本文主要介紹當Linux系統ECS實例CPU使用率或CPU負載較高時,如何排查分析及常見案例說明。
操作場景
在您使用ECS實例過程中,可能會遇到實例CPU使用率或CPU負載持續較高的情況,您可以按照以下步驟排查定位具體問題。
找到影響CPU使用率或CPU負載過高的具體進程。
排查影響CPU使用率或CPU負載過高的進程是否正常,并分類進行處理。
對于正常進程:您需要對程序進行優化或者升配實例規格。具體操作,請參見包年包月實例升配規格或按量付費實例變配規格。
對于異常進程:您可以手動對進程進行查殺,也可以使用第三方安全工具去查殺。
CPU負載的查詢分析
在Linux系統中,查看進程的常用命令如下所示。本文主要介紹vmstat和top常用命令的使用。
vmstat
top
ps -aux
ps -ef
vmstat命令的使用
vmstat(VirtualMemoryStatistics,虛擬內存統計),通過vmstat命令,從系統維度查看操作系統的虛擬內存、進程、CPU等的整體情況。
vmstat命令
常用vmstat命令如下所示。
vmstat [-n] [delay [count]] [-n]:只在開始時顯示一次各字段名稱。
[delay]:刷新時間間隔。如果不指定,只顯示一條結果。
[count]:刷新次數。如果不指定刷新次數,但指定了刷新時間間隔,這時刷新次數為無窮。
使用示例
執行如下命令,使用vmstat每1秒統計一次各進程的CPU使用情況,連續統計4次。
vmstat -n 1 4返回示例類似如下。
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
1 0 0 2684984 310452 2364304 0 0 5 17 19 35 4 2 94 0 0
0 0 0 2687504 310452 2362268 0 0 0 252 1942 4326 5 2 93 0 0
0 0 0 2687356 310460 2362252 0 0 0 68 1891 4449 3 2 95 0 0
0 0 0 2687252 310460 2362256 0 0 0 0 1906 4616 4 1 95 0 0顯示結果主要字段說明
r:表示系統中CPU等待處理的線程。一個CPU每次只能處理一個線程,所以該數值越大,通常表示系統運行越慢。
us:用戶模式消耗的CPU時間百分比。該值較高時,說明用戶進程消耗的CPU時間比較多。如果該值長期超過50%,則需要對程序算法或代碼等進行優化。
sy:內核模式消耗的CPU時間百分比。
wa:I/O等待消耗的CPU時間百分比。該值較高時,說明IO等待比較嚴重,這可能是磁盤大量作隨機訪問造成的,也可能是磁盤性能出現了瓶頸。
id:處于空閑狀態的CPU時間百分比。如果該值持續為0,同時sy是us的兩倍,則通常說明系統面臨CPU資源短缺。
top命令的使用
top命令是Linux系統中常用的性能分析工具,可以實時顯示系統中各進程的資源占用情況。
top命令
top [-n] [-d] [-n]:刷新次數。如果不指定刷新次數,但指定了刷新時間間隔,這時刷新次數為無窮。
[-d] :刷新時間間隔。
使用示例
遠程連接Linux系統的ECS實例。
具體操作,請參見連接方式概述。
執行如下命令,查看系統中各進程的資源占用情況。
如下命令表示:每2秒統計一次各進程相關信息,統計5次后停止。
top -n 5 -d 2系統顯示類似如下。
top - 17:27:13 up 27 days, 3:13, 1 user, load average: 0.02, 0.03, 0.05 Tasks: 94 total, 1 running, 93 sleeping, 0 stopped, 0 zombie %Cpu(s): 0.3 us, 0.1 sy, 0.0 ni, 99.5 id, 0.0 wa, 0.0 hi, 0.0 si, 0.1 st KiB Mem: 1016656 total, 946628 used, 70028 free, 169536 buffers KiB Swap: 0 total, 0 used, 0 free. 448644 cached Mem PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 1 root 20 0 41412 3824 2308 S 0.0 0.4 0:19.01 systemd 2 root 20 0 0 0 0 S 0.0 0.0 0:00.04 kthreadd顯示結果主要字段說明
針對CPU使用率和CPU負載問題,您只需關注回顯的第一行和第三行信息,詳細說明如下。
第一行:顯示的內容
17:27:13 up 27 days, 3:13, 1 user, load average: 0.02, 0.03, 0.05,依次為系統當前時間、系統到目前為止已運行的時間、當前登錄系統的用戶數量、系統負載。第三行:顯示當前CPU資源的總體使用情況,下方會顯示各個進程的資源占用情況。
在top命令執行過程中,可以使用一些交互命令。
通過P鍵,可以對CPU使用率進行倒序排列,方便定位系統中占用CPU較高的進程。
通過M鍵,您可以對系統內存使用情況進行排序。如果有多核CPU,數字鍵1可以顯示每核CPU的負載狀況。
執行
ll /proc/PID/exe命令,可以查看每個進程ID對應的程序文件。終止CPU消耗較大的進程。
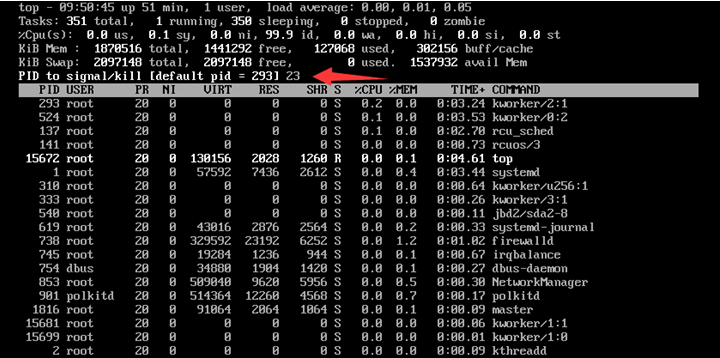
先寫入小寫字母k。
輸入想要終止的進程PID,按Enter鍵。
默認為輸出結果的第一個PID,如下圖所示,假如想要終止PID為23的進程,輸入23后按Enter鍵。
操作成功后,界面會出現類似
Send pid 23 signal [15/sigterm]的提示信息,按Enter鍵確認即可。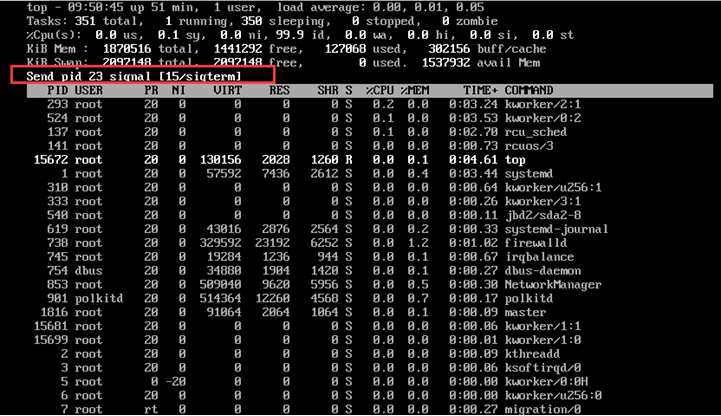
常見CPU資源過高案例分析
案例一:CPU使用率較低但負載較高
問題現象
當前Linux系統沒有業務程序運行。通過top命令觀察,發現CPU使用率不高,但是CPU負載(load average)卻非常高,如下圖所示。

問題原因
該問題可能是因為僵尸(zombie)進程過多導致。
load average是對CPU負載進行評估的,其值越高說明其任務隊列越長,處于等待執行的任務越多。
解決方案
您可以通過ps -axjf命令查看是否存在D+狀態進程,該狀態是指不可中斷的睡眠狀態。
處于該狀態的進程無法終止,也無法自行退出,只能通過恢復其依賴的資源或者重啟系統來解決。

案例二:kswapd0進程占用CPU較高
問題現象
ECS實例運行卡頓,使用top命令查看,kswapd0進程占用了99% CPU。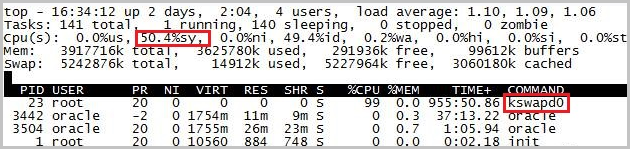
問題原因
出現該問題可能是系統此時在持續進行換頁操作,導致占用大量CPU資源。
kswapd0是虛擬內存管理中負責換頁的進程,當ECS實例物理內存不足時,kswapd0會執行換頁操作,換頁操作會消耗大量的CPU資源。
解決方案
您可以通過修改vm.swappiness內核參數來控制交換空間的大小,來解決kswapd0進程占用CPU較高的問題。
登錄Linux實例。
具體操作,請參見連接方式概述。
查看swappiness參數。
cat /proc/sys/vm/swappiness系統顯示類似如下,表示當物理內存低于60%(100-40)時使用swap空間。
說明swappiness參數越低,表示Linux系統盡量少用swap分區,多用物理內存;swappiness參數值越高,表示使內核更多地去使用swap空間。

根據業務需要,修改swappiness參數。
打開內核參數配置文件sysctl.conf。
vi /etc/sysctl.conf根據業務需要,修改swappiness參數值。
如在sysctl.conf文件中,修改
vm.swappiness = 10。按
Esc鍵,輸入:wq保存修改。重新加載sysctl配置文件,使配置生效。
sysctl -p若該問題還未解決,建議您升配實例規格。具體操作,請參見包年包月實例升配規格或按量付費實例變配規格。
案例三:CPU使用率過高100%問題排查
問題現象
使用ECS實例的過程中,如果遇到CPU使用率高達100%等異常情況,且無法通過top、htop等命令查詢到消耗CPU資源的具體進程。
問題原因
該問題可能是病毒導致。
解決方案
查看云監控監控數據。
登錄云監控管理控制臺。
在左側導航欄,單擊主機監控。
找到異常主機,單擊操作列的監控圖表。
在操作系統監控頁簽下,查看該主機的CPU使用率并記錄具體時間點。
查看Linux實例的命令修改記錄。
登錄Linux實例。
具體操作,請參見連接方式概述。
執行如下命令,查看當前Linux系統命令最近是否被修改過。
stat /usr/bin/top系統顯示類似如下,系統命令有被修改。查看更改時間是否和云監控中CPU使用率出現100%的時間點吻合。

分別執行如下命令,查看
ps或top命令是否被修改過。rpm -Vf /bin/ps rpm -Vf /usr/bin/top正常情況下,系統無返回修改信息。
系統異常情況下,顯示類似如下,表示
ps和top命令被修改過。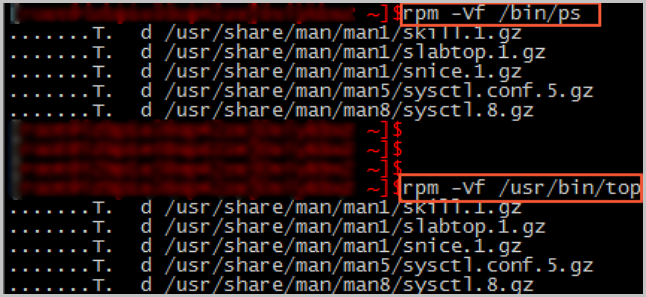
執行如下命令,查看當前實例是否連接到異常域名。
iftop -i [$Device] -n -P說明[$Device]請替換為當前系統使用的網卡,如eth0。
系統顯示類似如下,若您沒有連接過crypto-pool.fr,則crypto-pool.fr是異常域名。
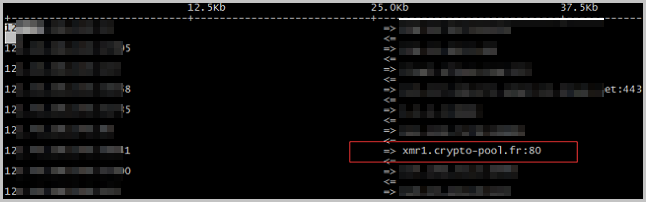
綜合以上表現,top、ps命令被修改,并且連接到異常域名,判斷您的ECS實例已被病毒入侵,可以參考以下方案。