開發人員在基于GitHub開源項目進行開發時會產生海量事件,GitHub會記錄每次事件的類型、詳情、開發者和代碼倉庫等信息,并開放其中的公開事件。DataWorks提供“Github十大熱門編程語言”模板,通過對GitHub中公開數據集進行加工和分析,并將分析結果以郵箱的方式發送給指定用戶。運行本案例后,您將得到Github中Top10編程語言每小時被提交的次數與排行。
手動配置與實際應用中的ETL模板在工作流細節上存在一定差異,但兩者實現的案例效果大體相同。
案例說明
DataWorks為您提供了一個公共的MySQL數據源,存儲來自Github的公開實時數據,本案例將此數據進行同步分析,最終將分析結果通過郵件發送至指定郵箱。主要業務過程如下:
通過DataWorks的數據集成功能,將MySQL上的Github實時數據同步至MaxCompute。
將同步至MaxCompute的數據進行分析處理,查詢獲取過去1小時Github中Top10的代碼語言及提交次數,并將處理結果存儲于阿里云OSS。
在函數計算中開發一個Python函數,函數邏輯為將OSS中的處理結果發送至指定郵箱。
通過DataWorks的任務調度能力,實現過去1小時Github熱門編程語言數據自動更新,并將數據處理結果發送至指定郵箱。
操作步驟
ETL模板配置
本實驗中的,任務代碼可以通過ETL工作流模板一鍵導入,直接體驗。在導入模板后,您可以前往目標工作空間,并自行完成任務運維等后續操作。
僅空間管理員角色可導入ETL模板至目標工作空間,為賬號授權空間管理員角色詳情請參見空間級模塊權限管控。
導入ETL工作流模板,詳情請參見ETL工作流快速體驗。
ETL工作流模板快捷入口,請點擊GitHub十大熱門編程語言。
前置準備
進行本案例前,請務必確保已完成以下操作:
建議開通以下云產品時選擇同一地域,本文以上海地域為例。
如果您此前未使用過阿里云以下產品,可前往DataWorks免費試用、MaxCompute免費試用、函數計算免費試用、OSS免費試用申請免費試用資源。
開通大數據開發治理平臺DataWorks并創建工作空間。本文以創建標準模式工作空間為例,標準模式和簡單模式工作區間區別請參見簡單模式和標準模式的區別。
確保當前賬號已授予
AliyunOSSFullAccess(對象存儲OSS)和AliyunFCFullAccess(函數計算FC)權限。詳細操作,請參見查看RAM用戶的權限、為RAM用戶授權。
步驟一:登錄并進入指定工作區間
登錄DataWorks控制臺。
在頂部左上角根據實際情況選擇地域。
在左側導航欄選擇工作空間,單擊指定工作空間名稱,進入工作空間詳情頁。
步驟二:創建MaxCompute數據源并綁定到數據開發
在左側導航欄選擇管理中心,進入管理中心配置頁面。
在左側導航欄選擇數據源。
單擊新增數據源,選擇數據源類型為MaxCompute,根據界面提示創建MaxCompute數據源。
進入>,找到已創建的MaxCompute數據源,進行綁定操作。
步驟三:創建OSS數據源
在左側導航欄選擇管理中心,進入管理中心配置頁面。
在左側導航欄選擇數據源。
單擊新增數據源,選擇數據源類型為OSS,創建OSS數據源。
參數
說明
數據源名稱
輸入數據源名稱,以字母開頭,由大小寫字母、數字、下劃線(_)組成,最多60個字符。
數據源描述
對數據源進行簡單描述,最多80個字符。
適用環境
本文以使用標準模式工作空間為例,此處選中開發和生產。
Endpoint
本文以上海地域為例,此處輸入
http://oss-cn-shanghai.aliyuncs.com。其他地域Endpoint請參見OSS地域和訪問域名。Bucket
輸入OSS Bucket。如果沒有可用的Bucket,請創建Bucket。
訪問模式
RAM角色授權模式
Access Key模式
選擇角色
當訪問模式為RAM角色授權模式,選擇RAM角色,詳情請參見通過RAM角色授權模式配置數據源。
AccessKey ID
當訪問模式為Access Key模式,需輸入AccessKey信息,詳情請參見查看RAM用戶的AccessKey信息。
AccessKey Secret
資源組連通性
在數據集成頁簽下,單擊已綁定的數據集成資源組操作列測試連通性,等待界面提示測試完成,連通狀態列顯示為可連通。
步驟四:配置案例
在DataWorks控制臺左側導航欄選擇大數據體驗 > ETL工作流模板,單擊Github十大熱門編程語言模板,單擊載入模板,配置模板參數。
參數 | 說明 |
模板名稱 | 顯示當前模板名稱,即“Github十大熱門編程語言”。 |
工作空間 | 選擇前置準備中創建的DataWorks工作空間。 |
服務開通 | |
服務開通 | 本文涉及以下產品服務,請確保已全部開通。如果顯示未開通,請參見前置準備開通。
|
MaxCompute配置 | |
數據源類型 | 顯示當前數據源類型,即MaxCompute。 |
數據源名稱 | 選擇步驟二中創建的MaxCompute數據源。 |
OSS配置 | |
數據源類型 | 顯示當前數據源類型,即OSS。 |
數據源名稱 | 選擇步驟三中創建的OSS數據源。 |
Bucket名稱 | 顯示步驟三創建OSS數據源時配置的Bucket。 |
選擇文件夾 | 選擇上述Bucket下的目錄,用于存放加工后的數據。
|
完整路徑 | 顯示存放加工后數據的OSS路徑。 |
函數計算配置 | |
函數計算配置 | 首次配置時,單擊一鍵創建應用,本案例將在以下產品中創建對應的數據:
|
案例參數配置 | |
服務器地址 | 發送端服務器,格式為smtp.***.com,例如:smtp.163.com。 說明 以163郵箱為例,獲取服務器地址和端口號,請參見客戶端設置。 |
端口號 | 發送端服務器端口,例如:上述發送郵件服務器端口號為465。 |
用戶名 | 發送端用戶名,例如:發送郵箱為dw***_sender@163.com,則用戶名為dw***_sender。 |
密碼 | 發送端密碼,即發送端郵箱密碼。 |
郵件發送地址 | 發送端郵箱,例如:dw***_sender@163.com。 |
郵件接收地址 | 接收端郵箱,例如:dw***_receiver@126.com。 |
載入方式 | 首次配置時,本文將為您創建“Github十大熱門編程語言”業務流程,如果后續配置且該業務流程已經存在,則按以下方式載入:
|
參數配置完成后,單擊確認,進入業務流程頁面。
步驟五:調試工作流
單擊業務流程頁面頂部的運行按鈕,調試運行整個業務流程。
當界面提示運行完成后,您可登錄收取數據處理結果的郵箱查看郵件。
手動配置
資源準備
進行本實踐前,您需先開通涉及的阿里云產品并完成以下準備工作。
建議將以下涉及的云產品開通在同一地域,本文以均開通在上海地域為例。
如果您此前未使用過阿里云的以下產品,可申請免費試用資源免費使用,詳情請前往DataWorks免費試用、MaxCompute免費試用、函數計算免費試用、OSS免費試用。
開通大數據開發治理平臺DataWorks并創建工作空間(本實踐以使用標準模式工作空間為例,簡單模式的操作類似)。操作詳情請參見開通DataWorks服務、創建工作空間。
開通云原生大數據計算服務MaxCompute,并創建MaxCompute項目。操作詳情請參見開通MaxCompute和DataWorks。
開通函數計算FC。操作詳情請參見步驟一:開通函數計算服務。
開通對象存儲OSS并創建OSS Bucket。操作詳情請參見控制臺快速入門、步驟一:創建存儲空間。
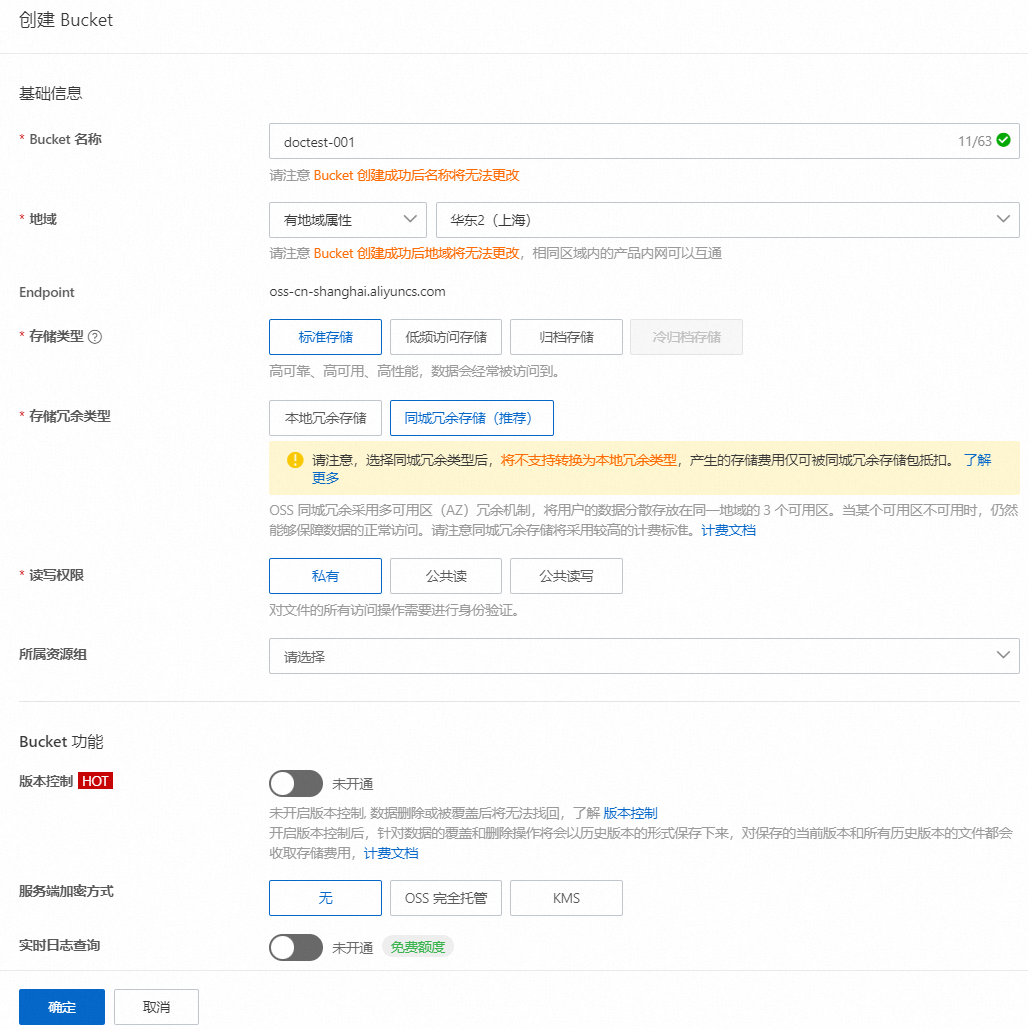
OSS側操作:創建OSS Bucket
登錄OSS控制臺,在Bucket列表頁面單擊創建Bucket,配置Bucket名稱和地域后單擊確定,創建OSS Bucket。
函數計算側操作:創建并開發函數
登錄函數計算控制臺創建服務并為服務添加OSS權限。
由于后續開發的函數代碼邏輯需要讀取OSS Bucket中的數據并將數據發送至指定郵箱,因此需給函數計算的服務授予OSS的權限。
在右上角單擊返回函數計算2.0,返回至函數計算2.0的工作臺頁面。
在函數計算2.0頁面,切換至服務及函數頁面,并在左上角切換地域,單擊創建服務,配置服務名稱后單擊確定。
單擊創建好的服務,單擊左側服務詳情,在角色配置區域單擊編輯,選擇服務角色AliyunFcDefaultRole,單擊保存,回到服務詳情頁簽,在角色配置區域單擊服務角色AliyunFcDefaultRole,進入RAM訪問控制的角色頁面。
單擊新增授權,選擇系統策略中的AliyunOSSReadOnlyAccess權限,根據界面提示進行添加。完成后即給函數計算服務授予了OSS的讀權限。
創建函數并開發函數邏輯。
創建函數。
回到函數計算中創建的服務頁面,單擊左側函數管理頁簽,單擊創建函數,配置函數名稱,并選擇運行環境為Python3.9,其他參數可保持默認值,完成后單擊創建。
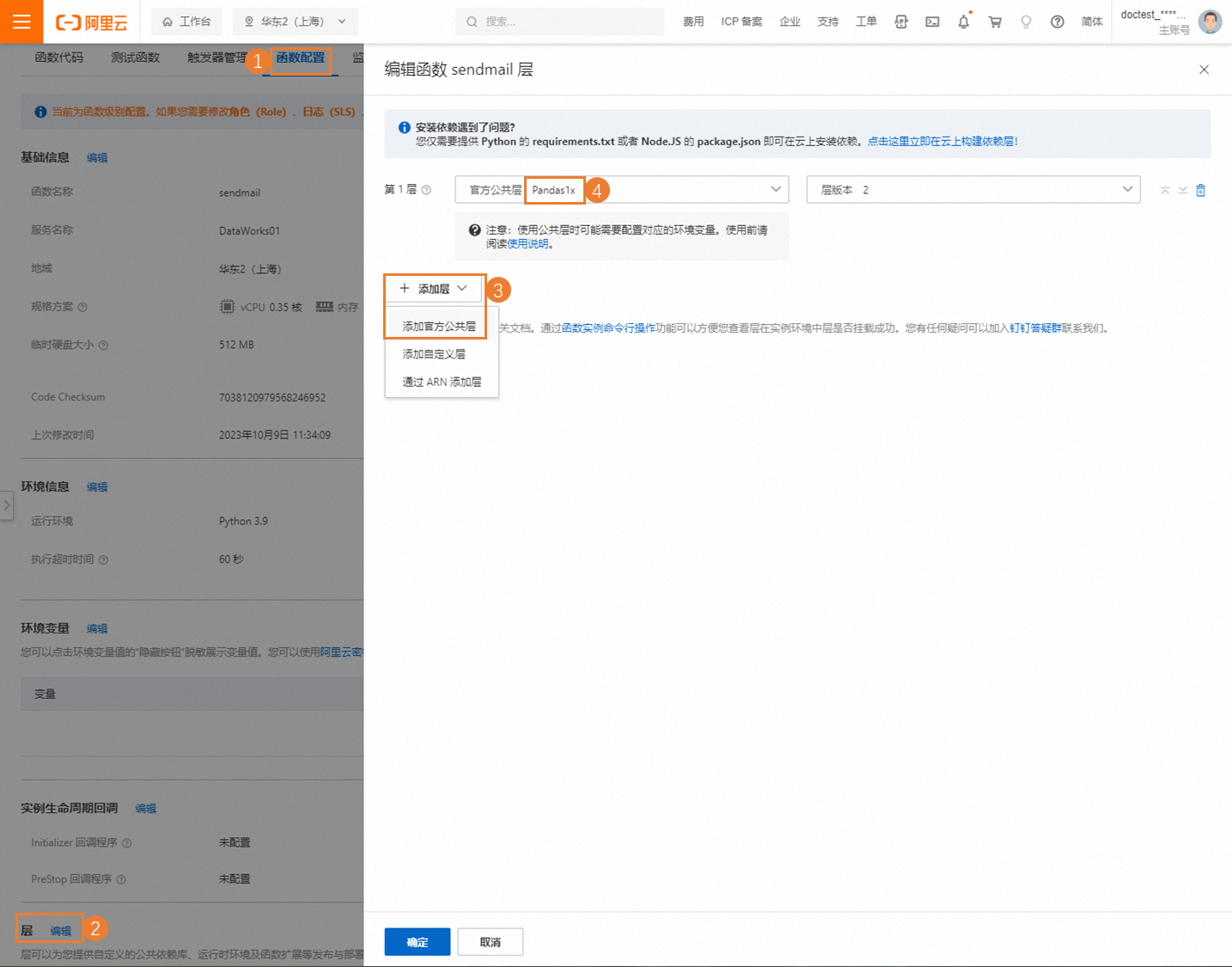
為函數環境安裝相關依賴包。
說明本實踐需使用oss2阿里云二方包和pandas開源三方包。其中oss2包 python3.9 runtime內置支持無需手動安裝,您需參考以下步驟手動安裝panadas包。
單擊創建好的函數,在函數頁面的函數配置頁簽中,單擊層配置區域后的編輯,單擊添加層,選擇添加官方公共層后,選擇Pandas1.x,完成后單擊確定。
回到函數頁面后,單擊函數代碼頁簽,當WebIDE的Python環境加載完成后,復制以下代碼至Index.py文件中,并修改其中的OSS內網Endpoint參數、郵箱相關參數。
# -*- coding: utf-8 -*- import logging import json import smtplib import oss2 import pandas as pd from email.mime.text import MIMEText from email.mime.multipart import MIMEMultipart from email.mime.base import MIMEBase from email.mime.text import MIMEText from email.utils import COMMASPACE from email import encoders def handler(event, context): evts = json.loads(event) bucket_name = evts["bucketName"] file_path = evts["filePath"] auth = oss2.StsAuth(context.credentials.access_key_id, context.credentials.access_key_secret, context.credentials.security_token) endpoint = 'https://oss-{}-internal.aliyuncs.com'.format(context.region) bucket = oss2.Bucket(auth, endpoint, bucket_name) file_name = file_path for obj in oss2.ObjectIteratorV2(bucket, prefix=file_path): if not obj.key.endswith('/'): file_name = obj.key csv_file = bucket.get_object(file_name) logger = logging.getLogger() logger.info('event: %s', evts) mail_host = 'smtp.***.com' ## 郵箱服務地址 mail_port = '465'; ## 郵箱smtp協議端口號 mail_username = 'sender_****@163.com' ## 身份認證用戶名:填完整的郵箱名 mail_password = 'EWEL******KRU' ## 身份認證密碼:填郵箱 SMTP 授權碼 mail_sender = 'sender_****@163.com' ## 發件人郵箱地址 mail_receivers = ['receiver_****@163.com'] ## 收件人郵箱地址 message = MIMEMultipart('alternative') message['Subject'] = 'Github數據加工結果' message['From'] = mail_sender message['To'] = mail_receivers[0] html_message = generate_mail_content(evts, csv_file) message.attach(html_message) # Send email smtpObj = smtplib.SMTP_SSL(mail_host + ':' + mail_port) smtpObj.login(mail_username,mail_password) smtpObj.sendmail(mail_sender,mail_receivers,message.as_string()) smtpObj.quit() return 'mail send success' def generate_mail_title(evt): mail_title='' if 'mailTitle' in evt.keys(): mail_content=evt['mailTitle'] else: logger = logging.getLogger() logger.error('msg not present in event') return mail_title def generate_mail_content(evts, csv_file): headerList = ['Github Repos', 'Stars'] # Read csv file content dumped_file = pd.read_csv(csv_file, names=headerList) # Convert DataFrame to HTML table table_html = dumped_file.to_html(header=headerList,index=False) # Convert DataFrame to HTML table table_html = dumped_file.to_html(index=False) mail_title=generate_mail_title(evts) # Email body html = f""" <html> <body> <h2>{mail_title}</h2> <p>Here are the top 10 languages on GitHub in the past hour:</p> {table_html} </body> </html> """ # Attach HTML message html_message = MIMEText(html, 'html') return html_message說明示例代碼中使用到了bucketName、filePath、mailTitle這三個變量,此三個變量的取值后續通過DataWorks的函數計算節點同步取值,無需在代碼中修改。
待修改參數
配置指導
OSS內網Endpoint
(第20行)
根據您當前操作的地域,將其中的
'https://oss-{}-internal.aliyuncs.com'替換為OSS的內網Endpoint取值。以上海地域為例,需修改參數為
'https://oss-cn-shanghai-internal.aliyuncs.com'。各地域的OSS內網Endpoint信息請參見OSS地域和訪問域名。
郵箱相關參數
(31~36行)
根據實際業務需要:
修改31~35行為后續發送郵件郵箱服務地址、smtp協議端口號、郵箱用戶名及密碼等信息。
修改36行為后續接收郵件的郵箱地址。
說明您可在您使用的郵箱幫助文檔中查看如何獲取相關取值。以163郵箱為例,您可以參考SMTP服務器是什么、如何使用授權碼獲取相關信息。
完成代碼開發后,單擊部署代碼。
DataWorks側操作:創建數據源并綁定計算引擎
創建MySQL數據源。
本實踐使用的公共Github數據存儲在公共的MySQL數據庫中,您需要先創建一個MySQL數據源,用于后續同步數據至MaxCompute時對接MySQL數據庫。
進入數據源頁面。
登錄DataWorks控制臺,切換至目標地域后,單擊左側導航欄的,在下拉框中選擇對應工作空間后單擊進入管理中心。
進入工作空間管理中心頁面后,單擊左側導航欄的,進入數據源頁面。
單擊新增數據源,選擇數據源類型為MySQL,根據界面提示配置數據源名稱等參數,核心參數如下。
參數
說明
數據源類型
選擇連接串模式。
數據源名稱
自定義。本文以github_events_share為例。
JDBC URL
配置為:jdbc:mysql://rm-bp1z69dodhh85z9qa.mysql.rds.aliyuncs.com:3306/github_events_share
重要該數據源僅支持數據同步場景去讀取使用,其他模塊不支持。
用戶名
配置為:workshop
密碼
配置為:workshop#2017
此密碼僅為本教程示例,請勿在實際業務中使用。
認證選項
無認證。
資源組連通性
單擊數據集成公共資源組后的測試連通性,等待界面提示測試完成,連通狀態為可連通。
創建MaxCompute數據源。
后續需將Github數據同步至MaxCompute,因此您需創建一個MaxCompute數據源。
進入數據源頁面。
登錄DataWorks控制臺,切換至目標地域后,單擊左側導航欄的,在下拉框中選擇對應工作空間后單擊進入管理中心。
進入工作空間管理中心頁面后,單擊左側導航欄的,進入數據源頁面。
單擊新增數據源,選擇數據源類型為MaxCompute,根據界面提示配置數據源名稱、對應的MaxCompute項目等參數,詳細請參見創建MaxCompute數據源。
綁定MaxCompute數據源為計算引擎。
后續需創建一個MaxCompute的SQL任務進行數據處理,因此您需要將MaxCompute數據源綁定為DataWorks的計算引擎,便于后續創建ODPS SQL節點進行SQL任務開發。
進入管理中心頁面。
登錄DataWorks控制臺,切換至目標地域后,單擊左側導航欄的管理中心,在下拉框中選擇對應工作空間后單擊進入管理中心。
單擊計算引擎信息頁簽,在MaxCompute頁簽下單擊數據開發-數據源,選擇上述步驟中創建好的MaxCompute數據源。進行綁定操作。綁定后,才能基于數據源的連接信息讀取該數據源的數據,進行后續操作。
說明當數據源信息發生變更時,若當前界面數據更新不及時,請刷新當前頁面更新緩存數據。
DataWorks側操作:創建業務流程并開發數據處理任務
進入數據開發頁面。
登錄DataWorks控制臺,切換至目標地域后,單擊左側導航欄的,在下拉框中選擇對應工作空間后單擊進入數據開發。
創建業務流程。
單擊左上角的,配置業務名稱后單擊新建。
創建業務節點并配置依賴關系。
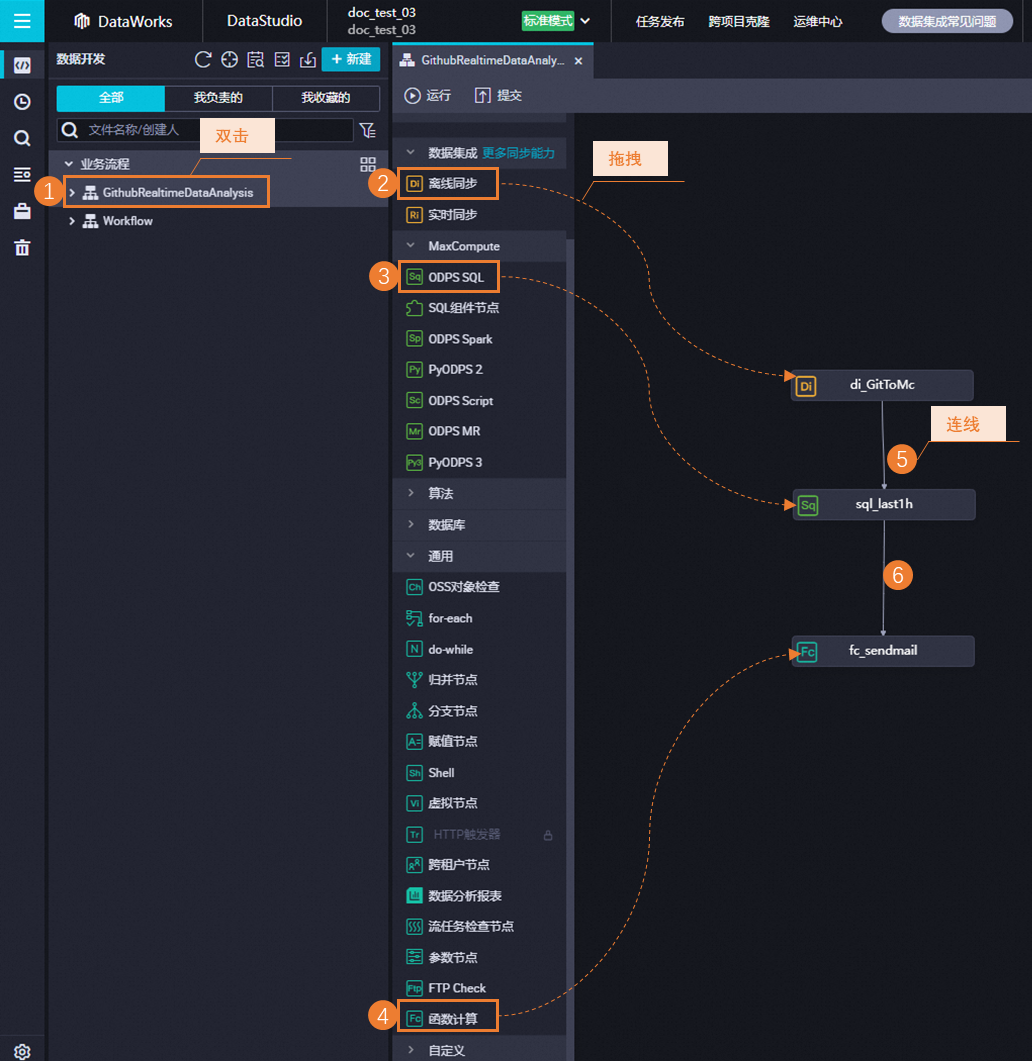
雙擊創建的業務名稱,打開業務流程頁面。
在業務流程頁面單擊新建節點,拖拽離線同步節點進業務流程頁面,配置節點名稱后單擊確認,創建一個離線同步節點。
重復上述步驟,再創建一個ODPS SQL節點、函數計算節點。
配置離線同步節點。
雙擊業務流程中創建的離線同步節點,進入離線同步節點頁面。
配置離線同步任務的網絡與資源。
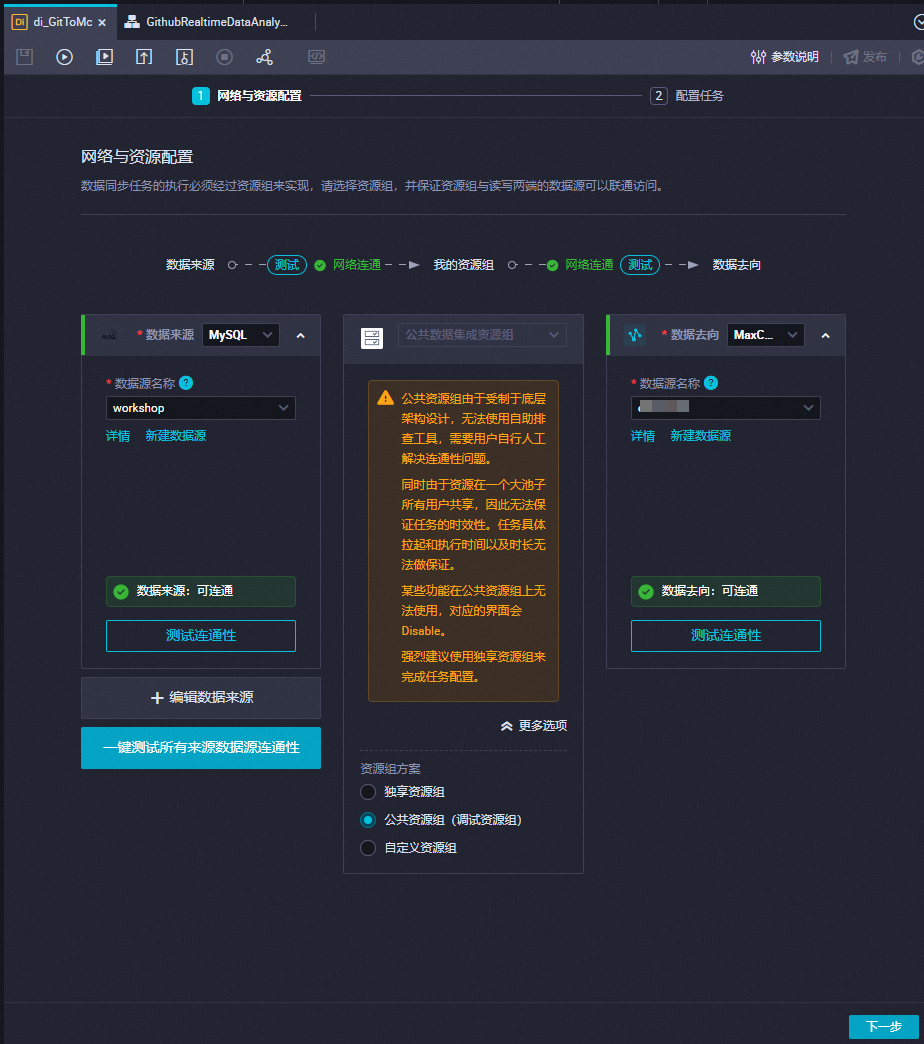
配置項
配置說明
數據來源
選擇數據來源為MySQL,數據源選擇上述步驟創建的MySQL數據源。
數據去向
選擇數據去向為MaxCompute,數據源選擇已創建的MaxCompute數據源。
我的資源
選擇右下角的。
完成后單擊下一步,根據界面提示完成網絡連通測試。
配置離線同步任務,核心參數如下,其他參數可保持默認。
配置項
配置說明
數據來源
表:在下拉框中選擇github_public_event。
數據過濾:配置為
created_at >'${day1} ${hour1}' and created_at<'${day2} ${hour2}'
數據去向
表:單擊一鍵生成目標表結構,在彈框中單擊新建表。
分區信息:配置為
pt=${day_hour}。
單擊頁面右側的調度配置,配置調度參數,核心參數如下,其他參數可保持默認。
配置項
配置說明
調度參數
單擊加載代碼中的參數,新增以下五個參數并配置參數的取值邏輯如下:
day1:$[yyyy-mm-dd-1/24]hour1:$[hh24-1/24]day2:$[yyyy-mm-dd]hour2:$[hh24]day_hour:$[yyyymmddhh24]
時間屬性
調度周期:配置為小時
重跑屬性:配置為運行成功或失敗后皆可重跑
調度依賴
勾選使用工作空間根節點
單擊右上角的保存按鈕,保存節點配置。
配置ODPS SQL節點。
雙擊業務流程中創建的ODPS SQL節點,進入ODPS SQL節點頁面。
將以下示例代碼貼入節點中。
重要以下示例代碼創建了一個OSS外部表,用于存儲處理后的數據。如果您是首次使用OSS外部表,您還需對當前操作賬號進行授權,否則后續業務流程運行會報錯,授權操作請參見OSS的STS模式授權。
-- 1. 創建odps的oss外部表用于接收Github公共數據集數據加工結果。 -- 本案例創建的oss外表為odps_external,存放于在步驟1創建的OSS Bucket,本案例OSS Bucket名為xc-bucket-demo2,您需要根據實際情況進行修改。 CREATE EXTERNAL TABLE IF NOT EXISTS odps_external( language STRING COMMENT 'repo全名:owner/Repository_name', num STRING COMMENT '提交次數' ) partitioned by ( direction string ) STORED BY 'com.aliyun.odps.CsvStorageHandler' WITH SERDEPROPERTIES( 'odps.text.option.header.lines.count'='0', 'odps.text.option.encoding'='UTF-8', 'odps.text.option.ignore.empty.lines'='false', 'odps.text.option.null.indicator'='') LOCATION 'oss://oss-cn-shanghai-internal.aliyuncs.com/${YOUR_BUCKET_NAME}/odps_external/'; -- 2. 對同步MaxCompute的GitHub數據加工后寫入MaxCompute的oss外表。 -- 查詢獲取過去1小時Github中Top10的代碼語言及提交次數 SET odps.sql.unstructured.oss.commit.mode=true; INSERT INTO TABLE odps_external partition (direction='${day_hour}') SELECT language, COUNT(*) AS num FROM github_public_event WHERE language IS NOT NULL AND pt='${day_hour}' GROUP BY language ORDER BY num DESC limit 10;單擊頁面右側的調度配置,配置調度參數,核心參數如下,其他參數可保持默認。
配置項
配置說明
調度參數
單擊加載代碼中的參數,新增以下幾個參數并配置參數的取值邏輯:
YOUR_BUCKET_NAME:參數值為上述步驟中創建的OSS Bucket名稱。day_hour:$[yyyymmddhh24]
時間屬性
調度周期:配置為小時
重跑屬性:配置為運行成功或失敗后皆可重跑
單擊右上角的保存按鈕,保存節點配置。
配置函數計算節點。
雙擊業務流程中創建的函數計算節點,進入函數計算節點頁面。
配置函數計算節點任務。
配置項
配置說明
選擇服務
選擇上述步驟在函數計算控制臺中創建的服務。
選擇函數
選擇上述步驟在函數計算控制臺中創建的函數。
調用方式
選擇同步。
變量
配置為以下內容。
{ "bucketName": "${YOUR_BUCKET_NAME}", "filePath": "odps_external/direction=${day_hour}/", "mailTitle":"過去1小時Github中Top10的代碼語言及其提交次數" }單擊頁面右側的調度配置,配置調度參數,核心參數如下,其他參數可保持默認。
配置項
配置說明
調度參數
單擊新增參數,新增以下幾個參數并配置參數的取值邏輯如下:
YOUR_BUCKET_NAME:參數值為上述步驟中創建的OSS Bucket名稱。day_hour:$[yyyymmddhh24]
時間屬性
調度周期:配置為小時
重跑屬性:配置為運行成功或失敗后皆可重跑
單擊右上角的保存按鈕,保存節點配置。
DataWorks側:調試工作流
在DataWorks數據開發頁面雙擊創建的業務名稱,打開業務流程頁面。
單擊頂部的運行按鈕,調試運行整個業務流程。
當界面提示運行完成后,您可登錄收取數據處理結果的郵箱查看郵件。
DataWorks側:提交發布工作流
(可選)后續如果您希望周期性同步數據至MaxCompute進行處理,并周期性發送處理結果到指定郵箱,您需要將業務流程提交發布至DataWorks的運維中心。
在數據開發頁面,雙擊創建的業務名稱,打開業務流程頁面。
單擊業務流程頁面的提交按鈕,根據界面提示將業務流程提交發布至運維中心,操作詳情請參見發布任務。
后續業務流程即會根據配置的調度周期,周期性運行。
后續步驟:釋放資源
如果您使用的是免費試用資源,或后續您不需要繼續使用此實踐的云產品,可釋放對應的云產品資源,避免產生額外費用。
釋放OSS資源:前往OSS控制臺刪除本案例使用的Bucket。
釋放函數計算資源:前往函數計算控制臺刪除服務。
釋放DataWorks資源:前往DataWorks控制臺刪除DataWorks工作空間。
釋放MaxCompute資源:前往MaxCompute控制臺刪除MaxCompute項目。