磁盤故障及其運維通常伴隨著磁盤上的數據銷毀。在進行磁盤運維時,您應考慮數據是否需要遷移備份。對于Kafka集群,您還需要考慮Topic分區副本數據是否可以從其他Broker節點分區副本同步恢復。本文以EMR Kafka 2.4.1版本為例,介紹Kafka磁盤故障運維的操作。
業務場景
Kafka將日志數據存儲到磁盤中,當磁盤出現故障時,會導致磁盤IO能力下降、集群吞吐量下降、消息讀寫延時或日志目錄offline等問題。這些情況有可能影響到線上業務平穩運行、數據丟失、Kafka集群容錯能力下降,單塊盤故障甚至有可能因為IO處理能力下降導致集群出現雪崩效應、引起重大生產事故。因此需要對磁盤故障進行有效監控以便及時發現故障。當磁盤發生故障時,應及時完成相關故障的處理,及時恢復集群的容錯能力。
磁盤運維概述
本文從磁盤監控和磁盤故障恢復角度來介紹磁盤運維策略。
磁盤監控
以下內容從Kafka服務層面以及ECS系統層面來簡單了解一下磁盤的監控策略。
Kafka服務層面:可以在云監控系統中設置EMR Kafka集群的OfflineLogDirectoryCount和UnderReplicatedPartitions等指標告警,及時發現相關指標的異常。
ECS系統層面:可以在云監控中設置相應ECS實例的I/O wait和mbps等指標,來監控磁盤的健康狀態。ECS后臺也會自動的檢測磁盤狀態,當發現問題時,會自動為您推送相關的磁盤事件。
磁盤故障恢復
當出現log directory offline、Under Replicated Partition時,需要盡快定位是否是由于磁盤故障導致的。
當出現磁盤故障時,需要根據故障原因、故障影響程度、業務需求(是否接受數據丟失、是否允許服務較長時間不可用)、集群狀態等綜合考慮恢復采取的策略。
如果業務優先保證服務可用,但允許丟失部分數據,則應考慮在可能會丟失數據的情況下,先恢復服務可用性。
如果業務不允許數據丟失,但能容忍服務較長時間不可用,則需要考慮如何盡可能的避免丟失數據的情況出現。
如果業務需要高可用與數據不丟失,則您需要通過合理的集群配置、使用Kafka方式提高系統容錯能力,以避免出現一塊盤故障就導致數據丟失的情況出現。
如果發現因為故障盤IO性能下降導致集群整體性能下降,影響業務,則應快速隔離故障盤來進行業務止損。
當檢測或定位到磁盤故障時,可以考慮如下運維策略:
節點間分區遷移:將故障磁盤中的分區副本遷移到其他Broker,詳情請參見節點間分區遷移方式。
節點內分區遷移:將故障磁盤中的分區副本遷移到當前Broker的其他磁盤,詳情請參見節點內分區遷移方式。
原Broker數據恢復:將異常磁盤從log.dirs中移除,重啟Broker后會自動恢復丟失的Partition數據到本節點的其他目錄,詳情請參見原Broker數據恢復方式。
使用限制
本文檔僅適用于EMR-5.8.0及后續版本,EMR-3.42.0及后續版本。
注意事項
磁盤故障運維應注意以下信息:
選擇修復策略:綜合各種因素考慮選擇磁盤維修的策略。
注意限流:在磁盤運維過程當中,如果涉及到數據復制遷移,需要注意限制運維流量,避免對正常業務流量造成影響。
限流閾值:應根據磁盤IO能力和正常業務流量來評估遷移時的限流閾值。
分區副本遷移:物理盤維修完畢上線之后,應將Topic分區數據遷移回原磁盤,leader負載遷移回原Broker節點。
數據遷移時長:在磁盤運維過程當中,如果涉及到數據復制遷移,需要評估數據遷移時長對業務的影響。
節點間分區遷移方式
方案描述
當發現磁盤故障隱患或者由于其他原因需要替換磁盤時,可以將故障磁盤上的分區副本數據遷移到其他磁盤。故障磁盤維修更換期間,分區副本個數不會變化、集群處于正常容錯狀態。故障盤維修更換完畢之后將分區數據遷回到原磁盤。此方案的優點在于磁盤運維周期,集群處于正常容錯狀態,各Broker負載較為均衡;缺點是當故障盤上的分區沒有其他ISR副本時,有可能丟失數據。
適用場景
故障盤所在Broker磁盤容量不足場景,或者故障盤所在Broker負載過高的場景。
注意事項
注意限流:分區數據遷移將產生較大的數據遷移流量,需要對流量進行限制以避免對正常業務產生影響。
遷移時長:如果需要遷移的數據較多,相應的遷移時長也會加大。
限流閾值:應根據磁盤IO能力、正常業務流量來評估遷移時的限流閾值。
磁盤空間:需要確保集群有足夠的磁盤容量來存放遷移的數據。
備份原始assignment文件。分區遷移時,需要注意保存原來的assignment文件,便于磁盤修復后,將分區遷移回原來的磁盤目錄。
由于disk1存儲了Kafka服務的日志文件,所有涉及disk1的壞盤修復操作必須遵循以下步驟:
下線disk1前:務必先將日志目錄遷移至其他存儲介質。
# 創建新的日志目錄,確保目錄權限與/mnt/disk1/log/保持一致。 sudo mkdir /mnt/disk2/log # 檢查軟鏈接是否正確指向disk2。 sudo ln -sf /mnt/disk2/log /var/log/taihao-apps # 遷移原日志文件至新目錄。 sudo mv /mnt/disk1/log/* /mnt/disk2/log/上線disk1后:確保將日志文件目錄恢復到原位。
# 創建disk1的日志目錄。 sudo mkdir /mnt/disk1/log # 檢查軟鏈接是否正確指向disk1。 sudo ln -sf /mnt/disk1/log /var/log/taihao-apps # 移動日志文件回disk1。 sudo mv /mnt/disk2/log/* /mnt/disk1/log/
操作步驟
本示例以Broker 0的壞盤/mnt/disk7為例,介紹如何采用節點間分區遷移的方式進行故障盤運維。
分區遷移。
以SSH方式登錄到源Kafka集群的Master節點,詳情請參見登錄集群。
可選:待維修磁盤隔離。如果磁盤已經發生故障,您需要執行以下命令快速隔離該磁盤。
chmod 000 /mnt/disk7執行以下命令,將待維修磁盤上的分區遷移到其他Broker節點。
kafka-reassign-partitions.sh --zookeeper master-1-1:2181/emr-kafka --reassignment-json-file reassign.json --throttle 30000000 --execute說明reassign.json包含了待遷移磁盤上需要遷移的分區副本。
執行完reassign命令后,會輸出原始的assignment,可以將該輸出保存起來,便于后續恢復。
執行以下命令,確認故障盤上數據已經遷移完畢。
ls -lrt /mnt/disk7/kafka/log通過回顯信息,查看日志目錄下是否有日志文件,沒有日志文件表示數據已經遷移完畢。
可選:如果前面步驟中沒有隔離待維修磁盤,則需要執行以下命令隔離待維修磁盤。
chmod 000 /mnt/disk7
卸載故障磁盤目錄。
重要編輯fstab條目時,直接刪除而不是注釋掉故障盤條目。
執行以下命令,編輯/etc/fstab。
vim /etc/fstab刪除disk7的信息。
執行以下命令,驗證目錄句柄是否釋放。
lsof +D /mnt/disk7如果發現句柄長時間(半個小時以上)無法釋放,則可以通過控制臺重啟對應Broker服務。
執行以下命令,卸載故障磁盤目錄。
umount /mnt/disk7
修改log.dirs配置并重啟服務。
在EMR控制臺,修改恢復后的Broker節點級別的log.dirs配置項,移除故障磁盤對應的分區目錄。
本示例需要移除的目錄為/mnt/disk7/kafka/log。
在EMR控制臺重啟Broker服務,詳情請參見操作步驟。
說明如果ECS的修復磁盤事件運維流程中需要重啟ECS實例,則可以將重啟Broker服務與重啟ECS實例結合起來完成。
通過修復磁盤事件,在ECS控制臺進行后續磁盤修復工作。
此過程可能需要的時間周期為幾天。
磁盤上線,詳情請參見磁盤上線。
您需要將修復后的磁盤重新mount到原來的目錄。本示例為/mnt/disk7目錄。
在修復后的磁盤目錄上創建kafka日志目錄。
//創建原始日志目錄。本例子為/mnt/disk7/kafka/log。 sudo mkdir -p /mnt/disk7/kafka/log sudo chown -R kafka:hadoop /mnt/disk7/kafka/log修改log.dirs配置并重啟服務。
在EMR控制臺,修改恢復后的Broker節點級別的log.dirs配置項,添加修復后磁盤對應的分區目錄。
本示例需要增加的目錄為/mnt/disk7/kafka/log。
在EMR控制臺重啟Broker服務,詳情請參見操作步驟。
遷回分區副本。
使用步驟1保存的原始assignment文件,將原來故障盤上的分區遷回到修復后的磁盤。
原Broker數據恢復方式
方案描述
當磁盤故障時,如果磁盤IO性能已經明顯下降,則需要快速隔離故障磁盤避免因單點故障影響集群性能。
磁盤隔離之后,對應kafka日志目錄處于offline狀態。此時,如果分區存在ISR副本或者允許分區數據丟失,可以直接將故障磁盤從log.dirs中刪除下線,然后重啟Broker。重啟Broker后,如果其他節點存在新的leader副本,原有故障盤分區副本將在其所在Broker進行恢復。磁盤修復上線后,您可以通過reassign工具將原有數據遷移回修復后的磁盤。
本方案的缺點在于:當故障盤上的分區沒有ISR副本時,有可能丟失數據。
適用場景
故障磁盤IO性能已經明顯下降,需要快速進行故障盤隔離的場景。
故障磁盤上的日志目錄已經offline的場景。
故障盤上的分區在其他節點已經沒有ISR副本時,允許丟失分區數據。
注意事項
流量限制:由于數據在同一個節點恢復,會產生副本恢復流量,應注意限流。
磁盤空間:需要注意本Broker的其他節點是否有足夠的空間容納異常磁盤的數據。
數據遷移:磁盤修復重新上線后,通常需要將數據從其他磁盤挪回到修復后的磁盤以保證磁盤負載均衡。
操作步驟
以下示例以Broker 0的/mnt/disk7壞盤為例,介紹如何采用原地數據恢復方式進行故障盤運維。
故障盤隔離。
以SSH方式登錄到源Kafka集群的Master節點,詳情請參見登錄集群。
執行以下命令,隔離故障盤。
chmod 000 /mnt/disk7
可選:備份故障盤上Kafka日志分區目錄名稱。
通過備份故障盤目錄名稱,當磁盤修復上線后,您可以將原有分區遷移回修復后的磁盤中。
卸載故障磁盤目錄。
重要編輯fstab條目時,直接刪除而不是注釋掉故障盤條目。
執行以下命令,編輯/etc/fstab。
vim /etc/fstab刪除disk7的信息。
執行以下命令,驗證目錄句柄是否釋放。
lsof +D /mnt/disk7如果發現句柄長時間(半個小時以上)無法釋放,則可以通過控制臺重啟對應Broker服務。
執行以下命令,卸載故障磁盤目錄。
umount /mnt/disk7
修改故障Broker節點的log.dirs配置并限制恢復流量。
在EMR控制臺,修改恢復后的Broker節點級別的log.dirs配置項,移除故障磁盤對應的分區目錄。
本示例需要移除的目錄為/mnt/disk7/kafka/log。
可選:通過設置reassign限流參數的方式來限制Broker上分區數據同步恢復時候的流量帶寬,詳情請參見限制Kafka服務端運維流量。
在EMR控制臺重啟Broker服務,詳情請參見操作步驟。
說明如果ECS的修復磁盤事件運維流程中需要重啟ECS實例,則可以將重啟Broker服務與重啟ECS實例結合起來完成。
在重啟的過程中,Kafka將會恢復本Broker故障盤上缺失的副本分區到其他磁盤,待Kafka恢復好分區數據后,如果前一步驟設置了限流參數,則需要將限流參數去除掉。
通過修復磁盤事件,在ECS控制臺進行后續磁盤修復工作。
此過程可能需要的時間周期為幾天。
磁盤上線,詳情請參見磁盤上線。
您需要將修復后的磁盤重新mount到原來的目錄。本示例為/mnt/disk7目錄。
創建Kafka日志目錄并重啟服務。
在修復后的磁盤目錄上創建Kafka日志目錄。
//創建原始日志目錄。本例子為/mnt/disk7/kafka/log。 sudo mkdir -p /mnt/disk7/kafka/log sudo chown -R kafka:hadoop /mnt/disk7/kafka/log在EMR控制臺,修改恢復后的Broker節點級別的log.dirs配置項,添加修復后磁盤對應的分區目錄。
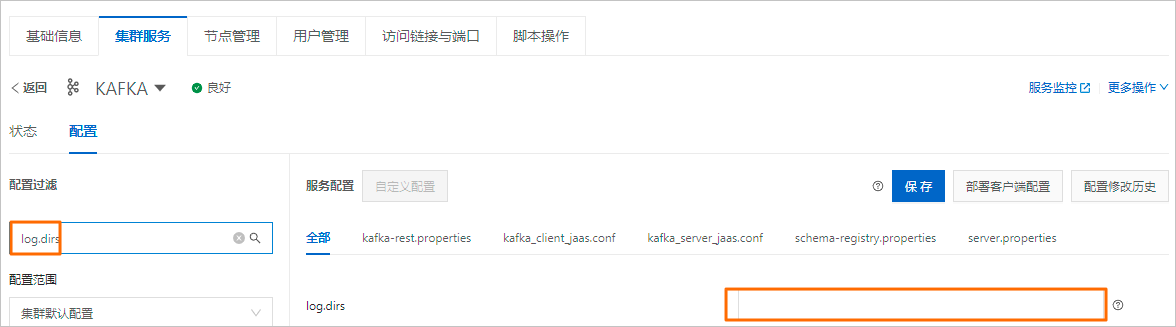
本示例需要增加的目錄為/mnt/disk7/kafka/log。
在EMR控制臺重啟Broker服務,詳情請參見操作步驟。
遷回分區副本。
使用步驟2保存的分區副本目錄,通過reassign工具遷移分區副本broker內部目錄的方式遷回到修復后的磁盤。
節點內分區遷移方式
方案描述
當發現磁盤故障時,如果磁盤IO性能已經明顯下降,需要快速隔離故障磁盤避免因單點故障影響集群性能。
磁盤隔離之后,對應的kafka日志目錄處于offline狀態。此時,如果故障盤上存在無法切換到其他Broker的副本且業務數據不能丟失,則可以將分區副本數據遷移到本Broker的其他磁盤后,再進行后續的磁盤運維流程。本方案用于處理如果使用其他運維方案會丟失數據,但業務不允許數據丟失的場景。
適用場景
故障盤上的分區在其他節點已經沒有ISR副本,并且業務不允許數據丟失的場景。
注意事項
需要評估OS系統層面的mv操作產生的IO熱點的影響。
操作步驟
本示例以Broker 0的壞盤/mnt/disk7為例,介紹如何采用節點內分區遷移的方式進行故障盤運維。
故障盤隔離。
以SSH方式登錄到源Kafka集群的Master節點,詳情請參見登錄集群。
執行以下命令,隔離故障盤。
chmod 000 /mnt/disk7
可選:備份故障盤上Kafka日志分區目錄名稱。
通過備份故障盤目錄名稱,當磁盤修復上線后,您可以將原有分區遷移回修復后的磁盤中。
遷移節點內分區。
將/mnt/disk7/kafka/log下的所有數據以分區為單位,按照分區占用磁盤容量的大小,均勻的遷移到當前節點的其他目錄,詳情請參見節點內分區遷移方式恢復。
卸載故障磁盤目錄。
重要編輯fstab條目時,直接刪除而不是注釋掉故障盤條目。
執行以下命令,編輯/etc/fstab。
vim /etc/fstab刪除disk7的信息。
執行以下命令,驗證目錄句柄是否釋放。
lsof +D /mnt/disk7如果發現句柄長時間(半個小時以上)無法釋放,則可以通過控制臺重啟對應Broker服務。
執行以下命令,卸載故障磁盤目錄。
umount /mnt/disk7
在EMR控制臺重啟Broker服務,詳情請參見操作步驟。
說明如果ECS的修復磁盤事件運維流程中需要重啟ECS實例,則可以將重啟Broker服務與重啟ECS實例結合起來完成。
通過修復磁盤事件,在ECS控制臺進行后續磁盤修復工作。
此過程可能需要的時間周期為幾天。
磁盤上線,詳情請參見磁盤上線。
您需要將修復后的磁盤重新mount到原來的目錄。本示例為/mnt/disk7目錄。
創建Kafka日志目錄并重啟服務。
在修復后的磁盤目錄上創建kafka日志目錄。
//創建原始日志目錄。本例子為/mnt/disk7/kafka/log。 sudo mkdir -p /mnt/disk7/kafka/log sudo chown -R kafka:hadoop /mnt/disk7/kafka/log在EMR控制臺,修改恢復后的Broker節點級別的log.dirs配置項,添加修復后磁盤對應的分區目錄。
在EMR控制臺重啟Broker服務,詳情請參見操作步驟。
可選:遷回分區副本。
使用步驟2保存的分區副本目錄,通過reassign工具遷移分區副本broker內部目錄的方式遷回到修復后的磁盤。