如果您想構建一個基于文本索引的語義搜索系統,您可以利用事件總線(EventBridge)、向量檢索服務和函數計算 FC(Function Compute),并通過百煉服務上的同步接口API,從零開始構建一個基于文本索引和向量檢索的語義搜索系統。本文將介紹如何構建一個完全動態的RAG入庫方案,通過事件總線(EventBridge)拉取OSS非結構化數據,同時將數據投遞至向量數據庫,從而實現完整的RAG Ingestion流程。
RAG背景概述
大語言模型(LLM)作為自然語言處理領域的核心技術,具有豐富的自然語言處理能力。然而,其訓練語料庫主要由普適知識和常識性知識(如維基百科、新聞、小說)以及各種領域的專業知識組成,這導致LLM在處理特定領域的知識表示和應用時存在一定的局限性。特別是在垂直領域或企業內部等私域專屬知識方面,由于缺乏針對性的數據和專業術語的充分覆蓋,LLM的表現可能會不盡人意。為了解決這些問題,可以通過微調或增加專有數據集來提高模型在特定領域的性能。
實現專屬領域的知識問答的關鍵在于讓大型語言模型(LLM)能夠理解并獲取那些超出了它訓練數據范圍內的特定領域知識。這可以通過精心設計的提示詞(Prompt)來引導LLM,在回答該領域的問題時,根據提供的額外知識來進行作答。通常情況下,用戶的提問采用完整的句子形式,而非像搜索引擎那樣僅輸入幾個關鍵詞。因此,直接使用關鍵詞與企業內部的知識庫進行匹配往往效果不佳,因為處理長句還涉及到分詞、權重分配等一系列復雜步驟。相反,如果將提問文本以及知識庫中的內容都轉換為高質量的向量表示,然后通過向量檢索技術將其轉變為一種基于語義的搜索過程,則可以在提取相關信息方面達到更高效的結果。
步驟概述
數據集成(Ingestion):將對象存儲OSS中的文件通過事件觸發的方式,經過轉換后存入向量數據庫DashVector中。

數據檢索(Search):把檢索到的原始數據轉換為易于計算機處理的向量形式,最后存儲于DashVector數據庫中以便高效檢索和分析。

前提條件
開通向量檢索服務,然后完成以下操作:
已開通函數計算服務。具體操作,請參見開通函數計算服務。
開通事件總線(EventBridge)服務。具體操作,請參見開通事件總線EventBridge并授權。



1. 創建Ingestion數據集成任務
在左側導航欄,單擊事件流,然后選擇目標地域,最后單擊創建事件流。
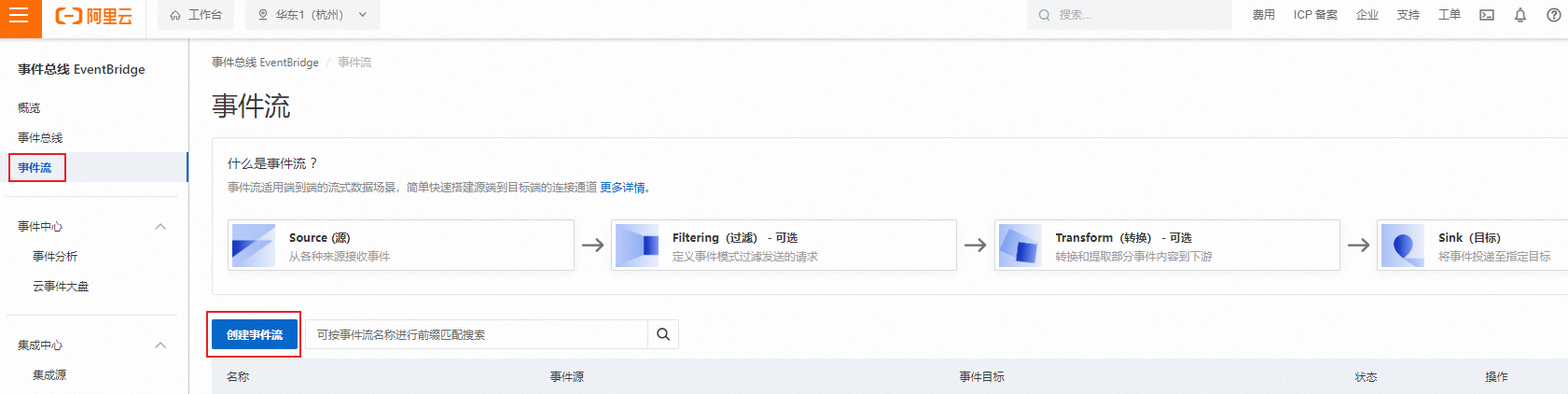
在創建事件流頁面,配置以下信息。
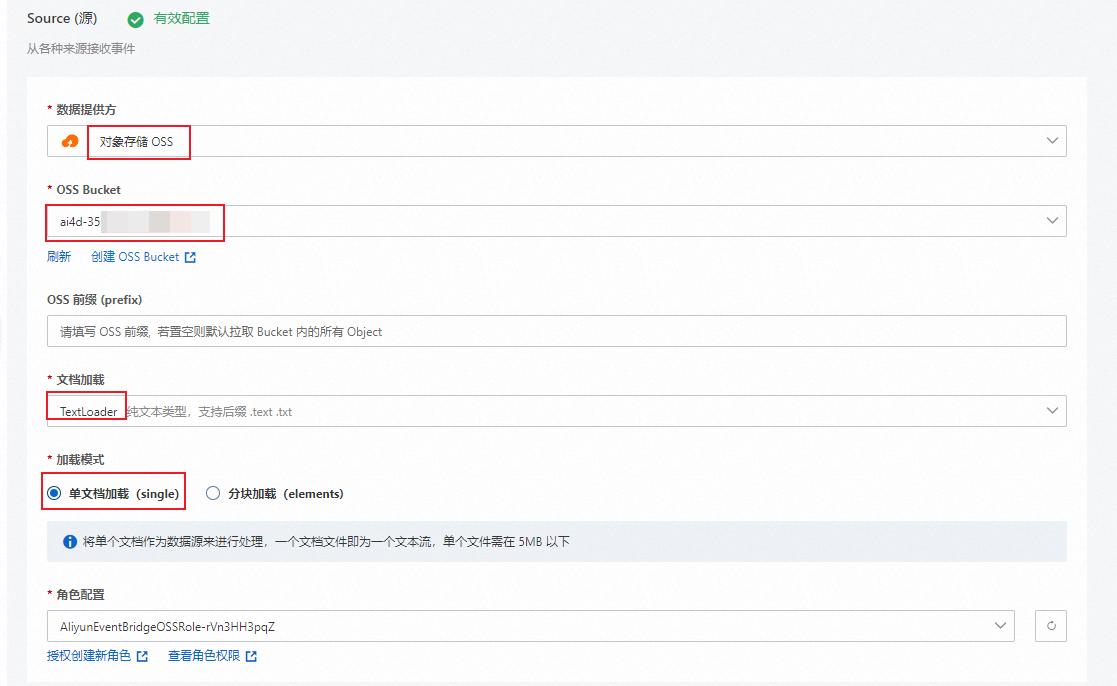
在Source(源)配置導向頁面,按照以下表格說明配置參數信息,然后單擊下一步。
配置項
示例值
說明
數據提供方
對象存儲 OSS
在下拉框中選擇對象存儲 OSS。
OSS Bucket
ai4d-35bzmh7q33gl******選擇已創建的OSS Bucket,如果沒有,可單擊創建OSS Bucket進行創建。
OSS 前綴 (prefix)
無
非必填項,若不填表示EB將拉取整個Bucket內容。
文檔加載
TextLoder
支持解析TextLoader作為文檔加載器。
加載模式
單文檔加載(single)
有兩種模式可供您選擇:
單文檔加載(single):表示單個文件作為一條數據加載。本示例中采用此種模式。
分塊加載(elements):表示按照分隔符加載數據。
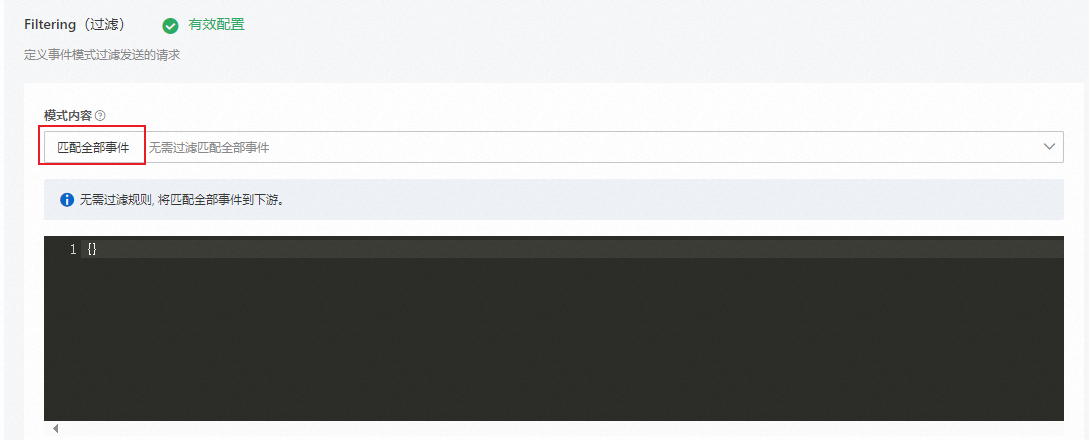
在Filtering(過濾)配置向導頁面,選擇模式內容,然后單擊下一步。
說明本示例中模式內容為匹配全部事件。
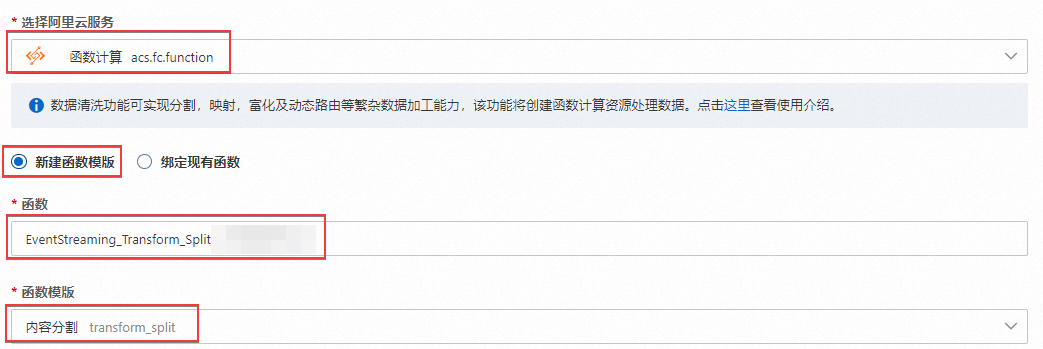
在Transform(轉換)配置向導頁面,選擇選擇阿里云服務為函數計算,然后選擇目標函數和函數版本,最后單擊下一步。
重要轉換部分主要是將原始數據轉換成向量化數據,為投遞至DashVector做數據準備。
配置項
示例值
說明
選擇阿里云服務
函數計算
在下拉框中選擇函數計算,并選擇新建函數模板。
函數
EventStreaming_Transform_Split_****自定義函數名稱,也選擇控制臺默認的函數名稱。
函數模板
內容分割
支持以下四種函數模板,請按需選擇。
內容分割
內容映射
內容富化
動態路由
函數模板的具體介紹,請參見使用函數計算實現消息數據清洗。
測試代碼如下所示:
# -*- coding: utf-8 -*- import os import ast import copy import json import logging import dashscope from dashscope import TextEmbedding from http import HTTPStatus logger = logging.getLogger() logger.setLevel(level=logging.INFO) dashscope.api_key='Your-API-KEY' # 需要您替換成自己創建的DashScope API-KEY。 def handler(event, context): evt = json.loads(event) evtinput = evt['data'] resp = dashscope.TextEmbedding.call( model=dashscope.TextEmbedding.Models.text_embedding_v1, api_key=os.getenv('DASHSCOPE_API_KEY'), # 需要您替換成自己創建的DashScope API-KEY。 input= evtinput ) if resp.status_code == HTTPStatus.OK: print(resp) else: print(resp) return resp重要需手動安裝相關函數環境。具體操作,請參見為函數安裝第三方依賴。
pip3 install dashvector dashscope -t .返回樣例如下所示:
{ "code": "", "message": "", "output": { "embeddings": [ { "embedding": [ -2.192838430404663, -0.703125, ... ... -0.8980143070220947, -0.9130208492279053, -0.520526111125946, -0.47154948115348816 ], "text_index": 0 } ] }, "request_id": "e9f9a555-85f2-9d15-ada8-133af54352b8", "status_code": 200, "usage": { "total_tokens": 3 } }
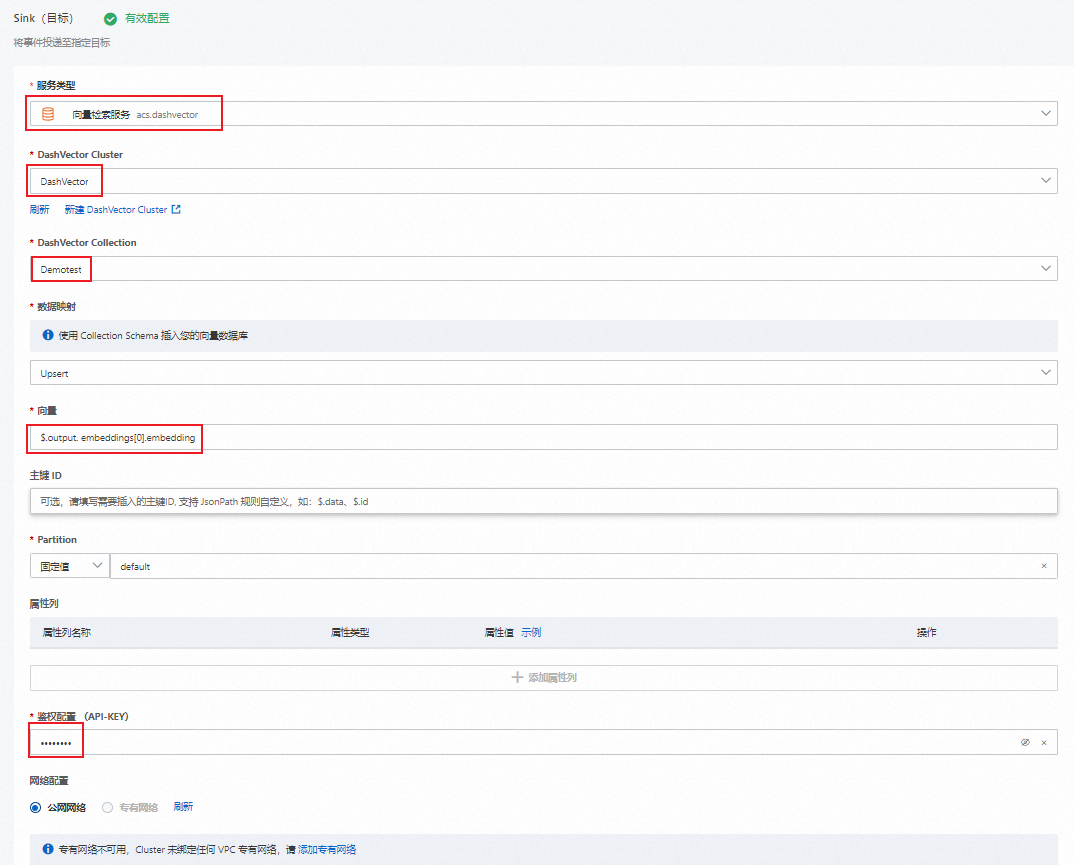
在Sink(目標)配置向導頁面,按照以下表格說明配置參數信息,然后單擊保存。
配置項
示例值
說明
服務類型
向量檢索服務
在下拉框中選擇向量檢索服務。
DashVector Cluster
DashVector
選擇創建成功的數據庫,如果沒有,可單擊新建 DashVector Cluster進行創建。
DashVector Collection
Demotest
選擇創建成功的Collection。
數據映射
Upsert
選擇Upsert方式插入您的向量數據庫。
向量
$.output. embeddings[0].embedding填寫上游Dashscope的TextEmbedding投遞的向量信息。如
$.output. embeddings[0].embedding。鑒權配置 (API-KEY)
********
獲取的DashVector API-KEY參數。
2. 創建Search數據檢索任務
在進行數據檢索時,需要首先對數據進行Embedding,然后將Embedding后的向量值與數據庫值做檢索排序。最后填寫Prompt模板,通過自然語言理解和語義分析,理解數據檢索意圖。
該任務可以部署在云端函數計算,也可以在直接本地環境中執行。
創建
embedding.py文件,將需要檢索的問題進行文本向量化。示例代碼如下所示:import os import dashscope from dashscope import TextEmbedding def generate_embeddings(news): rsp = TextEmbedding.call( model=TextEmbedding.Models.text_embedding_v1, input=news ) embeddings = [record['embedding'] for record in rsp.output['embeddings']] return embeddings if isinstance(news, list) else embeddings[0] if __name__ == '__main__': dashscope.api_key = '{your-dashscope-api-key}' # 需要您替換成自己創建的Dashscope API-KEY 。創建
search.py文件,并將如下示例代碼復制到search.py文件中,通過DashVector的向量檢索能力來檢索相似度的最高的內容。from dashvector import Client from embedding import generate_embeddings def search_relevant_news(question): # 初始化 dashvector client client = Client( api_key='{your-dashvector-api-key}', # 需要您替換成自己創建的Dashvector API-KEY。 endpoint='{your-dashvector-cluster-endpoint}' ) # 獲取存入的集合 collection = client.get('news_embedings') assert collection # 向量檢索:指定 topk = 1 rsp = collection.query(generate_embeddings(question), output_fields=['raw'], topk=1) assert rsp return rsp.output[0].fields['raw']創建
answer.py文件,就可以按照特定的模板作為Prompt向LLM發起提問了,本示例中選用的LLM是通義千問,代碼示例如下:from dashscope import Generation def answer_question(question, context): prompt = f'''請基于```內的內容回答問題。" ``` {context} ``` 我的問題是:{question}。 ''' rsp = Generation.call(model='qwen-turbo', prompt=prompt) return rsp.output.text創建
run.py文件,并將如下示例代碼復制到run.py文件中,并執行run.py文件。import dashscope from search import search_relevant_news from answer import answer_question if __name__ == '__main__': dashscope.api_key = '{your-dashscope-api-key}' # 需要您替換成自己創建的DashScope API-KEY。 question = 'EventBridge 是什么,它有哪些能力?' context = search_relevant_news(question) answer = answer_question(question, context) print(f'question: {question}\n' f'answer: {answer}')