DataWorks支持基于EMR(E-MapReduce)計算引擎創建Hive、MR、Presto和Spark SQL等節點,實現EMR任務工作流的配置、定時調度和元數據管理等功能,保障數據生產及管理的高效穩定。本文為您介紹在DataWorks上使用EMR的基本開發流程,以及相關費用說明、環境準備、權限控制等內容。
背景信息
開源大數據開發平臺E-MapReduce(簡稱EMR),是運行在阿里云平臺上的一種大數據處理的系統解決方案。
EMR基于開源的Apache Hadoop和Apache Spark,讓您可以方便地使用Hadoop和Spark生態系統中的其他周邊系統分析和處理數據。阿里云EMR提供了on ECS、on ACK和Serverless形態,以滿足不同用戶的需求。詳情請參見E-MapReduce產品概述。
支持的集群類型
您需將EMR集群注冊至DataWorks,后續才可在DataWorks上使用該集群運行相關任務。在DataWorks執行相關操作前,請提前創建好相應集群。DataWorks目前支持注冊的集群類型如下:
EMR Serverless StarRocks僅需創建對應類型的數據源,即可在DataWorks上使用該類型集群。詳情請參見DataWorks on EMR Serverless StarRocks最佳實踐。
若您使用的集群類型無法注冊至DataWorks,請提交工單聯系技術支持人員處理。
使用限制
任務類型:DataWorks暫不支持執行EMR的Flink任務。
任務執行:DataWorks僅支持使用獨享調度資源組進行EMR任務執行。
任務治理:
僅EMR Hive、EMR Spark及EMR Spark SQL節點中SQL任務支持產出血緣關系。當集群版本為5.9.1或3.43.1及以上版本時,以上節點均支持查看表級血緣與字段級血緣。
說明對于Spark類型節點,當EMR集群版本為5.8.0和3.42.0及以上版本時,支持查看表級血緣與字段級血緣,當EMR集群版本低于5.8.0和3.42.0版本時,僅Spark 2.x支持查看表級血緣。
DataLake或自定義集群若要在DataWorks管理元數據,需先在集群側配置EMR-HOOK。若未配置,則在DataWorks中無法實時展示元數據、生成審計日志、展示血緣關系,EMR相關治理任務將無法開展。目前僅EMR Hive、EMR Spark SQL服務支持配置EMR-HOOK,配置詳情請參見配置Hive的EMR-HOOK、配置Spark SQL的EMR-HOOK。
地域限制:目前僅華北3(張家口)地域支持使用EMR Serverless Spark。
前提條件
已開通DataWorks并創建工作空間,詳情請參見開通DataWorks服務、創建并管理工作空間。
已創建EMR集群,詳情請參見創建集群。
說明在DataWorks運行EMR任務時可選擇多種EMR組件,不同組件運行任務時的最優配置存在差異,您在創建EMR集群時請參考EMR集群配置建議,根據實際情況進行選擇。
已購買DataWorks的Serverless資源組。
DataWorks資源組購買后,默認與其他云產品網絡不連通。在對接使用EMR時,需先保障EMR集群和資源組間網絡連通,才可進行后續相關操作。
說明Serverless資源組(推薦)為通用型資源組,可滿足多種任務類型(例如,數據同步、任務調度)的場景應用,購買詳情請參見新增和使用Serverless資源組。新用戶僅支持購買Serverless資源組。
若您已購買過舊版獨享資源組,也可使用該資源組運行EMR任務。舊版獨享資源組需根據待運行的任務類型選擇相應資源組。例如,運行數據同步任務,需使用獨享數據集成資源組;運行數據調度任務,需使用獨享調度資源組。詳情請參見使用舊版資源組。
使用說明
DataWorks on EMR的相關開發說明如下。
序號 | 說明 |
DataWorks上進行EMR任務開發,除DataWorks側產品費用外,還會產出其他產品側費用。 | |
DataWorks上進行EMR任務開發前,您需根據業務需求購買相應DataWorks版本及所需資源組,并完成相關EMR集群注冊及開發環境的準備工作。 | |
DataWorks為您提供了產品級與模塊級的權限控制,您可根據業務需求對不同用戶授權不同權限,實現權限的精細化管理。 | |
DataWorks數據集成提供EMR Hive數據的讀取與寫入的能力,并提供離線同步、全增量同步任務等多種數據同步場景。 | |
DataWorks提供數據建模服務,將無序、雜亂、繁瑣、龐大且難以管理的數據,進行結構化有序的管理。還提供數據開發(DataStudio)功能,用于調度任務的開發,并與運維中心配合使用,進行調度任務的監控運維。 | |
DataWorks數據分析提供EMR數據分析與服務共享能力。 | |
DataWorks提供EMR元數據管理與數據治理能力。 | |
DataWorks提供數據服務能力,幫助您統一管理面向內外部的API服務。 | |
DataWorks支持開放能力,幫助您快速實現各類應用系統對接DataWorks,并進行數據流程管控、數據治理和運維,及時響應各應用系統對接DataWorks的業務狀態變化。 |
費用說明
一、DataWorks相關費用
以下費用會體現在DataWorks產品相關賬單中。DataWorks計費詳情請參見計費簡介。
費用 | 說明 |
DataWorks版本費用 | 進行任務開發前,您需先開通DataWorks。如果開通的是DataWorks標準版、專業版、企業版,則在開通時需支付相應版本的版本費用。 |
任務調度的調度資源費用 | 任務開發完成后,進行任務調度需使用調度資源。您可使用Serverless資源組(推薦)或舊版獨享調度資源組,支付相應資源組費用。 說明 購買的Serverless資源組可滿足任務調度、數據同步共同使用。 |
數據同步的同步資源費用 | 運行數據同步任務時,除調度資源外,還需使用數據同步資源。您可使用Serverless資源組(推薦)或舊版獨享數據集成資源組,支付相應資源組費用。 |
二、非DataWorks相關費用
以下費用不會體現在DataWorks產品相關賬單中。
涉及其他產品的費用,收費情況以對應產品的收費邏輯決定,您可查看對應產品的計費文檔了解詳情。以EMR為例,計費詳情請參見計費概述。
費用 | 說明 |
數據庫費用 | 數據同步時,讀寫上下游數據庫中的數據時,可能會產生數據庫費用。 |
計算和存儲費用 | 運行計算引擎任務時,可能會產生計算引擎的計算和存儲費用。 |
網絡服務費用 | 連通DataWorks和其他相關產品的網絡環境時,可能會產生網絡服務費用。例如,使用高速通道、共享帶寬、EIP等產品連通網絡時,會產生相應產品的服務費用。 |
環境準備
一、資源準備
類別 | 描述 | 相關文檔 |
版本選擇 | DataWorks基礎版服務可滿足EMR基本的數據上云、數據開發與調度生產、簡單的數據治理工作,若需獲取更專業的數據治理、數據安全解決方案,可選擇相應的標準版、專業版、企業版服務。 | |
資源組選擇 | EMR集群目前僅支持使用Serverless資源組(推薦)或舊版獨享資源組執行任務。 |
二、開發環境準備
您需先在DataWorks工作空間注冊EMR集群,才可在數據開發(DataStudio)進行數據開發工作,并以工作空間為單位管理空間成員以便進行協同開發。
類別 | 描述 | 相關文檔 |
數據同步環境準備 | 基于集群的組件執行數據同步任務前,需先將該組件創建為相應的DataWorks數據源。 | |
數據開發、數據分析環境準備 | 基于DataWorks進行計算引擎任務周期性調度前,您需先將集群添加至DataWorks。添加后,才可使用該集群進行相關數據開發、數據分析、周期性調度運行任務等操作。 | |
協同開發環境準備 | 為保障RAM用戶以工作空間為單位進行協同開發,您需執行如下操作:
|
權限控制
DataWorks為您提供了產品級與模塊級的權限控制,您可根據業務需求對不同用戶授權不同權限。權限控制相關介紹如下。
一、數據訪問權限控制
加入至DataWorks工作空間進行EMR任務開發的RAM用戶,可通過為其配置集群賬號映射的方式,使空間成員(RAM用戶)擁有該集群映射賬號所擁有的權限。集群賬號映射,詳情請參見:設置集群身份映射。
DataWorks提供DLF可視化權限申請、權限審批及權限審計等功能,可實現數據湖全托管的統一權限管理,當EMR已將DLF設置為元數據服務時,您可以在DataWorks安全中心進行數據權限申請與控制,詳情請參見DLF數據訪問權限控制。
二、功能模塊權限控制
進行數據開發前,您可參考為RAM用戶授權指引,讓其擁有不同的操作權限。權限類型如下:
通過全局級模塊權限控制,管理DataWorks功能模塊(例如,不允許用戶訪問數據地圖)與DataWorks控制臺的權限(例如,允許用戶刪除工作空間)。
通過空間級模塊權限管控,管理DataWorks空間級模塊(例如,允許用戶進入數據開發執行相關開發操作)與全局模塊的使用權限(例如,禁止用戶訪問數據保護傘模塊)。
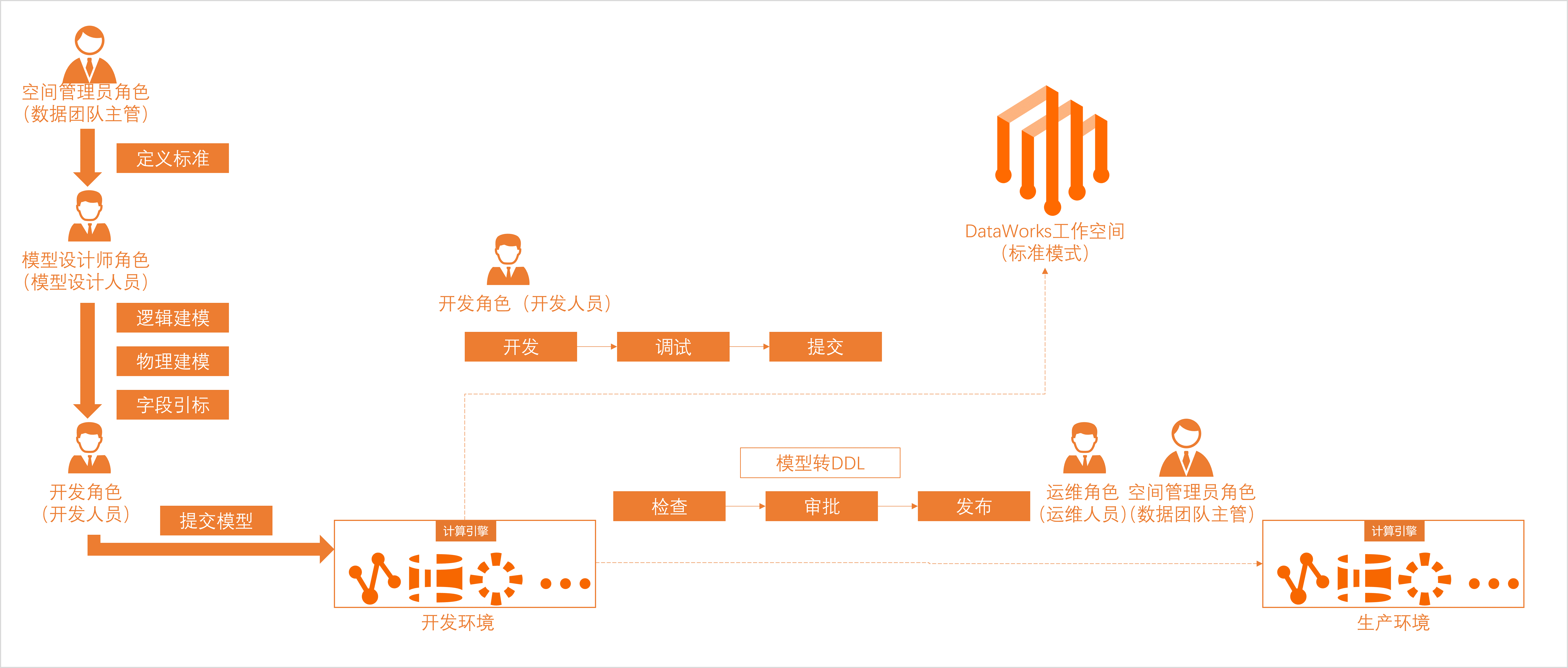
開始使用
DataWorks為您提供了多個功能模塊,您可在數據開發(DataStudio)中進行調度任務的開發,并在開發完成后進入生產運維中心進行調度任務的監控運維。同時,提供了任務開發與發布的流程管控,助力您規范開發操作,保障開發過程的安全性。
一、數據集成
DataWorks的數據集成模塊為您提供讀取和寫入數據至EMR Hive的能力,您需要將Hive組件創建為DataWorks的Hive數據源,實現將其他數據源的數據同步至Hive數據源,或將Hive數據源的數據同步至其他數據源。同時,可根據需要選擇離線同步、全增量同步任務等場景執行相關數據同步操作。詳情請參見數據集成。
二、數據建模與開發
模塊 | 說明 | 相關文檔 |
數據建模 | 數據建模是全鏈路數據治理的第一步,沉淀阿里巴巴數據中臺建模方法論,從數倉規劃、數據標準、維度建模、數據指標四個方面,以業務視角對業務的數據進行詮釋,讓企業內部實現“數同文”的快速理解與流通。 | |
數據開發 | DataWorks將EMR計算引擎的能力進行了封裝,支持您執行EMR相關的數據同步、數據開發任務。
| |
您可結合DataWorks的通用類型節點和引擎計算節點進行復雜的邏輯處理。 主要節點如下:
| ||
節點任務開發完成后,可根據需要執行如下操作:
| ||
運維中心 | 運維中心是一站式大數據運維、監控平臺,支持實時查看任務的運行狀態,并為異常任務提供智能診斷、重跑等運維操作。它提供智能基線功能,幫助您解決重要任務產出時間不可控、海量任務監控難等問題,保障任務產出的時效性。 | |
數據質量 | 數據質量針對數據研發的全鏈路,保障數據可用性。通過對數據質量規則的高效校驗,以及與任務調度流程的緊密結合,可以幫助用戶第一時間發現質量問題、有效防止數據質量問題擴散,為業務提供高效、可靠、可信賴的數據。 |
二、數據分析
幫助您實現在線SQL分析、業務洞察、編輯和分享數據;并支持將查詢結果保存為圖表卡片,快速搭建可視化數據報告便于日常匯報。詳情請參見數據分析概述。
三、數據治理
注冊EMR集群至DataWorks后,DataWorks將自動采集您引擎下的元數據,您可前往數據地圖概述進行查看;同時,也可進入數據治理中心概述,查看DataWorks檢測的待治理問題,進行相關數據治理操作。
模塊 | 說明 | 相關文檔 |
數據地圖 | DataWorks數據地圖提供了企業級數據管理平臺,能夠基于統一元數據的底層建設,提供數據對象的管理和盤點的能力,以及數據對象的快速查找和深度理解的能力。 | |
安全中心 數據保護傘 審批中心 | 安全中心是集數據資產分級分類、敏感數據識別、數據授權管理、敏感數據脫敏、敏感數據訪問審計、風險識別與響應于一體的一站式數據安全治理界面,幫助用戶落地數據安全治理事項。 | |
數據治理中心 | 數據治理中心針對多個治理領域,通過數據領域規則沉淀、自動識別資產待優化問題項、覆蓋事后及事前的治理優化策略等方式幫助用戶主動式、體系化完成數據治理工作。 |
四、數據服務
DataWorks數據服務旨在為企業提供全面的數據服務及共享能力,幫助企業統一管理面向內外部的API服務。詳情請參見數據服務概述。
五、開放平臺
DataWorks支持開放能力,幫助您快速實現各類應用系統對接DataWorks、方便快捷的進行數據流程管控、數據治理和運維,及時響應應用系統對接DataWorks的業務狀態變化。
類別 | 描述 | 相關文檔 |
OpenAPI | DataWorks開放平臺的OpenAPI功能,為您提供開放API能力,通過開放API實現本地服務和DataWorks服務的交互,提升企業大數據處理效率,減少人工操作和運維工作,降低數據風險和企業成本。 | |
開放事件 | DataWorks開放平臺的開放事件(OpenEvent)功能,為您提供消息訂閱服務,通過訂閱DataWorks事件狀態、應用系統對接DataWorks、實時獲取相關內容的狀態變化,幫助您及時響應相應事件,滿足個性化決策需求。 | |
擴展程序 | DataWorks通過OpenEvent為您提供消息推送訂閱功能,您可將服務程序注冊為DataWorks的擴展程序,通過擴展程序來卡點并響應訂閱的事件消息,實現通過擴展程序對特定事件進行消息通知與流程管控。 |
附錄:EMR集群配置建議
在DataWorks運行EMR任務時可選擇多種EMR組件,不同組件運行任務時的最優配置存在差異,您在配置EMR集群時請參考下文,根據實際情況選擇。
Kyuubi組件
在生產環境配置Kyuubi組件時,建議將
kyuubi_java_opts內存大小調整至10g及以上;將kyuubi_beeline_opts內存大小調整至2g及以上。Spark組件
由于Spark組件內存默認值較小,您可在
spark-submit命令行中添加設置內存大小的命令,修改內存默認值為合適大小。您可根據所使用的EMR集群規模情況調整Spark組件以下配置項:
spark.driver.memory、spark.driver.memoryOverhead、spark.executor.memory至合適大小。
重要僅DataWorks的EMR Hive、EMR Spark及EMR Spark SQL節點支持血緣功能。其中,EMR Hive節點支持表及列血緣,Spark類型節點僅支持表血緣。
更多Spark組件的配置詳情,請參見Spark Memory Management。
HDFS
您可根據所使用的EMR集群規模情況調整HDFS的以下配置項:
hadoop_namenode_heapsize、hadoop_datanode_heapsize、hadoop_secondary_namenode_heapsize、hadoop_namenode_opts至合適大小。