Flink作業支持智能調優和定時調優兩種自動調優模式。本文為您介紹如何配置智能調優和定時調優,以及配置過程中的注意事項。
背景信息
通常,您需要花費大量的時間進行作業調優。例如,新上線一個作業時,需要考慮如何配置該作業的資源、并發個數、Task Manager個數及大小等。此外,作業運行過程中,還需要考慮如何調整作業資源,使作業處于最高資源利用率;作業出現反壓或延時增大的情況時,需要考慮如何調整作業配置等。實時計算Flink版提供了自動調優功能,您可以根據以下信息,選擇合適的調優模式。
調優模式 | 適用場景 | 使用優勢 | 相關文檔 |
智能調優 | 某作業使用資源30 CU,上線平穩運行一段時間后,發現在Source無延遲、無反壓的情況下,作業的CPU和內存使用率有時會很低。 此時如果您不想人工調節資源,需要系統自動完成資源調節,可以使用智能調優模式。系統將在資源使用率比較低時,自動降低資源配置,在資源使用率提高到一定閾值時,再自動提高資源配置。 |
|
|
定時調優 | 定時調優計劃描述了資源和時間點的對應關系,一個定時調優計劃中可以包含多組資源和時間點的關系。 在使用定時調優計劃時,您需要明確知道各個時間段的資源使用情況,根據業務時間區間特征,設置對應的資源。 例如,某業務全天早09:00~19:00是業務高峰,19:00到第二天09:00是業務低峰。此時您可以使用定時調優功能,在高峰時間段使用30 CU,在業務低峰時使用10 CU。 | 配置定時調優策略,請參見開啟并配置定時調優。 |
使用限制
最多創建20個資源計劃。
定時調優和智能調優模式互斥,如果您應用了任何一種調優模式,則無法應用另外一種。如果您需要應用另外一種調優模式,則需要先停止正在應用的調優模式。
定時調優中的定時計劃互斥,如果您應用了某個定時計劃,則無法應用其他定時調優計劃。如果您需要應用其他定時調優計劃,則需要先停止正在應用的定時調優計劃。
在開啟unaligned checkpoint時,不支持調整并發。
智能調優不支持Session集群部署的作業。
智能調優無法解決流作業所有的性能瓶頸。
流作業性能問題是由上下游共同決定的,如果是Flink出現了瓶頸,可以通過Flink資源調優解決。但調優策略對作業的處理模式是基于一定的假設的。例如,流量平滑變化、不能有數據傾斜、每個算子的吞吐能力能夠隨并發度的升高而線性拓展。當業務邏輯嚴重偏離以上假設時,作業可能會存在異常。例如:
無法觸發修改并發度的操作、作業不能達到正常狀態和作業持續重啟等。
自定義標量函數UDF、自定義聚合函數UDAF或自定義表值函數UDTF性能問題。
智能調優無法識別外部系統的問題。如果出現外部系統問題,您需要自行解決。
外部系統故障或訪問變慢時,會導致作業并發度增大,加重外部系統的壓力,導致外部系統雪崩。常見的外部系統問題如下:
數據總線DataHub分區不足或消息隊列RocketMQ吞吐量不足。
Sink性能問題。
云數據庫RDS死鎖。
智能調優和定時調優都支持基礎模式和專家模式。
注意事項
任何模式的調優使作業重啟時,會導致作業短暫停止數據。
說明VVR 8.0.1及以上版本,Flink系統會先嘗試使用動態參數更新重啟作業,再嘗試使用作業整體重啟。動態參數更新下業務中斷時間較之作業整體重啟縮小30%-98%,具體依賴于作業狀態和邏輯,目前僅支持并發的修改。詳情請參見動態擴縮容與參數動態更新。
如果您使用了DataStream作業或SQL自定義的連接器,請確認作業代碼中未配置作業并發度,否則智能調優和定時調優將無法調整作業資源,即自動調優配置無法生效。
開啟并配置智能調優
進入智能調優開啟和配置頁面。
登錄實時計算控制臺。
單擊目標工作空間操作列下的控制臺。
在頁面,單擊目標作業名稱。
在自動調優頁簽,單擊智能調優模式。
打開自動調優開關。
開啟后,在自動調優頁簽頁面頂部會顯示智能調優應用中。如果您需要關閉已開啟的智能調優,則可以單擊關閉智能調優或者關閉自動調優右側的開關。
單擊調優配置右側的編輯后,修改智能調優相關參數。
參數
說明
調優策略
平穩策略:通過應用該策略,系統會尋找適合整個運行周期的固定資源或定時計劃,并根據整個周期作業的運行情況來調整作業資源,從而減少啟停行為對作業的影響。這樣做可以使作業的運行趨于穩定,減少不必要的變動和波動,最終達到收斂狀態。
說明只有找到更適合整個周期的資源配置,才會動態調整,否則不會修改已有資源。
自適應策略:應用該策略后,系統會根據實時作業資源和指標信息動態修改資源配置,更加關注當前作業的延時和資源使用情況,并根據相關指標的變化更快速地優化資源適配。這樣做可以使系統更加敏銳地響應作業需求,提高資源配置的效率和適應性。
調整間隔時間(分鐘)
作業調優重啟生效一次之后,下一次再進行調優的時間間隔。
最大CPU限制
作業自動調整資源可以擴容的最大CPU上限,不同的調優策略的默認值不同。
最大內存限制
作業自動調整資源可以擴容的最大內存上限,不同的調優策略的默認值不同。
更多參數配置
平穩策略和自適應策略,都可以配置如下參數:
mem.scale-down.interval:調低內存時最小觸發時間間隔。
默認值為24小時。24小時內,檢測內存使用率如果小于閾值,則會降低內存,或建議降低內存。
parallelism.scale.max:并發度向上調整時,最大并發限制。
默認值為-1,表示最大并發沒有限制。
說明對于消息隊列類產品(例如Kafka,MQ,SLS等),自動調優并發的調整會受到分區數的影響,無法超過該上限。即如果您設置的并發度最大值超過其分區數,系統將自動調整并發度為分區數。
parallelism.scale.min:并發度向下調整時,最小并發限制。
默認值為1,表示最小并發為1。
delay-detector.scale-up.threshold:可以容忍的最大延遲閾值。基于消費數據源頭的延遲,來衡量作業處理吞吐的能力。
默認值為1分鐘。當數據處理能力不足延遲超過1分鐘,則會通過Scale Up方式來提高作業的吞吐能力,Scale Up方式包括增加并發或者拆Chain,或建議Scale Up。
slot-usage-detector.scale-up.threshold:監控數據處理節點(不包括Source節點)空閑時間,當VERTEX處理數據時間占比持續大于該值時,觸發調大并發度的操作,以提升資源的使用。默認值為0.8。
slot-usage-detector.scale-down.threshold:監控數據處理節點(不包括Source節點)空閑時間,當VERTEX處理數據時間占比持續小于該值時,觸發調小并發度的操作,以降低資源的使用。默認值為0.2。
slot-usage-detector.scale-up.sample-interval:監控slot空閑指標的時間間隔,以便計算該時間間隔的平均值。
默認值為3分鐘,與slot-usage-detector.scale-up.threshold和slot-usage-detector.scale-down.threshold結合使用。當3分鐘內的空閑時間平均值大于0.8或者小于0.2時,則進行scale-up或者scale-down。
resources.memory-scale-up.max:調整單個Task Manager和Job Manager的內存時,能調整到的最大值。
默認值為16 GiB。TM和JM進行智能調優或調大并發時,內存的上限為16 GiB。
單擊保存。
開啟并配置定時調優
操作步驟
進入開啟并配置定時調優頁面。
登錄實時計算控制臺。
單擊目標工作空間操作列下的控制臺。
在頁面,單擊目標作業名稱。
在自動調優頁簽,單擊定時調優模式。
單擊新建定時計劃。
在資源配置區域,填寫資源配置信息。
(可選)單擊新增資源配置時段后,配置生效時間和資源配置。
您可以在同一個定時計劃中,配置多個時間段的資源調優計劃。
重要同一定時計劃中,新增資源配置時段的觸發時間必須和已有資源配置的觸發時間之間的間隔大于半小時,否則無法保存新的資源配置。
單擊目標資源定時計劃名稱右側操作列下的應用。
配置示例
全天09:00~19:00是業務高峰,在高峰時間段使用30 CU。19:00到第二天09:00是業務低峰,在業務低峰時使用10 CU。該場景的調優策略配置結果如下圖所示。
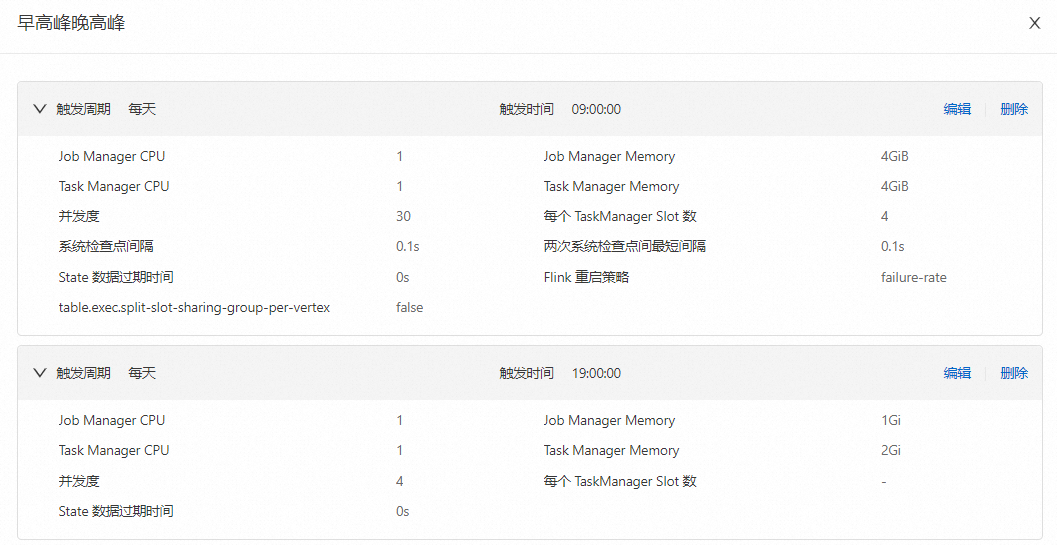
智能調優默認調優行為
如果您開啟了智能調優,則系統默認會從并發度和內存兩個方面為您進行自動調優:
智能調優會調整作業的并發度來滿足作業流量變化所需要的吞吐。
智能調優會監控消費源頭數據的延遲變化情況、TaskManager(TM) CPU實際使用率和各個算子處理數據能力來調整作業的并發度。詳情如下:
作業延遲Delay指標正常(不超過60s),不修改當前作業并發。
作業延遲Delay指標超過默認閾值60s,分以下兩種情況來調整并發度:
延遲正在下降,不進行并發度調整。
延遲增加并且連續上升3分鐘(默認值), 默認調整作業并發度到當前實際TPS的兩倍,但不超過設置最大的資源(默認值為64 CU)。
作業不存在延遲指標。
作業某VERTEX節點連續6分鐘實際處理數據時間占比超過80%,調大作業并發度使得SLOT使用率降低到50%,但不超過設置最大的資源(默認為64 CU)。
所有TM的平均利用率連續6分鐘超過80%,調高并發度使TM的CPU使用率降低到50%。
所有TM的最大CPU使用率連續24小時低于20%,且VERTEX的實際處理數據時間低于20%時,調低作業的并發度使CPU和VERTEX實際處理的時間占比提高到50%。
智能調優也會監控作業的內存使用和Failover情況,來調整作業的內存配置。詳情如下:
在JobManager GC頻繁或者發生OOM異常時,會調高JM的內存,默認最大調整到16 GiB。
在TM GC頻繁或者發生OOM異常、HeartBeatTimeout異常時,會調高TM的內存,默認最大調整到16 GiB。
在TM內存使用率超過95%時,會調大TM的內存。
在TM的實際內存使用率連續24小時低于30%時,降低TM內存的配置,默認最小調整到1.6 GiB。
相關文檔
作業智能診斷服務能夠幫您監控作業健康狀況,全面保障您的業務穩定可靠運行,詳情請參見作業智能診斷。
通過作業配置和Flink SQL優化兩方面提升Flink SQL作業性能,詳情請參見高性能Flink SQL優化技巧。