本文介紹如何搭建Stable Diffusion的WebUI框架以實現2秒內文本生成圖片、如何使用AiaccTorch加速圖片生成速度,以及如何使用不同模型進行推理。
背景信息
Stable Diffusion是一個可通過文本生成圖像的擴散模型,基于CLIP模型從文字中提取隱變量,并通過UNet模型生成圖片;最后通過逐步擴散、逐步處理圖像,優化圖像質量。
AIACC-Inference(AIACC推理加速器)Torch版可通過對模型的計算圖進行切割,執行層間融合,以及高性能OP實現,大幅度提升PyTorch的推理性能。您無需指定精度和輸入尺寸,即可通過JIT編譯的方式對PyTorch框架下的深度學習模型進行推理優化。更多信息,請參見手動安裝AIACC-Inference(AIACC推理加速)Torch版。
本文基于阿里云GPU服務器和Stable Diffusion的WebUI框架,指導您如何基于AIACC加速器快速實現AIGC繪畫。

阿里云不對第三方模型的合法性、安全性、準確性進行任何保證,阿里云不對由此引發的任何損害承擔責任。
您應自覺遵守第三方模型的用戶協議、使用規范和相關法律法規,并就使用第三方模型的合法性、合規性自行承擔相關責任。
操作步驟
創建ECS實例
本文使用的ai-inference-solution市場鏡像中,內置了以下三個模型及運行環境。
v1-5-pruned-emaonly.safetensors:Stable Diffusion v1.5模型,一種潛在的text-to-image(文本到圖像)的擴散模型,能夠在給定任何文本輸入的情況下生成逼真的圖像。
說明該模型中文提示詞效果不好,建議使用英文提示詞。
Taiyi-Stable-Diffusion-1B-Chinese-v0.1:太乙-中文模型,基于0.2億篩選過的中文圖文對訓練,可以使用中文進行AI繪畫。
Taiyi-Stable-Diffusion-1B-Anime-Chinese-v0.1:太乙-動漫風格模型,首個開源的中文Stable Diffusion動漫模型,該模型是基于Taiyi-Stable-Diffusion-1B-Chinese-v0.1進行繼續訓練,經過100萬篩選過的動漫中文圖文對訓練得到的。太乙-動漫風格模型不僅能夠生成精美的動漫圖像,還保留了太乙-中文模型對中文概念強大的理解能力。
前往實例創建頁。
按照界面提示完成參數配置,創建一臺ECS實例。
需要注意的參數如下,其他參數的配置,請參見自定義購買實例。
實例:選擇實例規格為ecs.gn7i-c16g1.4xlarge。
鏡像:本文使用已部署好推理所需環境的云市場鏡像,名稱為ai-inference-solution。
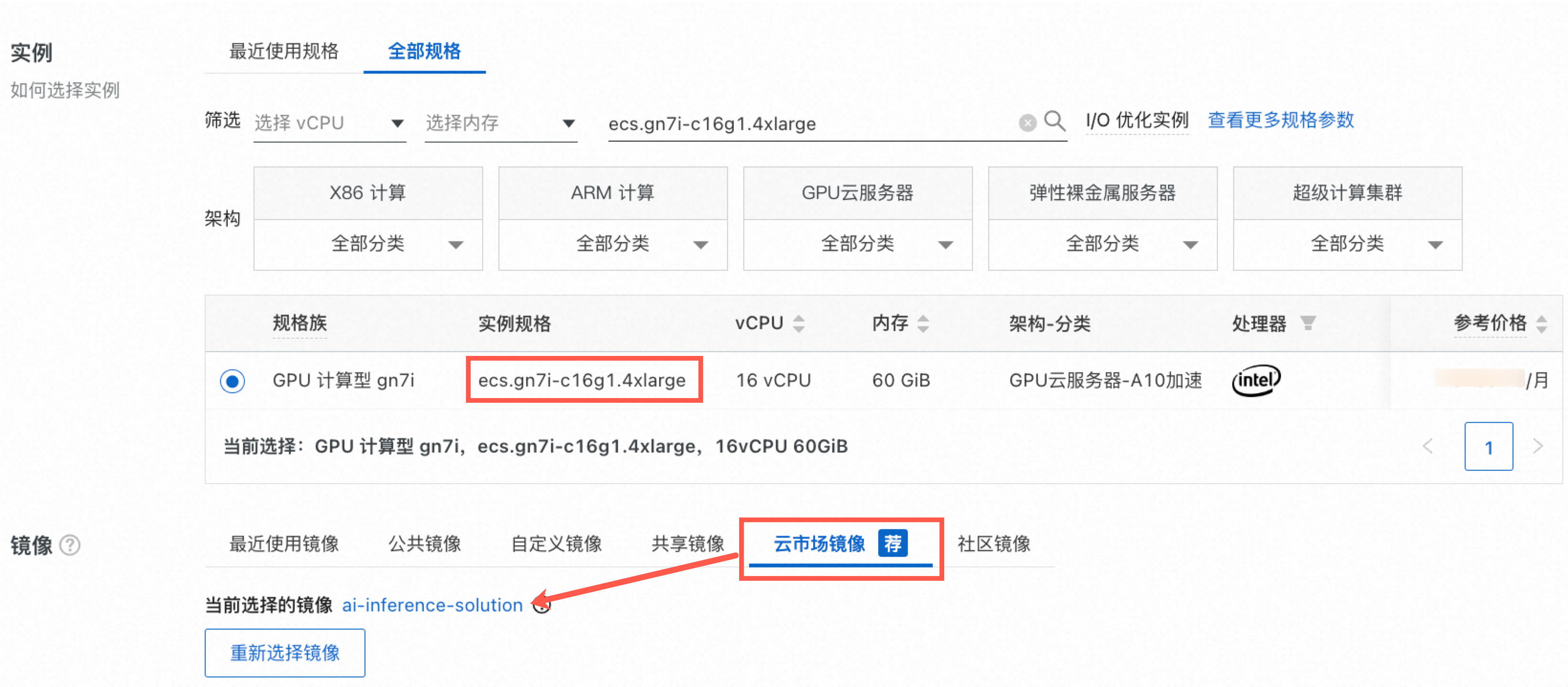
公網IP:選中分配公網IPv4地址,帶寬計費模式選擇按使用流量,帶寬峰值設置為10 Mbps。
說明如果您需要自行下載模型測試,建議將帶寬峰值設置為100 Mbps,以加快模型下載速度。
為當前ECS實例添加安全組規則,具體操作,請參見添加安全組規則。
安全組規則所屬的方向:入方向,端口范圍:5000/5000,授權對象:訪問WebUI服務的本地客戶端公網IP地址(非實例公網IP地址)。例如本地客戶端公網IP為101.200.XX.XX,則授權對象為101.200.XX.XX/32。

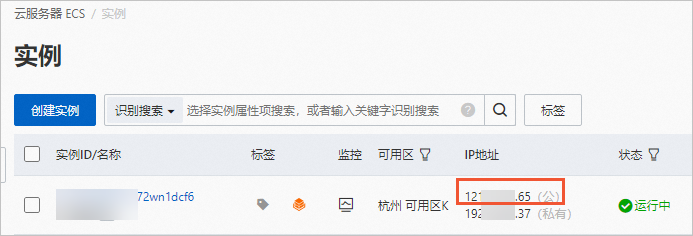
創建完成后,在ECS實例頁面,獲取公網IP地址。
說明公網IP地址用于生成圖片測試時訪問WebUI服務。
為Nginx添加用戶登錄驗證
本文所使用的鏡像中預裝了Nginx軟件,用于登錄鑒權,以防止非授權用戶登錄。
執行如下命令,創建登錄用戶和密碼。
說明${UserName}請替換為您自定義的用戶名,例如admin;'${Password}'請替換為您自定義的密碼,例如ECS@test1234。htpasswd -bc /etc/nginx/password ${UserName} '${Password}'執行如下命令,重啟Nginx。
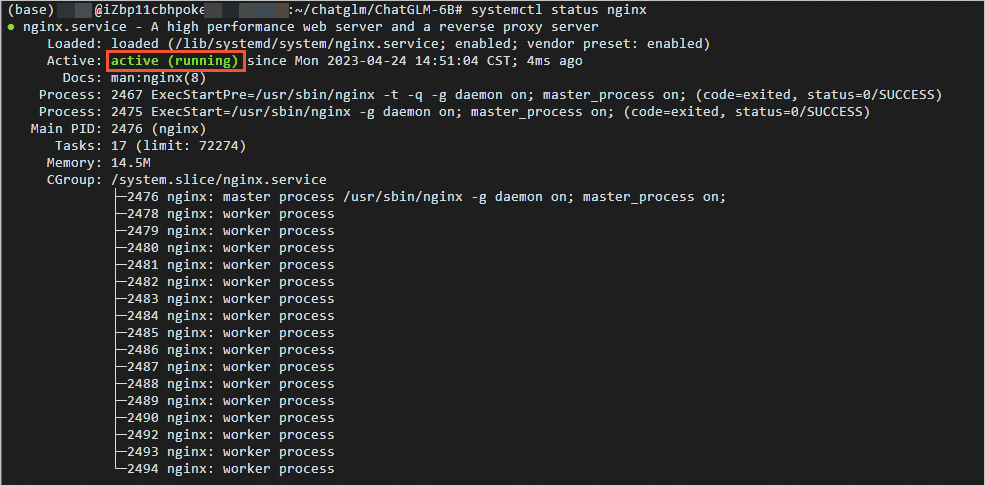
systemctl restart nginx執行如下命令,查看Nginx狀態。
systemctl status nginx當顯示如下圖所示的回顯信息時,說明Nginx處于運行中。
執行如下命令,設置Nginx開機自啟動。
systemctl enable nginx
開始文本生成圖片
步驟一:啟動WebUI服務
執行如下命令,啟動WebUI服務。
cd ~/stable-diffusion-webui/
nohup ./run_taiyi.sh &建議您等待1分鐘,等待WebUI加載完成。
步驟二:開啟AI繪畫并測試AiaccTorch加速效果
在瀏覽器地址欄輸入
http://<ECS公網IP地址>:5000,在彈出的登錄對話框,輸入上章節第1步中創建的用戶和密碼,單擊登錄。
開始AI繪畫。
說明首次應用AiaccTorch進行圖片生成,或者切換模型后的首次圖片生成,會多占用約30s時間,以進行AiaccTorch模型加載。
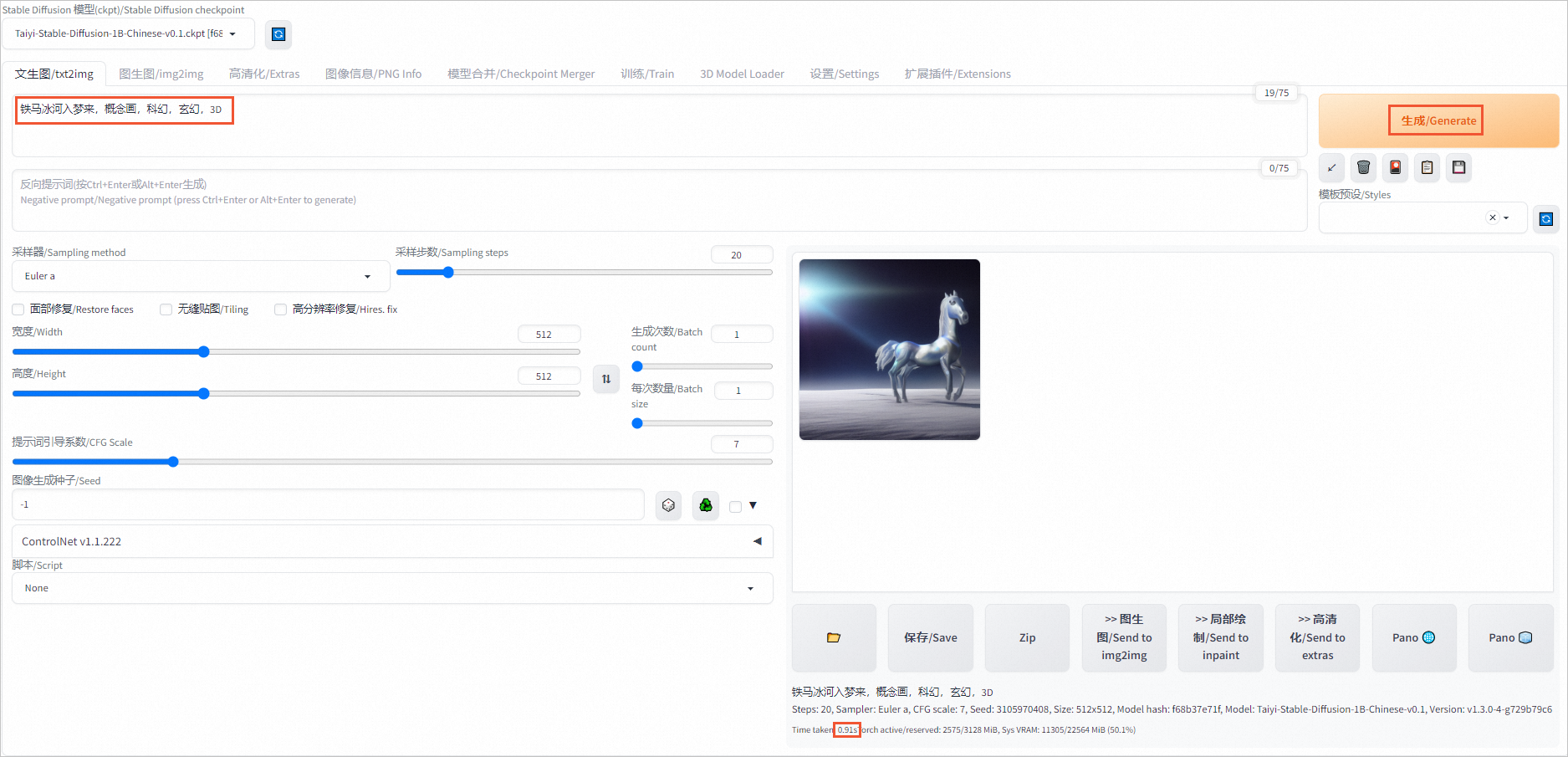
開啟AiaccTorch加速時進行AI繪畫(默認已開啟)
在對話框中輸入關鍵字,如鐵馬冰河入夢來,概念畫,科幻,玄幻,3D,單擊生成/Generate(您可以嘗試多次Generate,生成更符合需求的圖片)。
頁面右側將會展示生成的圖片和推理時間,本示例中單張圖片推理時間為0.91s。
禁用AiaccTorch時進行AI繪畫
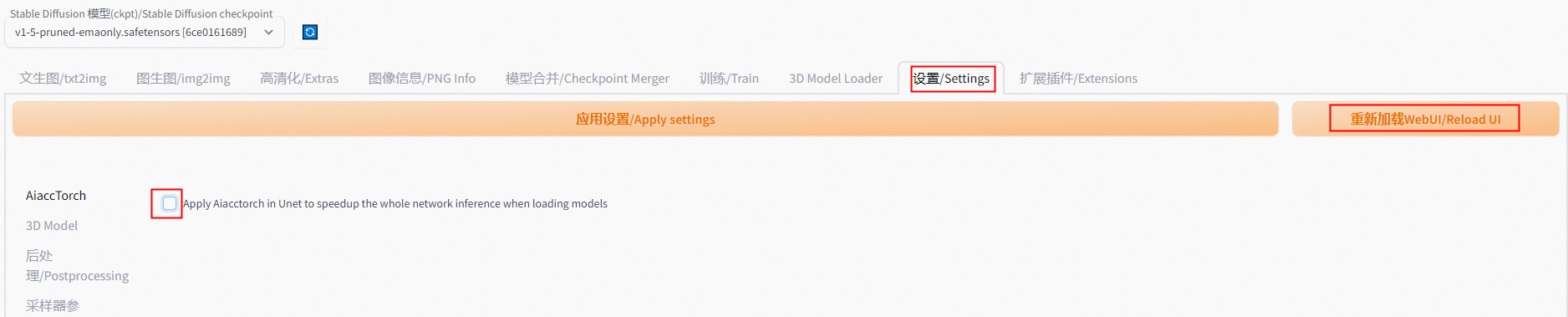
單擊設置/Settings頁簽,左側導航選擇AiaccTorch,取消選中Apply Aiacctorch in Unet to speedup the whole network inference when loading models后,單擊應用設置/Apply settings,再單擊重新加載WebUI/Reload UI。
在對話框中輸入關鍵字,單擊生成/Generate,重新生成圖片,查看推理時間(本示例為2.02s)。
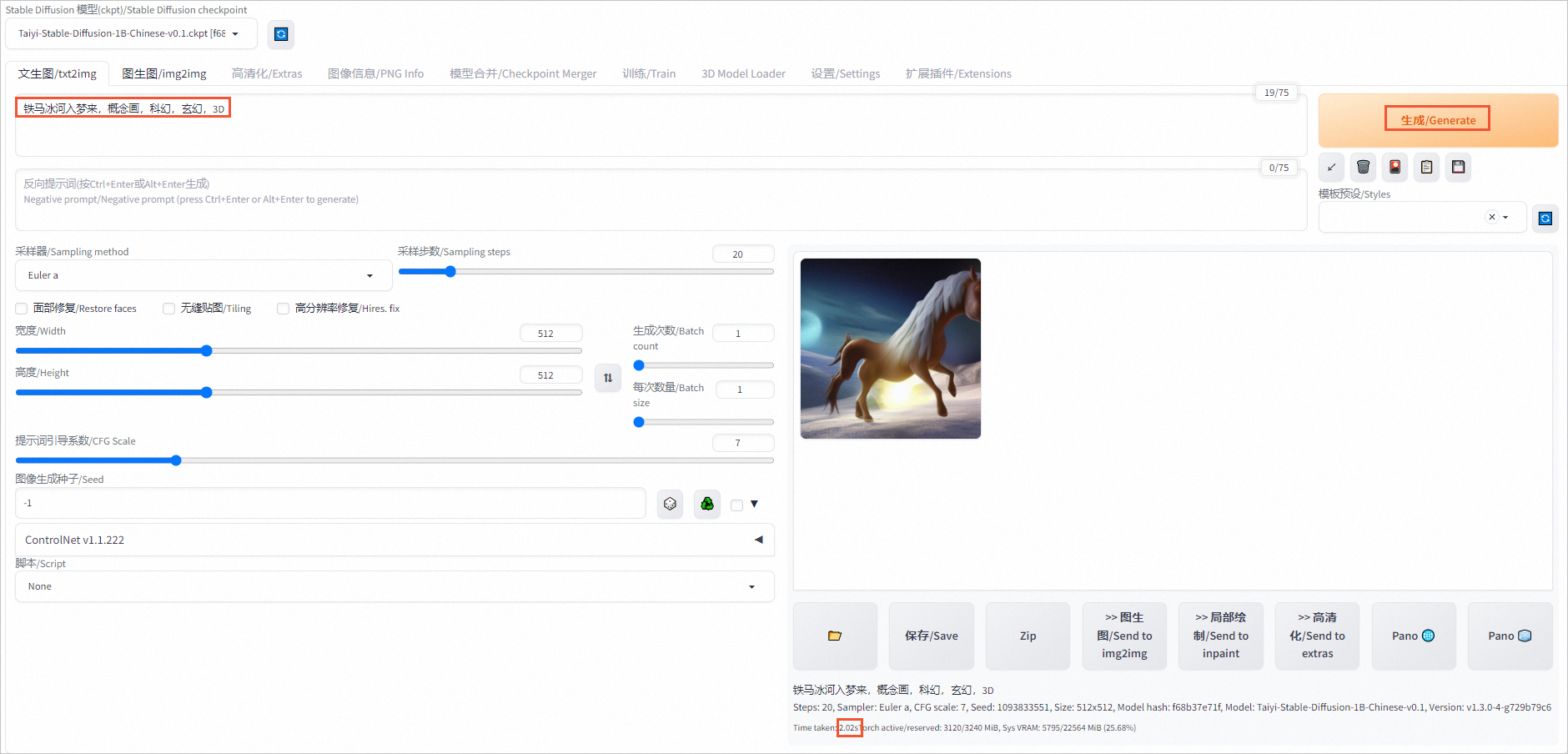
對比發現,開啟AiaccTorch后,單張圖片的推理時間要遠少于禁用AiaccTorch時的推理時間。
查看不同模型的推理效果
本文使用的鏡像中內置了3個模型,您可根據需求切換模型,查看不同模型的推理效果。
在頁面左上角,切換模型,例如切換為Taiyi-Stable-Diffusion-1B-Anime-Chinese-v0.1模型。
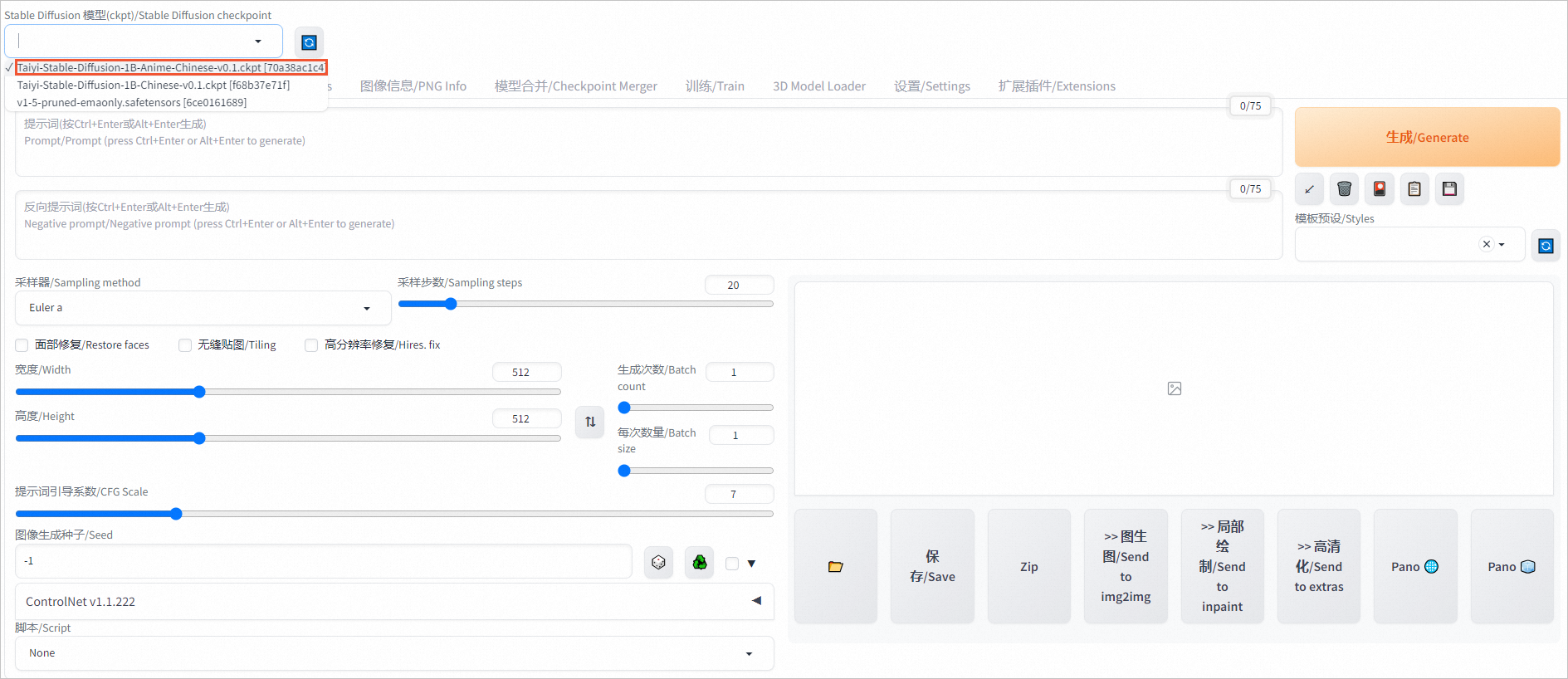
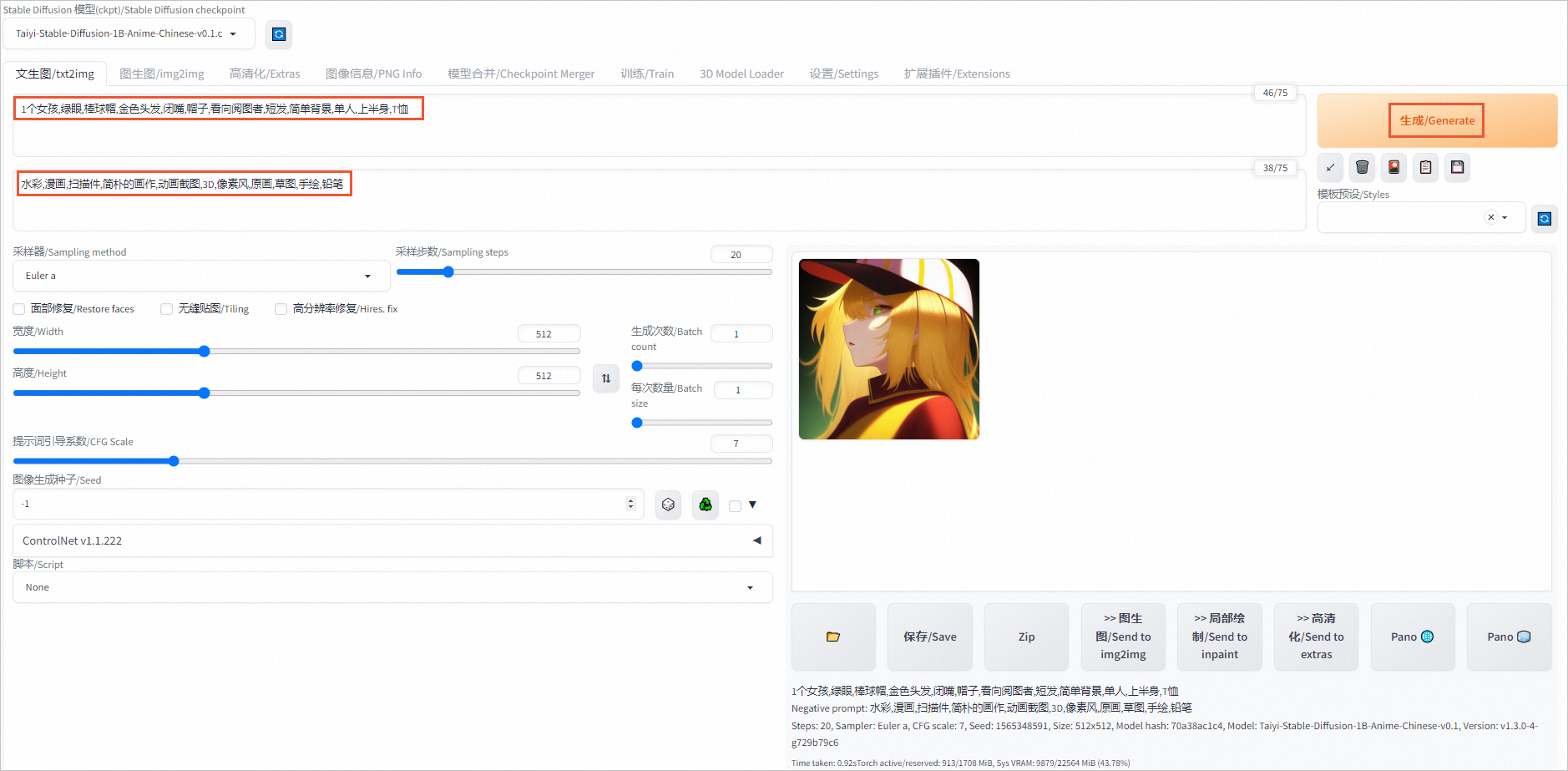
在對話框中輸入提示詞和反向提示詞。
提示詞示例:
1個女孩,綠眼,棒球帽,金色頭發,閉嘴,帽子,看向閱圖者,短發,簡單背景,單人,上半身,T恤反向提示詞示例:
水彩,漫畫,掃描件,簡樸的畫作,動畫截圖,3D,像素風,原畫,草圖,手繪,鉛筆生成的動漫風格圖像如下圖所示。
使用LoRA插件
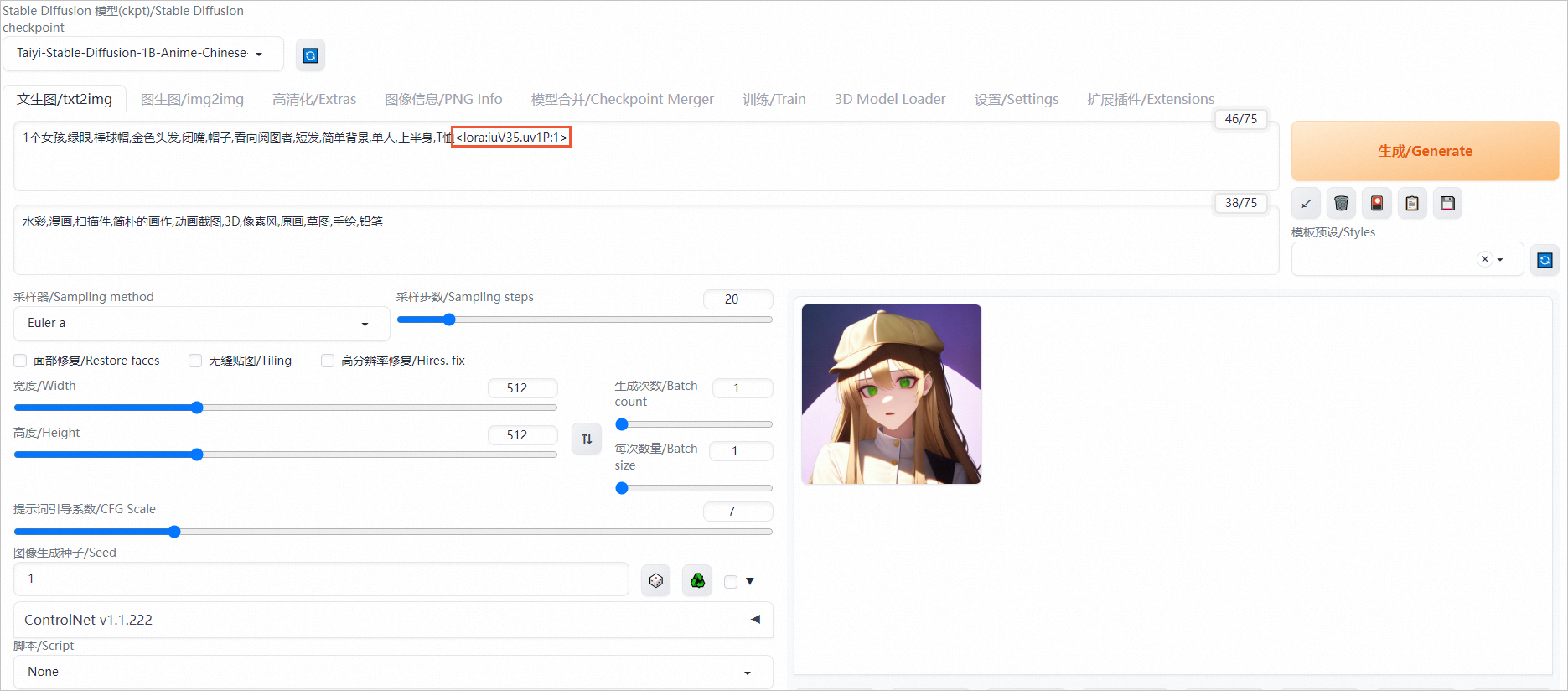
LoRA是Stable Diffusion模型的一種插件,它允許在不修改Stable Diffusion模型的情況下,使用少量數據訓練出一種畫風、IP或人物,以實現定制化需求。相較于訓練Stable Diffusion,使用LoRA所需的訓練資源更少,非常適合社區用戶和個人開發者使用。
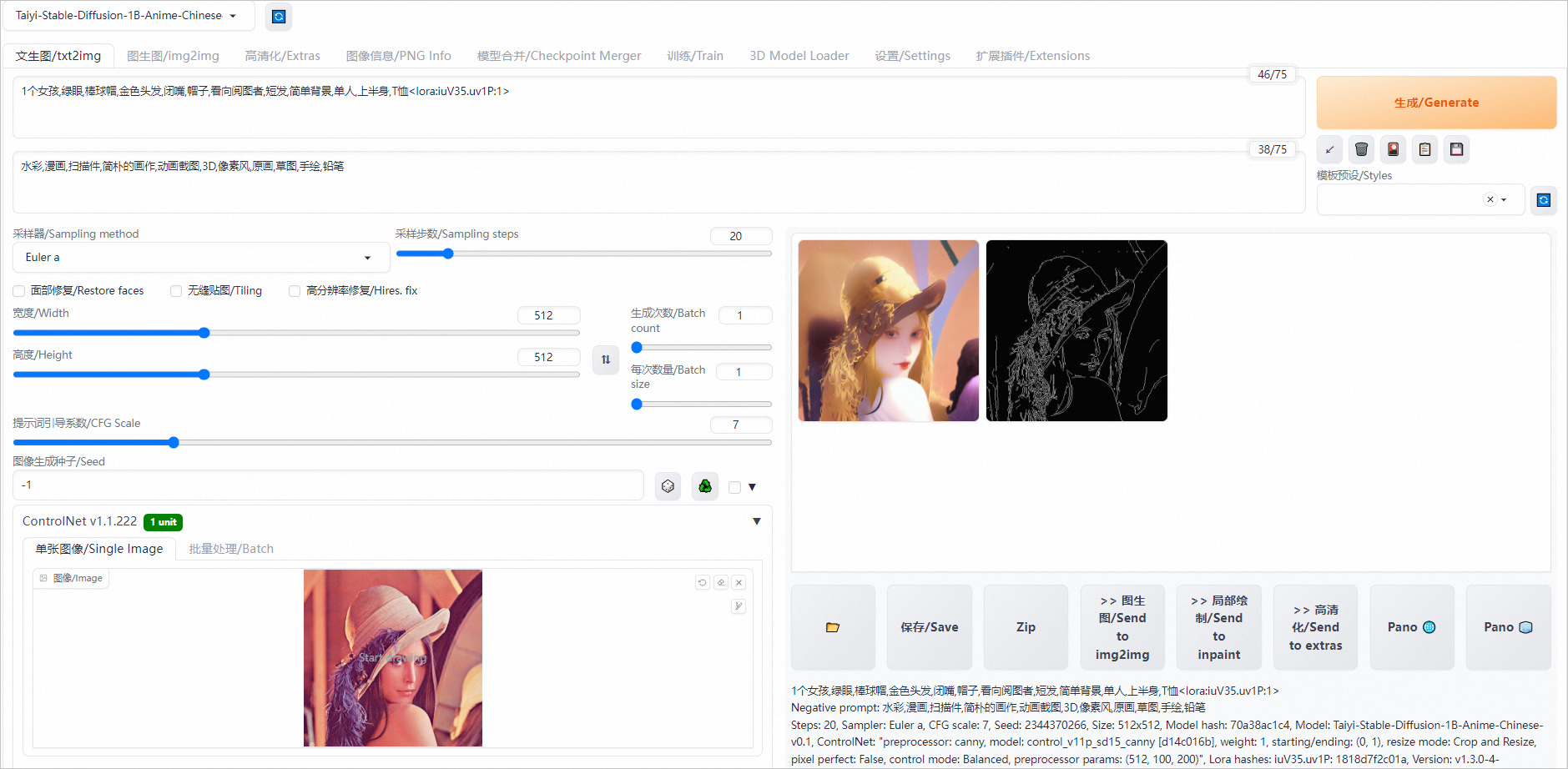
您可以在提示詞(Prompt)中添加LoRA支持文本<lora:iuV35.uv1P:1>以啟用該功能。
使用Controlnet插件
ControlNet是一個用于控制AI圖像生成的插件,它可以利用輸入圖片中的邊緣特征、深度特征或人體姿勢的骨架特征,與文字提示一起精準地控制AI圖像的生成,以獲得更好的視覺效果。
Canny是ControlNet中一個常見的模型,用于識別輸入圖像的邊緣信息,從上傳的圖片中生成線稿,然后根據關鍵詞生成與上傳圖片相似構圖的畫面。
單擊Controlnet右側的
 圖標,選中啟用/Enable,Control Type選擇Canny,在單張圖像/Single Image區域中,上傳輸入的圖片(如Lena圖)。
圖標,選中啟用/Enable,Control Type選擇Canny,在單張圖像/Single Image區域中,上傳輸入的圖片(如Lena圖)。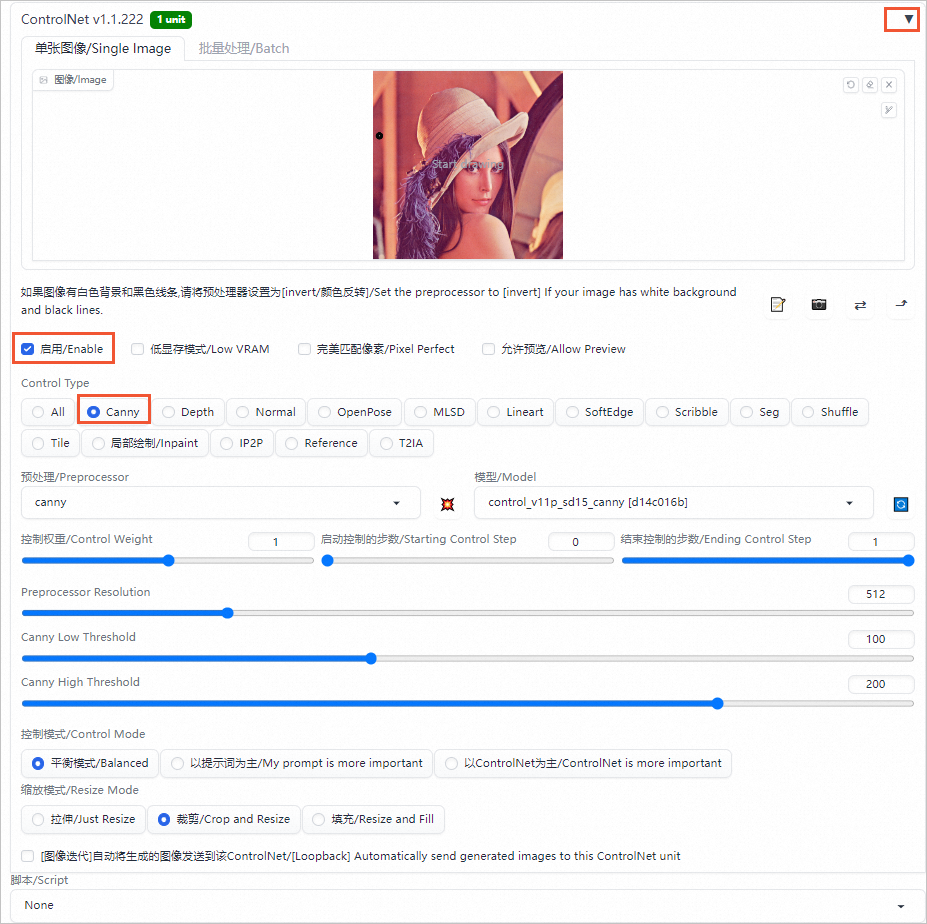
單擊生成/Generate,在頁面右側即可生成使用Canny模型生成的線稿和同樣構圖的圖片。
了解更多AIGC實踐和GPU優惠
活動入口:立即開啟AIGC之旅

反饋與建議
如果您在使用教程或實踐過程中有任何問題或建議,可以加入客戶釘釘群(釘釘群號:28335015590)與我們的工程師在線交流,將有專人跟進您的問題和建議。
