AIACC-ACSpeed性能數(shù)據(jù)
相比較通過原生DDP訓(xùn)練模型后的性能數(shù)據(jù),使用AIACC-ACSpeed訓(xùn)練多個(gè)模型時(shí),性能具有明顯提升。本文為您展示了AIACC-ACSpeed的部分典型模型的訓(xùn)練性能數(shù)據(jù)。
測試版本
ACSpeed版本:1.0.2
Cuda版本:11.1
torch版本:1.8.1+cu111
實(shí)例類型:某8卡GPU實(shí)例
訓(xùn)練性能效果
本文以AIACC-ACSpeed(簡稱ACSpeed)v1.0.2版本在阿里云某8卡機(jī)器上的多機(jī)性能數(shù)據(jù)為例,通過測試不同場景下的模型,展示ACSpeed的不同性能提升效果。
ACSpeed在多個(gè)模型下均有相應(yīng)的性能提升效果,整體有5%~200%的性能增益。通過測試ACSpeed訓(xùn)練多個(gè)模型后的性能效果,可以看到原生DDP的擴(kuò)展性(即多機(jī)線性度)不佳時(shí),ACSpeed的提升效果越明顯,且ACSpeed不會(huì)出現(xiàn)性能回退的現(xiàn)象,性能效果展示如下圖所示。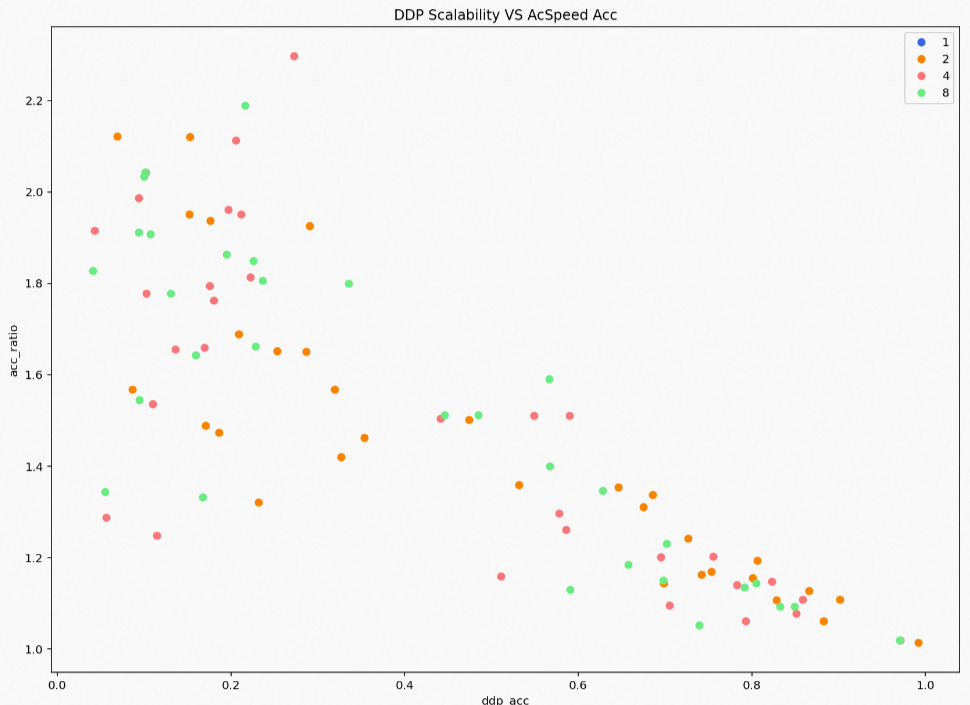
涉及的主要概念如下所示:
概念 | 說明 |
ddp_acc(橫坐標(biāo)) | 表示PyTorch原生分布式DDP的多機(jī)多卡的擴(kuò)展性。 多機(jī)多卡擴(kuò)展性:即多機(jī)線性度=多機(jī)性能/單機(jī)性能/集群數(shù),數(shù)值越低擴(kuò)展性越差。 |
acc_ratio(縱坐標(biāo)) | 表示ACSpeed相對于原生DDP的性能指標(biāo)的提升比值。例如,1.25表示ACSpeed的性能是原生DDP性能的1.25倍,即性能提升25%。 |
DDP Scalability VS AcSpeed Acc(圓點(diǎn)) | 表示具體的某個(gè)模型配置的DDP的原生性能和ACSpeed的加速效果,不同顏色表示不同集群規(guī)模。
|
 :表示集群數(shù)量為1。
:表示集群數(shù)量為1。 :表示集群數(shù)量為2。
:表示集群數(shù)量為2。 :表示集群數(shù)量為4。
:表示集群數(shù)量為4。 :表示集群數(shù)量為8。
:表示集群數(shù)量為8。典型模型性能數(shù)據(jù)
本節(jié)僅展示了部分已測試的典型模型的性能數(shù)據(jù)信息。不同場景下的模型,通信計(jì)算的占比不同也會(huì)導(dǎo)致端到端的性能提升有所差異。具體測試模型的性能數(shù)據(jù)如下:
如果您想了解更多機(jī)型性能測試效果,歡迎使用釘釘搜索群號(hào)33617640加入阿里云神龍AI加速AIACC外部支持群(釘釘通訊客戶端下載地址)。
場景1:訓(xùn)練alexnet模型
Model:alexnet
Domain:COMPUTER_VISION
Subdomain:CLASSIFICATION
Batch_size:128
Precision:amp
該場景下的alexnet模型訓(xùn)練后的性能數(shù)據(jù)如下所示: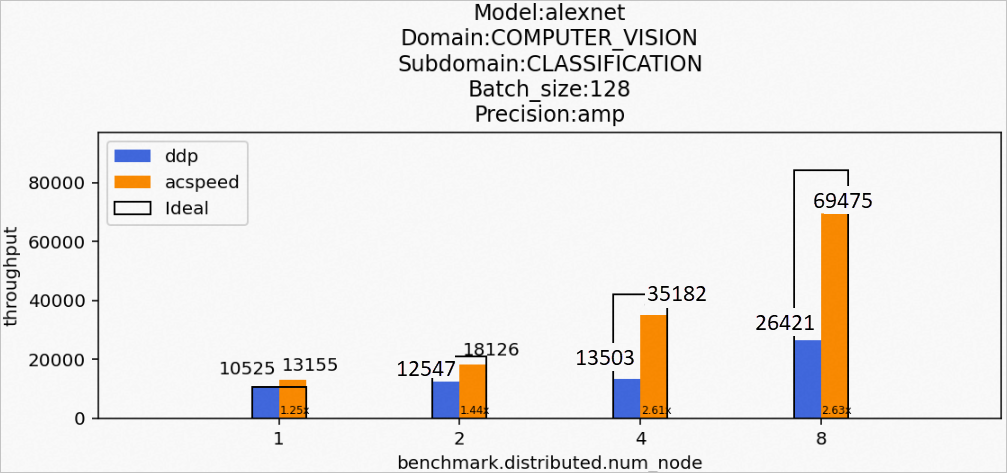
場景2:訓(xùn)練resnet18模型
Model:resnet18
Domain:COMPUTER_VISION
Subdomain:CLASSIFICATION
Batch_size:16
Precision:amp
該場景下的resnet18模型訓(xùn)練后的性能數(shù)據(jù)如下所示: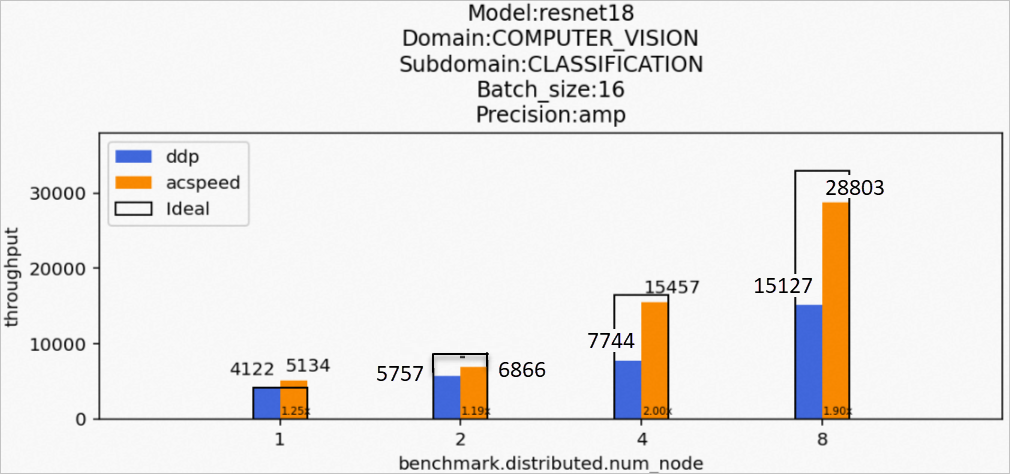
場景3:訓(xùn)練resnet50模型
Model:resnet50
Domain:COMPUTER_VISION
Subdomain:CLASSIFICATION
Batch_size:32
Precision:amp
該場景下的resnet50模型訓(xùn)練后的性能數(shù)據(jù)如下所示: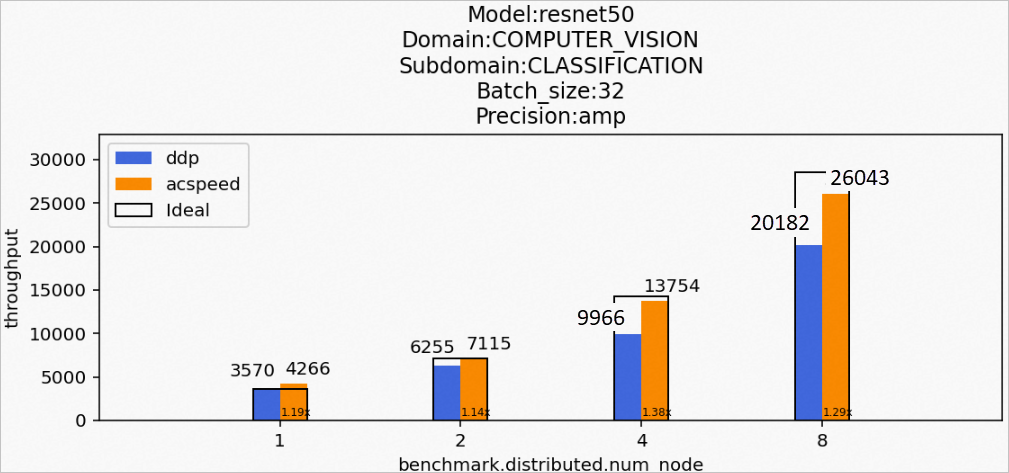
場景4:訓(xùn)練vgg16模型
Model:vgg16
Domain:COMPUTER_VISION
Subdomain:CLASSIFICATION
Batch_size:64
Precision:amp
該場景下的vgg16模型訓(xùn)練后的性能數(shù)據(jù)如下所示: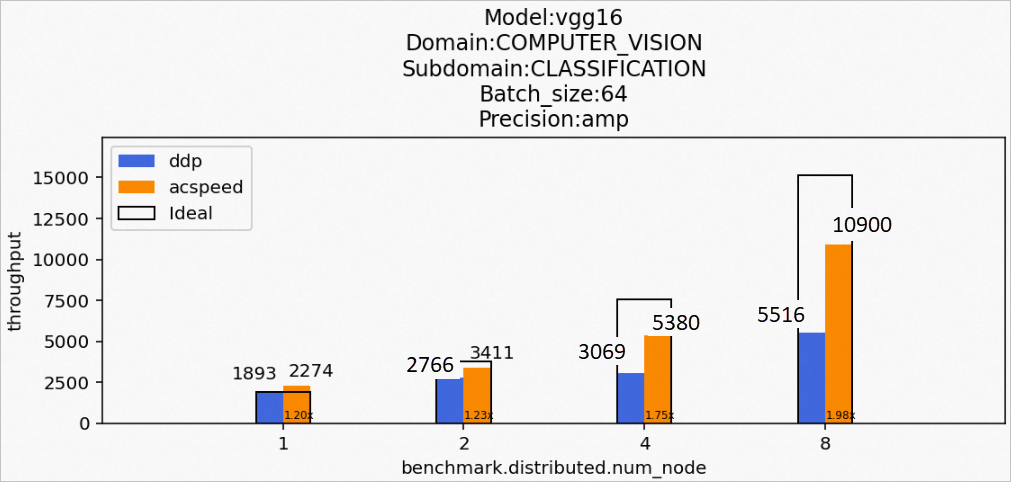
場景5:訓(xùn)練timm_vovnet模型
Model:timm_vovnet
Domain:COMPUTER_VISION
Subdomain:CLASSIFICATION
Batch_size:32
Precision:amp
該場景下的timm_vovnet模型訓(xùn)練后的性能數(shù)據(jù)如下所示: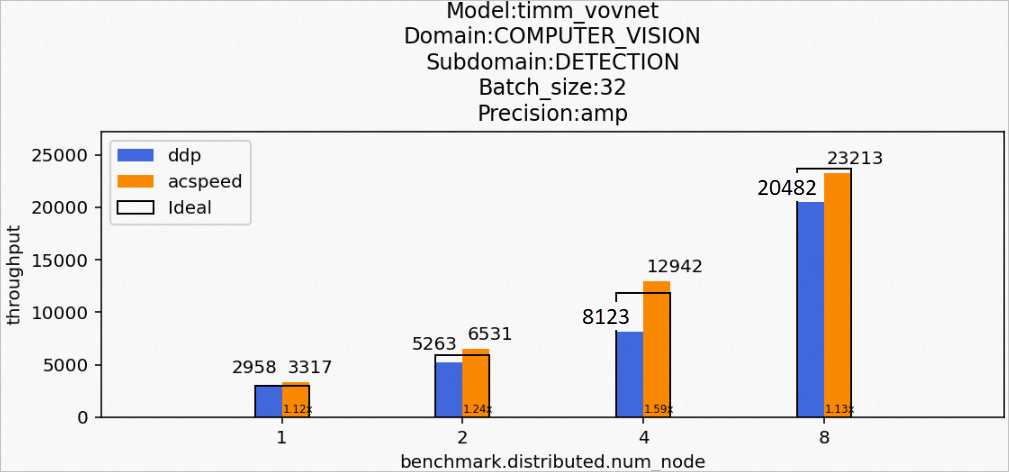
場景6:訓(xùn)練timm_vision_transformer模型
Model:timm_vision_transformer
Domain:COMPUTER_VISION
Subdomain:CLASSIFICATION
Batch_size:8
Precision:amp
該場景下的timm_vision_transformer模型訓(xùn)練后的性能數(shù)據(jù)如下所示: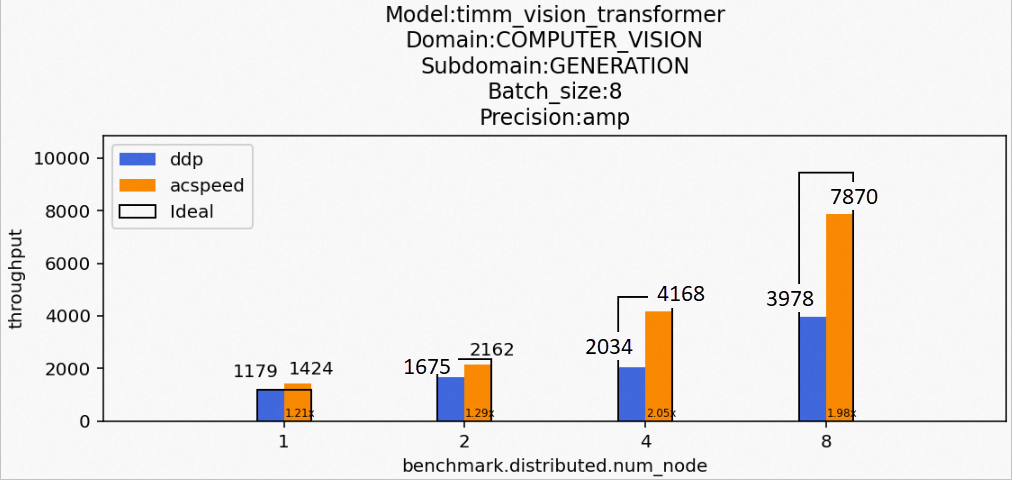
場景7:訓(xùn)練pytorch_unet模型
Model:pytorch_unet
Domain:COMPUTER_VISION
Subdomain:CLASSIFICATION
Batch_size:1
Precision:amp
該場景下的pytorch_unet模型訓(xùn)練后的性能數(shù)據(jù)如下所示: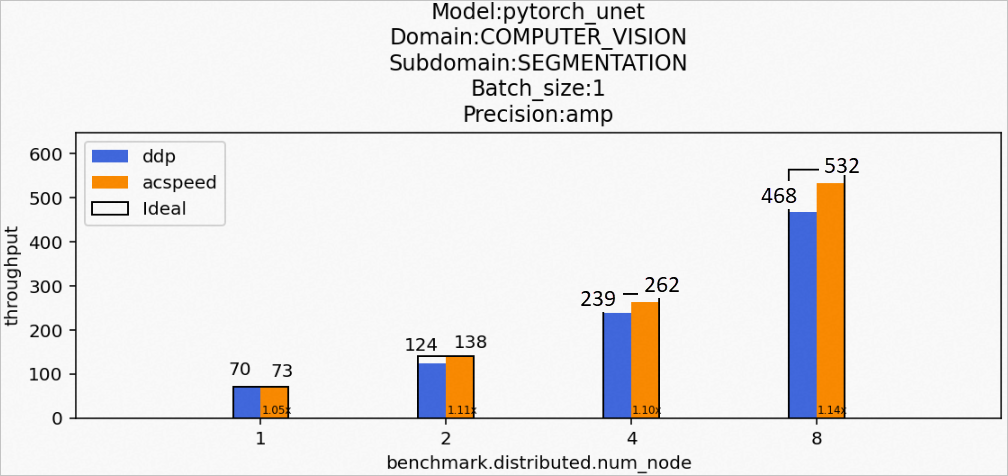
場景8:訓(xùn)練hf_Bart模型
Model:hf_Bart
Domain:NLP
Subdomain:LANGUAGE_MODELING
Batch_size:4
Precision:amp
該場景下的hf_Bart模型訓(xùn)練后的性能數(shù)據(jù)如下所示: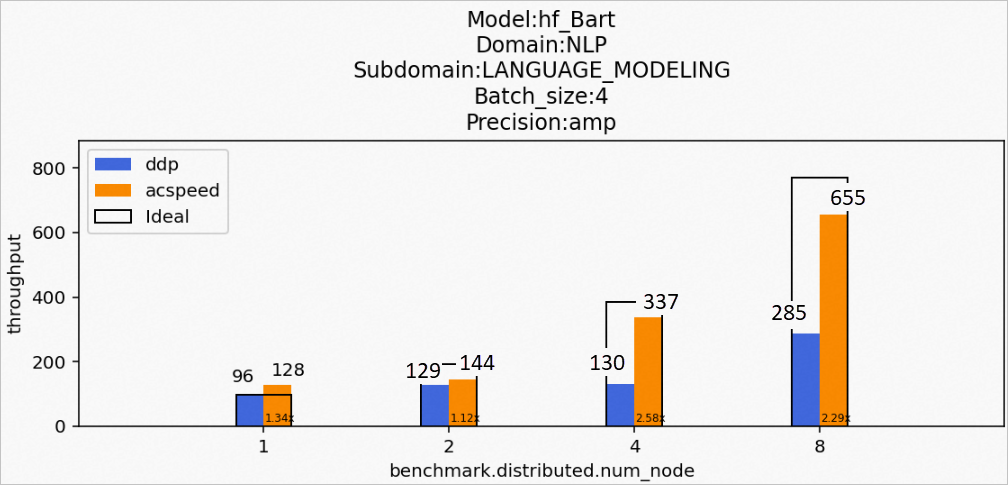
場景9:訓(xùn)練hf_Bert模型
Model:hf_Bert
Domain:NLP
Subdomain:LANGUAGE_MODELING
Batch_size:4
Precision:amp
該場景下的hf_Bert模型訓(xùn)練后的性能數(shù)據(jù)如下所示: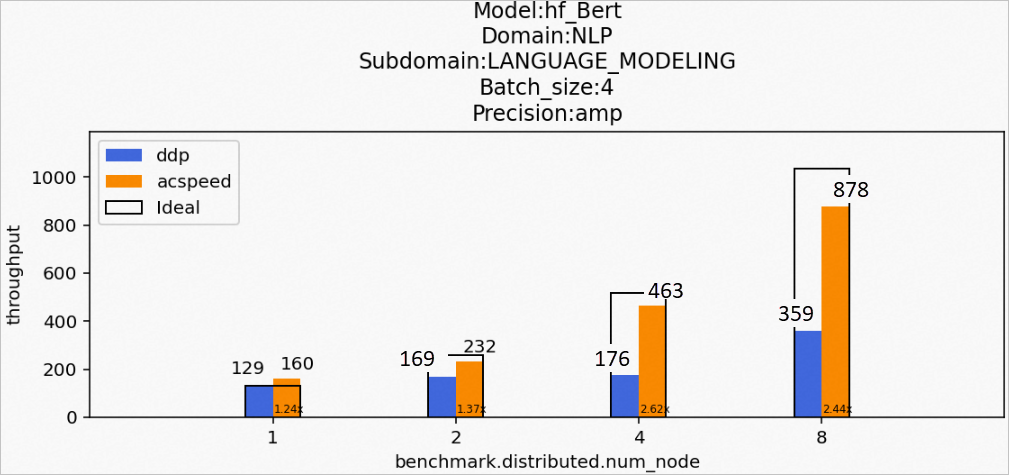
場景10:訓(xùn)練speech_transformer模型
Model:speech_transformer
Domain:SPEECH
Subdomain:RECOGNITION
Batch_size:32
Precision:amp
該場景下的speech_transformer模型訓(xùn)練后的性能數(shù)據(jù)如下所示: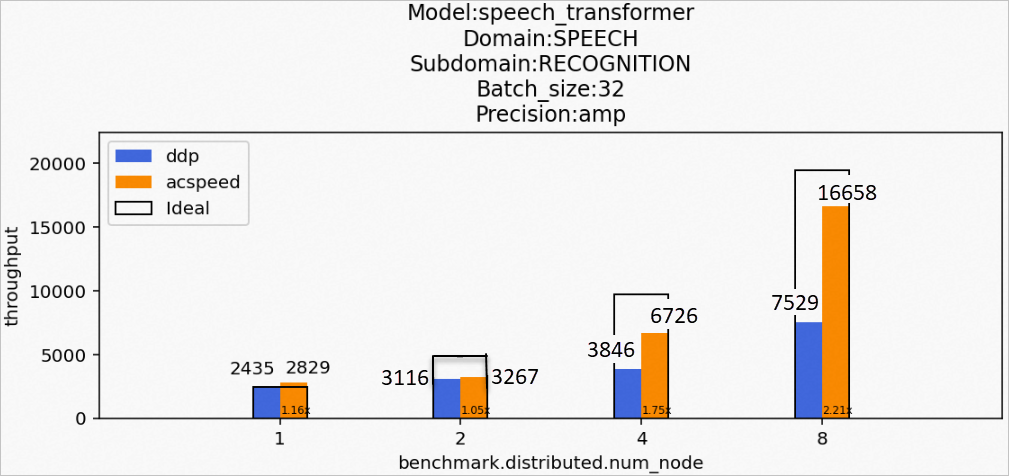
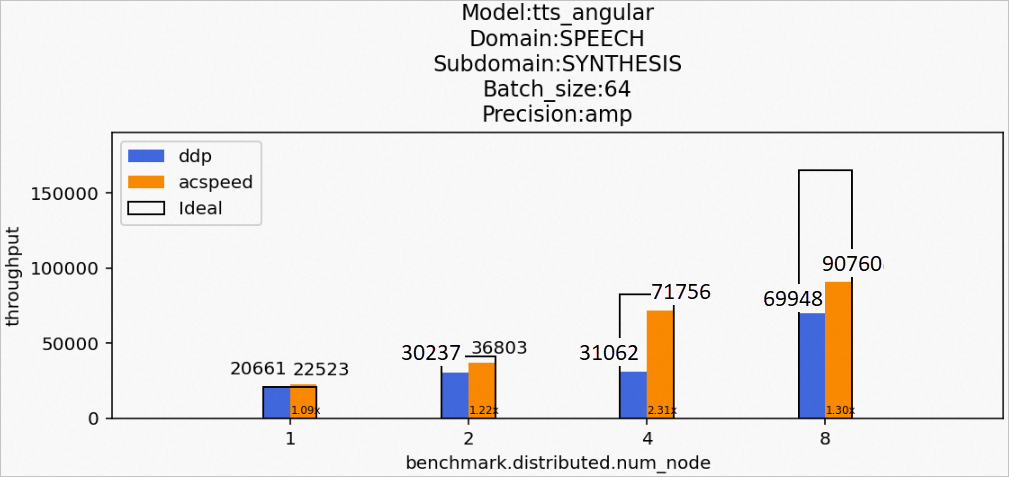
場景11:訓(xùn)練tts_angular模型
Model:tts_angular
Domain:SPEECH
Subdomain:SYNTHESIS
Batch_size:64
Precision:amp
該場景下的tts_angular模型訓(xùn)練后的性能數(shù)據(jù)如下所示: