本文為您介紹在Ubuntu環境中如何使用PyPaimon創建DLF Paimon表以及讀寫DLF Paimon表數據的方法。
背景信息
PyPaimon作為Apache Paimon的Python SDK,不僅支持通過Python便捷地將數據寫入Paimon表,實現高效的數據入湖操作,還支持通過Python高效處理Paimon中的數據。使用pypaimon_dlf2 SDK并配置DLF Catalog后,您可以將Paimon表的元數據同步至數據湖構建(DLF)服務中,從而便于阿里云上的其他計算引擎接入這些數據資源。此外,借助DLF提供的全面的數據湖管理功能,還可以實現對數據湖生命周期的有效管理和存儲格式的優化。
前提條件
已創建DLF 2.0數據目錄。如未創建,請參見新建數據目錄。
確保Ubuntu環境中已安裝JRE 8,可通過運行
java -version命令來驗證Java版本。如未安裝或版本不一致,請安裝正確的版本(例如, 您可嘗試通過apt install openjdk-8-jre來安裝OpenJDK 8的JRE版本)。確保Python版本為Python 3.8及以上。
操作步驟
步驟一:環境準備
下載pypaimon_dlf2-0.3.dev0.tar.gz安裝包,并上傳到Ubuntu環境的目標目錄下。
重要該安裝包目前僅支持Ubuntu環境,其他環境可能無法使用。
進入目標目錄下,執行以下命令,安裝pypaimon_dlf2 SDK。
pip3 install pypaimon_dlf2-0.3.dev0.tar.gz(可選)安裝完成后,可通過
pip show pypaimon_dlf2命令查看結果。
步驟二:通過PyPaimon訪問DLF Paimon表
在目標目錄下,執行以下命令,新建文件
testdlf.py。vim testdlf.py在
testdlf.py文件中,寫入以下完整示例代碼。此示例展示了如何通過PyPaimon創建DLF Paimon表以及讀寫DLF Paimon表數據。代碼的具體參數配置及多種讀寫表數據的方式,請參見代碼詳解。import pyarrow as pa import pandas as pd from pypaimon import Schema from pypaimon.py4j import Catalog # 創建 catalog catalog_options = { 'metastore': 'dlf-paimon', 'dlf.region': 'xxx', 'dlf.endpoint': 'xxx', 'dlf.catalog.id': 'xxx', 'dlf.catalog.accessKeyId': 'xxx', 'dlf.catalog.accessKeySecret': 'xxx', 'max-workers': 'N' } catalog = Catalog.create(catalog_options) # 創建 database catalog.create_database( name='testdb', ignore_if_exists=True # 是否忽略Database已存在的錯誤 ) # 創建 Schema pa_schema = pa.schema([ ('date', pa.string()), ('hour', pa.string()), ('key', pa.int64()), ('value', pa.string()) ]) schema = Schema( pa_schema=pa_schema, partition_keys=['date', 'hour'], primary_keys=['date', 'hour', 'key'], options={'bucket': '2'}, comment='my test table' ) # 創建 table catalog.create_table( identifier='testdb.tb', schema=schema, ignore_if_exists=True # 是否忽略表已存在的錯誤 ) table = catalog.get_table('testdb.tb') # 創建 table write and commit write_builder = table.new_batch_write_builder() table_write = write_builder.new_write() table_commit = write_builder.new_commit() # 寫表數據,支持pyarrow和Pandas # 寫入Pandas示例數據 data = { 'date': ['2024-12-01', '2024-12-01', '2024-12-02'], 'hour': ['08', '09', '08'], 'key': [1, 2, 3], 'value': ['AAA', 'BBB', 'CCC'], } dataframe = pd.DataFrame(data) table_write.write_pandas(dataframe) # 提交數據 table_commit.commit(table_write.prepare_commit()) # 關閉資源 table_write.close() table_commit.close() # 讀表數據,支持多種數據格式 read_builder = table.new_read_builder() predicate_builder = read_builder.new_predicate_builder() predicate = predicate_builder.equal('date', '2024-12-01') read_builder = read_builder.with_filter(predicate) table_scan = read_builder.new_scan() splits = table_scan.plan().splits() table_read = read_builder.new_read() pa_table = table_read.to_arrow(splits) print(pa_table)
步驟三:運行Python文件
進入目標目錄,執行以下命令,運行Python腳本。
python3 testdlf.py運行結果如下。
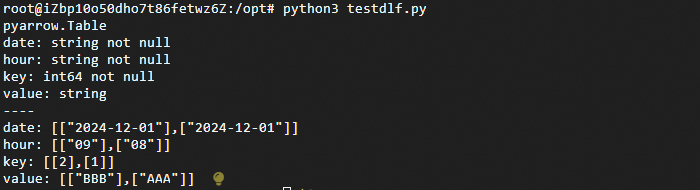
代碼詳解
通過PyPaimon創建DLF Paimon表
創建Paimon DLF Catalog。
說明Catalog是管理表的入口,在訪問DLF中的Paimon表之前,首先需要創建Catalog。
from pypaimon.py4j import Catalog # Catalog options是一個dict, key和value都是str catalog_options = { 'metastore': 'dlf-paimon', 'dlf.region': 'xxx', 'dlf.endpoint': 'xxx', 'dlf.catalog.id': 'xxx', 'dlf.catalog.accessKeyId': 'xxx', 'dlf.catalog.accessKeySecret': 'xxx', 'max-workers': 'N' } catalog = Catalog.create(catalog_options)參數說明如下。
參數
說明
metastore
dlf-paimon
dlf.region
DLF Region ID,詳情請參見地域及訪問域名。
dlf.endpoint
DLF Endpoint,詳情請參見地域及訪問域名。
dlf.catalog.id
DLF數據目錄ID。可在數據湖構建控制臺上查看數據目錄對應的ID,具體操作請參見數據目錄。
dlf.catalog.accessKeyId
訪問DLF服務所需的AccessKey。詳情請參見創建AccessKey。
dlf.catalog.accessKeySecret
訪問DLF服務所需的SecretKey。詳情請參見創建AccessKey。
max-workers
可選,PyPaimon讀數據時的并發數。N:大于等于1的整數,默認為1,即默認情況下是串行讀取。
創建Database。
在Paimon Catalog中,所有表都歸屬于特定的Database內。您可以創建Database來管理表。
catalog.create_database( name='database_name', ignore_if_exists=True, # 是否忽略Database已存在的錯誤 properties={'key': 'value'} # Database參數(可選) )創建Schema。
Schema包含列定義、分區鍵、主鍵、表參數和注釋。其中,列定義使用
pyarrow.Schema描述,而其余參數均為可選項。可通過以下兩種方式構建pyarrow.Schema。重要為了確保兼容性,列定義應使用小寫。因為在DLF中,列名會被自動轉換成小寫形式。否則,在查詢時可能會因為找不到對應的列而報錯。
PyArrow
使用
pyarrow.schema方法。示例如下。import pyarrow as pa from pypaimon import Schema pa_schema = pa.schema([ ('date', pa.string()), ('hour', pa.string()), ('key', pa.int64()), ('value', pa.string()) ]) schema = Schema( pa_schema=pa_schema, partition_keys=['date', 'hour'], primary_keys=['date', 'hour', 'key'], options={'bucket': '2'}, comment='my test table' )說明pyarrow和Paimon的數據類型映射,請參見PyPaimon數據類型映射。Pandas
如果您有pandas數據,也可以直接從
pandas.DataFrame中獲取。示例如下。import pandas as pd import pyarrow as pa from pypaimon import Schema # 這里是示例DataFrame數據 data = { 'date': ['2024-12-01', '2024-12-01', '2024-12-02'], 'hour': ['08', '09', '08'], 'key': [1, 2, 3], 'value': ['AAA', 'BBB', 'CCC'], } dataframe = pd.DataFrame(data) # 從DataFrame中獲取pyarrow.Schema record_batch = pa.RecordBatch.from_pandas(dataframe) pa_schema = record_batch.schema schema = Schema( pa_schema=pa_schema, partition_keys=['date', 'hour'], primary_keys=['date', 'hour', 'key'], options={'bucket': '2'}, comment='my test table' )創建并獲取Table。
catalog.create_table( identifier='database_name.table_name', schema=schema, ignore_if_exists=True # 是否忽略表已存在的錯誤 ) table = catalog.get_table('database_name.table_name')
寫入表數據
當前PyPaimon不支持寫bucket=-1的主鍵表。
創建Table寫入與提交操作。
# 創建 table write and commit write_builder = table.new_batch_write_builder() table_write = write_builder.new_write() table_commit = write_builder.new_commit() # 寫入Pandas示例數據 data = { 'date': ['2024-12-01', '2024-12-01', '2024-12-02'], 'hour': ['08', '09', '08'], 'key': [1, 2, 3], 'value': ['AAA', 'BBB', 'CCC'], }您可通過以下兩種方式寫入表數據:
在處理大規模數據集時,推薦使用PyArrow;而對于較小規模的數據(通常指幾GB以下),Pandas則能更高效地進行處理。
PyArrow
支持
pyarrow.Table和pyarrow.RecordBatch兩種方式。其中,pyarrow.RecordBatch更適合用于流式處理場景。方式一:寫入pyarrow.Table
# 創建字段 fields = [ pa.field('date', pa.string()), pa.field('hour', pa.string()), pa.field('key', pa.int64()), pa.field('value', pa.string()) ] # 使用數據和字段創建 Schema schema = pa.schema(fields) # 創建 Table pa_table = pa.Table.from_arrays(data, schema) # 寫入數據 table_write.write_arrow(pa_table)方式二:寫入pyarrow.RecordBatch
# 創建字段 fields = [ pa.field('date', pa.string()), pa.field('hour', pa.string()), pa.field('key', pa.int64()), pa.field('value', pa.string()) ] # 使用數據和字段創建 Schema schema = pa.schema(fields) # 創建 RecordBatch record_batch = pa.RecordBatch.from_arrays(data, schema) # 寫入數據 table_write.write_arrow_batch(record_batch)
Pandas
支持寫入pandas.DataFrame。
import pandas as pd dataframe = pd.DataFrame(data) table_write.write_pandas(dataframe)提交數據并關閉資源。
# 提交數據 table_commit.commit(table_write.prepare_commit()) # 關閉資源 table_write.close() table_commit.close()
讀取表數據
創建ReadBuilder,構建讀數據工具。
read_builder = table.new_read_builder()使用PredicateBuilder來構建和下推篩選條件。
支持條件篩選,例如您只想查詢date = 2024-12-01的數據。
predicate_builder = read_builder.new_predicate_builder() predicate = predicate_builder.equal('date', '2024-12-01') read_builder = read_builder.with_filter(predicate)支持篩選特定列,例如您只想查詢 key和value兩列。
read_builder = read_builder.with_projection(['key', 'value'])
說明更多支持的篩選條件,參見PyPaimon篩選條件。
獲取
splits。table_scan = read_builder.new_scan() splits = table_scan.plan().splits()將
splits轉換為多種數據格式。Apache Arrow
您可以把所有數據讀到
pyarrow.Table中。table_read = read_builder.new_read() pa_table = table_read.to_arrow(splits) print(pa_table) # 輸出示例: # pyarrow.Table # key: int64 not null # value: string # ---- # key: [[2],[1]] # value: [["BBB"],["AAA"]]也可以將數據讀到
pyarrow.RecordBatchReader并迭代讀取。table_read = read_builder.new_read() for batch in table_read.to_arrow_batch_reader(splits): print(batch) # 輸出示例: # pyarrow.RecordBatch # key: int64 # value: string # ---- # key: [1,2] # value: ["AAA","BBB"]
Pandas
您可以將數據讀到
pandas.DataFrame中。table_read = read_builder.new_read() df = table_read.to_pandas(splits) print(df) # 輸出示例: # key value # 0 1 AAA # 1 2 BBBDuckDB
重要需要安裝DuckDB,可通過
pip install duckdb安裝。您可以將數據轉換為一個in-memory的DuckDB table并查詢。
table_read = read_builder.new_read() duckdb_con = table_read.to_duckdb(splits, 'duckdb_table') print(duckdb_con.query("SELECT * FROM duckdb_table").fetchdf()) # 輸出示例: # key value # 0 1 AAA # 1 2 BBB print(duckdb_con.query("SELECT * FROM duckdb_table WHERE key = 1").fetchdf()) # 輸出示例: # key value # 0 1 AAARay
重要需要安裝Ray,可通過
pip install ray安裝。table_read = read_builder.new_read() ray_dataset = table_read.to_ray(splits) # 打印ray_dataset的信息 print(ray_dataset) # 輸出示例: # MaterializedDataset(num_blocks=1, num_rows=2, schema={key: int64, value: string}) # 打印ray_dataset中的前兩個元素 print(ray_dataset.take(2)) # 輸出示例: # [{'key': 1, 'value': 'AAA'}, {'key': 2, 'value': 'BBB'}] # 將整個ray_dataset轉換為Pandas DataFrame格式后打印 print(ray_dataset.to_pandas()) # 輸出示例: # key value # 0 1 AAA # 1 2 BBB
常見問題
Q:在安裝JRE時,執行apt install openjdk-8-jre失敗,報錯如下,應如何處理?
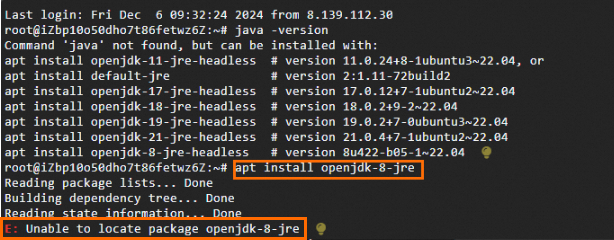
A:先執行apt update更新軟件包,再執行apt install openjdk-8-jre進行安裝。