分離的表與普通表的數據寫入方式完全一致,用戶可以參照使用Java API訪問增強版集群文檔中的方式或者使用多語言API訪問對表進行數據寫入。數據的寫入的時間戳使用的是當前時間。數據先會存儲在熱存儲(云盤)中。隨著時間的推移,如果這行數據的寫入時間超過COLD_BOUNDARY設置的值,就會在major_compact時歸檔到冷數據,此過程完全對用戶透明。
數據查詢
由于冷熱數據都在同一張表中,用戶全程只需要和一張表交互。在查詢過程中,如果用戶明確知道需要查詢的數據在熱數據里(寫入時間少于COLD_BOUNDARY設置的值),可以在Get或者Scan上設置HOT_ONLY的Hint來告訴服務器只查詢熱區數據。或者在Get/Scan上設置TimeRange來限定查詢數據的時間,系統會根據設置TimeRange決定是查詢熱區,冷區還是冷熱都查。查詢冷區數據延遲要比熱區數據延遲高的多,并且查詢吞吐受到冷存儲限制。
查詢示例
Get
Shell
// 不帶HotOnly Hint的查詢,可能會查詢到冷數據 hbase(main):013:0> get 'chsTable', 'row1' // 帶HotOnly Hint的查詢,只會查熱數據部分,如row1是在冷存儲中,該查詢會沒有結果 hbase(main):015:0> get 'chsTable', 'row1', {HOT_ONLY=>true} // 帶TimeRange的查詢,系統會根據設置的TimeRange與COLD_BOUNDARY冷熱分界線進行比較來決定查詢哪個區域的數據(注意TimeRange的單位為毫秒時間戳) hbase(main):016:0> get 'chsTable', 'row1', {TIMERANGE => [0, 1568203111265]}Java
Table table = connection.getTable("chsTable"); // 不帶HotOnly Hint的查詢,可能會查詢到冷數據 Get get = new Get("row1".getBytes()); System.out.println("result: " + table.get(get)); // 帶HotOnly Hint的查詢,只會查熱數據部分,如row1是在冷存儲中,該查詢會沒有結果 get = new Get("row1".getBytes()); get.setAttribute(AliHBaseConstants.HOT_ONLY, Bytes.toBytes(true)); // 帶TimeRange的查詢,系統會根據設置的TimeRange與COLD_BOUNDARY冷熱分界線進行比較來決定查詢哪個區域的數據(注意TimeRange的單位為毫秒時間戳) get = new Get("row1".getBytes()); get.setTimeRange(0, 1568203111265)
Scan
如果scan不設置Hot Only,或者TimeRange包含冷區時間,則會并行訪問冷數據和熱數據來合并結果,這是由于HBase的Scan原理決定的。
Shell
// 不帶HotOnly Hint的查詢,一定會查詢到冷數據 hbase(main):017:0> scan 'chsTable', {STARTROW =>'row1', STOPROW=>'row9'} // 帶HotOnly Hint的查詢,只會查詢熱數據部分 hbase(main):018:0> scan 'chsTable', {STARTROW =>'row1', STOPROW=>'row9', HOT_ONLY=>true} // 帶TimeRange的查詢,系統會根據設置的TimeRange與COLD_BOUNDARY冷熱分界線進行比較來決定查詢哪個區域的數據(注意TimeRange的單位為毫秒時間戳) hbase(main):019:0> scan 'chsTable', {STARTROW =>'row1', STOPROW=>'row9', TIMERANGE => [0, 1568203111265]}
Java
TableName tableName = TableName.valueOf("chsTable"); Table table = connection.getTable(tableName); // 不帶HotOnly Hint的查詢,一定會查詢到冷數據 Scan scan = new Scan(); ResultScanner scanner = table.getScanner(scan); for (Result result : scanner) { System.out.println("scan result:" + result); } // 帶HotOnly Hint的查詢,只會查詢熱數據部分 scan = new Scan(); scan.setAttribute(AliHBaseConstants.HOT_ONLY, Bytes.toBytes(true)); // 帶TimeRange的查詢,系統會根據設置的TimeRange與COLD_BOUNDARY冷熱分界線進行比較來決定查詢哪個區域的數據(注意TimeRange的單位為毫秒時間戳) scan = new Scan(); scan.setTimeRange(0, 1568203111265);
冷熱分離表中的冷區只是用來歸檔數據,查詢請求應該非常的少,用戶查詢冷熱分離表的絕大部分請求應該帶上HOT_ONLY的標記(或者設置的TimeRange只在熱區)。如果用戶有大量請求需要去查冷區數據,則可能得考慮COLD_BOUNDARY冷熱分界線的設置是否合理。
如果一行數據已經在冷數據區域,但這一行后續有更新,更新的字段先會在熱區,如果設置HOT_ONLY去查詢這一行(或者設置的TimeRange只在熱區),則只會返回這一行更新的字段(在熱區)。只有在查詢時去掉HOT_ONLY Hint,去掉TimeRange,或保證TimeRange覆蓋了該行數據插入和更新時間,才能完整返回這一行。因此不建議對已經進入冷區的數據進行更新,如果有頻繁更新冷數據的需求,則可能得考慮COLD_BOUNDARY冷熱分界線的設置是否合理。
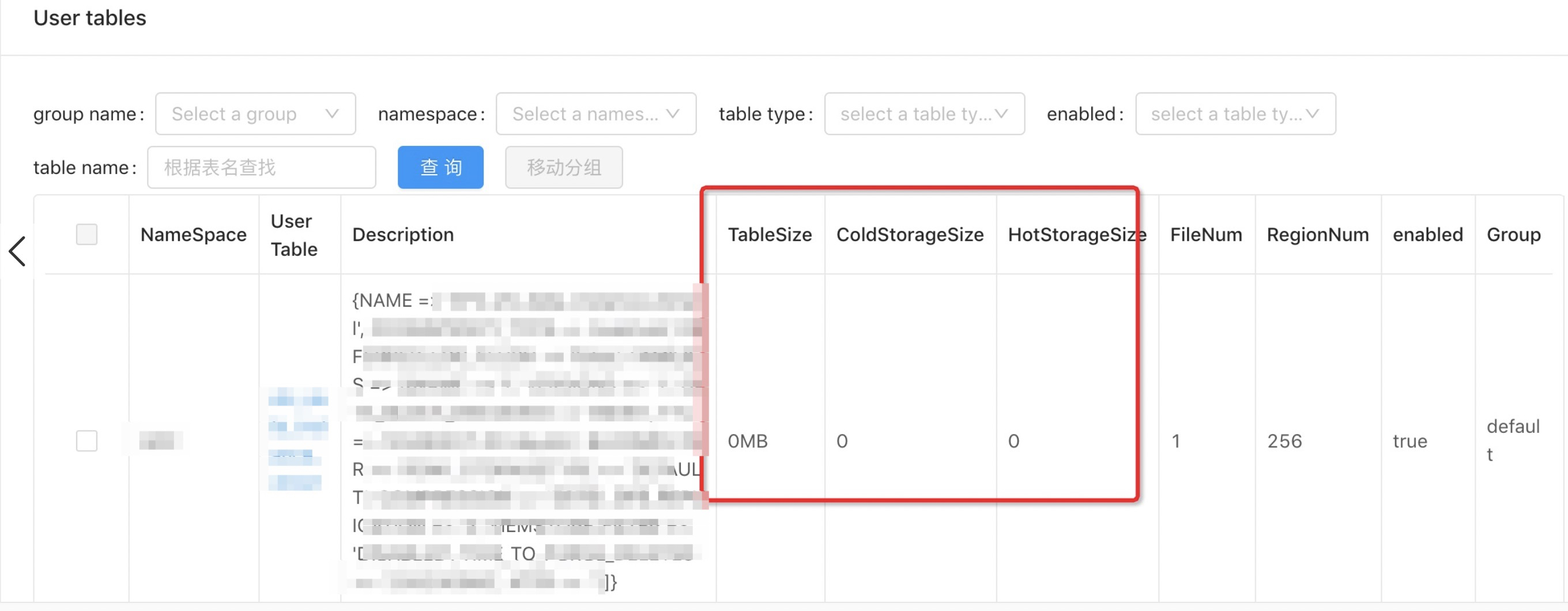
查看表中冷數據和熱數據的大小
在集群管理系統的表Tab中,可以顯示某一張表的冷存儲使用大小和熱存儲使用大小。
如果數據還沒有進入冷存儲,有可能數據還在內存中,請執行flush,將數據刷寫到盤上,再請執行major_compact完成后再查看。
優先查詢熱數據
在范圍查詢(Scan)場景下,查詢的數據可能橫跨冷熱區,比如查詢一個用戶的所有訂單、聊天記錄等。但查詢的結果往往是從新到舊的分頁展示,最先展示的是最近的熱數據。在這個場景下,普通的Scan(不帶Hot_Only)會并行地掃描冷熱數據,導致請求性能下降。而在開啟了優先查詢熱數據后,會優先只查熱數據,只有熱數據的條數不夠顯示(如用戶點了下一頁查看),才會去查詢冷數據,減少冷存儲的訪問,提升請求響應。
開啟熱數據優先查詢,只需在Scan上設置COLD_HOT_MERGE屬性即可。該屬性的含義是優先查詢熱存儲中的數據, 若熱存儲中的數據查完了,用戶仍然在調用next獲取下一條數據,則會開始查詢冷數據。
Shell
hbase(main):002:0> scan 'chsTable', {COLD_HOT_MERGE=>true}Java
scan = new Scan();
scan.setAttribute(AliHBaseConstants.COLD_HOT_MERGE, Bytes.toBytes(true));
scanner = table.getScanner(scan);若某一行同時包含熱數據和冷數據(部分列屬于熱數據,部分列屬于冷數據,比如部分列更新場景),開啟熱數據優先功能,會使得該行的查詢結果會分兩次返回,即scanner返回的Result集合中,對于同一個Rowkey會有兩個對應的Result。
由于是先返回熱數據,再返回冷數據,開啟熱數據優先功能后,無法保證后返回的冷數據結果的Rowkey一定大于先返回的熱數據結果的Rowkey,即Scan得到的Result集不保序, 但熱數據和冷數據的各自返回集仍保證按Rowkey有序排列(參見下面的demo)。在部分實際場景中, 用戶可以通過Rowkey設計,保障scan的結果仍然保序,比如訂單記錄表,Rowkey=用戶ID+訂單創建時間,掃描某個用戶的訂單數據是有序的。
//假設rowkey為"coldRow"的這一行是冷數據,rowkey為"hotRow"的這一行為熱數據
//正常情況下,由于hbase的row是字典序排列,rowkey為"coldRow"的這一行會比"hotRow"這一行先返回。
hbase(main):001:0> scan 'chsTable'
ROW COLUMN+CELL
coldRow column=f:value, timestamp=1560578400000, value=cold_value
hotRow column=f:value, timestamp=1565848800000, value=hot_value
2 row(s)
// 設置COLD_HOT_MERGE時, scan的rowkey順序被破壞,熱數據比冷數據先返回,因此返回的結果中,"hot"排在了"cold"的前面
hbase(main):002:0> scan 'chsTable', {COLD_HOT_MERGE=>true}
ROW COLUMN+CELL
hotRow column=f:value, timestamp=1565848800000, value=hot_value
coldRow column=f:value, timestamp=1560578400000, value=cold_value
2 row(s)