本文匯總了集群管理的常見問題。
擴容時報錯“The specified parameter AddNumber is not valid”,該如何處理?
服務類常見問題
EMR Doctor常見問題
EMR集群是否支持升級版本?
EMR集群不支持升級,也不能進行服務的升級。如果有升級需求,請釋放集群并重新創建集群。
EMR集群都支持哪些服務?
不同版本、不同集群支持的服務有所不同,詳情請參見版本概述。
EMR支持Hue服務嗎?如果不支持是否有替代方案?
EMR DataLake集群(EMR-5.8.0和EMR-3.42.0及以上版本)不再包含Hue組件。如果您想在DataLake集群使用Hue,請參見在DataLake集群自建Hue組件。
EMR支持Oozie服務嗎?如果不支持是否有替代方案?
EMR DataLake集群(EMR-5.8.0和EMR-3.42.0及以上版本)不再包含Oozie組件。如果您需要使用工作流調度服務,可以通過EMR Workflow來實現,詳情請參見什么是EMR Workflow。
高可用集群為什么部署3個Master節點?
新版EMR高可用集群采用3 Master節點,比2 Master更具可靠性。現在已不支持2 Master節點。
對于高可用集群,EMR會把Master節點分布在不同的底層硬件上以降低故障風險。
EMR支持哪些地域?
當前EMR支持的地域有:華東1(杭州)、華東2(上海)、華北1(青島)、華北2(北京)、華北3(張家口)、華北5(呼和浩特)、華北6(烏蘭察布)、華南1(深圳)、西南1(成都)、中國香港、日本(東京)、新加坡、馬來西亞(吉隆坡)、印度尼西亞(雅加達)、德國(法蘭克福)、英國(倫敦)、美國(硅谷)、美國(弗吉尼亞)、阿聯酋(迪拜)。
如何開啟磁盤加密?開啟后有什么影響?
您可以在創建集群頁面基礎配置階段的高級配置區域,選擇是否開啟數據盤加密,詳情請參見開啟數據盤加密。
僅支持在創建集群時開啟數據盤加密,集群創建后無法開啟該功能。
加密數據盤后,數據盤上的動態數據傳輸以及靜態數據都會被加密。如果您的業務存在安全合規要求,則可以使用該功能。數據盤加密后在ECS的OS層面對應用是透明的,因此不會影響作業運行。
如何清理創建失敗的集群?
集群創建失敗,通常是由于RDS配置錯誤導致集群部署失敗,或者是由于部分ECS沒有庫存導致的。
如果在創建過程中,集群已經創建出來部分ECS實例,且集群狀態為啟動失敗,這時需要您前往ECS控制臺釋放該部分ECS實例,在您的ECS實例全部被釋放后,EMR集群將會自動釋放。
如果在創建過程中,EMR部署失敗,且集群狀態為異常終止,此時集群不存在任何資源,也不存在任何收費,您可以單擊目標集群操作列的刪除,清除該集群。
創建集群后,還支持新增服務嗎?
EMR支持在集群創建成功后新增部分未安裝的服務,詳情請參見新增服務。
新增服務后,因為部分服務需要手動修改配置并進行重啟,所以請在業務低峰期進行新增服務操作。
因為各版本的服務有差異,所以具體待添加的服務請以控制臺界面顯示為準。
修改服務配置后,是否需要重啟服務?
EMR集群的Spark、Hive、HDFS等服務端類型配置修改后,需要重啟服務才能生效。EMR集群的客戶端類型配置修改后,只需要單擊部署客戶端配置就能生效,不用重啟服務。修改或添加配置項的具體操作請參見管理配置項。
如何查詢EMR集群有哪些節點?
您可以通過ListNodes接口查詢EMR集群節點列表,詳情請參見ListNodes - 查詢節點。
EMR的滾動重啟是什么意思?
滾動重啟機制是指在一個ECS實例重啟完成且該實例上的大數據服務全部恢復后,再啟動下一個ECS實例。每個節點重啟耗時約5分鐘。
集群創建后如何綁定公網IP?
您可以單獨申請EIP地址,并綁定到未分配公網IP地址的專有網絡VPC類型的實例上,使ECS實例可以通過公網訪問,詳情請參見綁定EIP。
什么場景下開啟部署集?
部署集是阿里云ECS(Elastic Compute Service)提供的能力,用于控制ECS實例分布的策略。建議為使用本地盤機型的Core節點組開啟部署集功能來提升數據安全性。開啟部署集可防止多個ECS實例部署在同一個物理機上,避免當某個物理機發生故障時影響多個ECS實例,導致EMR本地HDFS數據丟失。
受ECS部署集本身的限制,目前最多支持20臺ECS實例加入部署集。具體操作請參見開啟部署集。
擴容集群如何指定部署集?
默認本地盤機型會開啟部署集,其他機型關閉部署集,您可以根據需要自行調整。開啟部署集的具體操作,請參見開啟部署集。
擴容集群如何指定磁盤大小?
擴容時新節點的磁盤大小跟隨節點組設定,無法修改。如有需要,您可以調整節點組的磁盤大小。磁盤擴容的具體操作,請參見擴容磁盤。
是否支持磁盤的擴縮容?
僅支持數據盤擴容,不支持數據盤縮容,不支持系統盤擴容或縮容。
您可以在目標集群的節點管理頁簽,單擊目標節點組的磁盤擴容,對數據盤進行擴容。具體操作,請參見擴容磁盤。
是否支持集群的擴縮容?
如何更換節點組ECS實例的配置?
僅包年包月集群支持通過升配來更換節點組ECS實例的配置,且暫不支持降配。
您可以在包年包月的目標集群的節點管理頁簽,選擇Master和Core節點組的 > 配置升級,升級節點組的配置,詳情請參見升級節點配置。
> 配置升級,升級節點組的配置,詳情請參見升級節點配置。
擴容時報錯“The specified parameter AddNumber is not valid”,該如何處理?
問題現象:在集群擴容中遇到報錯信息
The specified parameter AddNumber is not valid. add instances number :xxx larger than deploymentSet availableAmount: xxx deploymentSetId: ds-uf6gwfou0a13kekupt14xxxx。問題分析:該錯誤表示您集群已開啟部署集功能,且節點組的節點數已到達部署集上限,部署集詳情請參見開啟部署集。
解決方法:請聯系ECS服務為您當前賬號提升部署集上限。
如何停止采集服務日志?
如果您不想EMR收集您的數據,則可以關閉采集服務日志。
關閉日志采集后,EMR的健康檢查和技術支持將受到限制,但其他功能仍可正常使用。因此請謹慎選擇。
解決方法:
關閉采集服務日志
創建集群時:在創建集群的軟件配置階段,單擊允許采集服務運行日志。
創建集群后:在目標集群的基礎信息頁面的軟件信息區域,單擊服務運行日志收集狀態。
驗證關閉情況。
查看/usr/local/ilogtail/user_log_config.json中是否存在
namenode-log信息,不存在則說明服務日志采集已關閉。說明關閉服務日志采集后,大約需要2-3分鐘來同步該配置,請耐心等待。
服務運行日志收集哪些信息?
服務運行日志收集僅包括集群服務組件運行的日志。您可以選擇一鍵開啟或關閉所有服務日志的采集。需要注意的是,關閉日志采集后,集群的健康檢測功能以及售后的技術支持都將受限。
創建集群時默認開啟服務運行日志收集,您可以根據需要選擇是否關閉該功能。具體操作,請參見如何停止采集服務日志?。
哪些集群類型支持EMR Doctor功能?
僅DataLake和Hadoop集群類型支持健康檢查功能。集群創建后,您可以在EMR控制臺目標集群的頁簽使用該功能。
如果您的Hadoop集群沒有此功能,則需要開通EMR Doctor,詳情請參見開通EMR Doctor(Hadoop集群類型)。
EMR Doctor在安裝和升級過程中,是否會對集群組件和集群任務產生影響?
EMR Doctor在安裝和升級過程中不會重啟任何服務,本身過程也不會對您現有任務產生任何影響,并且在安裝結束后,EMR Doctor會將必要參數配置到現有集群中,不需要您再手動進行配置。
EMR Doctor在安裝和升級過程中會對YARN、Spark、Tez和Hive服務進行配置整體下發,如果您現有的部分配置只進行了修改保存,并沒有下發,則需要您確保下發過程不會對服務造成影響。
EMR Doctor都會采集哪些數據?
EMR Doctor不會采集您的實際數據,也不會掃描您的實際文件和文件內容。
EMR Doctor僅采集必要的事件數據,例如任務啟動時間、終止時間、Metrics數據和Counters數據等。
EMR Doctor收費嗎?
當前是不收取任何費用的。
采集操作會對任務的運行會產生什么影響?
EMR Doctor存儲元數據采集會根據用戶資源動態調整采集的資源,不會占用過多用戶資源。
EMR Doctor的任務采集使用Java探針技術,不會單獨啟動Java進程監控。采集使用異步方式,不會阻塞任務主進程,當采集造成的壓力過大時,會自動丟棄采集數據,并且您可以根據參數調整采集頻率等。
TPC-DS部分測試的數據如下表所示。
SQL及使用引擎 | 使用EMR Doctor采集時間(10次平均) | 不使用EMR Doctor采集時間(10次平均) |
query7(Spark) | 21.0s | 21.2s |
query71(Tez) | 50.8s | 49.8s |
query19(MapReduce) | 68.6s | 68.2s |
本文的TPC-DS的實現基于TPC-DS的基準測試,并不能與已發布的TPC-DS基準測試結果相比較,本文中的測試并不符合TPC-DS的基準測試的所有要求。
什么時候可以看到采集報告?
EMR Doctor自安裝和升級之后,日報功能會根據用戶運行的任務以及是否采集存儲元數據來進行分析,所以集群需要存在負載任務。
對于計算任務:當集群的計算任務被收集后,第二天即可看到最新的報告,報告內容是根據前一天的集群任務運行狀態對集群整體進行分析后給出的集群評估建議。
對于存儲分析:EMR Doctor默認不啟用存儲采集分析,您可以手動開啟存儲采集。開啟采集后,通常是上午10點左右進行采集,等待所有采集結束后第二天凌晨才會進行分析并生成報告。如果是當天下午才開啟采集,則需要第三天才能看到結果。
可以給出配置的具體參數值嗎?
EMR Doctor給出的建議,采用的是指向性方式。例如,建議減少內存配置和修改GC參數等,并沒有給出具體的參數值。因為EMR Doctor采用打點抽樣進行采集,盡量避免對您的程序造成影響,即使推薦配置也需要您進行調整,并驗證可行性。
擴容時報錯“ECS庫存不足”,該如何處理?
問題現象:擴容集群時失敗,失敗原因顯示“ECS庫存不足_OutofStock”或“ECS庫存不足_OperationDenied.NoStock”。
問題分析:該錯誤表示您需要擴容的節點組的ECS機型庫存不足,無法滿足您的擴容需求。
解決方法:您可以等待需要擴容的ECS機型庫存充足后再擴容,或者通過新增節點組的方式選擇其他ECS機型對集群進行擴容,詳情請參見新增節點組。
創建集群時報錯“ECS庫存不足”,該如何處理?
問題現象:新建集群或新增節點組時失敗,失敗原因顯示“ECS庫存不足_OutofStock”或“ECS庫存不足_OperationDenied.NoStock”。
問題分析:該錯誤表示您創建集群或新增節點組時選擇的ECS機型庫存不足,無法滿足需求。
解決方法:在創建集群時選擇其他庫存充足且滿足您業務需求的ECS機型。
如何刪除不需要的服務?
目前不支持刪除集群已有的服務。一旦服務被啟動,您將無法通過控制臺或API刪除已有的服務。
如何登錄集群的節點?
E-MapReduce集群創建后,Master節點可以使用創建集群時設置的密碼登錄,其余節點的登錄方式,請查看登錄集群其他節點。
如何查看實例所屬交換機?
在阿里云EMR on ECS中,交換機信息與節點組緊密相關,不可在基礎信息頁面直接查看。您可以在節點管理頁面,單擊實例所屬的節點組名稱,查看該實例關聯的交換機信息。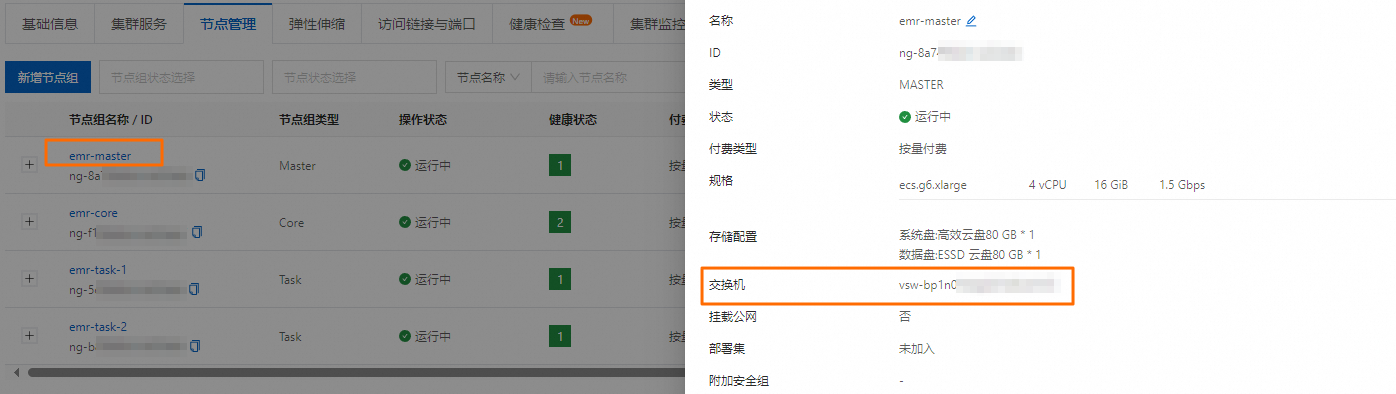
大規模集群網絡丟包如何解決?
問題現象:集群中頻繁出現網絡丟包現象,系統日志中可能會顯示錯誤信息,例如
neighbour: arp_cache: neighbor table overflow!。這表明ARP(Address Resolution Protocol)緩存表達到其容量上限,無法有效管理IP與MAC地址映射,從而導致網絡性能問題。問題分析:在大規模分布式系統中,尤其是當單個集群規模超過1000臺服務器,并且使用的是EMR-5.18.0之前或EMR-3.52.0之前(不包括這兩個版本)時,可能會遭遇網絡不穩定及數據丟包的問題。為此,可以通過調整系統參數來優化ARP Cache的管理。
ARP Cache存儲IP地址與MAC地址的映射關系,其參數配置如下:
net.ipv4.neigh.default.gc_thresh1:當ARP表小于該值時,不進行垃圾回收。默認值為128。net.ipv4.neigh.default.gc_thresh2:當ARP表超出該值時,5秒內進行垃圾回收。默認值為512。net.ipv4.neigh.default.gc_thresh3:ARP表的最大容量。默認值為1024。
說明由于默認配置較小,導致集群規模超過1000臺后,出現網絡丟包和不穩定現象,因此需要調整相關配置。
解決方法:
編輯
/etc/sysctl.conf文件,增加以下內容以擴大ARP緩存的容量限制及優化連接跟蹤最大值。net.ipv4.neigh.default.gc_thresh1 = 512 net.ipv4.neigh.default.gc_thresh2 = 2048 net.ipv4.neigh.default.gc_thresh3 = 10240 net.nf_conntrack_max = 524288執行命令
sudo sysctl -p,以使新的設置生效。說明如果在執行
sysctl -p命令時遇到錯誤信息sysctl: cannot stat /proc/sys/net/nf_conntrack_max: No such file or directory,請首先運行命令sudo modprobe nf_conntrack以加載相應模塊,然后再嘗試使用sysctl -p更新配置。
收到ECS系統事件SystemMaintenance.Redeploy后,應該如何處理?
如果您收到因系統維護實例重新部署(SystemMaintenance.Redeploy)類型的本地盤實例系統事件,表明阿里云檢測到集群節點的ECS實例的底層宿主機存在潛在的軟硬件故障風險,該風險會導致ECS實例重新部署,但請勿直接在ECS控制臺單擊重新部署,以避免數據丟失。
解決方法: