阿里云提供了ECS系統事件用于記錄和通知云資源信息,例如ECS實例的啟停、是否到期、任務執行情況等。在大規模集群、實時資源調度等場景,如果您需要主動監控和響應阿里云提供的ECS系統事件,來實現故障處理、動態調度等自動化運維,可通過云助手插件ecs-tool-event實現。
方案原理
監控和響應ECS系統事件可通過控制臺或對接OpenAPI兩種方式。然而,這兩種方式都存在一定的局限:
通過控制臺監控或響應系統事件:要手動干預,且對于多實例場景容易出現事件遺漏,無法做到自動化的響應。
通過對接ECS OpenAPI監控或響應系統事件:需要自行開發程序,有一定的開發成本和技術要求。
為了解決上述問題,阿里云提供了云助手插件ecs-tool-event,該插件會每分鐘定時請求metaserver獲取ECS系統事件,并將ECS系統事件轉化為日志格式存儲在操作系統內部。用戶無需進行額外的程序開發,直接在操作系統內部采集系統事件日志來實現監控和響應ECS系統事件。例如,具備K8s自動化運維能力的用戶,可以通過采集host_event.log的流式日志來適配自身運維系統。
方案實踐
請確保您的實例已安裝云助手Agent。如何安裝云助手Agent?
啟動、停止云助手插件或查看云助手插件狀態需要使用root權限。
登錄ECS實例,啟用云助手插件
ecs-tool-event。啟用后,該插件會每分鐘定時請求metaserver獲取ECS系統事件,并將ECS系統事件轉化為日志格式存儲在操作系統內部。
sudo acs-plugin-manager --exec --plugin=ecs-tool-event --params --start說明啟動后,可通過
ls /var/log查看自動生成的host_event.log文件。日志保存地址:/var/log/host_event.log
日志格式:
%Y-%m-%d %H:%M:%S - WARNING - Ecs event type is: ${事件類型},event status is: ${事件狀態}, action ISO 8601 time is ${實際執行ISO 8601時間}
示例:
2024-01-08 17:02:01 - WARNING - Ecs event type is: InstanceFailure.Reboot,event status is: Executed,action ISO 8601 time is 2023-12-27T11:49:28Z
查詢插件狀態。
sudo acs-plugin-manager --status結合自身業務場景,采集host_event.log的流式日志來適配自身運維系統。
(可選)如果您不再需要主動響應ECS系統事件,可停止云助手插件
ecs-tool-event。sudo acs-plugin-manager --remove --plugin ecs-tool-event
應用示例:Kubernetes集群場景自動化響應ECS系統事件
場景介紹
當ECS被用作Kubernetes集群的Node節點時,若單個節點出現異常(例如重啟、內存耗盡、操作系統錯誤等),可能會影響線上業務的穩定性,主動監測和響應節點異常事件至關重要。您可以通過云助手插件ecs-tool-event,將ECS系統事件轉化為操作系統日志,并結合K8s社區開源組件NPD(Node Problem Detector)、Draino和Autoscaler,實現免程序開發、便捷高效地監測和響應ECS系統事件,從而提升集群的穩定性和可靠性。
NPD:Kubernetes社區的開源組件,可用于監控節點的健康狀態、檢測節點的故障,比如硬件故障、網絡問題等。更多信息,請參見NPD官方文檔。
Draino:Kubernetes中的一個控制器,可監視集群中的節點,并將異常節點上的Pod遷移到其他節點。更多信息,請參見Draino官方文檔。
Autoscaler:Kubernetes社區的開源組件,可動態調整Kubernetes集群大小,監控集群中的Pods,以確保所有Pods都有足夠的資源運行,同時保證沒有閑置的無效節點。更多信息,請參見Autoscaler官方文檔。
方案架構
方案的實現原理和技術架構如下所示:
云助手插件ecs-tool-event每分鐘定時請求metaserver獲取ECS系統事件,轉化為系統日志存儲到操作系統內部(存儲路徑為
/var/log/host_event.log)。集群組件NPD采集到系統事件日志后,將問題上報給APIServer。
集群控制器Draino從APIServer接收K8s事件(ECS系統事件),將異常節點上的Pod遷移到其他正常節點。
完成容器驅逐后,您可以結合業務場景使用已有的集群下線方案完成異常節點下線,或者可以選擇使用Kubernetes社區的開源組件Autoscaler自動釋放異常節點并創建新實例加入到集群中。

方案實踐
步驟一:為節點啟動ecs-tool-event插件
登錄節點內部(即ECS實例),啟動ecs-tool-event插件。
實際應用場景中,需要給集群的每個節點都啟動該插件。您可以通過云助手批量為多個實例執行如下啟動命令。具體操作,請參見創建并執行命令。
sudo acs-plugin-manager --exec --plugin=ecs-tool-event --params --start啟動后,ecs-tool-event插件會自動把ECS系統事件以日志形式輸出并保存到操作系統內部。
步驟二:為集群配置NPD和Draino
登錄集群中的任一節點。
為集群配置NPD組件(該配置作用于整個集群)。
配置NPD文件,需要用到如下3個文件。
說明詳細配置說明,可參見官方文檔。
node-problem-detector-config.yaml:定義NPD需要監控的指標,例如系統日志。node-problem-detector.yaml:定義了NPD的在集群中的運行方式。rbac.yaml:定義NPD在Kubernetes集群中所需的權限。實例未配置NPD
在ECS實例添加上述3個YAML文件。
apiVersion: v1 data: kernel-monitor.json: | { "plugin": "kmsg", "logPath": "/dev/kmsg", "lookback": "5m", "bufferSize": 10, "source": "kernel-monitor", "conditions": [ { "type": "KernelDeadlock", "reason": "KernelHasNoDeadlock", "message": "kernel has no deadlock" }, { "type": "ReadonlyFilesystem", "reason": "FilesystemIsNotReadOnly", "message": "Filesystem is not read-only" } ], "rules": [ { "type": "temporary", "reason": "OOMKilling", "pattern": "Kill process \\d+ (.+) score \\d+ or sacrifice child\\nKilled process \\d+ (.+) total-vm:\\d+kB, anon-rss:\\d+kB, file-rss:\\d+kB.*" }, { "type": "temporary", "reason": "TaskHung", "pattern": "task \\S+:\\w+ blocked for more than \\w+ seconds\\." }, { "type": "temporary", "reason": "UnregisterNetDevice", "pattern": "unregister_netdevice: waiting for \\w+ to become free. Usage count = \\d+" }, { "type": "temporary", "reason": "KernelOops", "pattern": "BUG: unable to handle kernel NULL pointer dereference at .*" }, { "type": "temporary", "reason": "KernelOops", "pattern": "divide error: 0000 \\[#\\d+\\] SMP" }, { "type": "temporary", "reason": "MemoryReadError", "pattern": "CE memory read error .*" }, { "type": "permanent", "condition": "KernelDeadlock", "reason": "DockerHung", "pattern": "task docker:\\w+ blocked for more than \\w+ seconds\\." }, { "type": "permanent", "condition": "ReadonlyFilesystem", "reason": "FilesystemIsReadOnly", "pattern": "Remounting filesystem read-only" } ] } host_event.json: | { "plugin": "filelog", "pluginConfig": { "timestamp": "^.{19}", "message": "Ecs event type is: .*", "timestampFormat": "2006-01-02 15:04:05" }, "logPath": "/var/log/host_event.log", "lookback": "5m", "bufferSize": 10, "source": "host-event", "conditions": [ { "type": "HostEventRebootAfter48", "reason": "HostEventWillRebootAfter48", "message": "The Host Is Running In Good Condition" } ], "rules": [ { "type": "temporary", "reason": "HostEventRebootAfter48temporary", "pattern": "Ecs event type is: SystemMaintenance.Reboot,event status is: Scheduled.*|Ecs event type is: SystemMaintenance.Reboot,event status is: Inquiring.*" }, { "type": "permanent", "condition": "HostEventRebootAfter48", "reason": "HostEventRebootAfter48Permanent", "pattern": "Ecs event type is: SystemMaintenance.Reboot,event status is: Scheduled.*|Ecs event type is: SystemMaintenance.Reboot,event status is: Inquiring.*" } ] } docker-monitor.json: | { "plugin": "journald", "pluginConfig": { "source": "dockerd" }, "logPath": "/var/log/journal", "lookback": "5m", "bufferSize": 10, "source": "docker-monitor", "conditions": [], "rules": [ { "type": "temporary", "reason": "CorruptDockerImage", "pattern": "Error trying v2 registry: failed to register layer: rename /var/lib/docker/image/(.+) /var/lib/docker/image/(.+): directory not empty.*" } ] } kind: ConfigMap metadata: name: node-problem-detector-config namespace: kube-systemapiVersion: apps/v1 kind: DaemonSet metadata: name: node-problem-detector namespace: kube-system labels: app: node-problem-detector spec: selector: matchLabels: app: node-problem-detector template: metadata: labels: app: node-problem-detector spec: affinity: nodeAffinity: requiredDuringSchedulingIgnoredDuringExecution: nodeSelectorTerms: - matchExpressions: - key: kubernetes.io/os operator: In values: - linux containers: - name: node-problem-detector command: - /node-problem-detector - --logtostderr - --config.system-log-monitor=/config/kernel-monitor.json,/config/docker-monitor.json,/config/host_event.json image: cncamp/node-problem-detector:v0.8.10 resources: limits: cpu: 10m memory: 80Mi requests: cpu: 10m memory: 80Mi imagePullPolicy: Always securityContext: privileged: true env: - name: NODE_NAME valueFrom: fieldRef: fieldPath: spec.nodeName volumeMounts: - name: log mountPath: /var/log readOnly: true - name: kmsg mountPath: /dev/kmsg readOnly: true # Make sure node problem detector is in the same timezone # with the host. - name: localtime mountPath: /etc/localtime readOnly: true - name: config mountPath: /config readOnly: true serviceAccountName: node-problem-detector volumes: - name: log # Config `log` to your system log directory hostPath: path: /var/log/ - name: kmsg hostPath: path: /dev/kmsg - name: localtime hostPath: path: /etc/localtime - name: config configMap: name: node-problem-detector-config items: - key: kernel-monitor.json path: kernel-monitor.json - key: docker-monitor.json path: docker-monitor.json - key: host_event.json path: host_event.json tolerations: - effect: NoSchedule operator: Exists - effect: NoExecute operator: ExistsapiVersion: v1 kind: ServiceAccount metadata: name: node-problem-detector namespace: kube-system --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRoleBinding metadata: name: npd-binding roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: system:node-problem-detector subjects: - kind: ServiceAccount name: node-problem-detector namespace: kube-system實例已配置NPD
在
node-problem-detector-config.yaml文件中,添加host_event.json日志監控。如下所示:... host_event.json: | { "plugin": "filelog", #指定使用的日志采集插件,固定為filelog "pluginConfig": { "timestamp": "^.{19}", "message": "Ecs event type is: .*", "timestampFormat": "2006-01-02 15:04:05" }, "logPath": "/var/log/host_event.log", #系統事件日志路徑,固定為/var/log/host_event.log "lookback": "5m", "bufferSize": 10, "source": "host-event", "conditions": [ { "type": "HostEventRebootAfter48", #自定義事件名稱,Draino配置中會用到 "reason": "HostEventWillRebootAfter48", "message": "The Host Is Running In Good Condition" } ], "rules": [ { "type": "temporary", "reason": "HostEventRebootAfter48temporary", "pattern": "Ecs event type is: SystemMaintenance.Reboot,event status is: Scheduled.*|Ecs event type is: SystemMaintenance.Reboot,event status is: Inquiring.*" }, { "type": "permanent", "condition": "HostEventRebootAfter48", "reason": "HostEventRebootAfter48Permanent", "pattern": "Ecs event type is: SystemMaintenance.Reboot,event status is: Scheduled.*|Ecs event type is: SystemMaintenance.Reboot,event status is: Inquiring.*" } ] } ...在
node-problem-detector.yaml文件中在
- --config.system-log-monitor行中添加/config/host_event.json,告訴NPD監控系統事件日志。如下所示:containers: - name: node-problem-detector command: ... - --config.system-log-monitor=/config/kernel-monitor.json,/config/docker-monitor.json,/config/host_event.json和
- name: config的items:行下,按照如下注釋添加相關行。... - name: config configMap: name: node-problem-detector-config items: - key: kernel-monitor.json path: kernel-monitor.json - key: docker-monitor.json path: docker-monitor.json - key: host_event.json #待添加的行 path: host_event.json #待添加的行 ...
執行以下命令,使文件生效。
sudo kubectl create -f rbac.yaml sudo kubectl create -f node-problem-detector-config.yaml sudo kubectl create -f node-problem-detector.yaml執行如下命令,查看NPD配置是否生效。
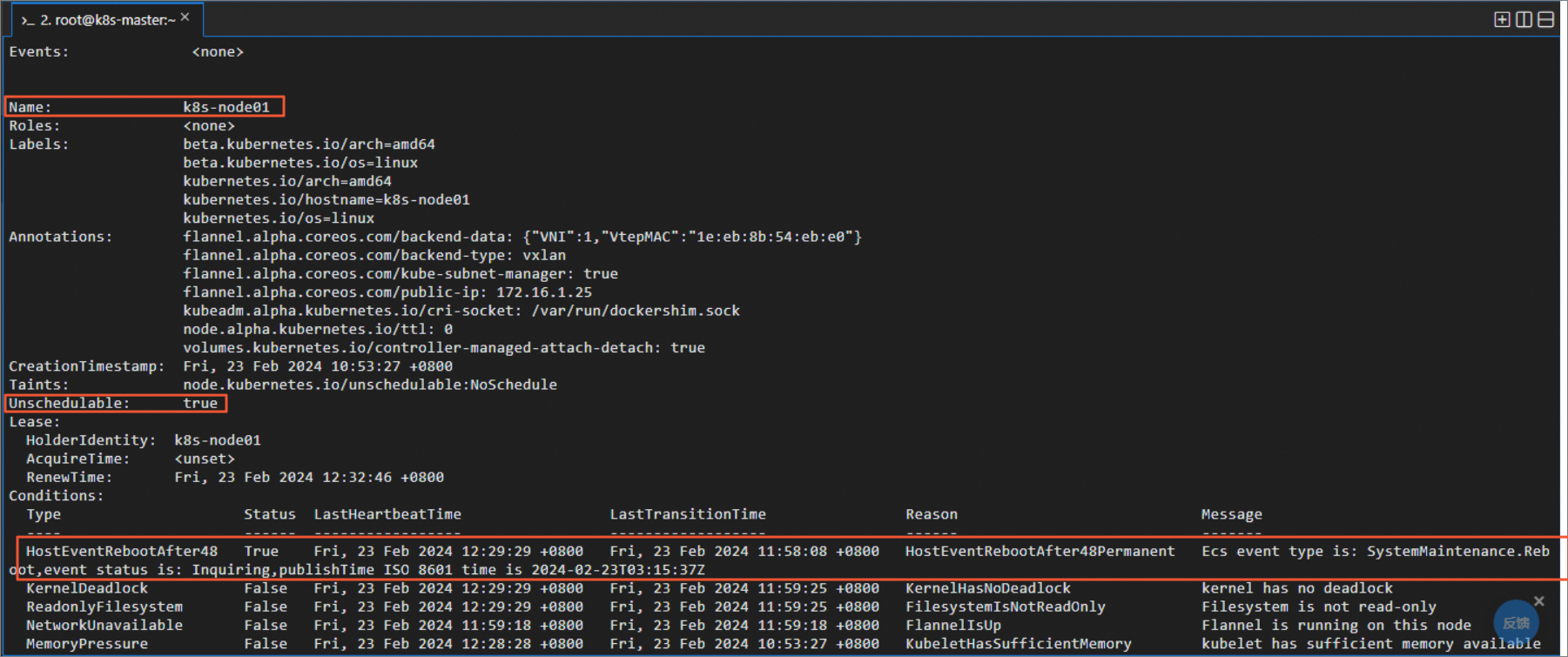
sudo kubectl describe nodes -n kube-system如以下回顯所示,condition已經新增HostEventRebootAfter48,表示NPD配置已完成并生效(若未出現,可稍等3~5分鐘)。
為集群配置控制器Draino(該配置作用于整個集群)。
根據實際情況,配置或修改Draino配置。
執行如下命令,使Draino配置生效。
實例未配置過Draino:安裝Draino
在實例內部添加如下YAML文件。
--- apiVersion: v1 kind: ServiceAccount metadata: labels: {component: draino} name: draino namespace: kube-system --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRole metadata: labels: {component: draino} name: draino rules: - apiGroups: [''] resources: [events] verbs: [create, patch, update] - apiGroups: [''] resources: [nodes] verbs: [get, watch, list, update] - apiGroups: [''] resources: [nodes/status] verbs: [patch] - apiGroups: [''] resources: [pods] verbs: [get, watch, list] - apiGroups: [''] resources: [pods/eviction] verbs: [create] - apiGroups: [extensions] resources: [daemonsets] verbs: [get, watch, list] --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRoleBinding metadata: labels: {component: draino} name: draino roleRef: {apiGroup: rbac.authorization.k8s.io, kind: ClusterRole, name: draino} subjects: - {kind: ServiceAccount, name: draino, namespace: kube-system} --- apiVersion: apps/v1 kind: Deployment metadata: labels: {component: draino} name: draino namespace: kube-system spec: # Draino does not currently support locking/master election, so you should # only run one draino at a time. Draino won't start draining nodes immediately # so it's usually safe for multiple drainos to exist for a brief period of # time. replicas: 1 selector: matchLabels: {component: draino} template: metadata: labels: {component: draino} name: draino namespace: kube-system spec: containers: - name: draino image: planetlabs/draino:dbadb44 # You'll want to change these labels and conditions to suit your deployment. command: - /draino - --debug - --evict-daemonset-pods - --evict-emptydir-pods - --evict-unreplicated-pods - KernelDeadlock - OutOfDisk - HostEventRebootAfter48 # - ReadonlyFilesystem # - MemoryPressure # - DiskPressure # - PIDPressure livenessProbe: httpGet: {path: /healthz, port: 10002} initialDelaySeconds: 30 serviceAccountName: draino實例已配置Draino:修改Draino配置
打開Draino配置文件,找到
containers:行,添加步驟2在node-problem-detector-config.yaml文件中定義的事件名稱(例如HostEventRebootAfter48),如下所示:containers: - name: draino image: planetlabs/draino:dbadb44 # You'll want to change these labels and conditions to suit your deployment. command: - /draino - --debug ...... - KernelDeadlock - OutOfDisk - HostEventRebootAfter48 # 添加的行sudo kubectl create -f draino.yaml
步驟三:下線異常節點并增加新節點
完成容器驅逐后,您可以結合業務場景用已有的集群下線方案完成異常節點下線,或者可以選擇使用社區開源的Autoscaler自動釋放異常節點并創建新實例加入到集群節點。如果需要使用Autoscaler,請參見Autoscaler官方文檔。
結果驗證
登錄任意節點,執行以下命令,模擬生成一條ECS系統事件日志。
重要時間需替換為系統當前最新時間。
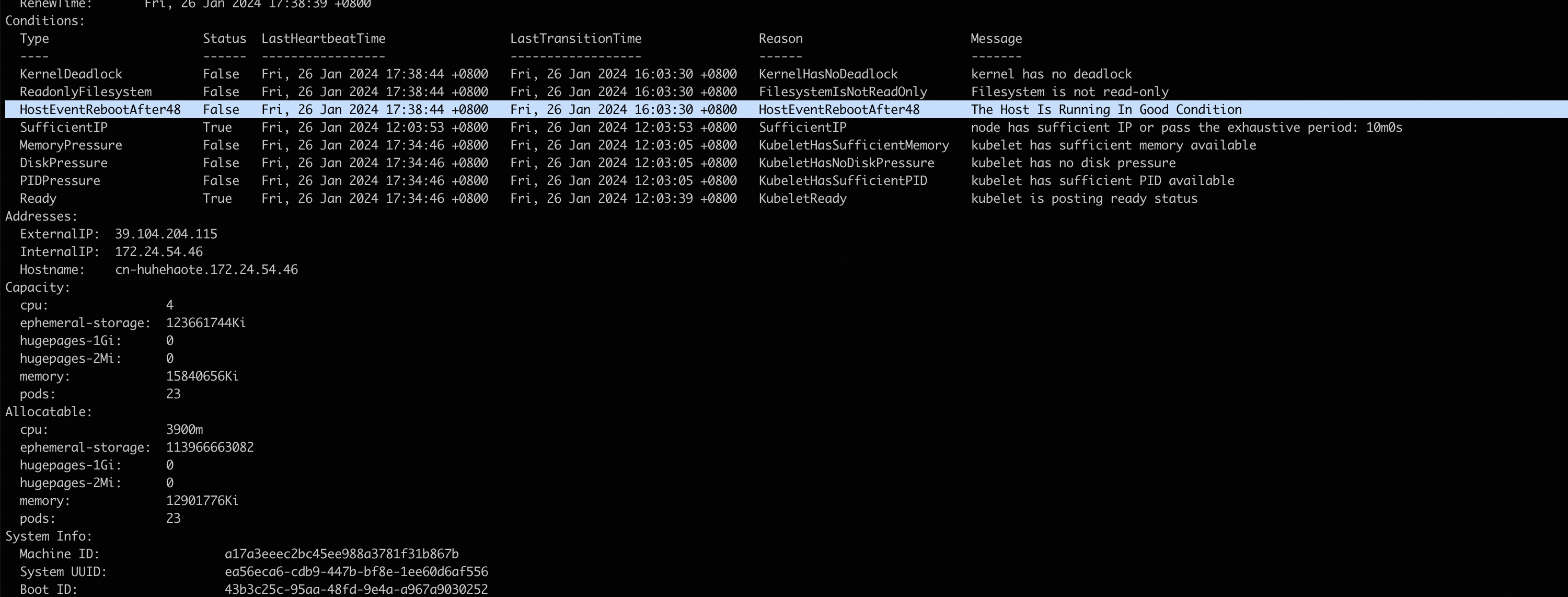
sudo echo '2024-02-23 12:29:29 - WARNING - Ecs event type is: InstanceFailure.Reboot,event status is: Executed,action ISO 8601 time is 2023-12-27T11:49:28Z' > /var/log/host_event.log執行如下命令,可看到插件會根據檢測到事件自動生成k8s事件,并將該節點置為不可調度。
sudo kubectl describe nodes -n kube-system