本文介紹如何使用HPL測試E-HPC集群的浮點性能。
背景信息
HPL(The High-Performance Linpack Benchmark)是測試高性能計算集群系統浮點性能的基準。HPL通過對高性能計算集群采用高斯消元法求解一元N次稠密線性代數方程組的測試,評價高性能計算集群的浮點計算能力。
浮點計算峰值是指計算機每秒可以完成的浮點計算次數,包括理論浮點峰值和實測浮點峰值。理論浮點峰值是該計算機理論上每秒可以完成的浮點計算次數,主要由CPU的主頻決定。理論浮點峰值=CPU主頻×CPU核數×CPU每周期執行浮點運算的次數。本文將為您介紹如何利用HPL測試實測浮點峰值。
準備工作
創建一個E-HPC集群。具體操作,請參見創建集群。
本文使用的集群配置示例如下:
配置項
配置
系列
標準版
部署模式
公共云集群
集群類型
OpenPBS
節點配置
包含1個管理節點和1個計算節點,規格如下:
管理節點:采用ecs.c7.large實例規格,該規格配置為2 vCPU,4 GiB內存。
計算節點:采用ecs.ebmc5s.24xlarge實例規格,該規格配置為96 vCPU、192 GiB內存。
集群鏡像
CentOS 7.6公共鏡像
創建一個集群用戶。具體操作,請參見用戶管理。
集群用戶用于登錄集群,進行編譯軟件、提交作業等操作。本文創建的用戶示例如下:
用戶名:hpltest
用戶組:sudo權限組
安裝軟件。具體操作,請參見安裝和卸載集群軟件。
需安裝的軟件如下:
linpack,版本為2018。
intel-mpi,版本為2018。
步驟一:連接集群
遠程連接E-HPC集群。具體操作,請參見連接集群。
步驟二:提交作業
執行以下命令,創建算例文件,算例文件命名為HPL.dat。
vim HPL.dat算例文件HPL.dat包含了HPL運行的參數。如下示例是在單臺ecs.ebmc5s.24xlarge實例上運行HPL的推薦配置。
HPLinpack benchmark input file Innovative Computing Laboratory, University of Tennessee HPL.out output file name (if any) 6 device out (6=stdout,7=stderr,file) 1 # of problems sizes (N) 143600 Ns 1 # of NBs 384 NBs 1 PMAP process mapping (0=Row-,1=Column-major) 1 # of process grids (P x Q) 1 Ps 1 Qs 16.0 threshold 1 # of panel fact 2 PFACTs (0=left, 1=Crout, 2=Right) 1 # of recursive stopping criterium 2 NBMINs (>= 1) 1 # of panels in recursion 2 NDIVs 1 # of recursive panel fact. 1 RFACTs (0=left, 1=Crout, 2=Right) 1 # of broadcast 0 BCASTs (0=1rg,1=1rM,2=2rg,3=2rM,4=Lng,5=LnM) 1 # of lookahead depth 0 DEPTHs (>=0) 0 SWAP (0=bin-exch,1=long,2=mix) 1 swapping threshold 1 L1 in (0=transposed,1=no-transposed) form 1 U in (0=transposed,1=no-transposed) form 0 Equilibration (0=no,1=yes) 8 memory alignment in double (> 0)您可以根據節點的硬件配置,調整HPL.dat文件中相關參數,參數的說明如下所示:
第5~6行內容。
1 # of problems sizes (N) 143600 NsN表示求解的矩陣數量與規模。矩陣規模N越大,有效計算所占的比例也越大,系統浮點處理性能也就越高。但矩陣規模越大會導致內存消耗量越多,如果系統實際內存空間不足,使用緩存、性能會大幅度降低。矩陣占用系統總內存的80%左右為最佳,即N×N×8=系統總內存×80%(其中總內存的單位為字節)。
第7~8行內容。
1 # of NBs 384 NBsNB表示求解矩陣過程中矩陣分塊的大小。分塊大小對性能有很大的影響,NB的選擇和軟硬件許多因素密切相關。NB值的選擇主要是通過實際測試得出最優值,一般遵循以下規律:
NB不能太大或太小,一般小于384。
NB×8一定是緩存行的倍數。
NB的大小和通信方式、矩陣規模、網絡、處理器速度等有關系。
一般通過單節點或單CPU測試可以得到幾個較好的NB值,但當系統規模增加、問題規模變大,有些NB取值所得性能會下降。因此建議在小規模測試時選擇3個性能不錯的NB值,再通過大規模測試檢驗這些選擇。
第10~12行內容。
1 # of process grids (P x Q) 1 Ps 1 QsP表示水平方向處理器個數,Q表示垂直方向處理器個數。P×Q表示二維處理器網格。P×Q=進程數。對于處理器為Intel? Xeon?的ECS實例,關閉超線程可以提高HPL性能。P和Q的取值一般遵循以下規律:
P≤Q,一般情況下P的取值小于Q,因為列向通信量(通信次數和通信數據量)要遠大于橫向通信。
P建議選擇2的冪。HPL中水平方向通信采用二元交換法(Binary Exchange),當水平方向處理器個數P為2的冪時性能最優。
執行以下命令,創建并打開作業腳本文件,腳本文件命名為hpl.pbs。
vim hpl.pbs腳本內容示例如下:
說明本示例測試單節點的實測浮點峰值。如果您想測試多個節點的實測浮點峰值,可以修改腳本內容。
#!/bin/sh #PBS -j oe export MODULEPATH=/opt/ehpcmodulefiles/ module load linpack/2018 module load intel-mpi/2018 echo "run at the beginning" mpirun -n 1 -host compute000 /opt/linpack/2018/xhpl_intel64_static > hpl-output #測試單節點的浮點性能,compute000為運行作業的節點名稱,請自行替換 #mpirun -n <N> -ppn 1 -host <node0>,...,<nodeN> /opt/linpack/2018/xhpl_intel64_static > hpl-output #測試多節點的浮點性能,<>里的內容請根據實際替換執行以下命令,提交作業。
qsub hpl.pbs返回示例如下,表示生成的作業ID為0.manager。
0.manager
步驟三:查看作業結果
查看作業運行情況。
qstat -x 0.manager預期返回如下,當返回信息中
S為R時,表示作業正在運行中;當返回信息中S為F時,表示作業已經運行結束。Job id Name User Time Use S Queue ---------------- ---------------- ---------------- -------- - ----- 0.manager hpl.pbs hpltest 11:01:49 F workq查看作業結果。
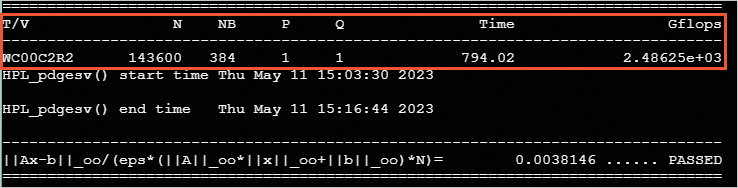
cat /home/hpltest/hpl-output本次測試結果如下: