SQL作業(yè)大狀態(tài)導(dǎo)致反壓的調(diào)優(yōu)原理與方法
狀態(tài)管理不僅影響應(yīng)用的性能,還關(guān)系到系統(tǒng)的穩(wěn)定性和資源的有效利用。如果狀態(tài)管理不當(dāng),可能會導(dǎo)致性能下降、資源耗盡,甚至系統(tǒng)崩潰。本文為您介紹SQL作業(yè)大狀態(tài)導(dǎo)致反壓的調(diào)優(yōu)原理與方法。
運(yùn)行原理:狀態(tài)算子的產(chǎn)生
作為一種特定領(lǐng)域語言,SQL的設(shè)計初衷是隱藏底層數(shù)據(jù)處理的復(fù)雜性,可以通過聲明式語言來進(jìn)行數(shù)據(jù)操作。而Flink SQL由于其架構(gòu)的特殊性,在實(shí)現(xiàn)層面通常需要引入狀態(tài)后端配合系統(tǒng)檢查點(diǎn)(Checkpoint)來保證計算結(jié)果的最終一致性。目前Flink SQL由優(yōu)化器根據(jù)配置項以及SQL語句來推導(dǎo)生成狀態(tài)算子,想要高效處理有狀態(tài)的大規(guī)模數(shù)據(jù)和性能調(diào)優(yōu),需要對SQL狀態(tài)算子生成機(jī)制和管理策略有一定了解。
基于優(yōu)化器推導(dǎo)產(chǎn)生的狀態(tài)算子
主要有如下三種狀態(tài)算子:
狀態(tài)算子 | 狀態(tài)清理機(jī)制 |
ChangelogNormalize | |
SinkUpsertMaterlizer | |
LookupJoin(*) |
ChangelogNormalize
ChangelogNormalize旨在對涉及主鍵語義的數(shù)據(jù)變更日志進(jìn)行標(biāo)準(zhǔn)化處理。通過該算子,可以有效地整合和優(yōu)化數(shù)據(jù)變更記錄,確保數(shù)據(jù)的一致性和準(zhǔn)確性。該狀態(tài)算子會在以下兩種場景出現(xiàn):
使用了帶有主鍵的upsert源表
upsert源表特指在保持主鍵順序一致性的前提下,僅產(chǎn)生基于主鍵的UPDATE(包括INSERT和 UPDATE_AFTER)及DELETE操作的變更數(shù)據(jù)表。例如,Upsert Kafka便是支持這類操作的典型連接器之一。此外,您也可以通過重寫自定義源表連接器中的getChangelogMode方法,實(shí)現(xiàn)upsert功能。
@Override public ChangelogMode getChangelogMode() { return ChangelogMode.upsert(); }顯式設(shè)置
'table.exec.source.cdc-events-duplicate' = 'true'在使用at-least-once語義進(jìn)行CDC事件處理時,可能會產(chǎn)生重復(fù)的變更日志。在需要exactly-once語義時,您需要開啟此配置項來對變更日志進(jìn)行去重。例如

當(dāng)出現(xiàn)該算子時,上游數(shù)據(jù)將按照Flink SQL源表DDL中定義的主鍵做一次hash shuffle操作后使用ValueState來存儲當(dāng)前主鍵下最新的整行記錄。更新狀態(tài)并向下游發(fā)送變更的過程如下圖所示。處理第二條
-U(2, 'Jerry', 77)時State已經(jīng)empty,說明截止目前+I/+UA和-D/-UB已經(jīng)兩兩抵銷,當(dāng)前這條retract消息是重復(fù)的,可以丟棄。
SinkUpsertMaterializer
專門用于處理具有主鍵定義的結(jié)果表,并確保數(shù)據(jù)的物化操作符合upsert語義。在數(shù)據(jù)流更新過程中,如果無法保證upsert的特定要求,即按照主鍵進(jìn)行更新時保持?jǐn)?shù)據(jù)的唯一性和有序性,優(yōu)化器會自動引入此算子。它通過維護(hù)基于結(jié)果表主鍵的狀態(tài)信息,來確保這些約束得到滿足。更多信息及常見場景請參見Flink SQL中Changelog事件亂序處理原理。
LookupJoin
在處理LookupJoin操作時,若主動配置了系統(tǒng)優(yōu)化選項'table.optimizer.non-deterministic-update.strategy'='TRY_RESOLVE',且優(yōu)化器識別到潛在的非確定性更新問題(如何消除流查詢的不確定性影響),則系統(tǒng)會嘗試采取特殊措施以解決這一問題。具體而言,若通過引入一個狀態(tài)算子能夠消除非確定性,優(yōu)化器便會自動創(chuàng)建一個帶狀態(tài)的LookupJoin算子。
帶狀態(tài)的LookupJoin算子主要適用于以下情況:結(jié)果表被定義了主鍵,而這些主鍵完全或部分來自于維表,同時維表中的數(shù)據(jù)可能會發(fā)生變化(例如通過變更數(shù)據(jù)捕獲,即CDC Lookup Source機(jī)制)。此外,用于Join操作的字段在維表中并非主鍵。在這種情況下,帶狀態(tài)的LookupJoin算子能夠有效地處理數(shù)據(jù)的動態(tài)變化,確保查詢結(jié)果的準(zhǔn)確性和一致性。
基于SQL操作產(chǎn)生的狀態(tài)算子
基于SQL操作產(chǎn)生的狀態(tài)算子,按狀態(tài)清理機(jī)制可以分為TTL過期和依賴watermark推進(jìn)兩類。具體說來,F(xiàn)link SQL里有部分狀態(tài)算子的生命周期不是由TTL來控制,例如Window相關(guān)的狀態(tài)計算(WindowAggregate、WindowDeduplicate、WindowJoin、WindowTopN等)。它們的狀態(tài)清理主要依賴于watermark的推進(jìn),當(dāng)watermark超過窗口結(jié)束時間時,內(nèi)置的定時器就會觸發(fā)狀態(tài)清理。
狀態(tài)算子 | 如何產(chǎn)生 | 狀態(tài)清理機(jī)制 |
Deduplicate | 使用row_number語句,order by的字段必須為時間屬性(time attribute)字段(事件時間event time或處理時間processing time),且只取第一條。 | TTL |
RegularJoin | 使用join語句,等值條件里不包含時間屬性字段。 | |
GroupAggregate | 使用group by語句進(jìn)行分組聚合,如sum、count、min、max、first_value、last_value,或使用distinct關(guān)鍵字。 | |
GlobalGroupAggregate | 分組聚合開啟local-global優(yōu)化。 | |
IncrementalGroupAggregate | 當(dāng)存在兩層分組聚合操作并開啟兩階段優(yōu)化時,內(nèi)層聚合對應(yīng)的狀態(tài)算子GlobalGroupAggregate和外層聚合對應(yīng)的狀態(tài)算子LocalGroupAggregate被合并成一個IncrementalGroupAggregate。 | |
Rank | 使用row_number語句,order by的字段必須為非時間屬性字段。 | |
GlobalRank | 使用row_number語句,order by的字段必須為非時間屬性字段,并開啟local-global優(yōu)化。 | |
IntervalJoin | 使用join語句,范圍條件里包含時間屬性字段(事件時間或處理時間)。例如: | watermark |
TemporalJoin | 使用基于事件時間的inner或left join語句。 | |
WindowDeduplicate | 基于Window TVF的去重操作。 | |
WindowAggregate | 基于Window TVF聚合。 | |
GlobalWindowAggregate | 基于Window TVF聚合,并開啟兩階段優(yōu)化。 | |
WindowJoin | 基于Window TVF的Join。 | |
WindowRank | 基于Window TVF的排序。 | |
GroupWindowAggregate | 基于legacy語法的Window聚合。 |
問題診斷方法
在Flink作業(yè)遭遇性能瓶頸時,系統(tǒng)往往表現(xiàn)出明顯的反壓現(xiàn)象。這種反壓可能由多種因素引起,但主要的原因之一是作業(yè)狀態(tài)規(guī)模的持續(xù)膨脹,直至超出內(nèi)存限制。此時,狀態(tài)存儲引擎會將部分不頻繁使用的狀態(tài)數(shù)據(jù)移至磁盤,而磁盤與內(nèi)存在數(shù)據(jù)存取速度上的巨大差異,使得磁盤IO操作成為數(shù)據(jù)處理效率的瓶頸。尤其在Flink的計算過程中,如果算子頻繁地從磁盤讀取狀態(tài)數(shù)據(jù),將顯著增加作業(yè)的延遲,降低整體處理速度,成為性能問題的根源。
為了準(zhǔn)確識別是否由狀態(tài)訪問引發(fā)反壓,需要對作業(yè)的運(yùn)行狀態(tài)和算子行為進(jìn)行深入分析。利用監(jiān)控工具追蹤和診斷性能瓶頸,可以有效地發(fā)現(xiàn)并解決由狀態(tài)訪問引起的性能問題,從而提升Flink作業(yè)的性能,具體方法請參見問題診斷方法。
調(diào)優(yōu)方法
主動避免生成不必要的狀態(tài)算子
基于SQL操作產(chǎn)生的狀態(tài)算子一般很難避免,因此主要針對優(yōu)化器自動推導(dǎo)的算子進(jìn)行討論。
ChangelogNormalize
在使用upsert source進(jìn)行數(shù)據(jù)處理時,需注意其ChangelogNormalize狀態(tài)節(jié)點(diǎn)的生成。通常情況下,除了事件時間的時態(tài)關(guān)聯(lián)(event time temporal join)外,其他upsert source應(yīng)用場景都會產(chǎn)生該狀態(tài)節(jié)點(diǎn)。因此,在選擇Upsert Kafka或類似的Upsert連接器時,應(yīng)首先評估具體的使用場景,對于非事件時間關(guān)聯(lián)場景,應(yīng)特別關(guān)注狀態(tài)算子的狀態(tài)指標(biāo)(state metrics)。由于狀態(tài)節(jié)點(diǎn)是基于KeyedState的,當(dāng)源表的主鍵數(shù)量龐大時,狀態(tài)節(jié)點(diǎn)的規(guī)模也會相應(yīng)增加。如果物理表的主鍵更新頻繁,狀態(tài)節(jié)點(diǎn)也將頻繁地被訪問和修改。從實(shí)踐角度而言,像數(shù)據(jù)同步類的場景,建議避免使用Upsert Kafka作為源表連接器,同時也最好選擇能夠保證exactly-once語義的數(shù)據(jù)同步工具。
SinkUpsertMaterializer
auto作為table.exec.sink.upsert-materialize配置項的默認(rèn)值,表明系統(tǒng)會自動判斷數(shù)據(jù)的一致性,尤其是在變更日志(changelog)出現(xiàn)無序的情況下。該機(jī)制確保了通過引入SinkUpsertMaterializer來維持?jǐn)?shù)據(jù)處理的準(zhǔn)確性。但并不意味著每當(dāng)該算子被激活,數(shù)據(jù)就一定存在無序問題。例如,將多個分組鍵(group by key)合并的操作,這種情況下優(yōu)化器無法準(zhǔn)確推導(dǎo)出upsert鍵,因此出于安全考慮,會默認(rèn)添加SinkUpsertMaterializer。如果對數(shù)據(jù)的分布有充分的了解,不使用該算子也能夠確保輸出結(jié)果的正確性,可以將參數(shù)設(shè)置為none,從而在數(shù)據(jù)正確性和性能上都得到保證。您可以通過檢查作業(yè)的最后一個節(jié)點(diǎn)來確認(rèn)SinkUpsertMaterializer是否被激活使用。在作業(yè)的運(yùn)行拓?fù)鋱D中(如下所示),該算子通常會與sink算子一起顯示,形成一個算子鏈。通過這種方式,可以直觀地監(jiān)控和評估SinkUpsertMaterializer在數(shù)據(jù)處理過程中的實(shí)際應(yīng)用情況,從而做出更加合理的優(yōu)化決策。

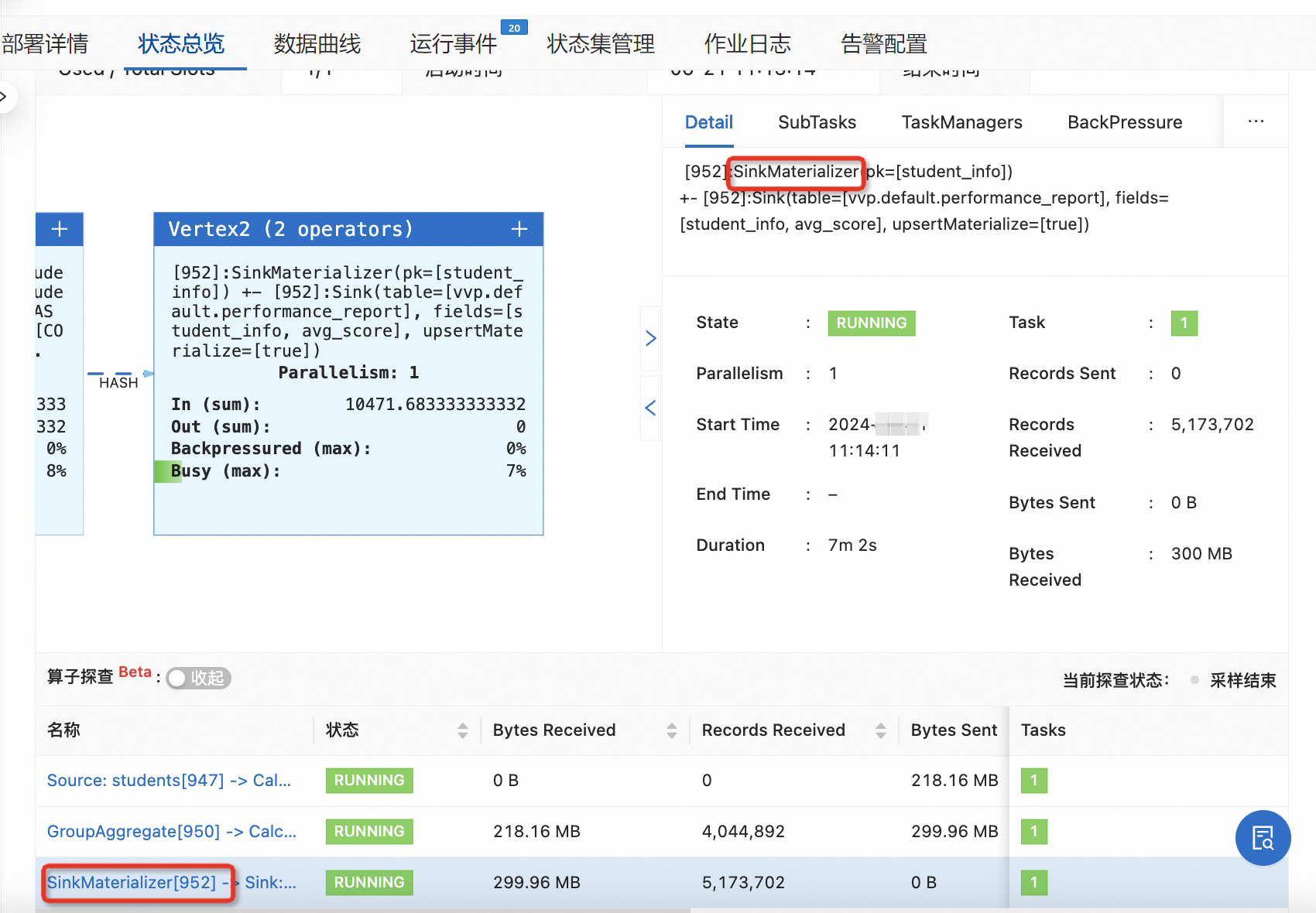
在檢測到生成了特定算子且數(shù)據(jù)計算無誤的情況下,可以調(diào)整配置項為
'table.exec.sink.upsert-materialize'='none'(配置步驟請參見如何配置作業(yè)運(yùn)行參數(shù)?),以避免自動添加SinkUpsertMaterializer。實(shí)時計算引擎VVR 8.0及以上版本中引入了SQL執(zhí)行計劃智能分析功能,協(xié)助您更好地識別此類問題,如下圖所示。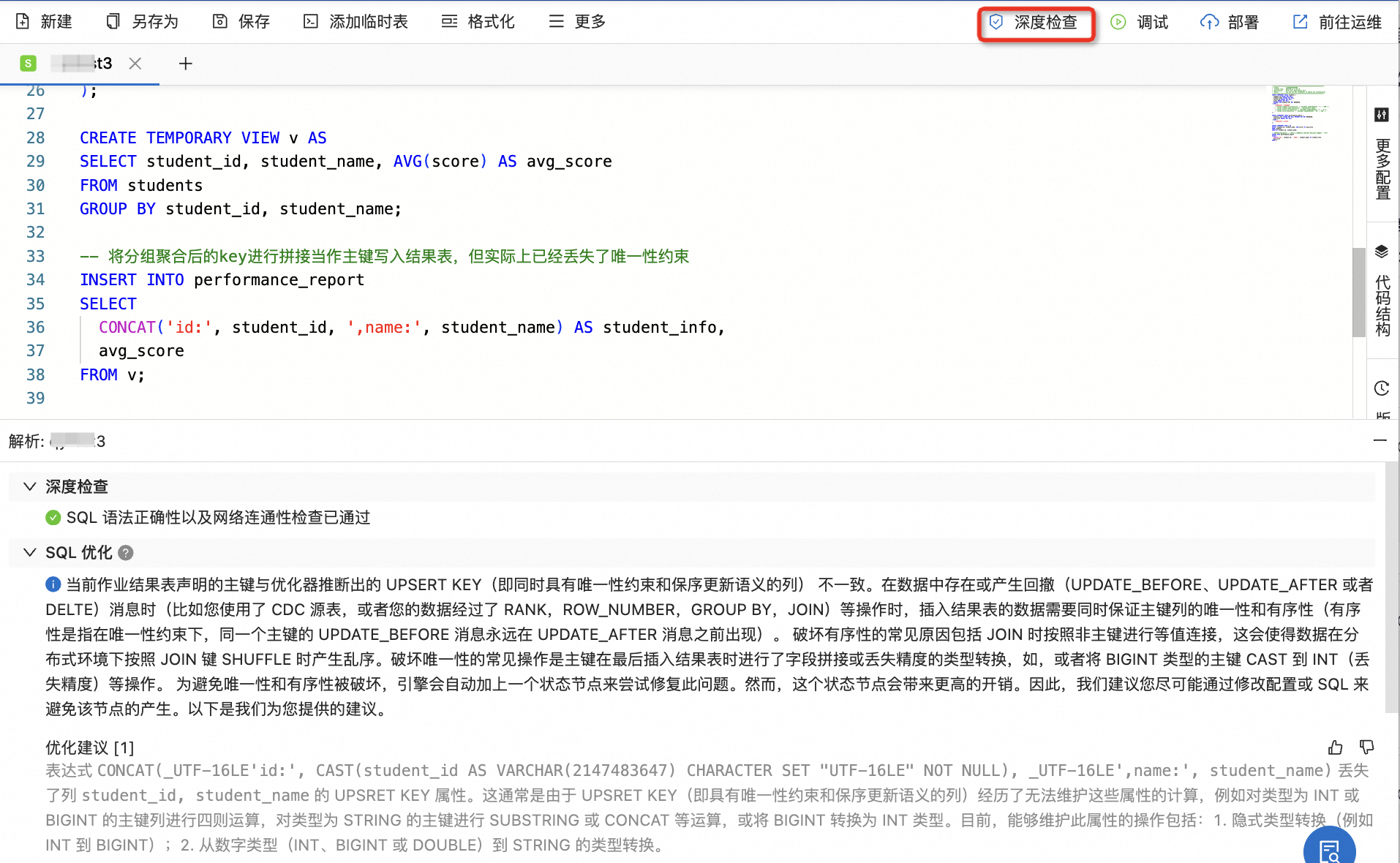
減少狀態(tài)訪問頻次:開啟mini-batch
在對延時要求不高(比如分鐘級別更新)的場景下,開啟mini-batch攢批優(yōu)化將會減少State的訪問和更新頻率(具體操作請參見開啟MiniBatch),提升吞吐。
實(shí)時計算Flink版可以應(yīng)用mini-batch的狀態(tài)算子如下:
狀態(tài)算子 | 說明 |
ChangelogNormalize | 無。 |
Deduplicate | 可配置table.exec.deduplicate.mini-batch.compact-changes-enable,在基于事件時間去重時是否壓縮Changelog。 |
GroupAggregate GlobalGroupAggregate IncrementalGroupAggregate | 無。 |
RegularJoin | 需額外配置table.exec.stream.join.mini-batch-enabled開啟mini-batch join優(yōu)化。適用于更新流和outer join場景。 |
減少狀態(tài)大小:設(shè)置合理生命周期
開啟或關(guān)閉TTL不能保證完全兼容。當(dāng)嘗試在已開啟TTL的作業(yè)上關(guān)閉TTL配置時,或者反過來操作時,將會導(dǎo)致兼容性失敗并引發(fā)StateMigrationException異常。
在優(yōu)化計算系統(tǒng)時,關(guān)鍵在于精簡狀態(tài)數(shù)據(jù)以提高性能。您可以在作業(yè)運(yùn)維頁面配置State數(shù)據(jù)過期時間(參數(shù)詳情請參見運(yùn)行參數(shù)配置)來控制作業(yè)狀態(tài)的生命周期,以滿足不同的運(yùn)維需求和策略。

過短的TTL可能導(dǎo)致數(shù)據(jù)未能及時處理,從而產(chǎn)生不符合預(yù)期的計算結(jié)果,例如,在聚合或連接操作時,部分?jǐn)?shù)據(jù)晚到,而相關(guān)狀態(tài)已過期,導(dǎo)致結(jié)果異常。相反,過長的TTL會消耗資源,降低作業(yè)的穩(wěn)定性。因此,在對Flink SQL作業(yè)進(jìn)行TTL配置時,建議根據(jù)數(shù)據(jù)特性和業(yè)務(wù)需求進(jìn)行恰當(dāng)?shù)腡TL設(shè)置。例如,如果計算周期以自然天為單位,并且數(shù)據(jù)跨天漂移不會超過1小時,那么將TTL設(shè)定為25小時即可滿足需求。數(shù)據(jù)開發(fā)人員應(yīng)深入了解業(yè)務(wù)場景和計算邏輯,以實(shí)現(xiàn)最佳的平衡。
此外,針對雙流連接場景,F(xiàn)link SQL自實(shí)時計算引擎VVR 8.0.1版本起,支持通過JOIN_STATE_TTL Hint為左流和右流分別設(shè)置不同的生命周期。這一改進(jìn)允許為各自數(shù)據(jù)流定制生命周期,有效減少不必要的狀態(tài)存儲開銷,從而優(yōu)化作業(yè)性能。您可以根據(jù)左右流數(shù)據(jù)的實(shí)際生命周期需求,靈活配置,以達(dá)到節(jié)省資源和提高作業(yè)效率的目的,具體操作請參見查詢提示。
SELECT /*+ JOIN_STATE_TTL('left_table' = '..', 'right_table' = '..') */ *
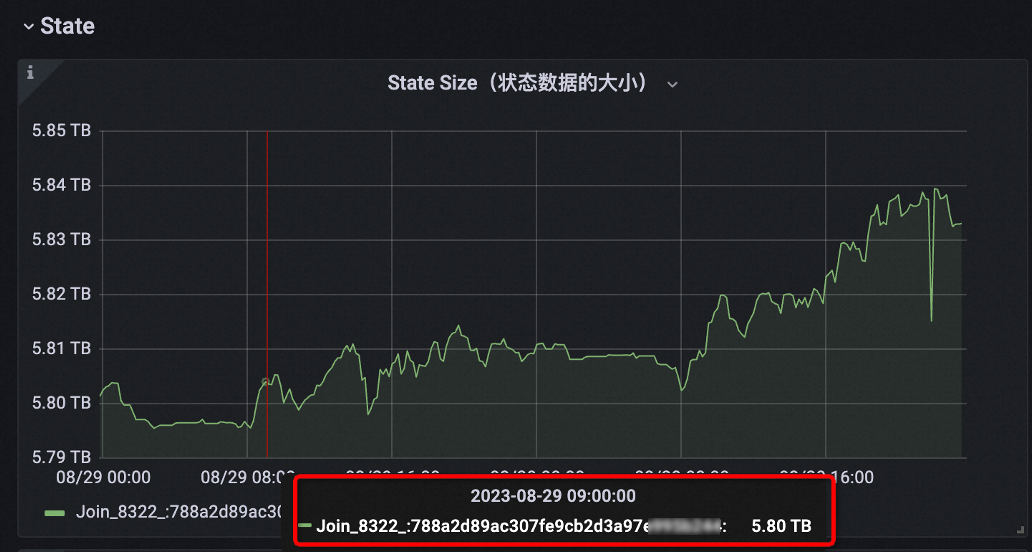
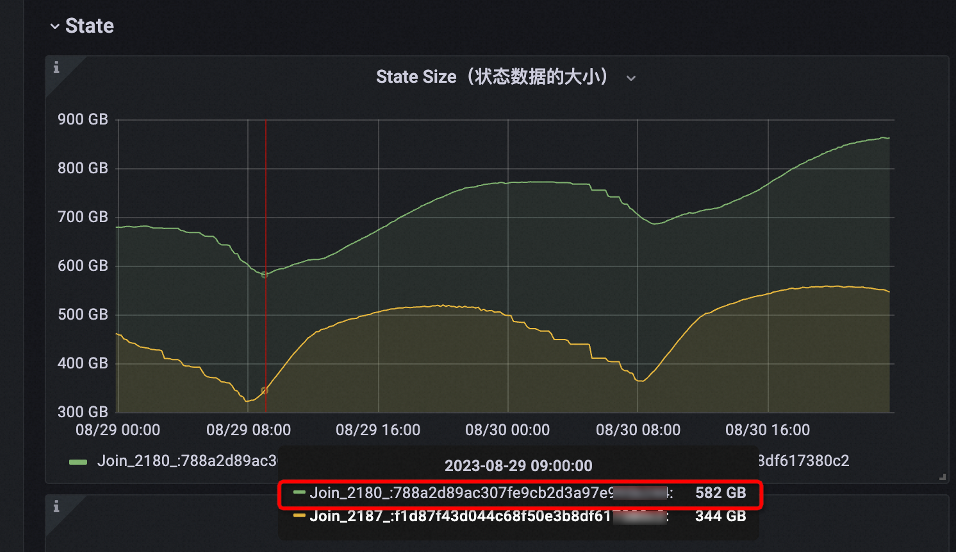
FROM left_table [LEFT | RIGHT | INNER] JOIN right_table ON ...下面是一個作業(yè)使用JOIN_STATE_TTL Hint前后的State大小對比示例。
對比 | 作業(yè)情況 | 狀態(tài)大小 |
優(yōu)化前 |
|
|
優(yōu)化后 |
|
|
減少狀態(tài)大小:命中更優(yōu)的執(zhí)行計劃
在生成執(zhí)行計劃時,優(yōu)化器會結(jié)合輸入SQL和配置選擇相應(yīng)的State實(shí)現(xiàn)。
利用主鍵優(yōu)化雙流連接
當(dāng)連接鍵(Join Key)包含主鍵時,系統(tǒng)采用ValueState<RowData>進(jìn)行數(shù)據(jù)存儲,這樣可以為每個連接鍵僅保留一條最新記錄,實(shí)現(xiàn)存儲空間的最大化節(jié)省。
如果連接操作使用了非主鍵字段,即使已定義主鍵,系統(tǒng)會使用MapState<RowData, RowData>進(jìn)行存儲,以便為每個連接鍵保存來自源表的、基于主鍵的最新記錄。
在未定義主鍵的情況下,系統(tǒng)將使用MapState<RowData, Integer>存儲數(shù)據(jù),記錄每個連接鍵對應(yīng)的整行數(shù)據(jù)及其出現(xiàn)次數(shù)。
因此,建議在建表DDL中聲明主鍵,并在雙流連接時優(yōu)先使用主鍵,以優(yōu)化存儲效率。
優(yōu)化append_only流去重操作
使用ROW_NUMBER函數(shù)替代FIRST_VALUE或LAST_VALUE函數(shù)進(jìn)行去重,可以更有效地保留首次(ROW_NUMBER函數(shù)生成的Deduplicate算子僅保留出現(xiàn)過的Key)或最新出現(xiàn)的記錄(保留Key及其最后一次出現(xiàn)的記錄)。
提升聚合查詢性能
在進(jìn)行多維度統(tǒng)計,例如計算全網(wǎng)UV、手機(jī)客戶端UV、PC端UV等,推薦使用AGG WITH FILTER語法替代傳統(tǒng)的CASE WHEN語法。SQL優(yōu)化器能夠識別Filter參數(shù),使得在同一個字段上根據(jù)不同條件計算COUNT DISTINCT時能夠共享狀態(tài)信息,減少狀態(tài)的讀寫次數(shù)。根據(jù)性能測試結(jié)果,采用AGG WITH FILTER語法相比CASE WHEN可以提升高達(dá)一倍的性能。
減少狀態(tài)大小:調(diào)整多流Join順序,緩解State放大
Flink在處理數(shù)據(jù)流時,采用了二進(jìn)制哈希連接(Binary Hash Join)的方式。在下圖示例中,A與B的連接結(jié)果會導(dǎo)致數(shù)據(jù)存儲的冗余,這種冗余程度與連接操作的頻率成正比。隨著加入連接的流數(shù)量增加,State的冗余問題會變得更加嚴(yán)重。
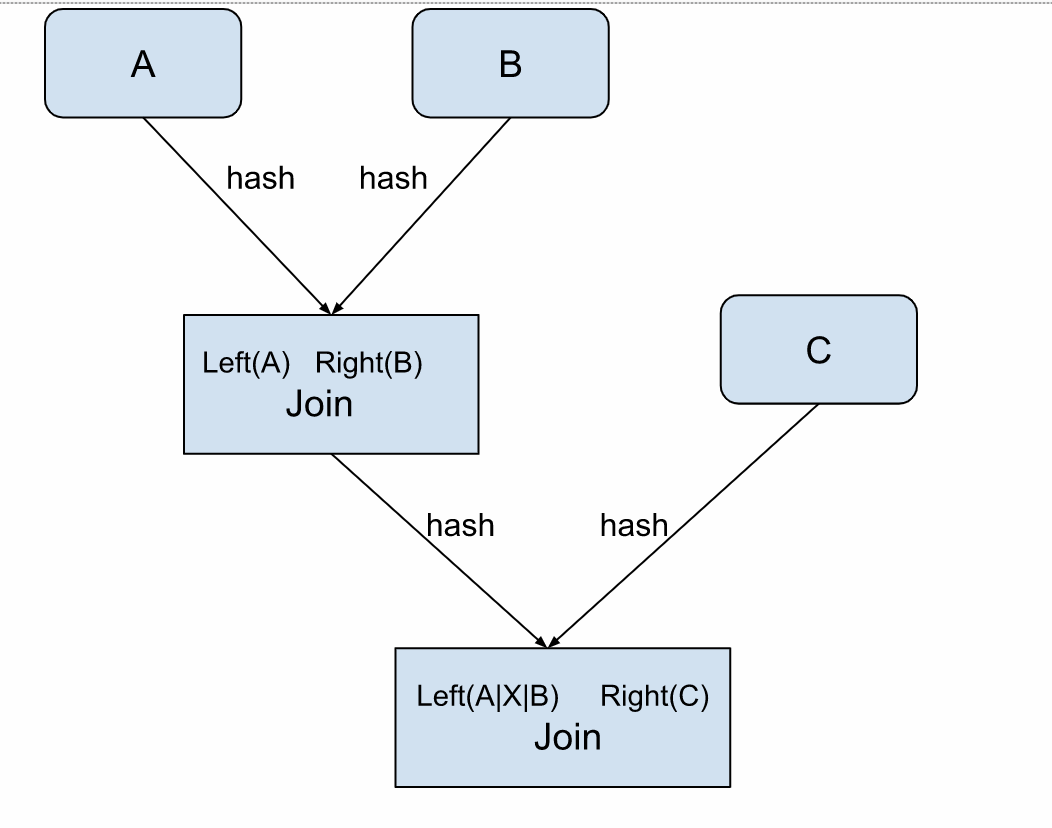
您可以策略性地調(diào)整連接的順序來優(yōu)化該問題。具體來說,可以先將數(shù)據(jù)量較小的流進(jìn)行連接,而將數(shù)據(jù)量大的流放在最后進(jìn)行。這樣的順序調(diào)整有助于減輕狀態(tài)冗余帶來的放大效應(yīng),從而提高數(shù)據(jù)處理的效率和性能。
盡可能減少讀盤
為了提升系統(tǒng)性能,可以通過減少磁盤讀取次數(shù)并優(yōu)化內(nèi)存使用來實(shí)現(xiàn),具體請參見盡可能減少讀盤。
相關(guān)文檔
大狀態(tài)作業(yè)導(dǎo)致的問題和診斷調(diào)優(yōu)整體思路,詳情請參見大狀態(tài)作業(yè)調(diào)優(yōu)實(shí)踐指南。
Flink Datastream API在狀態(tài)管理方面提供了靈活的接口,您可以采取相關(guān)措施來確保狀態(tài)大小可控,避免狀態(tài)的無限制增長,詳情請參見DataStream作業(yè)大狀態(tài)導(dǎo)致反壓的調(diào)優(yōu)原理與方法。
快速啟動和擴(kuò)縮容過程中初始化瓶頸問題的診斷方法和調(diào)優(yōu)策略,詳情請參見作業(yè)啟動和擴(kuò)縮容速度優(yōu)化。