為了更好地滿足各種不同的業務場景,StarRocks支持多種數據模型,StarRocks中存儲的數據需要按照特定的模型進行組織。本文為您介紹數據導入的基本概念、原理、系統配置、不同導入方式的適用場景,以及一些最佳實踐案例和常見問題。
背景信息
數據導入功能是將原始數據按照相應的模型進行清洗轉換并加載到StarRocks中,方便查詢使用。StarRocks提供了多種導入方式,您可以根據數據量大小或導入頻率等要求選擇最適合自己業務需求的導入方式。
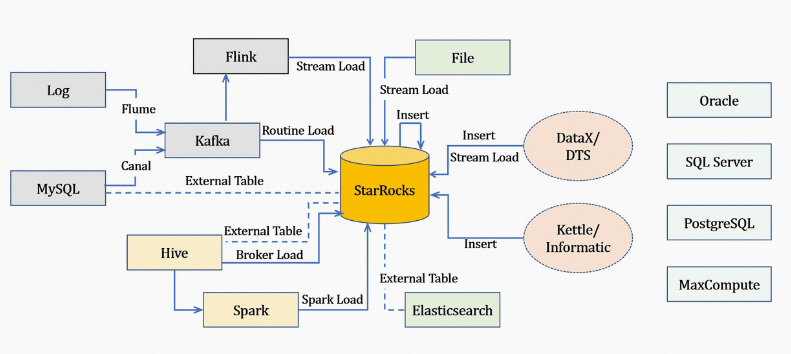
- 離線數據導入:如果數據源是Hive或HDFS,推薦使用Broker Load。如果數據表很多導入比較麻煩可以使用Hive外表,性能會比Broker load導入效果差,但是可以避免數據搬遷。
- 實時數據導入:日志數據和業務數據庫的Binlog同步到Kafka后,優先推薦通過Routine Load導入StarRocks。如果導入過程中有復雜的多表關聯和ETL預處理可以使用Flink(Flink Connector)處理以后,再通過Stream Load寫入StarRocks。
- 程序寫入StarRocks:推薦使用Stream Load,可以參見Stream Load中Java或Python的Demo。
- 文本文件導入:推薦使用Stream Load。
- MySQL數據導入:推薦使用MySQL外表,通過
insert into new_table select * from external_table的方式導入。 - StarRocks內部導入:推薦使用Insert Into方式導入,跟外部調度器配合實現簡單的ETL處理。
注意事項
- 選擇合適的導入方式:根據數據量大小、導入頻次或數據源所在位置選擇導入方式。
例如,如果原始數據存放在HDFS上,則使用Broker load導入。
- 確定導入方式的協議:如果選擇了Broker Load導入方式,則外部系統需要能使用MySQL協議定期提交和查看導入作業。
- 確定導入方式的類型:導入方式分為同步或異步。如果是異步導入方式,外部系統在提交創建導入后,必須調用查看導入命令,根據查看導入命令的結果來判斷導入是否成功。
- 制定Label生成策略:Label生成策略需滿足對每一批次數據唯一且固定的原則。
- 保證Exactly-Once:外部系統需要保證數據導入的At-Least-Once,StarRocks的Label機制可以保證數據導入的At-Most-Once,即可整體上保證數據導入的Exactly-Once。
基本概念
| 名詞 | 描述 |
|---|---|
| 導入作業 | 讀取用戶提交的源數據并進行清洗轉換后,將數據導入到StarRocks系統中。導入完成后,數據即可被用戶查詢到。 |
| Label | 用于標識一個導入作業,所有導入作業都有一個Label。 Label可由用戶指定或系統自動生成。Label在一個數據庫內是唯一的,一個Label僅可用于一個成功的導入作業。當一個Label對應的導入作業成功后,不可再重復使用該Label提交導入作業。如果某Label對應的導入作業失敗,則該Label可以被再使用。該機制可以保證Label對應的數據最多被導入一次,即At-Most-Once語義。 |
| 原子性 | StarRocks中所有導入方式都提供原子性保證,即同一個導入作業內的所有有效數據要么全部生效,要么全部不生效,不會出現僅導入部分數據的情況。此處的有效數據不包括由于類型轉換錯誤等數據質量問題而被過濾的數據。 |
| MySQL和HTTP協議 | StarRocks提供MySQL協議和HTTP協議兩種訪問協議接口來提交作業。 |
| Broker Load | Broker導入,即通過部署的Broker程序讀取外部數據源(例如HDFS)中的數據,并導入到StarRocks。Broker進程利用自身的計算資源對數據進行預處理導入。 |
| FE | Frontend,StarRocks系統的元數據和調度節點。在導入流程中主要負責導入執行計劃的生成和導入任務的調度工作。 |
| BE | Backend,StarRocks系統的計算和存儲節點。在導入流程中主要負責數據的ETL和存儲。 |
| Tablet | StarRocks表的邏輯分片,一個表按照分區、分桶規則可以劃分為多個分片,詳情請參見數據分布。 |
基本原理
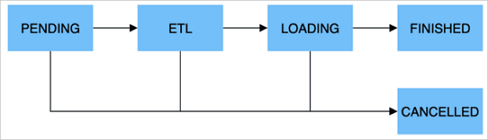
| 階段 | 描述 |
|---|---|
| PENDING | 非必須。該階段是指用戶提交導入作業后,等待FE調度執行。 |
| ETL | 非必須。該階段執行數據的預處理,包括清洗、分區、排序和聚合等。 |
| LOADING | 該階段先對數據進行清洗和轉換,然后將數據發送給BE處理。當數據全部導入后,進入等待生效過程,此時導入作業依舊是LOADING狀態。 |
| FINISHED | 在導入作業涉及的所有數據均生效后,作業的狀態變成FINISHED,FINISHED后導入的數據均可查詢。FINISHED是導入作業的最終狀態。 |
| CANCELLED | 在導入作業狀態變為FINISHED之前,作業隨時可能被取消并進入CANCELLED狀態,例如,您手動取消或導入出現錯誤等。CANCELLED也是導入作業的一種最終狀態。 |
| 類型 | 描述 |
|---|---|
| 整型類 | TINYINT、SMALLINT、INT、BIGINT、LARGEINT。例如:1,1000,1234。 |
| 浮點類 | FLOAT、DOUBLE、DECIMAL。例如:1.1,0.23,0.356。 |
| 日期類 | DATE、DATETIME。例如:2017-10-03,2017-06-13 12:34:03。 |
| 字符串類 | CHAR、VARCHAR。例如:I am a student,a。 |
導入方式
為適配不同的數據導入需求,StarRocks系統提供了以下導入方式,以支持不同的數據源(例如HDFS、Kafka和本地文件等),或者按不同的方式導入數據,StarRocks目前導入數據的方式分為同步導入和異步導入兩種。
所有導入方式都支持CSV數據格式。其中Broker Load還支持Parquet和ORC數據格式。
導入方式介紹
| 導入方式 | 描述 | 導入類型 |
|---|---|---|
| Broker Load | 通過Broker進程訪問并讀取外部數據源,然后采用MySQL協議向StarRocks創建導入作業。提交的作業將異步執行,您可以通過SHOW LOAD命令查看導入結果。Broker Load適用于源數據在Broker進程可訪問的存儲系統(例如HDFS)中,數據量為幾十GB到上百GB,詳細信息請參見Broker Load。 | 異步導入 |
| Stream Load | 是一種同步執行的導入方式。您可以通過HTTP協議發送請求將本地文件或數據流導入到StarRocks中,并等待系統返回導入的結果狀態,從而判斷導入是否成功。 Stream Load適用于導入本地文件,或通過程序導入數據流中的數據,詳細信息請參見Stream Load。 | 同步導入 |
| Routine Load | Routine Load(例行導入)提供了一種自動從指定數據源進行數據導入的功能。您可以通過MySQL協議提交例行導入作業,生成一個常駐線程,不間斷的從數據源(例如Kafka)中讀取數據并導入到StarRocks中,詳細信息請參見Routine Load。 | 異步導入 |
| Insert Into | 類似MySQL中的Insert語句,StarRocks提供INSERT INTO tbl SELECT ...;的方式從StarRocks的表中讀取數據并導入到另一張表,或者通過INSERT INTO tbl VALUES(...);插入單條數據,詳細信息請參見Insert Into。 | 同步導入 |
導入類型
- 同步導入
同步導入方式即用戶創建導入任務,StarRocks同步執行,執行完成后返回導入結果。用戶可以通過該結果判斷導入是否成功。
操作步驟:- 用戶(外部系統)創建導入任務。
- StarRocks返回導入結果。
- 用戶(外部系統)判斷導入結果。如果導入結果為失敗,則可以再次創建導入任務。
- 異步導入
異步導入方式即用戶創建導入任務后,StarRocks直接返回創建成功。創建成功不代表數據已經導入成功。導入任務會被異步執行,用戶在創建成功后,需要通過輪詢的方式發送查看命令查看導入作業的狀態。如果創建失敗,則可以根據失敗信息,判斷是否需要再次創建。
操作步驟:- 用戶(外部系統)創建導入任務。
- StarRocks返回創建任務的結果。
- 用戶(外部系統)判斷創建任務的結果,如果成功則進入步驟4;如果失敗則可以回到步驟1,重新嘗試創建導入任務。
- 用戶(外部系統)輪詢查看任務狀態,直至狀態變為FINISHED或CANCELLED。
適用場景
| 場景 | 描述 |
|---|---|
| HDFS導入 | 如果HDFS導入源數據存儲在HDFS中,當數據量為幾十GB到上百GB時,則可以采用Broker Load方法向StarRocks導入數據。此時要求部署的Broker進程可以訪問HDFS數據源。導入數據的作業異步執行,您可以通過SHOW LOAD命令查看導入結果。 |
| 本地文件導入 | 數據存儲在本地文件中,數據量小于10 GB,可以采用Stream Load方法將數據快速導入StarRocks系統。采用HTTP協議創建導入作業,作業同步執行,您可以通過HTTP請求的返回值判斷導入是否成功。 |
| Kafka導入 | 數據來自于Kafka等流式數據源,需要向StarRocks系統導入實時數據時,可以采用Routine Load方法。您通過MySQL協議創建例行導入作業,StarRocks持續不斷地從Kafka中讀取并導入數據。 |
| Insert Into導入 | 手工測試及臨時數據處理時可以使用Insert Into方法向StarRocks表中寫入數據。其中, |
內存限制
您可以通過設置參數來限制單個導入作業的內存使用,以防止導入占用過多的內存而導致系統OOM。不同導入方式限制內存的方式略有不同,詳情可以參見各個導入方式的文檔。
一個導入作業通常會分布在多個BE上執行,內存參數限制的是一個導入作業在單個BE上的內存使用,而不是在整個集群的內存使用。同時,每個BE會設置可用于導入作業的內存總上限,詳情請參見通用系統配置。配置限制了所有在該BE上運行的導入任務的總體內存使用上限。
較小的內存限制可能會影響導入效率,因為導入流程可能會因為內存達到上限而頻繁的將內存中的數據寫回磁盤。而過大的內存限制可能導致當導入并發較高時系統OOM。所以需要根據需求合理地設置內存參數。
通用系統配置
FE配置
以下配置屬于FE的系統配置,可以通過FE的配置文件fe.conf來修改。
| 參數 | 描述 |
|---|---|
| max_load_timeout_second | 導入超時時間的最大、最小取值范圍,均以秒為單位。默認的最大超時時間為3天,最小超時時間為1秒。您自定義的導入超時時間不可超過該范圍。該參數通用于所有類型的導入任務。 |
| min_load_timeout_second | |
| desired_max_waiting_jobs | 等待隊列可以容納的最多導入任務數目,默認值為100。 例如,FE中處于PENDING狀態(即等待執行)的導入任務數目達到該值,則新的導入請求會被拒絕。此配置僅對異步執行的導入有效,如果處于等待狀態的異步導入任務數達到限額,則后續創建導入的請求會被拒絕。 |
| max_running_txn_num_per_db | 每個數據庫中正在運行的導入任務的最大個數(不區分導入類型、統一計數),默認值為100。 當數據庫中正在運行的導入任務超過最大值時,后續的導入任務不會被執行。如果是同步作業,則作業會被拒絕;如果是異步作業,則作業會在隊列中等待。 |
| label_keep_max_second | 導入任務記錄的保留時間。 已經完成的(FINISHED或CANCELLED)導入任務記錄會在StarRocks系統中保留一段時間,時間長短則由此參數決定。參數默認值為3天。該參數通用于所有類型的導入任務。 |
BE配置
以下配置屬于BE的系統配置,可以通過BE的配置文件be.conf來修改。
| 參數 | 描述 |
|---|---|
| push_write_mbytes_per_sec | BE上單個Tablet的寫入速度限制。默認值是10,即10MB/s。 根據Schema以及系統的不同,通常BE對單個Tablet的最大寫入速度大約在10~30MB/s之間。您可以適當調整該參數來控制導入速度。 |
| write_buffer_size | 導入數據在BE上會先寫入到一個內存塊,當該內存塊達到閾值后才會寫回磁盤。默認值為100 MB。 過小的閾值可能導致BE上存在大量的小文件。您可以適當提高該閾值減少文件數量。但過大的閾值可能導致RPC超時,詳細請參見參數tablet_writer_rpc_timeout_sec。 |
| tablet_writer_rpc_timeout_sec | 導入過程中,發送一個Batch(1024行)的RPC超時時間。默認為600秒。 因為該RPC可能涉及多個分片內存塊的寫盤操作,所以可能會因為寫盤導致RPC超時,可以適當調整超時時間來減少超時錯誤(例如send batch fail)。同時,如果調大參數write_buffer_size,則tablet_writer_rpc_timeout_sec參數也需要適當調大。 |
| streaming_load_rpc_max_alive_time_sec | 在導入過程中,StarRocks會為每個Tablet開啟一個Writer,用于接收數據并寫入。該參數指定了Writer的等待超時時間。默認為600秒。 如果在參數指定時間內Writer沒有收到任何數據,則Writer會被自動銷毀。當系統處理速度較慢時,Writer可能長時間接收不到下一批數據,導致導入報錯 |
| load_process_max_memory_limit_percent | 分別為最大內存和最大內存百分比,限制了單個BE上可用于導入任務的內存上限。系統會在兩個參數中取較小者,作為最終的BE導入任務內存使用上限。
|
| load_process_max_memory_limit_bytes |