本文為您介紹實時計算Flink版分場景排錯指引方面的常見問題,包括權限、運維和數據異常等問題。
權限
運維
數據異常
不小心刪除了角色或者變更了授權策略,導致實時計算Flink版服務不可用怎么辦?
您可以按照以下步驟重新進行自動化授權。
確認您已刪除了名稱為AliyunStreamAsiDefaultRole的RAM角色。詳情請參見刪除RAM角色。
重要您需要將對應角色的所有權限策略解除授權后,此角色才能刪除成功。
刪除名稱為FlinkServerlessStack和FlinkOnAckStack資源棧,詳情請參見刪除資源棧。
FlinkServerlessStack:實時計算Flink版的ROS資源棧統一名稱。
FlinkOnAckStack:容器服務ACK的ROS資源棧統一名稱。
刪除名稱為AliyunStreamAsiDefaultRolePolicy的RAM權限策略。詳情請參見刪除自定義權限策略。
在實時計算控制臺,重新自動化授權,詳情請參見開通流程。
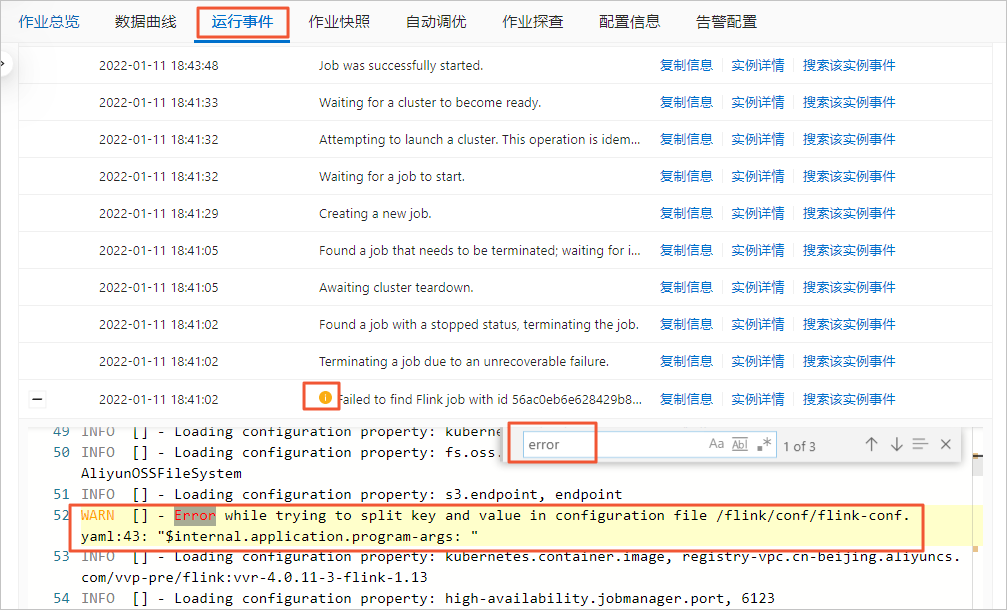
JobManager沒有運行起來,如何快速定位問題?
JobManager沒有運行起來即無法進入Flink UI頁面。此時,您可以通過以下操作進行問題定位:
在頁面,單擊目標作業名稱。
單擊運行事件頁簽。
通過快捷鍵搜索error,獲取異常信息。
Windows系統:Ctrl+F
Mac系統:Command+F
Python作業,如果Checkpoint慢怎么辦?
問題原因
Python算子內部有一定的緩存,在進行Checkpoint時,需要將緩存中的數據全部處理完。因此,如果Python UDF的性能較差,則會導致Checkpoint時間變長,從而影響作業執行。
解決方案
將緩存調小,您需要在其他配置中設置以下參數,具體操作請參見如何配置作業運行參數?。
python.fn-execution.bundle.size:默認值為100000,單位是條數。 python.fn-execution.bundle.time:默認值為1000,單位是毫秒。參數的詳細信息請參見Flink Python配置。
報錯:Invalid versionName string
報錯詳情
作業啟動時報錯Invalid versionName string。SQL作業不受影響,1.11.3及以下版本的Flink引擎JAR或PYTHON作業會受影響。
報錯原因
創建Session模式的JAR或PYTHON作業時,沒有設置Flink引擎版本。
解決方案
在作業開發頁面,設置Flink引擎版本后,重新上線啟動作業。
對于SDK方式創建的Session作業,建議您升級依賴的SDK common包到1.0.21版本,并在創建Artifact時,設置Flink引擎版本。詳細信息如下所示:
common包
<dependency> <groupId>com.aliyun</groupId> <artifactId>ververica-common</artifactId> <version>1.0.21</version> </dependency>Artifact設置
com.ververica.common.model.deployment.Artifact.SqlScriptArtifact#setVersionName com.ververica.common.model.deployment.Artifact.JarArtifact#setVersionName重要versionName取值須和Session集群上的Flink引擎版本保持一致。
如何定位Flink無法讀取源數據的問題?
當Flink無法讀取源數據時,建議從以下幾個方面進行排查并處理:
檢查上游存儲和實時計算Flink版之間網絡是否連通。
實時計算Flink版僅支持訪問相同地域、相同VPC下的存儲。如果您有訪問跨VPC存儲資源或者通過公網訪問實時計算Flink版的特殊需求,請查看以下文檔:
如果您需要跨VPC訪問存儲資源,則可以通過5種方式解決,詳情請參見如何訪問跨VPC的其他服務?
如果您需要通過公網訪問實時計算Flink版,則可以使用阿里云提供的NAT網關實現VPC網絡和公網的連通。詳情請參見實時計算Flink版如何訪問公網?
檢查上游存儲中是否已配置了白名單。
上游存儲中需要配的產品有Kafka和ES。您可以按照以下步驟配置白名單:
獲取實時計算Flink版虛擬交換機的網段。
獲取方法請參見設置白名單。
在上游存儲中配置實時計算Flink版白名單。
上游存儲中配置白名單的方法,請參見對應DDL文檔的前提條件中的文檔鏈接,例如Kafka源表前提條件。
檢查DDL中定義的字段類型、字段順序和字段大小寫是否和物理表一致。
上游存儲支持的字段類型和實時計算Flink版支持的字段類型可能不完全一致,但存在一定的映射關系。您需要按照DDL定義的字段類型映射關系一對一匹配,詳情請參見對應DDL文檔類型映射文檔,例如日志服務SLS源表類型映射。
查看源表Taskmanager.log日志中是否有異常信息。
如果有異常報錯,請先按照報錯提示處理問題。查看源表Taskmanager.log日志的操作如下:
在頁面,單擊目標作業名稱。
在狀態總覽頁簽,單擊Source節點。
在SubTasks頁簽操作列,單擊Open TaskManager Log Page。
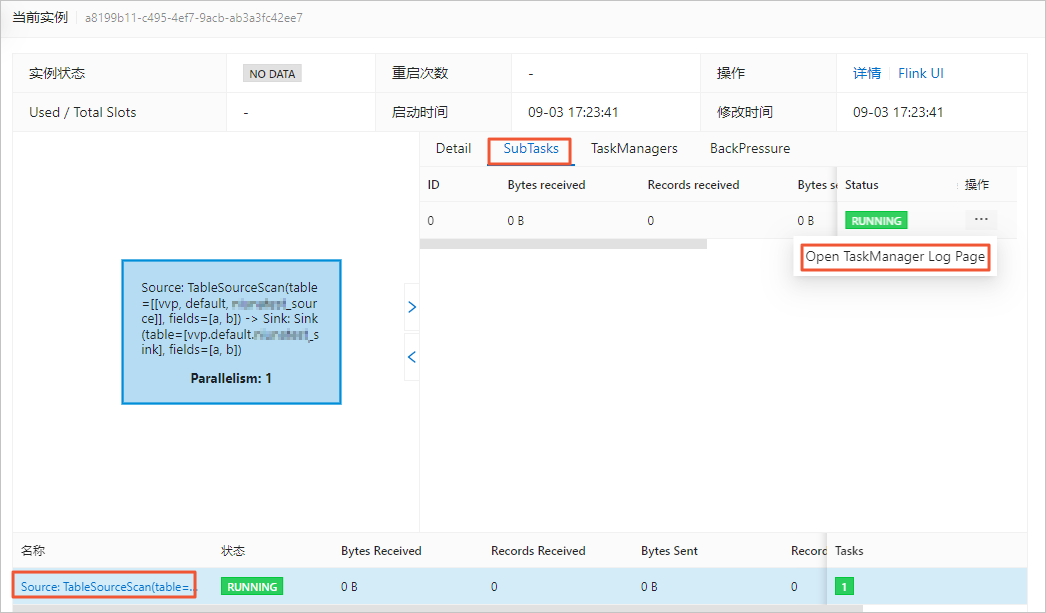
在logs頁簽,查看日志信息。
在當前頁面查找最后一個Caused by信息,即第一個Failover中的Caused by信息,往往是導致作業異常的根因,根據該根因的提示信息,可以快速定位作業異常的原因。
如何定位Flink無法將數據寫入到結果表的問題?
當Flink無法將數據寫入到結果表時,建議從以下幾個方面進行排查并處理:
確認下游存儲和實時計算Flink版之間網絡是否連通。
實時計算Flink版僅支持訪問相同地域、相同VPC下的存儲。如果您有訪問跨VPC存儲資源或者通過公網訪問實時計算Flink版的特殊需求,請查看以下文檔:
如果您需要跨VPC訪問存儲資源,則可以通過5種方式解決,詳情請參見如何訪問跨VPC的其他服務?
如果您需要通過公網訪問實時計算Flink版,則可以使用阿里云提供的NAT網關實現VPC網絡和公網的連通。詳情請參見實時計算Flink版如何訪問公網?
確認下游存儲中是否已配置了白名單。
下游存儲中需要配置白名單的產品包括RDS MySQL、Kafka、ES、云原生數據倉庫AnalyticDB MySQL版3.0、HBase、Redis和ClickHouse。您可以按照以下步驟配置白名單:
獲取實時計算Flink版虛擬交換機的網段。
獲取方法請參見設置白名單。
在下游存儲中配置實時計算Flink版白名單。
下游存儲中配置白名單的方法,請參見對應DDL文檔的前提條件中的文檔鏈接,例如RDS MySQL結果表前提條件。
確認DDL中定義的字段類型、字段順序和字段大小寫是否和物理表一致。
下游存儲支持的字段類型和實時計算Flink版支持的字段類型可能不完全一致,但存在一定的映射關系。您需要按照DDL定義的字段類型映射關系一對一匹配,詳情請參見對應DDL文檔類型映射文檔,例如日志服務SLS結果表類型映射。
確認數據是否被中間節點過濾了,例如WHERE、JOIN和窗口等。
具體請查看Vertex拓撲圖上每個計算節點數據輸入和輸出情況。例如WHERE節點輸入為5,輸出為0,則代表被WHERE節點過濾了,因此下游存儲中無數據寫入。
確認下游存儲中設置的輸出條件相關參數的默認值是否合適。
如果您的數據源的數據量較小,但結果表DDL定制中設置的輸出條件的默認值較大,會導致一直達不到輸出條件,而無法下發數據至下游存儲。此時,您需要將輸出條件相關參數的默認值改小。常見的下游存儲中的輸出條件參數情況如下表所示。
輸出條件
參數
涉及的下游存儲
一次批量寫入的條數。
batchSize
DataHub
Tablestore
MongoDB
Phoenix5
RDS MYSQL
云原生數據倉庫AnalyticDB MySQL版3.0
ClickHouse
InfluxDB
每次批量寫入數據的最大數據條數。
batchCount
DataHub
Odps tunnel writer緩沖區Flush間隔。
flushIntervalMs
MaxCompute
寫入HBase前,內存中緩存的數據量(字節)大小。
sink.buffer-flush.max-size
Hbase
寫入HBase前,內存中緩存的數據條數。
sink.buffer-flush.max-rows
Hbase
將緩存數據周期性寫入到HBase的間隔,可以控制寫入HBase的延遲。
sink.buffer-flush.interval
Hbase
Hologres Sink節點數據攢批的最大值。
jdbcWriteBatchSize
Hologres
確認窗口是否因為亂序而導致數據無法輸出。
假如,實時計算Flink版一開始就流入一條2100年的未來數據,它的Watermark為2100年,系統會默認2100年前的數據已被處理完,只會處理比2100年大的數據。而后續流入的2021年的正常數據因為Watermark小于2100年而被丟棄。直到出現大于2100年的數據流入實時計算Flink版,則會觸發窗口關閉而輸出數據,否則就會導致結果表一直沒有數據輸出。
您可以通過Print Sink或者Log4j的方式確認數據源中是否存在亂序的數據,詳情請參見print結果表和配置作業日志輸出。找到亂序數據后,您可以過濾或者采取延遲觸發窗口計算的方式處理亂序的數據。
確認是否因為個別并發沒有數據而導致數據無法輸出。
如果作業為多并發,但個別并發沒有數據流入實時計算Flink版,則它的Watermark就為1970年0點0分,而多個并發的Watermark取最小值,因此就永遠沒有滿足窗口結束的Watermark,就不能觸發窗口結束而輸出數據。
此時,您需要檢查您上游的Vertex拓撲圖的Subtask每個并發是不是都有數據流入。如果有個別并發無數據,建議調整作業并發數小于等于源表Shard數,從而保證所有并發都有數據。
確認Kafka的某個分區是否無數據而導致數據無法輸出。
如果Kafka某個分區沒有數據,則會影響Watermark的產生,從而導致Kafka源表數據基于Event Time的窗口后,不能輸出數據。解決方案請參見為什么Kafka源表數據基于Event Time的窗口后,不能輸出數據?
如何定位數據丟失的問題?
數據經過JOIN、WHERE或窗口等節點時,數據量減少是正常現象,這是因條件限制被過濾或JOIN不上。但如果您的數據丟失異常,建議從以下幾個方面進行排查并處理:
確認維表Cache緩存策略是否有問題。
如果維表DDL中Cache緩存策略設置的有問題,則會導致維表的數據沒有被拉取到,從而導致數據丟失。此時建議檢查并修改作業Cache策略。作業Cache策略詳情請參見各維表的Cache策略,例如HBase維表Cache參數。
確認函數使用方法是否不正確。
如果您在作業中使用了to_timestamp_tz、date_format等函數,而函數的使用方法不對,導致數據轉化出問題,數據被丟失。
此時,您可以通過Print Sink或者Log4j的方式,單獨將使用的函數的信息打印到日志中,確認函數的使用方法是否正確。詳情請參見print結果表或配置作業日志輸出。
確認數據是否亂序。
如果作業中存在亂序的數據,這些亂序的數據的Watermark不在新窗口的開窗和關窗時間范圍內,導致這些數據被丟棄。例如下圖中11秒的數據在16秒進入15~20秒的窗口,而它的Watermark為11,會被系統認為是遲到數據,從而導致被丟棄。
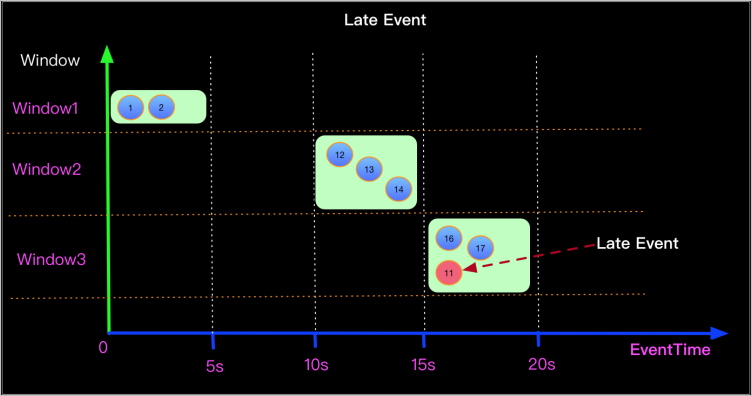
通常丟失的數據都是一個窗口的,您可以通過Print Sink或者Log4j的方式確認數據源中是否存在亂序的數據。詳情請參見print結果表或配置作業日志輸出。
找到亂序數據后,可以根據亂序的程度,合理的設置Watermark,采取延遲觸發窗口計算的方式處理亂序的數據。例如該示例中,可以定義Watermark生成策略為Watermark = Event time -5s,從而讓亂序的數據可以被正確的處理。建議以整天整時整分開窗口求聚合,否則數據亂序嚴重,增加offset后還是會有數據丟失問題。