本案例將以視頻社交平臺的'猜你喜歡'和'詳情頁相關推薦'為例,通過推薦算法為用戶呈現最符合其興趣的視頻內容為背景,為您介紹在DataWorks中如何使用阿里云PAI的協同過濾算法挖掘深層次的數據關聯性,實現視頻的個性化推薦。
背景信息
協同過濾算法是一種用于個性化推薦的技術,它可以基于用戶間的行為相似性或物品間的相似性為用戶推薦物。本案例中,I2I視頻相似度模型算法將通過調用阿里云PAI中的協同過濾算法etrec完成,更多召回和排序算法您可參考EasyRec。
請注意,實際的推薦算法應用比本案例要復雜得多,本案例僅旨在為初學者提供一個推薦算法的基礎教程。
注意事項
本案例提供的數據僅作為阿里云大數據開發治理平臺DataWorks數據應用體驗使用,所有數據均為模擬數據。
本案例可能會產生少量DataWorks調度費用、MaxCompute計算與存儲費用和PAI計算費用。收費詳情請參見DataWorks計費邏輯、MaxCompute計費邏輯、PAI Designer計費邏輯。
本案例通過命令建表,在實際開發中,您可通過DataWorks可視化功能創建,詳情請參見:創建并使用MaxCompute表。
本案例中的,數據開發部分任務可以通過ETL工作流模板一鍵導入。在導入模板后,您可以前往目標工作空間,并自行完成后續操作。
僅空間管理員角色可導入ETL模板至目標工作空間,為賬號授權空間管理員角色詳情請參見空間級模塊權限管控。
導入ETL工作流模板,詳情請參見ETL工作流快速體驗。
ETL工作流模板快捷入口,請點擊視頻個性化推薦(協同過濾)。
前提條件
已創建DataWorks工作空間,詳情請參見創建工作空間。
DataWorks工作空間已開啟調度PAI算法服務,若空間還未開啟調度PAI算法,您可前往管理中心開啟,詳情請參見:管理中心功能概覽。
已創建MaxCompute數據源并綁定至工作空間,詳情請參見創建MaxCompute數據源并綁定至工作空間。
相關概念
I2I(Item-to-Item):基于item之間的相關性來推薦其他item的內容推薦算法,本案例中item特指視頻。
U2I(User-to-Item):本案例中指用戶對item(視頻)的交互行為,如曝光、點擊、點贊。
U2I2I召回:結合了 U2I(User-to-Item)和 I2I(Item-to-Item)推薦邏輯的表,用于存儲推薦系統根據用戶歷史行為和物品相關性生成的召回列表。
召回(Recall):是推薦系統流程中的一步,它的目的是從大量候選物品中篩選出有可能對用戶感興趣的一個子集,本案例中物品特指視頻。
視頻交互方式(用戶行為事件/event):“視頻有曝光給用戶”(expr)、“用戶瀏覽了視頻"(click)、“用戶點贊了視頻“(praise)
實施策略
實施策略如下:
相似視頻挖掘(I2I):通過用戶的視頻交互行為數據挖掘視頻與視頻之間的相關性,您可基于此案例修改為您的數據來制作符合您業務場景的詳情頁相關內容推薦。
用戶興趣點發現(U2I):利用用戶的視頻交互歷史數據,并結合時間衰減效應確定其興趣點,即用戶已經表達過感興趣的視頻。
視頻個性化推薦構建與生成(U2I2I):基于興趣點,再通過I2I(Item-to-Item)相關度模型算法擴展感興趣的視頻范圍,精確計算用戶對視頻內容的興趣得分,并根據此生成個性化推薦列表,以滿足每位用戶的獨特偏好。
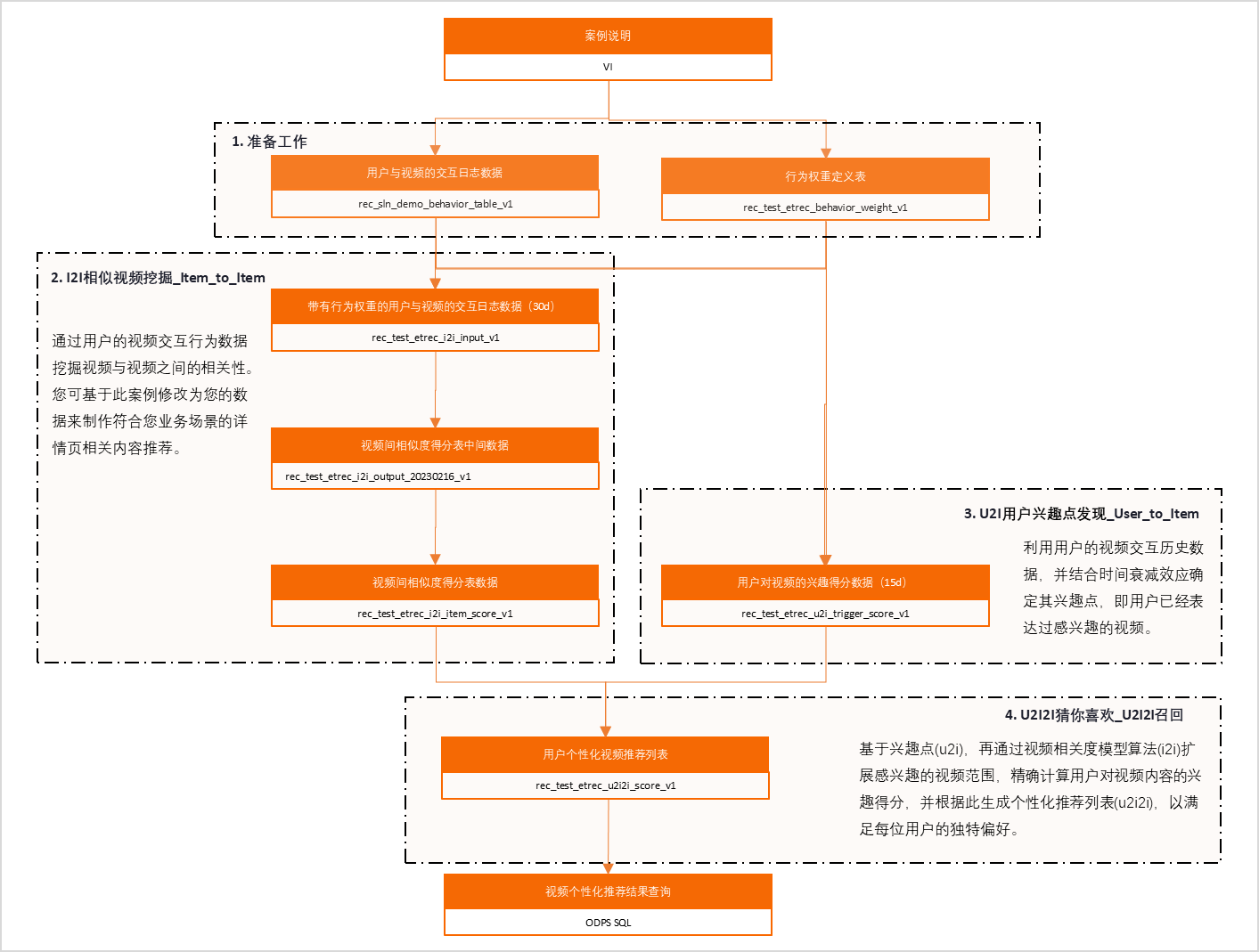
開發前準備
進入數據開發頁面。
登錄DataWorks控制臺,切換至目標地域后,單擊左側導航欄的,在下拉框中選擇對應工作空間后單擊進入數據開發。
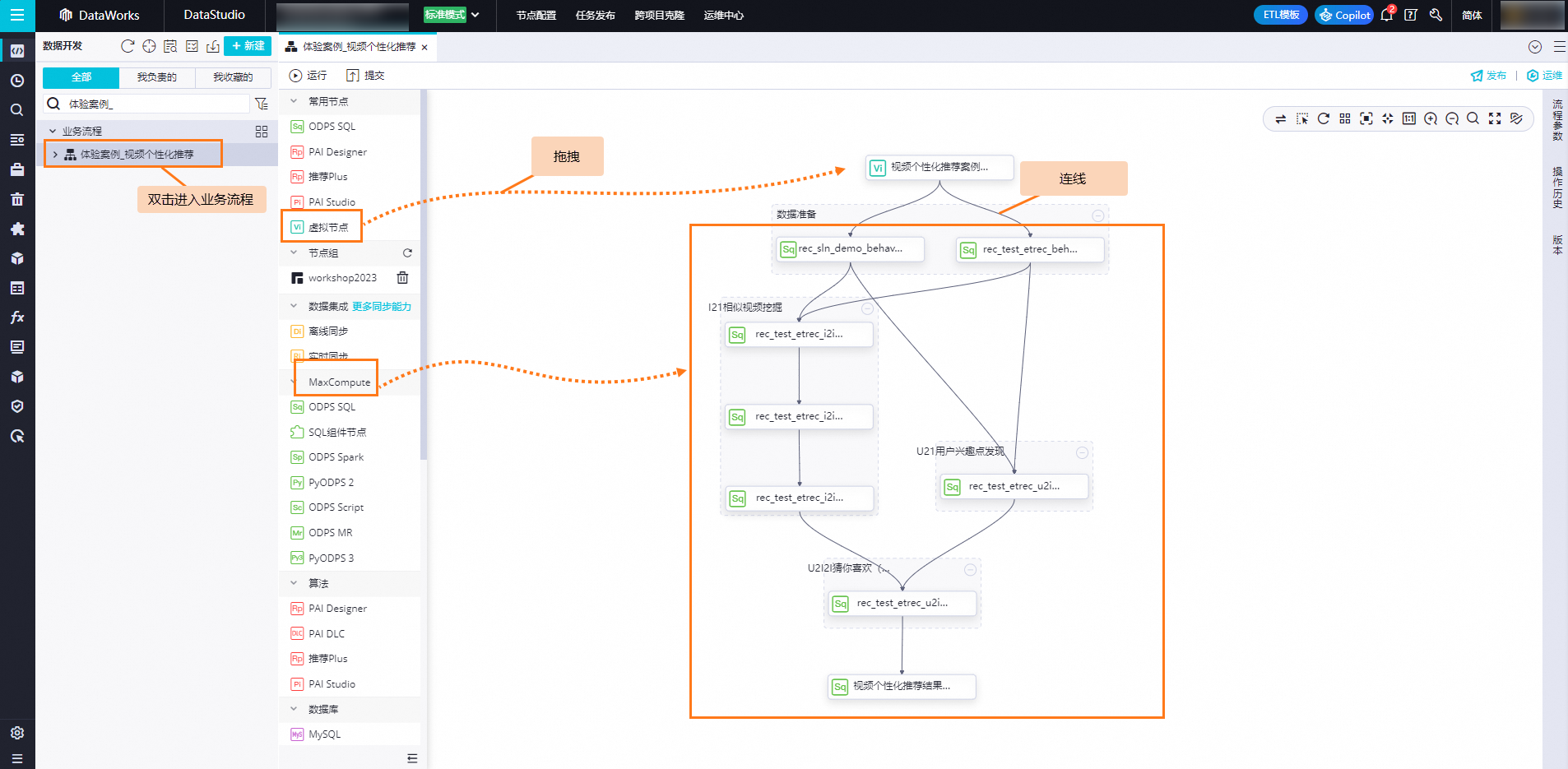
創建業務流程。
鼠標懸停至
 圖標,單擊新建業務流程。
圖標,單擊新建業務流程。在新建業務流程對話框中,輸入業務名稱和描述。本案例業務流程名為體驗案例_視頻個性化推薦。
單擊新建。
新建節點。
在左側目錄樹中,雙擊步驟2中創建的業務流程名稱,進入業務流程面板,并通過拖拽組件以及拉線的方式在業務流程畫布中編排整個流程。
本案例中會使用到兩個類型節點:虛擬節點和ODPS SQL節點。
虛擬節點將作為整個視頻個性化推薦業務流程的起始節點,用于管理整個業務流程;
ODPS SQL任務用于執行SQL任務數據計算及加工邏輯,其中視頻相似度計算將通過在ODPS SQL節點代碼中調用PAI-EasyRec算法服務實現。
任務流程圖預覽。
本案例預計將創建以下業務流程。其中,為便于快速辨別每一個任務加工邏輯,本案例使用節點組功能對節點進行分組,節點代碼請參照后續步驟。
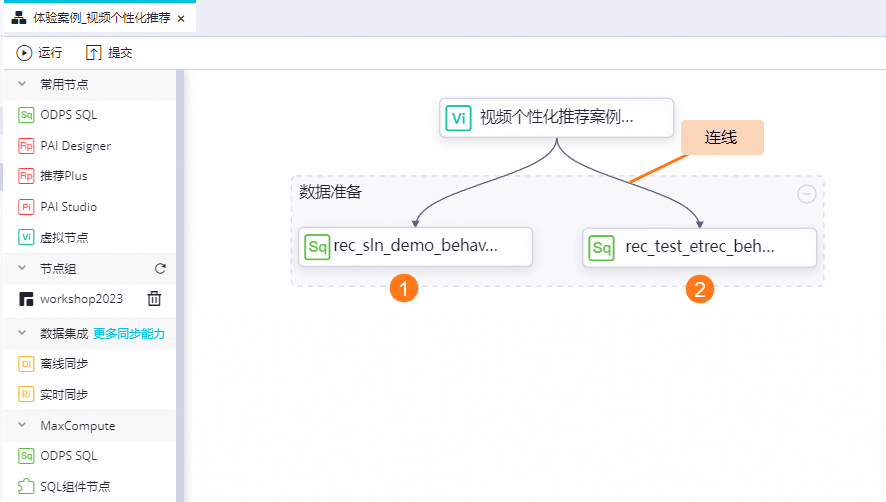
任務開發:數據準備
本階段需要創建一個虛擬節點和兩個ODPS SQL節點:
虛擬節點:
視頻個性化推薦案例說明。兩個ODPS SQL節點:
rec_sln_demo_behavior_table_v1和rec_test_etrec_behavior_weight_v1。
節點間的依賴關系,如下圖所示:
rec_sln_demo_behavior_table_v1
表數據:用戶與視頻的交互日志數據表,該表記錄了用戶對各個視頻內容的交互行為,每一行代表用戶每一次視頻交互記錄。
節點說明:當前案例需要最近30天的用戶與視頻的交互日志數據進行訓練,所以需要確保該表至少有30天的數據。阿里云PAI(公共數據集)已提供該數據,本節點將直接讀取后寫入。
在
rec_sln_demo_behavior_table_v1節點編輯頁面,輸入如下示例代碼:-- 表定義:“用戶與視頻的交互日志數據” -- 表數據:該表記錄了用戶對各個視頻內容的交互行為,每一行代表用戶每一次視頻交互記錄與權重。 CREATE TABLE IF NOT EXISTS rec_sln_demo_behavior_table_v1 ( request_id STRING COMMENT '埋點ID/請求ID' ,user_id STRING COMMENT '用戶唯一ID' ,exp_id STRING COMMENT '用戶唯一ID' ,page STRING COMMENT '頁面' ,net_type STRING COMMENT '網絡型號' ,event_time BIGINT COMMENT '行為時間' ,item_id STRING COMMENT '內容ID' ,event STRING COMMENT '行為類型' ,playtime DOUBLE COMMENT '播放時長/閱讀時長' ) COMMENT '視頻個性化推薦(協同過濾)-用戶與視頻的交互日志數據' PARTITIONED BY ( ds STRING ) LIFECYCLE 7 ; -- 用戶與視頻的交互日志數據準備,原始數據由阿里云PAI提供,可直接讀取。 INSERT OVERWRITE TABLE rec_sln_demo_behavior_table_v1 PARTITION (ds) SELECT * FROM pai_online_project.rec_sln_demo_behavior_table WHERE ds > "20221231" AND ds < "20230217" ;
rec_test_etrec_behavior_weight_v1
表數據:行為權重定義,用于記錄用戶行為事件(event)權重定義如下:
expr:視頻有曝光給用戶的行為,事件權重定義為0,即不考慮曝光事件。
click:用戶瀏覽了視頻的行為,權重定為1。
praise:用戶點贊視頻的行為,權重定為3。
節點說明:在實際訓練前,需要定義視頻瀏覽場景下各行為權重,將用戶對某視頻的不同行為,例如點贊、點擊等進行量化,以此幫助算法準確評估用戶對視頻內容的興趣強度。
在
rec_test_etrec_behavior_weight_v1節點編輯頁面,輸入如下示例代碼:-- 表定義: “行為權重定義表” CREATE TABLE IF NOT EXISTS rec_test_etrec_behavior_weight_v1 ( event STRING ,weight DOUBLE COMMENT '行為權重' ) COMMENT '視頻個性化推薦(協同過濾)-行為權重表' LIFECYCLE 7 ; -- 1. 數據寫入:本案例將"用戶瀏覽視頻"(click)行為權重定為“1”;將"用戶點贊視頻"(praise)行為權重定為"3",將"視頻有曝光給用戶"(expr)權重定義為0"。 -- 2. 業務意義:用戶與視頻的交互日志數據關聯該表后可為每個用戶的每一次交互(例如點贊、點擊等)賦予相應的權重,通過數值量化用戶不同行為幫助算法準確評估用戶對視頻內容的興趣強度。 INSERT OVERWRITE TABLE rec_test_etrec_behavior_weight_v1 VALUES ('expr',0.0) ,('click',1.0) ,('praise',3.0) ;
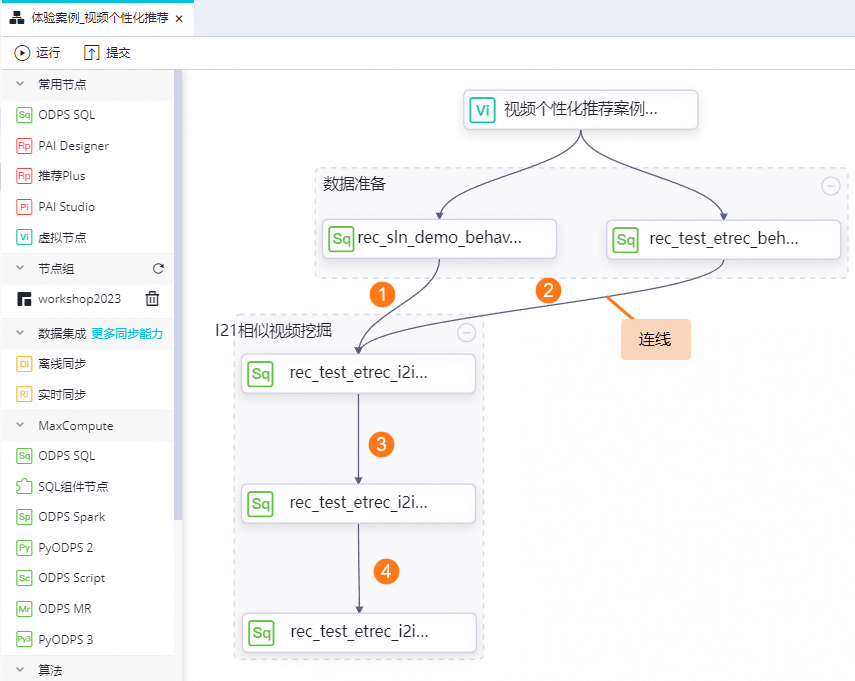
任務開發:相似視頻挖掘(I2I)
本階段需要創建三個ODPS SQL節點:
rec_test_etrec_i2i_input_v1節點。rec_test_etrec_i2i_output_20230216_v1節點。rec_test_etrec_i2i_item_score_v1節點。
節點間的依賴關系,如下圖所示:
rec_test_etrec_i2i_input_v1
表數據:帶有行為權重的用戶與視頻的交互日志數據表,該表記錄了用戶對各個視頻內容的交互行為,并通過預先定義的行為權重量化了這些行為。
節點說明:將過去30天內的用戶視頻訪問行為數據”rec_sln_demo_behavior_table_v1“與行為權重數據”rec_test_etrec_behavior_weight_v1“結合,生成帶有行為權重的用戶歷史偏好統計數據(即帶有量化了用戶對視頻的喜好程度的日志數據)寫入到"rec_test_etrec_i2i_input_v1"表最新分區,本案例以寫入20230216分區為例。
在
rec_test_etrec_i2i_input_v1節點編輯頁面,輸入如下示例代碼:-- 1. 表定義:“帶有行為權重的用戶與視頻的交互日志數據(30天)” -- 2. 表數據:該表記錄了用戶對各個視頻內容的交互行為,并通過預先定義的行為權重量化了這些行為。 -- 每一行代表用戶每一次視頻交互記錄與權重,即每條記錄通常代表一個用戶對一個視頻的單次行為(例如,一次查看視頻、一次點贊視頻等)。 -- 若用戶對同一個視頻存在多次行為,那么該表會存儲這個用戶對該視頻的多條行為記錄。 -- 3. 業務意義:該表將作為物品間相關度(Item-to-Item,I2I)推薦引擎的輸入數據,權重的引入可體現用戶對視頻不同行為 -- 在推薦系統中的影響力,可幫助算法準確評估用戶對視頻內容的興趣強度。 CREATE TABLE IF NOT EXISTS rec_test_etrec_i2i_input_v1 ( user_id STRING COMMENT '用戶ID' ,item_id STRING COMMENT '內容ID' ,event STRING COMMENT '行為類型' ,event_time BIGINT COMMENT '行為發生時間' ,weight DOUBLE COMMENT '行為權重' ) COMMENT '視頻個性化推薦(協同過濾)-帶有行為權重的用戶與視頻的交互日志數據' PARTITIONED BY ( ds STRING ) LIFECYCLE 7 ; -- 過去30天內的用戶與視頻的交互日志數據"rec_sln_demo_behavior_table_v1"與行為權重數據"rec_test_etrec_behavior_weight_v1"結合, -- 生成結合行為權重的歷史偏好統計數據寫入到rec_test_etrec_i2i_input_v1表最新分區,本案例以寫入20230216分區為例。 INSERT OVERWRITE TABLE rec_test_etrec_i2i_input_v1 PARTITION (ds = '20230216') SELECT CAST(sq0.user_id AS STRING) user_id ,CAST(sq0.item_id AS STRING) item_id ,sq0.event ,sq0.event_time ,sq1.weight FROM ( -- 獲取過去30天的用戶視頻訪問行為數據 SELECT * FROM rec_sln_demo_behavior_table_v1 WHERE ds > TO_CHAR(DATEADD(TO_DATE('20230216','yyyymmdd'),-30,'dd'),'yyyymmdd') AND ds <= '20230216' ) sq0 JOIN ( -- 去除"視頻有曝光給用戶"(expr)事件數據、保留"用戶瀏覽了視頻"(click)、"用戶點贊了視頻"(praise)的事件數據 SELECT * FROM rec_test_etrec_behavior_weight_v1 WHERE weight > 0 ) sq1 ON sq0.event = sq1.event ;
rec_test_etrec_i2i_output_20230216_v1
表數據:視頻間相關度得分臨時表,該表包含每個視頻內容與其他視頻內容之間的相關度得分,每一行記錄某個視頻與其相關度最高的N個視頻。
節點說明:使用阿里云PAI協同過濾算法PAI—eTrec,基于帶有行為權重的用戶與視頻的交互日志數據”rec_test_etrec_i2i_input_v1“計算視頻間相關度,得分數據寫入rec_test_etrec_i2i_output_20230216_v1表。
在
rec_test_etrec_i2i_output_20230216_v1節點編輯頁面,輸入如下示例代碼:-- 當前節點將產出"rec_test_etrec_i2i_output_20230216_v1"表數據 -- 1. 表定義:"視頻間相關度得分臨時表" -- 2. 表數據:該表包含每個視頻內容與其他視頻內容之間的相關度得分,每一行記錄某個視頻與其相關度最高的N個視頻。 -- 3. 業務意義:通過相關性度量方法來計算矩陣中視頻內容之間的相關性,這些得分由阿里云PAI提供的協同過濾算法PAI-eTrec根據用戶交互行為和設定的權重計算得出。 -- 刪除之前可能存在的以2023年2月16日為分區的item-to-item輸出表,以便本次算法運行可正常創建該表并往該表寫入數據。 DROP TABLE IF EXISTS rec_test_etrec_i2i_output_20230216_v1 ; -- 使用PAI命令進行item-to-item計算 -- 1. 數據流:使用阿里云PAI協同過濾算法PAI-eTrec,基于帶有行為權重的用戶與近30天用戶與視頻的交互日志數據"rec_test_etrec_i2i_input_v1"計算視頻間相關度,得分數據寫入表"rec_test_etrec_i2i_output_20230216_v1"。 -- 2. 其中,-DtopN代表每個視頻僅返回與之最相關的前100個視頻。更多參數說明,請參見:http://bestwisewords.com/document_detail/172063.html PAI -name pai_etrec -project algo_public -DinputTableName="rec_test_etrec_i2i_input_v1" -DinputTablePartitions="ds=20230216" -DuserColName="user_id" -DitemColName="item_id" -DsimilarityType="wbcosine" -DtopN="100" -DmaxUserBehavior="1000" -DminUserBehavior="2" -Doperator="add" -DitemDelimiter=";" -DkvDelimiter="," -DoutputTableName="rec_test_etrec_i2i_output_20230216_v1" -Dlifecycle="7" ; -- 查詢視頻間相關度得分表"rec_test_etrec_i2i_output_20230216_v1" -- 表中的每一行代表一個特定的視頻(itemid),以及與該視頻相關的一組其他視頻及它們的相關度得分(similarity), ------------------------------------------------------------------- -- itemid similarity -- 視頻1的ID 相關視頻2的id:相關視頻2的得分;相關視頻3的視頻id:相關視頻3的得分 ------------------------------------------------------------------- -- select * from rec_test_etrec_i2i_output_20230216_v1 limit 10;
rec_test_etrec_i2i_item_score_v1
表數據:視頻間相關度得分數據,每一行都表示兩個視頻之間的一個唯一的相關度得分,對rec_test_etrec_i2i_output_20230216_v1表數據進行拆分展平。
節點說明:將相關度得分數據"rec_test_etrec_i2i_output_20230216_v1"進行了轉換和簡化,以便于后續的查詢和使用,具體轉換和簡化策略,請分別打開當前節點及上游節點”rec_test_etrec_i2i_output_20230216_v1“對比查看。
在
rec_test_etrec_i2i_item_score_v1節點編輯頁面,輸入如下示例代碼:-- 表定義:視頻間相關度得分數據(拆分similarity字段) -- 表數據:每一行都表示兩個視頻之間的一個唯一的相關度得分 CREATE TABLE IF NOT EXISTS rec_test_etrec_i2i_item_score_v1 ( trigger_id STRING COMMENT '觸發推薦的視頻id(I2I中的左邊的item)' ,item_id STRING COMMENT '基于觸發推薦的視頻trigger_id,計算出與其相關的視頻' ,item_score STRING COMMENT '基于用戶的共同觀看行為計算得到的上述兩個視頻的相關度評分' ) COMMENT '視頻個性化推薦(協同過濾)-視頻間相關度得分數據(eTrec I2I item score)' PARTITIONED BY ( ds STRING ) LIFECYCLE 7 ; -- 加工過程:對視頻間相關度得分表中間表"rec_test_etrec_i2i_output_20230216_v1"的"similarity"字段進行拆分, -- 寫入視頻間相關度得分表"rec_test_etrec_i2i_item_score_v1"最新分區,本案例以寫入20230216分區為例。 -- 拆分目的:讓每一對相關視頻及其得分都被單獨一行存儲,便于使用這些得分來構建推薦。 INSERT OVERWRITE TABLE rec_test_etrec_i2i_item_score_v1 PARTITION (ds = '20230216') SELECT itemid trigger_id ,SPLIT(itemid_score,',')[0] item_id ,SPLIT(itemid_score,',')[1] item_score FROM rec_test_etrec_i2i_output_20230216_v1 LATERAL VIEW EXPLODE(SPLIT(similarity,';')) subview0 AS itemid_score ; -- 查詢拆分后的視頻間相關度得分表數據rec_test_etrec_i2i_item_score_v1 ------------------------------------------------------------------- -- trigger_id item_id item_score -- 視頻1的ID 相關視頻2的id 相關視頻2的得分 -- 視頻1的ID 相關視頻3的id 相關視頻3的得分 ------------------------------------------------------------------- -- select * from rec_test_etrec_i2i_item_score_v1 where ds = '20230216';
任務開發:用戶興趣點發現(U2I)
本階段需要創建一個ODPS SQL節點:
rec_test_etrec_u2i_trigger_score_v1節點。節點間的依賴關系,如圖所示:
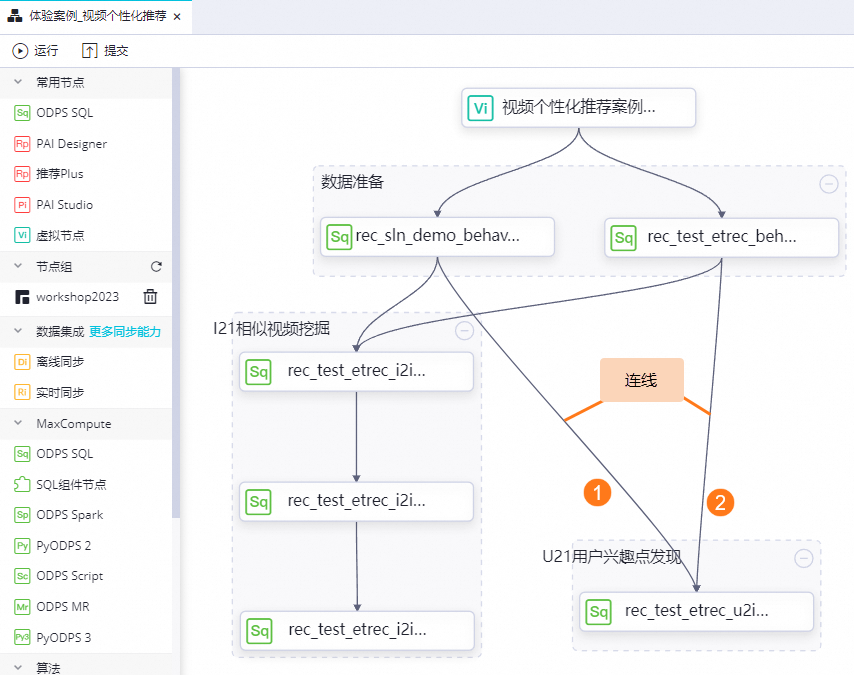
rec_test_etrec_u2i_trigger_score_v1
表數據:用戶對視頻的興趣得分數據表,從U2I中通過數值量化用戶對各個視頻內容的興趣程度,對用戶和某視頻的所有單次行為記錄權重進行匯總,代表用戶對某視頻的喜好程度。
節點說明:基于用戶近15天的視頻訪問行為數據“rec_sln_demo_behavior_table_v1”與行為權重數據"rec_test_etrec_behavior_weight_v1“,并考慮時間衰減因素,計算得出用戶對各視頻內容的興趣得分,并為每個用戶保留得分最高的100個視頻,推薦的視頻信息寫入"rec_test_etrec_u2i_trigger_score_v1"。
在
rec_test_etrec_u2i_trigger_score_v1節點編輯頁面,輸入如下示例代碼:-- 1. 表定義:“用戶對視頻的興趣得分數據”。 -- 2. 表數據:從用戶行為中派生出的感興趣的視頻得分(User-to-Item,U2I),通過數值量化用戶對各個視頻內容的興趣程度,這些數值(得分),表示用戶的偏好,表中存儲的每一行記錄代表1個用戶對1個視頻的興趣得分,通過匯總每個用戶和每個視頻的所有單次行為權重計算用戶對視頻的感興趣程度(用戶的歷史偏好)。 -- 3. 業務意義:后續該表將被用來為用戶推薦他們可能感興趣的視頻內容。 CREATE TABLE IF NOT EXISTS rec_test_etrec_u2i_trigger_score_v1 ( user_id STRING COMMENT '用戶ID' ,item_id STRING COMMENT '用戶交互過的視頻ID' ,trigger_score DOUBLE COMMENT '用戶對于視頻的偏好得分,即通過數值量化用戶對視頻的興趣程度或者偏好強度。得分基于用戶的歷史行為數據(如視頻點擊、點贊等)和行為權重(如視頻點擊權重為1,點贊行為權重為3)計算得出的。例如,如果一個用戶多次點擊觀看某個視頻,則這個視頻的偏好得分會更高。' ,rk BIGINT COMMENT '得分排序,表示根據用戶對視頻的感興趣程度按照觸發得分從高到低的順序進行排名,有助于在推薦場景中對用戶優先推薦得分高的視頻。' ) COMMENT '視頻個性化推薦(協同過濾)-用戶對視頻的興趣得分數據' PARTITIONED BY ( ds STRING ) LIFECYCLE 7 ; -- 基于用戶行為數據“rec_sln_demo_behavior_table_v1”與行為權重數據"rec_test_etrec_behavior_weight_v1“,并考慮時間衰減因素,計算得出用戶對各視頻內容的興趣得分, -- 并為每個用戶保留得分最高的100個視頻寫入rec_test_etrec_u2i_trigger_score_v1。 -- 1. 選擇行為數據:從用戶行為數據“rec_sln_demo_behavior_table_v1”中選擇最近15天的用戶行為數據,確保推薦是基于用戶當前的行為趨勢。 -- 2. 關聯行為權重:將用戶行為數據與"rec_test_etrec_behavior_weight_v1”權重數據進行連接,為每種事件(例如點擊、點贊)賦予預先定義好的權重,去除曝光記錄。 -- 3. 應用時間衰減:用DATEDIFF函數計算行為發生時間與當前日期的差距,并應用時間衰減函數來調整行為權重。時間衰減函數通過指數衰減使舊的行為對總得分的貢獻變得更小, -- 保證推薦系統能夠適應用戶興趣的變化,即可基于用戶最新喜好為用戶推薦視頻。 -- 4. 計算得分:對每個用戶和每個視頻(user_id, item_id)的行為權重進行求和,計算總的觸發得分trigger_score。如果用戶對同一個視頻有多個行為記錄, -- 這些行為的權重都將被累加以得出最終的 trigger_score。 -- 5. 排序和取TopN:使用ROW_NUMBER()函數,按trigger_score降序排列來對每個用戶的視頻得分進行排序。每個用戶的得分和排序反映了對該用戶最有吸引力的視頻內容, -- 推薦系統可以利用這些數據來生成個性化的視頻推薦。 INSERT OVERWRITE TABLE rec_test_etrec_u2i_trigger_score_v1 PARTITION (ds = '20230216') SELECT * FROM ( SELECT CAST(sq2.user_id AS STRING) user_id ,CAST(sq2.item_id AS STRING) item_id -- 對每個用戶和每個視頻(user_id, item_id)的行為權重進行求和,計算總的觸發得分trigger_score。如果用戶對同一個視頻有多個行為記錄,這些行為的權重都將被累加以得出最終的 trigger_score。 ,SUM(sq2.weight) trigger_score -- 使用ROW_NUMBER()函數按得分降序排名 ,ROW_NUMBER() OVER (PARTITION BY sq2.user_id ORDER BY SUM(sq2.weight) DESC ) rk FROM ( SELECT sq0.user_id ,sq0.item_id -- 通過指數衰減函數 EXP(-0.2 * 時間差) 來調整行為的權重 ,sq1.weight * EXP(-0.2 * DATEDIFF(TO_DATE('20230216','yyyymmdd'),TO_DATE(ds,'yyyymmdd'),'dd')) weight FROM ( -- 獲取最近15天的行為數據,確保推薦是基于用戶當前的行為趨勢,即確保推薦的是符合用戶當前的喜好的視頻 SELECT * FROM rec_sln_demo_behavior_table_v1 WHERE ds > TO_CHAR(DATEADD(TO_DATE('20230216','yyyymmdd'),-15,'dd'),'yyyymmdd') AND ds <= '20230216' ) sq0 JOIN ( -- 去除權重為0的行為,后續將從行為數據中去除那些視頻投放記錄中有推送給用戶,但用戶未點擊查看視頻的記錄 SELECT * FROM rec_test_etrec_behavior_weight_v1 WHERE weight > 0 ) sq1 ON sq0.event = sq1.event ) sq2 GROUP BY sq2.user_id ,sq2.item_id ) sq3 WHERE sq3.rk <= 100 ;
任務開發:猜你喜歡(U2I2I)
本階段需要創建兩個ODPS SQL節點:
rec_test_etrec_u2i2i_score_v1節點。視頻個性化推薦結果查詢節點。
節點間的依賴關系,如圖所示:
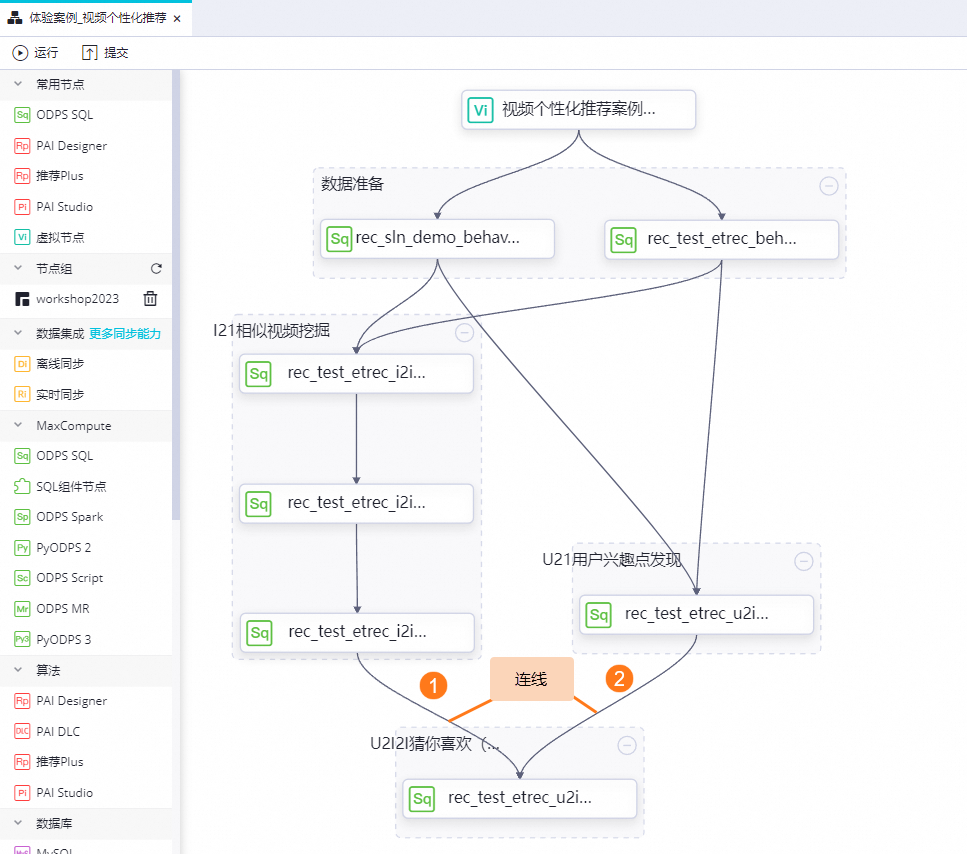
視頻個性化推薦構建與生成的數據加工邏輯:
結合U2I與I2I得分:對于每個用戶,選擇其觸發得分較高的視頻(即用戶有明顯興趣的視頻),并找到與這些視頻相關的其他視頻及其相關度得分。
計算推薦得分:通過用戶對一個已經表達過感興趣的視頻(觸發視頻得分)與該視頻與其他視頻的相關度得分(I2I)之間的乘積。這個乘積代表了用戶可能對其他某個視頻感興趣程度。
匯總與排序:對于每個用戶,對所有視頻的計算結果進行匯總,得到每個其他視頻的綜合得分。
rec_test_etrec_u2i2i_score_v1
表數據:用戶個性化視頻推薦列表,該表包含用戶已顯示出興趣的視頻(用戶的歷史偏好),也有用戶可能會感興趣的其他視頻(推測喜好)。
節點說明:基于用戶對視頻的直接興趣得分(U2I,User-to-Item),即用戶對這些視頻的興趣程度數據“rec_test_etrec_u2i_trigger_score_v1”,以及視頻間的相關度得分,即兩個視頻內容的相似程度數據(I2I,即 Item-to-Item)"rec_test_etrec_i2i_item_score_v1",生成最終的個性化推薦列表數據寫入"rec_test_etrec_u2i2i_score_v1"。
在
rec_test_etrec_u2i2i_score_v1節點編輯頁面,輸入如下示例代碼:-- 1. 表定義:“用戶個性化視頻推薦列表”。在算法場景下該表屬性為:U2I2I召回表。 -- 2. 表數據:該表存儲了最終的個性化推薦列表。 -- 3. 業務意義:基于用戶的視頻喜好數據,用戶已顯示出興趣的視頻(用戶的歷史偏好(User-to-Item,U2I)), 并通過視頻內容的相關 -- 性來擴展推薦范圍,推薦用戶可能會感興趣的其他視頻(基于內容的推薦(Item-to-Item,I2I)),提供一種更綜合的個性化視頻推薦列表。 CREATE TABLE IF NOT EXISTS rec_test_etrec_u2i2i_score_v1 ( user_id STRING COMMENT '用戶ID' ,item_ids STRING COMMENT '根據u2i2i計算得到topN的視頻,其中包含了推薦的視頻ID和視頻對應的得分,格式為物品ID:得分。物品ID和得分之間用冒號:分隔,而不同的物品得分對則使用逗號,分隔。' ) COMMENT '視頻個性化推薦(協同過濾)-用戶個性化視頻推薦列表(eTrec u2i2i召回表)' PARTITIONED BY ( ds STRING ) LIFECYCLE 7 ; -- 1. 數據流:基于用戶對視頻的直接興趣得分(U2I,User-to-Item),即用戶對這些視頻的興趣程度數據“rec_test_etrec_u2i_trigger_score_v1”, -- 以及視頻間的相關度得分(I2I,Item-to-Item),即兩個視頻內容的相關程度數據(例如視頻內容相關程度)"rec_test_etrec_i2i_item_score_v1", -- 生成最終的個性化推薦列表數據寫入"rec_test_etrec_u2i2i_score_v1" -- 2. 加工邏輯: -- 2.1 結合U2I與I2I得分:對于每個用戶,選擇其觸發得分較高的視頻(即用戶有明顯興趣的視頻),并找到與這些視頻相關的其他視頻及其相關度得分。 -- 2.2 計算推薦得分:通過用戶對一個已經表達過感興趣的視頻(觸發視頻得分)與該視頻與其他視頻的相關度得分(I2I)之間的乘積。這個乘積代表了用戶可能對其他某個視頻感興趣程度。 -- 2.3 匯總與排序:對于每個用戶,對所有視頻的計算結果進行匯總,得到每個其他視頻的綜合得分。 -- 3. 排序和篩選: -- 3.1 Top-N排序:對計算出的視頻綜合得分進行降序排序,并篩選出得分最高的前100個視頻。 -- 3.2 排名:使用窗口函數ROW_NUMBER()按用戶分組進行排序,并且對每個用戶,只保留綜合得分最高的100個視頻。 -- 注意:本案例最終推薦結果中包含用戶已看過的視頻,您可再次加工從推薦列表中去除已看過的視頻。 INSERT OVERWRITE TABLE rec_test_etrec_u2i2i_score_v1 PARTITION (ds = '20230216') SELECT sq3.user_id -- 將每個用戶的推薦視頻和相應的得分通過':'合并成一個單獨的字段 ,WM_CONCAT(',',CONCAT(sq3.item_id,':',sq3.u2i_score)) item_ids FROM ( SELECT sq2.user_id ,sq2.item_id ,ROUND(SUM(sq2.trigger_relation_score),4) u2i_score -- 為每個用戶推薦的每個視頻分配一個排名 ,ROW_NUMBER() OVER (PARTITION BY sq2.user_id ORDER BY SUM(sq2.trigger_relation_score) DESC ) rn FROM ( SELECT sq0.user_id ,sq1.item_id -- 用戶可能對相關視頻感興趣的程度 = 用戶對特定視頻的興趣得分(U2I得分)* 該視頻與另一個視頻的相關度得分(I2I得分) -- 例如:如果用戶對某個視頻表現出高興趣(U2I得分高),且該視頻與另一個視頻非常相關(I2I得分高),那么用戶也很可能對這個相關的視頻感興趣。 ,sq0.trigger_score * sq1.item_score trigger_relation_score FROM ( -- 獲取最新的用戶對視頻的興趣得分數據 SELECT * FROM rec_test_etrec_u2i_trigger_score_v1 WHERE ds = '20230216' ) sq0 JOIN ( -- 獲取最新的視頻相關性得分數據 SELECT * FROM rec_test_etrec_i2i_item_score_v1 WHERE ds = '20230216' ) sq1 ON sq0.item_id = sq1.trigger_id ) sq2 GROUP BY sq2.user_id ,sq2.item_id ) sq3 -- 控制最終的推薦列表中只包含了綜合得分最高的前100個視頻。 WHERE sq3.rn <= 100 GROUP BY sq3.user_id ;
任務運行:業務流程
所有SQL任務全部編輯成功后,您可通過如下方式運行整個業務流程:
在數據開發(DataStudio)頁面,雙擊打開業務流程。
在工具欄單擊
 圖標,在單擊運行業務流程對話框中確認按鈕,運行整個業務流程。
圖標,在單擊運行業務流程對話框中確認按鈕,運行整個業務流程。運行結束后,即可在頁面下方查看運行日志和結果。
結果查詢
創建查詢節點
本階段需要創建一個ODPS SQL節點:
視頻個性化推薦結果查詢,該節點依賴上述所有任務:節點間的依賴關系,如圖所示:
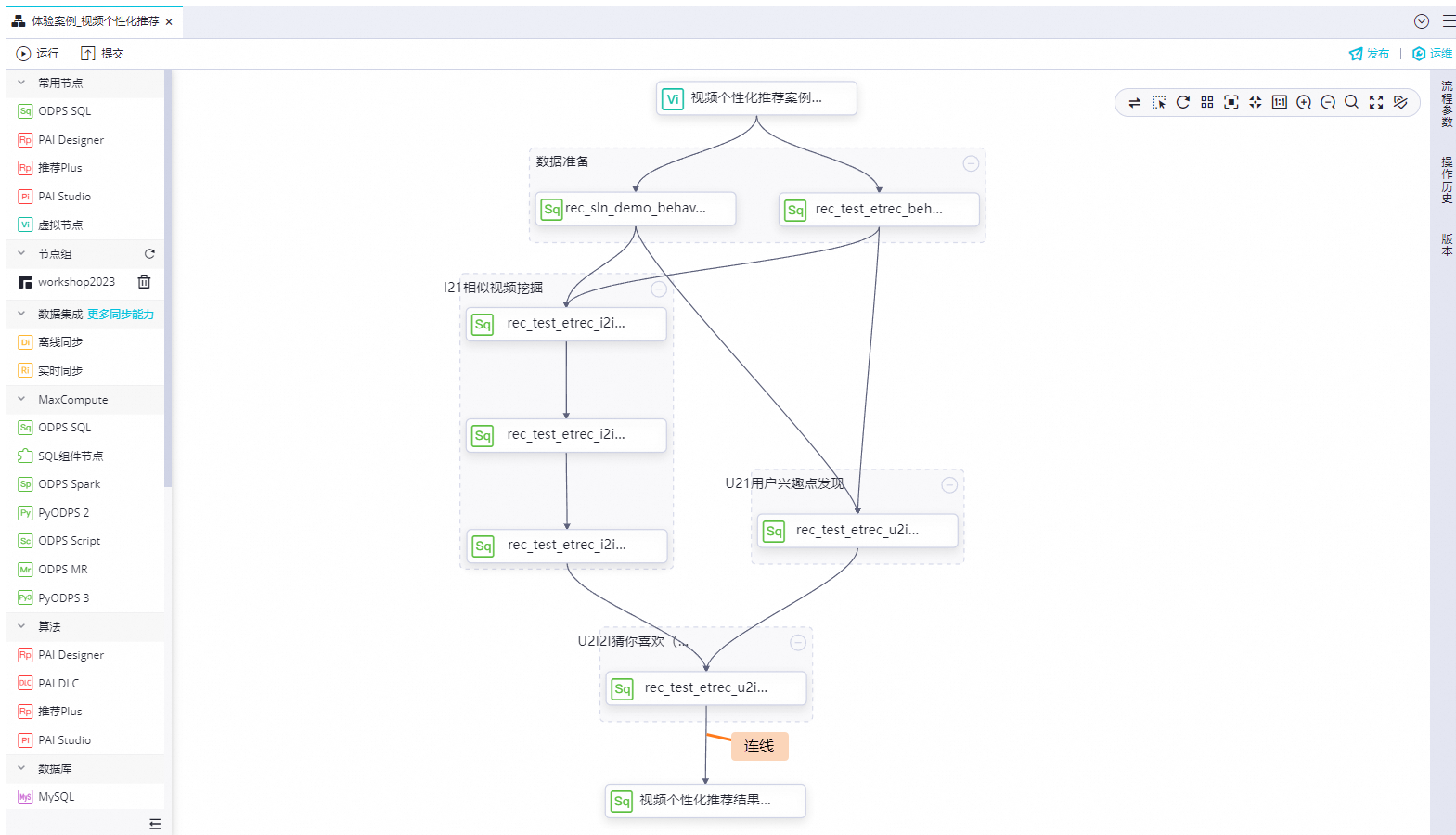
表定義:通過上述步驟已經實現了視頻個性化推薦,創建查詢節點,編寫SQL查詢語句,查看推薦結果。
在
視頻個性化推薦結果查詢節點編輯頁面,輸入如下示例代碼:--@exclude_input=rec_test_etrec_u2i2i_score_v1 --@exclude_input=rec_test_etrec_u2i_trigger_score_v1 --@exclude_input=rec_test_etrec_i2i_item_score_v1 --@exclude_input=rec_test_etrec_i2i_output_20230216_v1 --@exclude_input=rec_test_etrec_i2i_input_v1 --@exclude_input=rec_test_etrec_behavior_weight_v1 --@exclude_input=rec_sln_demo_behavior_table_v1 --odps sql --********************************************************************-- --author:dataworks_demo2 --create time:2024-01-04 18:16:50 --********************************************************************-- -- 查詢用戶與視頻的交互日志數據 select * from rec_sln_demo_behavior_table_v1 where ds='20230216' limit 10; -- 查詢行為權重定義表 select * from rec_test_etrec_behavior_weight_v1 limit 10; -- 查詢帶有行為權重的用戶與視頻交互日志數據 select * from rec_test_etrec_i2i_input_v1 where ds='20230216' limit 10; -- 查詢視頻間相關度得分臨時表 select * from rec_test_etrec_i2i_output_20230216_v1 limit 10; -- 查詢視頻間相關度得分數據 select * from rec_test_etrec_i2i_item_score_v1 where ds='20230216' limit 10; -- 查詢用戶對視頻的興趣得分數據 select * from rec_test_etrec_u2i_trigger_score_v1 where ds='20230216' limit 10; -- 查詢用戶個性化視頻推薦列表 select * from rec_test_etrec_u2i2i_score_v1 where ds='20230216' limit 10; SELECT '====================================可進入當前節點再次運行查看結構化結果集====================================';
運行查詢節點
運行整個業務流程之后,單獨運行視頻個性化推薦結果查詢節點查看推薦結果,具體操作如下所示:
雙擊打開
視頻個性化推薦結果查詢節點編輯頁面。在工具欄單擊
 圖標,單獨運行該節點,查看運行結果。
圖標,單獨運行該節點,查看運行結果。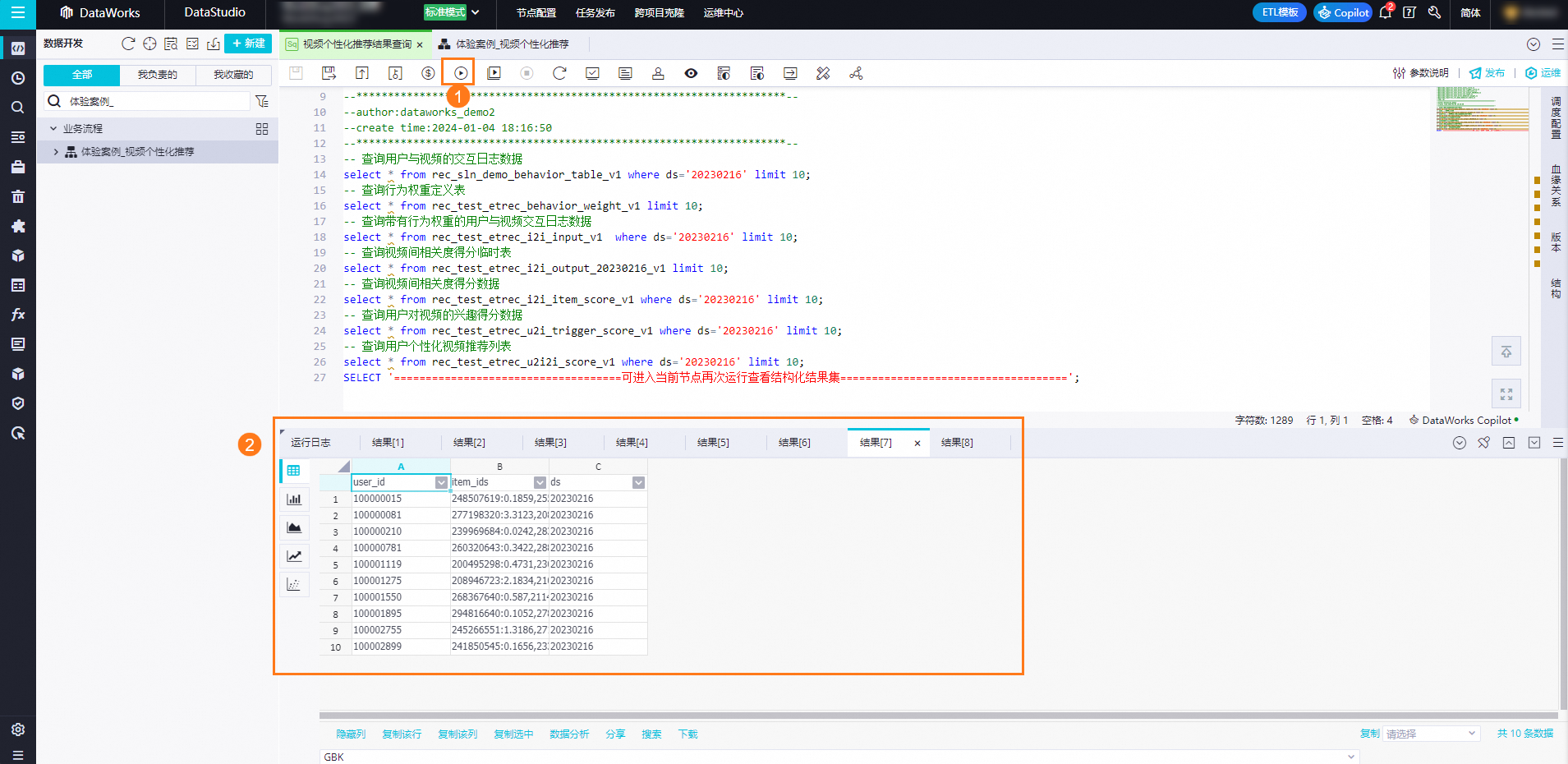
附錄:使用ETL工作流模板
DataWorks ETL工作流模板已內置該案例,您直接導入本案例相關代碼,具體操作如下:
登錄DataWorks控制臺,點擊左側導航欄的,進入ETL工作流模板頁面。
在ETL工作流模板頁面選擇視頻個性化推薦(協同過濾)業務流程,單擊查看詳情進入模板頁面,點擊載入模板。
在載入模板對話框中,選擇對應的工作空間,并在MaxCompute配置中,選擇在數據源名稱下拉列表選擇數據源,點擊確認載入模板。
資源釋放
若您在案例測試完成之后,想要清理與釋放當前案例生成的資源,您可參考以下文檔處理:
刪除表:批量刪除MaxCompute表。
下線任務:下線任務。
后續步驟
為便于理解,本案例選擇使用固定分區(20230216)進行演示,您可基于此案例制作符合您業務場景的詳情頁相關內容推薦,并結合調度參數支持的格式,將任務發布到生產周期調度中,實現數據的自動更新。詳情請參見:發布任務、查看并管理周期任務。
相關文檔
了解虛擬節點相關操作,詳情請參見:虛擬節點。
了解MaxCompute節點的ODPS SQL節點,詳情請參見:創建并管理MaxCompute節點。
了解更多開發ODPS SQL任務,詳情請參見:開發ODPS SQL任務。
了解更多運維中心的周期任務調度,詳情請參見:周期任務基本運維操作。