Routine Load是一種例行導入方式,StarRocks通過該方式支持從Kafka持續不斷的導入數據,并且支持通過SQL控制導入任務的暫停、重啟和停止。本文為您介紹Routine Load導入的基本原理、導入示例以及常見問題。
基本概念
- RoutineLoadJob:提交的一個例行導入任務。
- JobScheduler:例行導入任務調度器,用于調度和拆分一個RoutineLoadJob為多個Task。
- Task:RoutineLoadJob被JobScheduler根據規則拆分的子任務。
- TaskScheduler:任務調度器,用于調度Task的執行。
基本原理
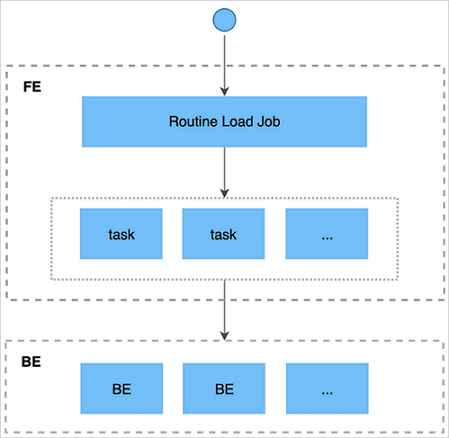
- 用戶通過支持MySQL協議的客戶端向FE提交一個Kafka導入任務。
- FE將一個導入任務拆分成若干個Task,每個Task負責導入指定的一部分數據。
- 每個Task被分配到指定的BE上執行。在BE上,一個Task被視為一個普通的導入任務,通過Stream Load的導入機制進行導入。
- BE導入完成后,向FE匯報。
- FE根據匯報結果,繼續生成后續新的Task,或者對失敗的Task進行重試。
- FE會不斷的產生新的Task,來完成數據不間斷的導入。
導入流程
環境要求
支持訪問無認證或使用SSL方式認證的Kafka集群。
支持的消息格式如下:
CSV文本格式,每一個message為一行,且行尾不包含換行符。
JSON文本格式。
不支持Array類型。
僅支持Kafka 0.10.0.0及以上版本。
創建導入任務
語法
CREATE ROUTINE LOAD <database>.<job_name> ON <table_name> [COLUMNS TERMINATED BY "column_separator" ,] [COLUMNS (col1, col2, ...) ,] [WHERE where_condition ,] [PARTITION (part1, part2, ...)] [PROPERTIES ("key" = "value", ...)] FROM [DATA_SOURCE] [(data_source_properties1 = 'value1', data_source_properties2 = 'value2', ...)]相關參數描述如下表所示。
參數 是否必填 描述 job_name 是 導入任務的名稱,前綴可以攜帶導入數據庫名稱,常見命名方式為時間戳+表名。 一個DataBase內,任務名稱不可重復。 table_name 是 導入的目標表的名稱。 COLUMNS TERMINATED子句 否 指定源數據文件中的列分隔符,分隔符默認為\t。 COLUMNS子句 否 指定源數據中列和表中列的映射關系。 - 映射列:例如,目標表有三列col1、col2和col3,源數據有4列,其中第1、2、4列分別對應col2、col1和col3,則書寫為
COLUMNS (col2, col1, temp, col3),其中temp列為不存在的一列,用于跳過源數據中的第三列。 - 衍生列:除了直接讀取源數據的列內容之外,StarRocks還提供對數據列的加工操作。例如,目標表后加入了第四列col4,其結果由col1 + col2產生,則可以書寫為
COLUMNS (col2, col1, temp, col3, col4 = col1 + col2)。
WHERE子句 否 指定過濾條件,可以過濾掉不需要的行。過濾條件可以指定映射列或衍生列。 例如,只導入k1大于100并且k2等于1000的行,則書寫為
WHERE k1 > 100 and k2 = 1000。PARTITION子句 否 指定導入目標表的Partition。如果不指定,則會自動導入到對應的Partition中。 PROPERTIES子句 否 指定導入任務的通用參數。 desired_concurrent_number 否 導入并發度,指定一個導入任務最多會被分成多少個子任務執行。必須大于0,默認值為3。 max_batch_interval 否 每個子任務的最大執行時間。范圍為5~60,單位是秒。默認值為10。 1.15版本后,該參數表示子任務的調度時間,即任務多久執行一次。任務的消費數據時間為fe.conf中的routine_load_task_consume_second,默認為3s。任務的執行超時時間為fe.conf中的routine_load_task_timeout_second,默認為15s。
max_batch_rows 否 每個子任務最多讀取的行數。必須大于等于200000。默認值為200000。 1.15版本后,該參數只用于定義錯誤檢測窗口范圍,窗口的范圍是10 * max-batch-rows。
max_batch_size 否 每個子任務最多讀取的字節數。單位為字節,范圍是100 MB到1 GB。默認值為100 MB。 1.15版本后,廢棄該參數,任務消費數據的時間為fe.conf中的routine_load_task_consume_second,默認為3s。
max_error_number 否 采樣窗口內,允許的最大錯誤行數。必須大于等于0。默認是0,即不允許有錯誤行。 重要 被WHERE條件過濾掉的行不算錯誤行。strict_mode 否 是否開啟嚴格模式,默認為開啟。 如果開啟后,非空原始數據的列類型變換為NULL,則會被過濾。關閉方式為設置該參數為false。
timezone 否 指定導入任務所使用的時區。 默認為使用Session的timezone參數。該參數會影響所有導入涉及的和時區有關的函數結果。
DATA_SOURCE 是 指定數據源,請使用KAFKA。 data_source_properties 否 指定數據源相關的信息。包括以下參數: - kafka_broker_list:Kafka的Broker連接信息,格式為
ip:host。多個Broker之間以逗號(,)分隔。 - kafka_topic:指定待訂閱的Kafka的Topic。說明 如果指定數據源相關的信息,則kafka_broker_list和kafka_topic必填。
- kafka_partitions和kafka_offsets:指定需要訂閱的Kafka Partition,以及對應的每個Partition的起始offset。
- property:Kafka相關的屬性,功能等同于Kafka Shell中
"--property"參數。創建導入任務更詳細的語法可以通過執行HELP ROUTINE LOAD;命令查看。
- 映射列:例如,目標表有三列col1、col2和col3,源數據有4列,其中第1、2、4列分別對應col2、col1和col3,則書寫為
示例:向StarRocks提交一個無認證的Routine Load導入任務example_tbl2_ordertest,持續消費Kafka集群中Topic ordertest2的消息,并導入至example_tbl2表中,導入任務會從此Topic所指定分區的最早位點開始消費。
CREATE ROUTINE LOAD load_test.example_tbl2_ordertest ON example_tbl COLUMNS(commodity_id, customer_name, country, pay_time, price, pay_dt=from_unixtime(pay_time, '%Y%m%d')) PROPERTIES ( "desired_concurrent_number"="5", "format" ="json", "jsonpaths" ="[\"$.commodity_id\",\"$.customer_name\",\"$.country\",\"$.pay_time\",\"$.price\"]" ) FROM KAFKA ( "kafka_broker_list" ="<kafka_broker1_ip>:<kafka_broker1_port>,<kafka_broker2_ip>:<kafka_broker2_port>", "kafka_topic" = "ordertest2", "kafka_partitions" ="0,1,2,3,4", "property.kafka_default_offsets" = "OFFSET_BEGINNING" );示例:使用SSL安全協議訪問Kafka,具體的配置示例如下。
-- 指定安全協議為SSL。 "property.security.protocol" = "ssl", -- CA證書的位置。 "property.ssl.ca.location" = "FILE:ca-cert", -- 如果Kafka Server端開啟了Client認證,則還需設置以下三個參數: -- Client的公鑰位置。 "property.ssl.certificate.location" = "FILE:client.pem", -- Client的私鑰位置。 "property.ssl.key.location" = "FILE:client.key", -- Client私鑰的密碼。 "property.ssl.key.password" = "******"關于創建文件的詳細信息,請參見CREATE FILE。
說明在使用CREATE FILE時,請使用OSS的HTTP訪問地址作為
url。具體的使用方式,請參見OSS訪問域名使用規則。
查看任務狀態
顯示load_test下,所有的例行導入任務(包括已停止或取消的任務)。結果為一行或多行。
USE load_test; SHOW ALL ROUTINE LOAD;顯示load_test下,名稱為example_tbl2_ordertest的當前正在運行的例行導入任務。
SHOW ROUTINE LOAD FOR load_test.example_tbl2_ordertest;在EMR StarRocks Manager控制臺,單擊元數據管理,單擊待查看的數據庫名稱,單擊任務,即可在Kafka導入頁簽查看任務的執行狀態。
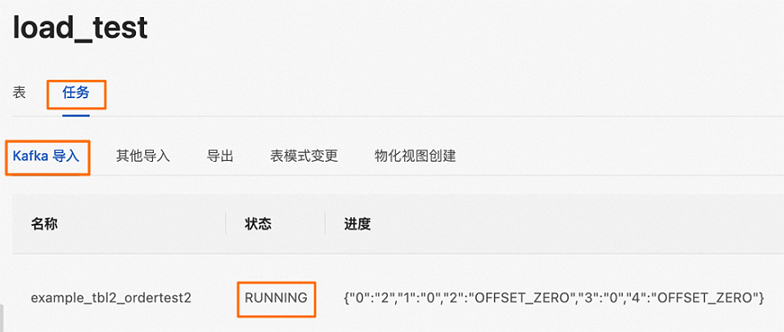
StarRocks只能查看當前正在運行中的任務,已結束和未開始的任務無法查看。
執行SHOW ALL ROUTINE LOAD命令,可以查看當前正在運行的所有Routine Load任務,返回如下類似信息。
*************************** 1. row ***************************
Id: 14093
Name: routine_load_wikipedia
CreateTime: 2020-05-16 16:00:48
PauseTime: N/A
EndTime: N/A
DbName: default_cluster:load_test
TableName: routine_wiki_edit
State: RUNNING
DataSourceType: KAFKA
CurrentTaskNum: 1
JobProperties: {"partitions":"*","columnToColumnExpr":"event_time,channel,user,is_anonymous,is_minor,is_new,is_robot,is_unpatrolled,delta,added,deleted","maxBatchIntervalS":"10","whereExpr":"*","maxBatchSizeBytes":"104857600","columnSeparator":"','","maxErrorNum":"1000","currentTaskConcurrentNum":"1","maxBatchRows":"200000"}
DataSourceProperties: {"topic":"starrocks-load","currentKafkaPartitions":"0","brokerList":"localhost:9092"}
CustomProperties: {}
Statistic: {"receivedBytes":150821770,"errorRows":122,"committedTaskNum":12,"loadedRows":2399878,"loadRowsRate":199000,"abortedTaskNum":1,"totalRows":2400000,"unselectedRows":0,"receivedBytesRate":12523000,"taskExecuteTimeMs":12043}
Progress: {"0":"13634667"}
ReasonOfStateChanged:
ErrorLogUrls: http://172.26.**.**:9122/api/_load_error_log?file=__shard_53/error_log_insert_stmt_47e8a1d107ed4932-8f1ddf7b01ad2fee_47e8a1d107ed4932_8f1ddf7b01ad2fee, http://172.26.**.**:9122/api/_load_error_log?file=__shard_54/error_log_insert_stmt_e0c0c6b040c044fd-a162b16f6bad53e6_e0c0c6b040c044fd_a162b16f6bad53e6, http://172.26.**.**:9122/api/_load_error_log?file=__shard_55/error_log_insert_stmt_ce4c95f0c72440ef-a442bb300bd743c8_ce4c95f0c72440ef_a442bb300bd743c8
OtherMsg:
1 row in set (0.00 sec)本示例創建名為routine_load_wikipedia的導入任務,相關參數描述如下表。
參數 | 描述 |
State | 導入任務狀態。RUNNING表示該導入任務處于持續運行中。 |
Statistic | 進度信息,記錄了從創建任務開始后的導入信息。 |
receivedBytes | 接收到的數據大小,單位是Byte。 |
errorRows | 導入錯誤行數。 |
committedTaskNum | FE提交的Task數。 |
loadedRows | 已導入的行數。 |
loadRowsRate | 導入數據速率,單位是行每秒(row/s)。 |
abortedTaskNum | BE失敗的Task數。 |
totalRows | 接收的總行數。 |
unselectedRows | 被WHERE條件過濾的行數。 |
receivedBytesRate | 接收數據速率,單位是Bytes/s。 |
taskExecuteTimeMs | 導入耗時,單位是ms。 |
ErrorLogUrls | 錯誤信息日志,可以通過URL看到導入過程中的錯誤信息。 |
暫停導入任務
使用PAUSE語句后,此時導入任務進入PAUSED狀態,數據暫停導入,但任務未終止,可以通過RESUME語句重啟任務。
PAUSE ROUTINE LOAD FOR <job_name>;暫停導入任務后,任務的State變更為PAUSED,Statistic和Progress中的導入信息停止更新。此時,任務并未終止,通過SHOW ROUTINE LOAD語句可以看到已經暫停的導入任務。
恢復導入任務
使用RESUME語句后,任務會短暫的進入NEED_SCHEDULE狀態,表示任務正在重新調度,一段時間后會重新恢復至RUNNING狀態,繼續導入數據。
RESUME ROUTINE LOAD FOR <job_name>;停止導入任務
使用STOP語句讓導入任務進入STOP狀態,數據停止導入,任務終止,無法恢復數據導入。
STOP ROUTINE LOAD FOR <job_name>;停止導入任務后,任務的State變更為STOPPED,Statistic和Progress中的導入信息再也不會更新。此時,通過SHOW ROUTINE LOAD語句無法看到已經停止的導入任務。
最佳實踐案例
本案例是創建了一個Routine Load導入任務,持續不斷地消費Kafka集群的CSV格式的數據,然后導入至StarRocks中。
在Kafka集群中執行以下操作。
創建測試的topic。
kafka-topics.sh --create --topic order_sr_topic --replication-factor 3 --partitions 10 --bootstrap-server "core-1-1:9092,core-1-2:9092,core-1-3:9092"執行如下命令,生產數據。
kafka-console-producer.sh --broker-list core-1-1:9092 --topic order_sr_topic輸入測試數據。
2020050802,2020-05-08,Johann Georg Faust,Deutschland,male,895 2020050802,2020-05-08,Julien Sorel,France,male,893 2020050803,2020-05-08,Dorian Grey,UK,male,1262 2020051001,2020-05-10,Tess Durbeyfield,US,female,986 2020051101,2020-05-11,Edogawa Conan,japan,male,8924
在StarRocks集群中執行以下操作。
執行以下命令,創建目標數據庫和數據表。
根據CSV數據中需要導入的幾列(例如除第五列性別外的其余五列需要導入至StarRocks), 在StarRocks集群的目標數據庫load_test 中創建表routine_load_tbl_csv。
CREATE TABLE load_test.routine_load_tbl_csv ( `order_id` bigint NOT NULL COMMENT "訂單編號", `pay_dt` date NOT NULL COMMENT "支付日期", `customer_name` varchar(26) NULL COMMENT "顧客姓名", `nationality` varchar(26) NULL COMMENT "國籍", `price`double NULL COMMENT "支付金額" ) ENGINE=OLAP PRIMARY KEY (order_id,pay_dt) DISTRIBUTED BY HASH(`order_id`) BUCKETS 5;執行以下命令,創建導入任務。
CREATE ROUTINE LOAD load_test.routine_load_tbl_ordertest_csv ON routine_load_tbl_csv COLUMNS TERMINATED BY ",", COLUMNS (order_id, pay_dt, customer_name, nationality, temp_gender, price) PROPERTIES ( "desired_concurrent_number" = "5" ) FROM KAFKA ( "kafka_broker_list" ="192.168.**.**:9092,192.168.**.**:9092,192.168.**.**:9092", "kafka_topic" = "order_sr_topic", "kafka_partitions" ="0,1,2,3,4", "property.kafka_default_offsets" = "OFFSET_BEGINNING" )執行以下命令,查看名稱為routine_load_tbl_ordertest_csv的導入任務的信息。
SHOW ROUTINE LOAD FOR routine_load_tbl_ordertest_csv;如果狀態為RUNNING,則說明作業運行正常。

執行以下命令,查詢目標表中的數據,您會發現數據已經同步完成。
SELECT * FROM routine_load_tbl_csv;您還可以任務進行以下操作:
暫停導入任務
PAUSE ROUTINE LOAD FOR routine_load_tbl_ordertest_csv;恢復導入任務
RESUME ROUTINE LOAD FOR routine_load_tbl_ordertest_csv;修改導入任務
說明僅支持修改狀態為PAUSED的任務。
例如:修改desired_concurrent_number為6。
ALTER ROUTINE LOAD FOR routine_load_tbl_ordertest_csv PROPERTIES ( "desired_concurrent_number" = "6" )停止導入任務
STOP ROUTINE LOAD FOR routine_load_tbl_ordertest_csv;